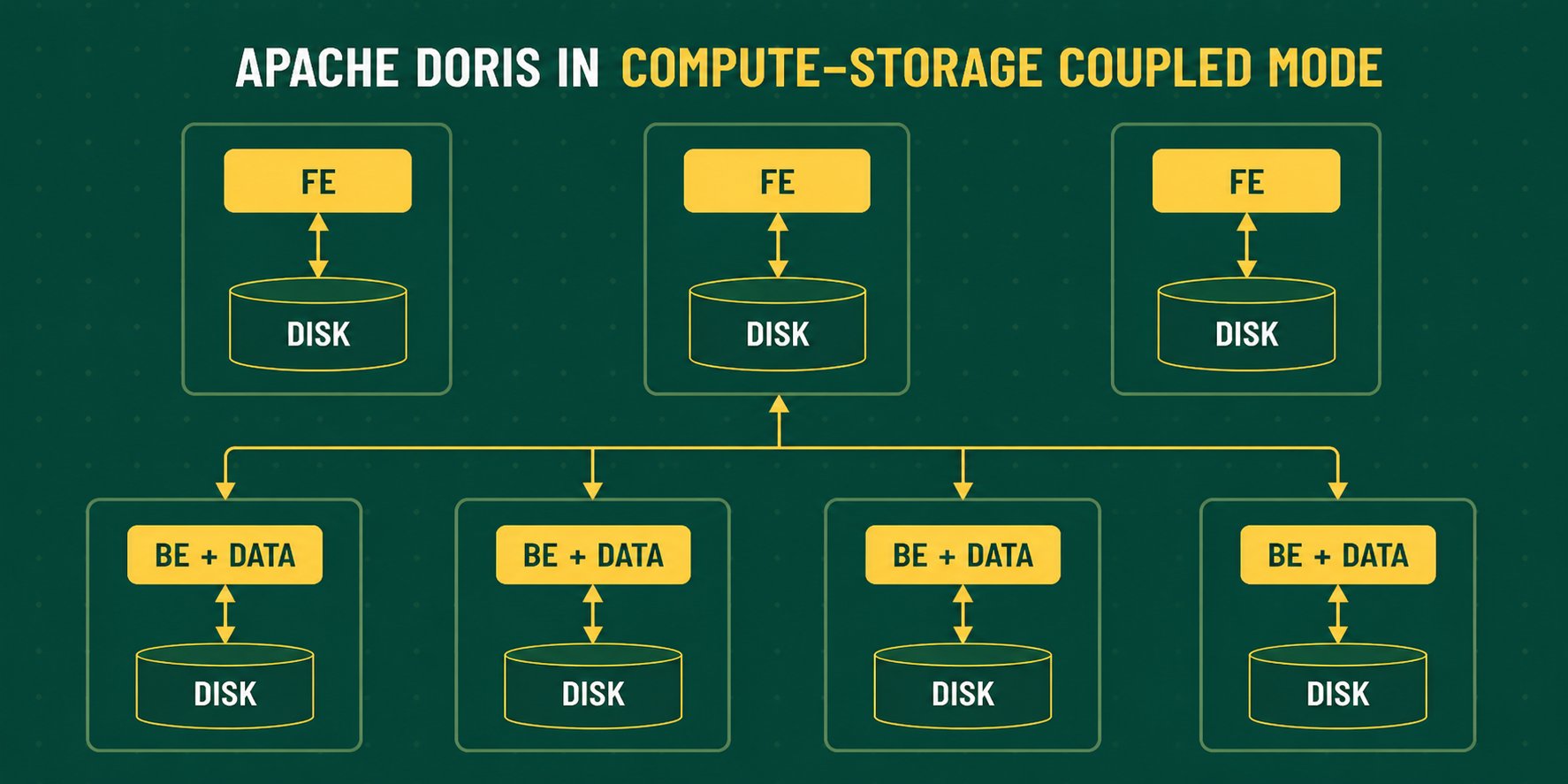
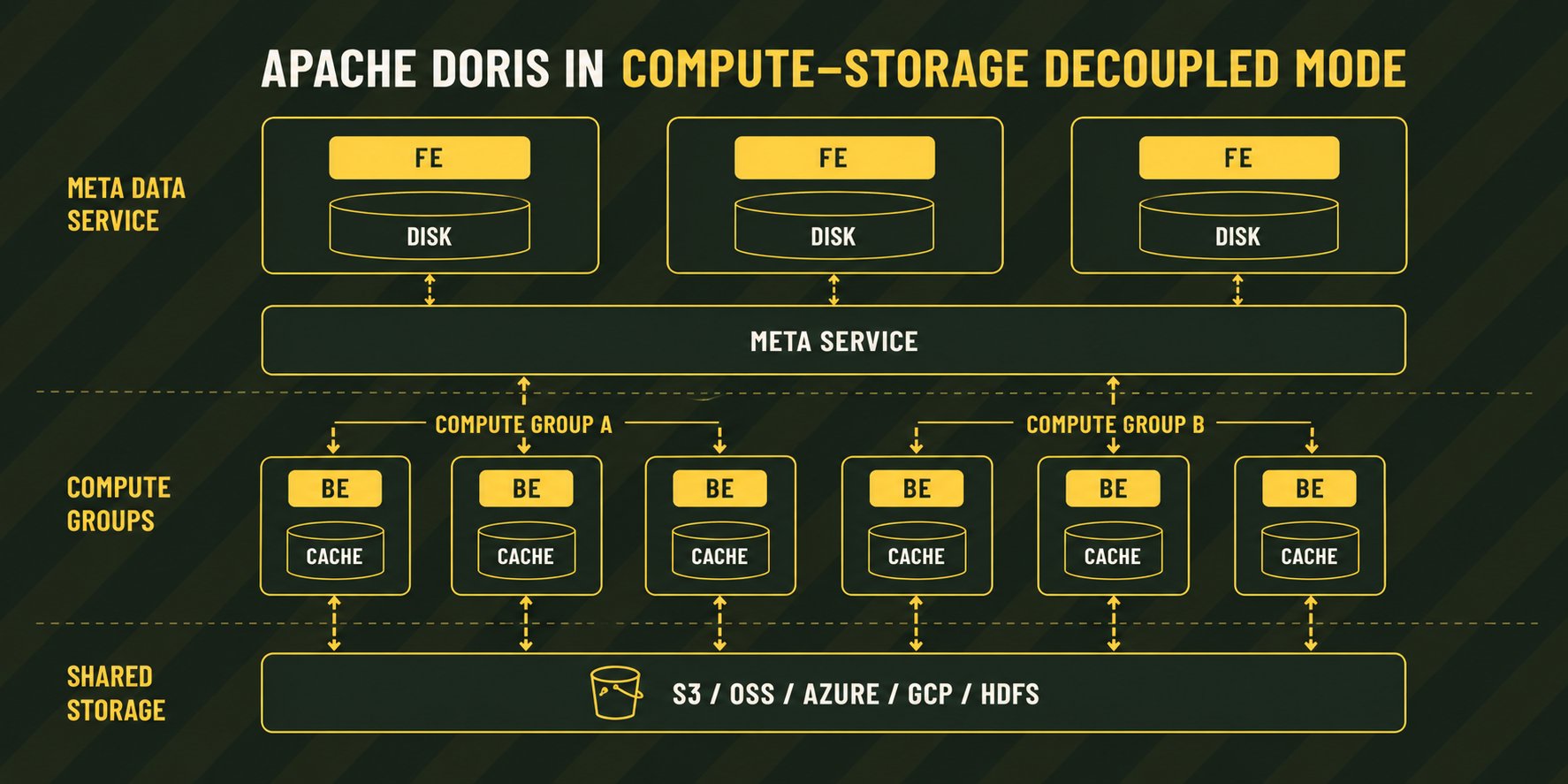
Ave AIAI
Ave AI is a fast-growing data startup turning messy enterprise signals into AI-driven analytics and intelligent decisioning for modern data teams.
Use case
Builds AI-driven data products on Doris with fast SQL access for ad-hoc exploration and reporting.