
How We increased database query concurrency by 20 times
A unified analytic database is the holy grail for data engineers, but what does it look like specifically? It should evolve with the needs of data users.
Vertically, companies now have an ever enlarging pool of data and expect a higher level of concurrency in data processing. Horizontally, they require a wider range of data analytics services. Besides traditional OLAP scenarios such as statistical reporting and ad-hoc queries, they are also leveraging data analysis in recommender systems, risk control, customer tagging and profiling, and IoT.
Among all these data services, point queries are the most frequent operations conducted by data users. Point query means to retrieve one or several rows from the database based on the Key. A point query only returns a small piece of data, such as the details of a shopping order, a transaction, a consumer profile, a product description, logistics status, and so on. Sounds easy, right? But the tricky part is, a database often needs to handle tens of thousands of point queries at a time and respond to all of them in milliseconds.
Most current OLAP databases are built with a columnar storage engine to process huge data volumes. They take pride in their high throughput, but often underperform in high-concurrency scenarios. As a complement, many data engineers invite Key-Value stores like Apache HBase for point queries, and Redis as a cache layer to ease the burden. The downside is redundant storage and high maintenance costs.
Since Apache Doris was born, we have been striving to make it a unified database for data queries of all sizes, including ad-hoc queries and point queries. Till now, we have already taken down the monster of high-throughput OLAP scenarios. In the upcoming Apache Doris 2.0, we have optimized it for high-concurrency point queries. Long story short, it can achieve over 30,000 QPS for a single node.
Five Ways to Accelerate High-Concurrency Queries
High-concurrency queries are thorny because you need to handle high loads with limited system resources. That means you have to reduce the CPU, memory and I/O overheads of a single SQL as much as possible. The key is to minimize the scanning of underlying data and follow-up computing.
Apache Doris uses five methods to achieve higher QPS.
Partioning and Bucketing
Apache Doris shards data into a two-tiered structure: Partition and Bucket. You can use time information as the Partition Key. As for bucketing, you distribute the data into various nodes after data hashing. A wise bucketing plan can largely increase concurrency and throughput in data reading.
This is an example:
select * from user_table where id = 5122 and create_date = '2022-01-01'
In this case, the user has set 10 buckets. create_date is the Partition Key and id is the Bucket Key. After dividing the data into partitions and buckets, the system only needs to scan one bucket in one partition before it can locate the needed data. This is a huge time saver.
Index
Apache Doris uses various data indexes to speed up data reading and filtering, including smart indexes and secondary indexes. Smart indexes are auto-generated by Doris upon data ingestion, which requires no action from the user's side.
There are two types of smart indexes:
- Sorted Index: Apache Doris stores data in an orderly way. It creates a sorted index for every 1024 rows of data. The Key in the index is the value of the sorted column in the first row of the current 1024 rows. If the query involves the sorted column, the system will locate the first row of the relevant 1024 row group and start scanning there.
- ZoneMap Index: These are indexes on the Segment and Page level. The maximum and minimum values of each column within a Page will be recorded, so are those within a Segment. Hence, in equivalence queries and range queries, the system can narrow down the filter range with the help of the MinMax indexes.
Secondary indexes are created by users. These include Bloom Filter indexes, Bitmap indexes, Inverted indexes, and NGram Bloom Filter indexes. (If you are interested, I will go into details about them in future articles.)
Example:
select * from user_table where id > 10 and id < 1024
Suppose that the user has designated id as the Key during table creation, the data will be sorted by id on Memtable and the disks. So any queries involving id as a filter condition will be executed much faster with the aid of sorted indexes. Specifically, the data in storage will be put into multiple ranges based on id, and the system will implement binary search to locate the exact range according to the sorted indexes. But that could still be a large range since the sorted indexes are sparse. You can further narrow it down based on ZoneMap indexes, Bloom Filter indexes, and Bitmap indexes.
This is another way to reduce data scanning and improve overall concurrency of the system.
Materialized View
The idea of materialized view is to trade space for time: You execute pre-computation with pre-defined SQL statements, and perpetuate the results in a table that is visible to users but occupies some storage space. In this way, Apache Doris can respond much faster to queries for aggregated data and breakdown data and those involve the matching of sorted indexes once it hits a materialized view. This is a good way to lessen computation, improve query performance, and reduce resource consumption.
// For an aggregation query, the system reads the pre-aggregated columns in the materialized view.
create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
// For a query where k3 matches the sorted column in the materialized view, the system directly performs the query on the materialized view.
CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
select k1, k2, k3 from table A where k3=3;
Runtime Filter
Apart from filtering data by indexes, Apache Doris has a dynamic filtering mechanism: Runtime Filter.
In multi-table Join queries, the left table is usually called ProbeTable while the right one is called BuildTable, with the former much bigger than the latter. In query execution, firstly, the system reads the right table and creates a HashTable (Build) in the memory. Then, it starts reading the left table row by row, during which it also compares data between the left table and the HashTable and returns the matched data (Probe).
So what's new about that in Apache Doris? During the creation of HashTable, Apache Doris generates a filter for the columns. It can be a Min/Max filter or an IN filter. Then it pushes down the filter to the left table, which can use the filter to screen out data and thus reduces the amount of data that the Probe node has to transfer and compare.
This is how the Runtime Filter works. In most Join queries, the Runtime Filter can be automatically pushed down to the most underlying scan nodes or to the distributed Shuffle Join. In other words, Runtime Filter is able to reduce data reading and shorten response time for most Join queries.
TOP-N Optimization
TOP-N query is a frequent scenario in data analysis. For example, users want to fetch the most recent 100 orders, or the 5 highest/lowest priced products. The performance of such queries determines the quality of real-time analysis. For them, Apache Doris implements TOP-N optimization. Here is how it goes:
- Apache Doris reads the sorted fields and query fields from the Scanner layer, reserves only the TOP-N pieces of data by means of Heapsort, updates the real-time TOP-N results as it continues reading, and dynamically pushes them down to the Scanner.
- Combing the received TOP-N range and the indexes, the Scanner can skip a large proportion of irrelevant files and data chunks and only read a small number of rows.
- Queries on flat tables usually mean the need to scan massive data, but TOP-N queries only retrieve a small amount of data. The strategy here is to divide the data reading process into two stages. In stage one, the system sorts the data based on a few columns (sorted column, or condition column) and locates the TOP-N rows. In stage two, it fetches the TOP-N rows of data after data sorting, and then it retrieves the target data according to the row numbers.
To sum up, Apache Doris prunes the data that needs to be read and sorted, and thus substantially reduces consumption of I/O, CPU, and memory resources.
In addition to the foregoing five methods, Apache Doris also improves concurrency by SQL Cache, Partition Cache, and a variety of Join optimization techniques.
How We Bring Concurrency to the Next Level
By adopting the above methods, Apache Doris was able to achieve thousands of QPS per node. However, in scenarios requiring tens of thousands of QPS, it was still bottlenecked by several issues:
- With Doris' columnar storage engine, it was inconvenient to read rows. In flat table models, columnar storage could result in much larger I/O usage.
- The execution engine and query optimizer of OLAP databases were sometimes too complicated for simple queries (point queries, etc.). Such queries needed to be processed with a shorter pipeline, which should be considered in query planning.
- FE modules of Doris, implementing Java, were responsible for interfacing with SQL requests and parsing query plans. These processes could produce high CPU overheads in high-concurrency scenarios.
We optimized Apache Doris to solve these problems. (Pull Request on Github)
Row Storage Format
As we know, row storage is much more efficient when the user only queries for a single row of data. So we introduced row storage format in Apache Doris 2.0. Users can enable row storage by specifying the following property in the table creation statement.
"store_row_column" = "true"
We chose JSONB as the encoding format for row storage for three reasons:
- Flexible schema change: If a user has added or deleted a field, or modified the type of a field, these changes must be updated in row storage in real time. So we choose to adopt the JSONB format and encode columns into JSONB fields. This makes changes in fields very easy.
- High performance: Accessing rows in row-oriented storage is much faster than doing that in columnar storage, and it requires much less disk access in high-concurrency scenarios. Also, in some cases, you can map the column ID to the corresponding JSONB value so you can quickly access a certain column.
- Less storage space: JSONB is a compacted binary format. It consumes less space on the disk and is more cost-effective.
In the storage engine, row storage will be stored as a hidden column (DORIS_ROW_STORE_COL). During Memtable Flush, the columns will be encoded into JSONB and cached into this hidden column. In data reading, the system uses the Column ID to locate the column, finds the target row based on the row number, and then deserializes the relevant columns.
Short-Circuit
Normally, an SQL statement is executed in three steps:
- SQL Parser parses the statement to generate an abstract syntax tree (AST).
- The Query Optimizer produces an executable plan.
- Execute the plan and return the results.
For complex queries on massive data, it is better to follow the plan created by the Query Optimizer. However, for high-concurrency point queries requiring low latency, that plan is not only unnecessary but also brings extra overheads. That's why we implement a short-circuit plan for point queries.
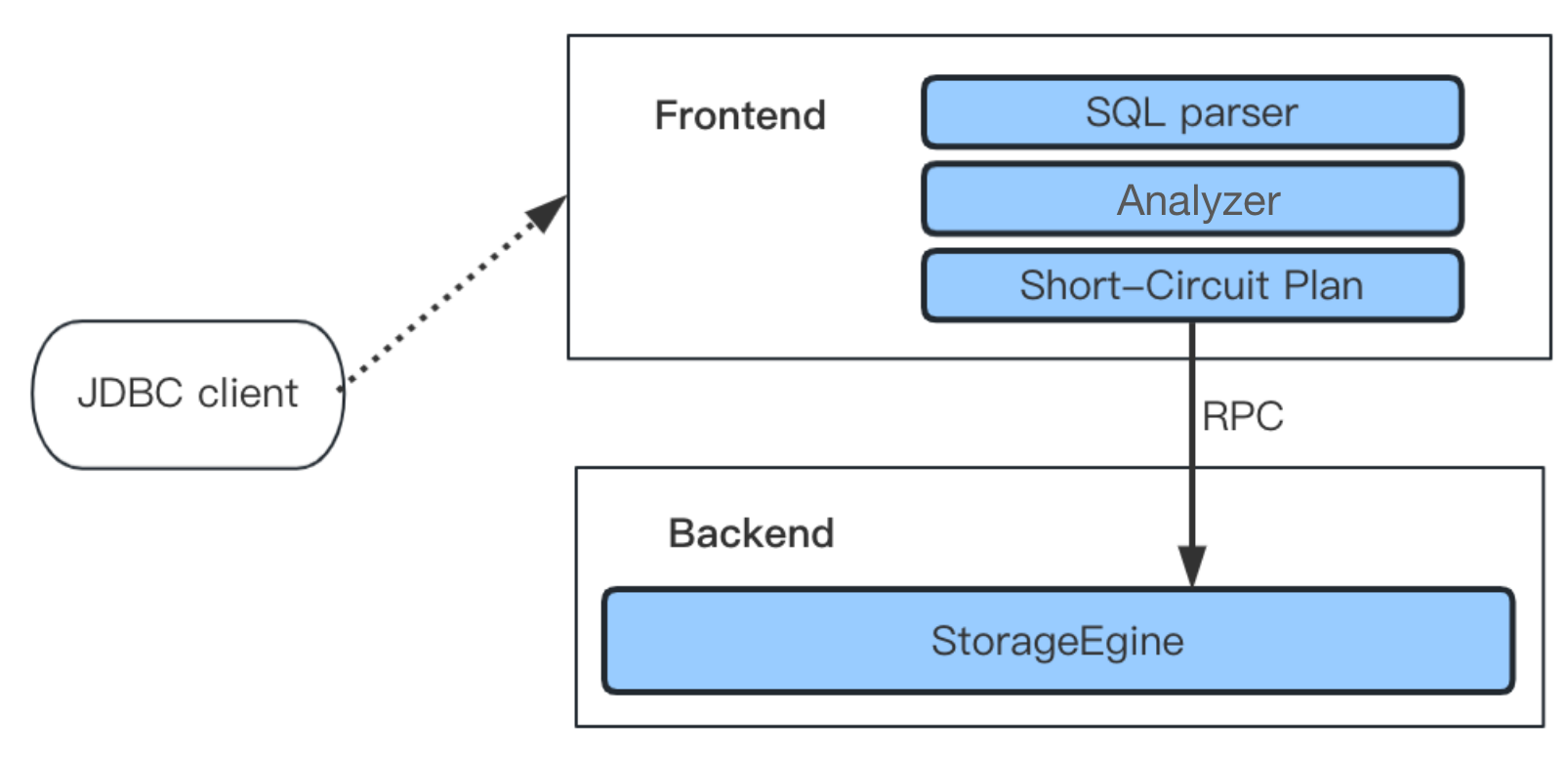
Once the FE receives a point query request, a short-circuit plan will be produced. It is a lightweight plan that involves no equivalent transformation, logic optimization or physical optimization. Instead, it conducts some basic analysis on the AST, creates a fixed plan accordingly, and finds ways to reduce overhead of the optimizer.
For a simple point query involving primary keys, such as select * from tbl where pk1 = 123 and pk2 = 456, since it only involves one single Tablet, it is better to use a lightweight RPC interface for interaction with the Storage Engine. This avoids the creation of a complicated Fragment Plan and eliminates the performance overhead brought by the scheduling under the MPP query framework.
Details of the RPC interface are as follows:
message PTabletKeyLookupRequest {
required int64 tablet_id = 1;
repeated KeyTuple key_tuples = 2;
optional Descriptor desc_tbl = 4;
optional ExprList output_expr = 5;
}
message PTabletKeyLookupResponse {
required PStatus status = 1;
optional bytes row_batch = 5;
optional bool empty_batch = 6;
}
rpc tablet_fetch_data(PTabletKeyLookupRequest) returns (PTabletKeyLookupResponse);
tablet_id is calculated based on the primary key column, while key_tuples is the string format of the primary key. In this example, the key_tuples is similar to ['123', '456']. As BE receives the request, key_tuples will be encoded into primary key storage format. Then, it will locate the corresponding row number of the Key in the Segment File with the help of the primary key index, and check if that row exists in delete bitmap. If it does, the row number will be returned; if not, the system returns NotFound. The returned row number will be used for point query on __DORIS_ROW_STORE_COL__. That means we only need to locate one row in that column, fetch the original value of the JSONB format, and deserialize it.
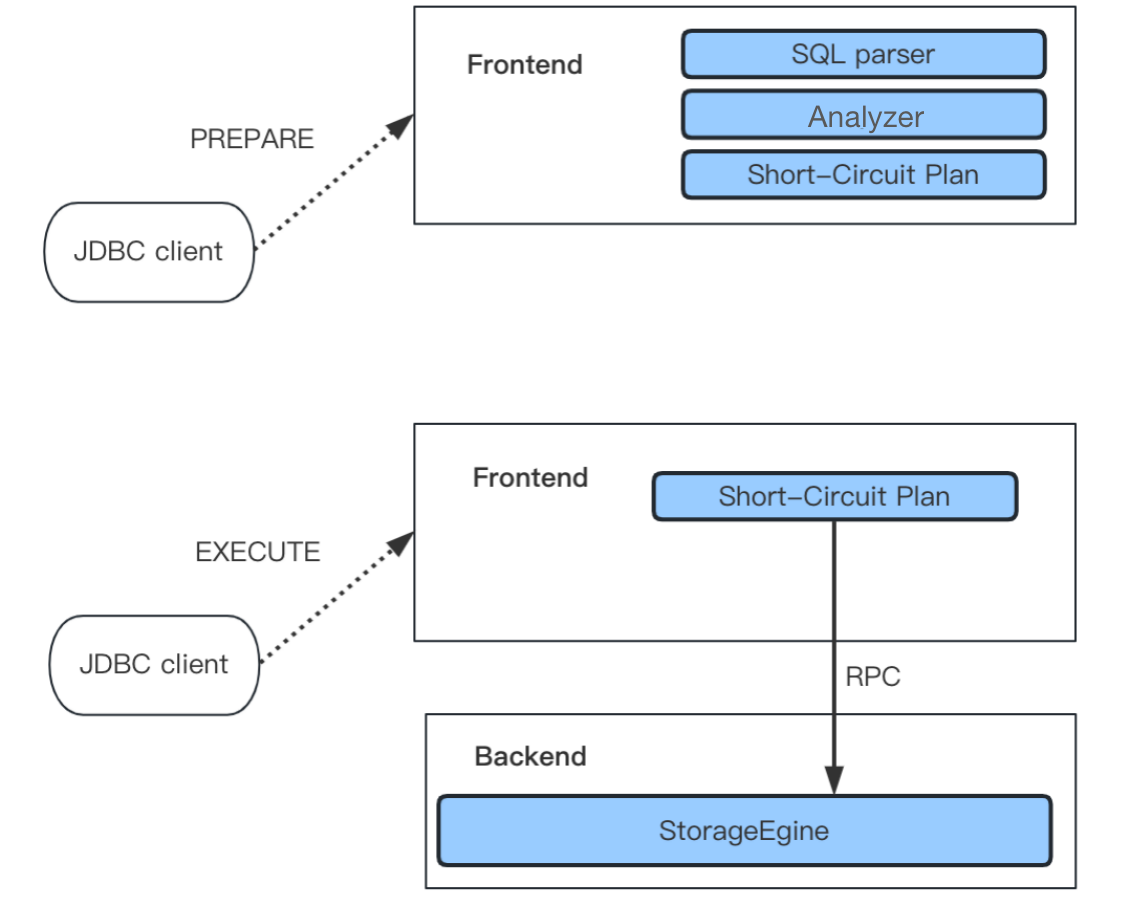
Prepared Statement
In high-concurrency queries, part of the CPU overhead comes from SQL analysis and parsing in FE. To reduce such overhead, in FE, we provide prepared statements that are fully compatible with MySQL protocol. With prepared statements, we can achieve a four-time performance increase for primary key point queries.
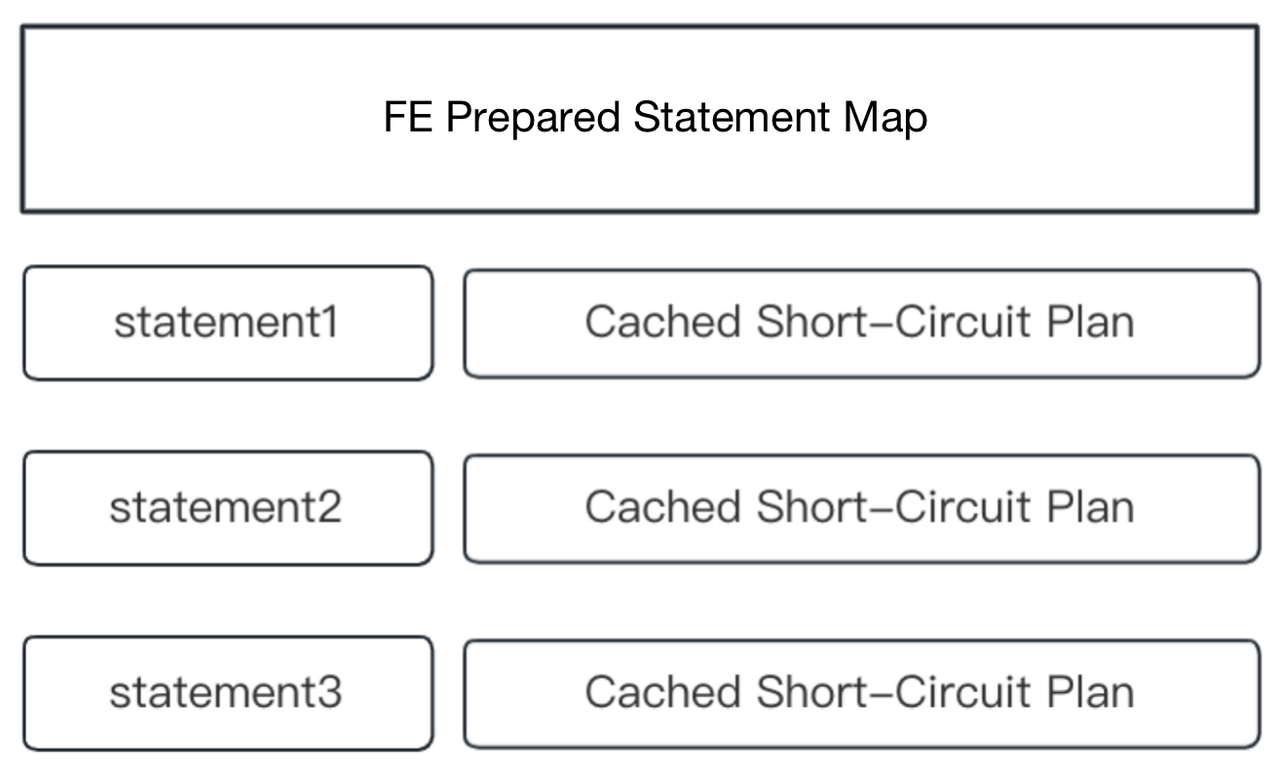
The idea of prepared statements is to cache precomputed SQL and expressions in HashMap in memory, so they can be directly used in queries when applicable.
Prepared statements adopt MySQL binary protocol for transmission. The protocol is implemented in the mysql_row_buffer.[h|cpp] file, and uses MySQL binary encoding. Under this protocol, the client (for example, JDBC Client) sends a pre-compiled statement to FE via PREPARE MySQL Command. Next, FE will parse and analyze the statement and cache it in the HashMap as shown in the figure above. Next, the client, using EXECUTE MySQL Command, will replace the placeholder, encode it into binary format, and send it to FE. Then, FE will perform deserialization to obtain the value of the placeholder, and generate query conditions.
Apart from caching prepared statements in FE, we also cache reusable structures in BE. These structures include pre-allocated computation blocks, query descriptors, and output expressions. Serializing and deserializing these structures often cause a CPU hotspot, so it makes more sense to cache them. The prepared statement for each query comes with a UUID named CacheID. So when BE executes the point query, it will find the corresponding class based on the CacheID, and then reuse the structure in computation.
The following example demonstrates how to use a prepared statement in JDBC:
- Set a JDBC URL and enable prepared statement at the server end.
url = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
- Use a prepared statement.
// Use `?` as placeholder, reuse readStatement.
PreparedStatement readStatement = conn.prepareStatement("select * from tbl_point_query where key = ?");
...
readStatement.setInt(1234);
ResultSet resultSet = readStatement.executeQuery();
...
readStatement.setInt(1235);
resultSet = readStatement.executeQuery();
...
Row Storage Cache
Apache Doris has a Page Cache feature, where each page caches the data of one column.
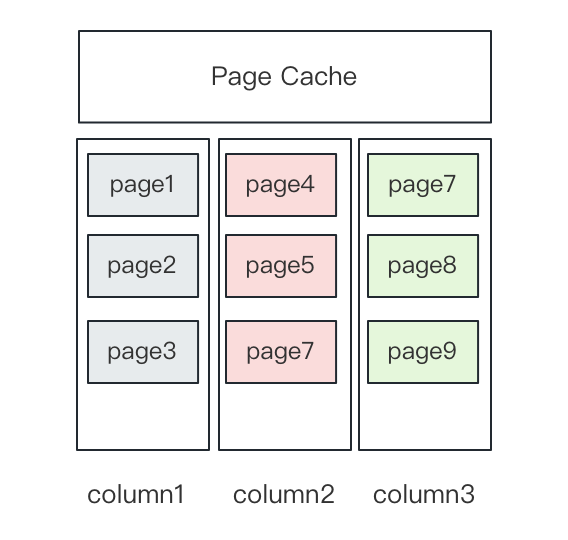
As mentioned above, we have introduced row storage in Doris. The problem with this is, one row of data consists of multiple columns, so in the case of big queries, the cached data might be erased. Thus, we also introduced row cache to increase row cache hit rate.
Row cache reuses the LRU Cache mechanism in Apache Doris. When the caching starts, the system will initialize a threshold value. If that threshold is hit, the old cached rows will be phased out. For a primary key query statement, the performance gap between cache hit and cache miss can be huge (we are talking about dozens of times less disk I/O and memory access here). So the introduction of row cache can remarkably enhance point query performance.
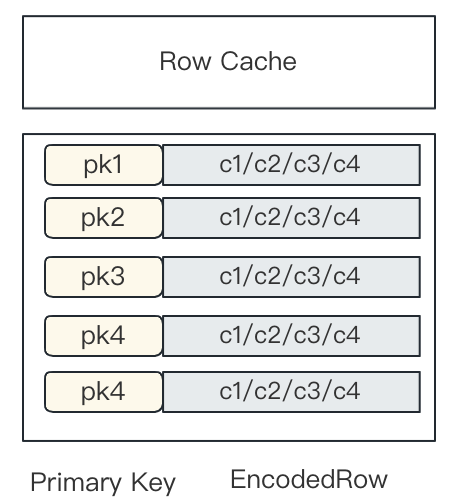
To enable row cache, you can specify the following configuration in BE:
disable_storage_row_cache=false // This specifies whether to enable row cache; it is set to false by default.
row_cache_mem_limit=20% // This specifies the percentage of row cache in the memory; it is set to 20% by default.
Benchmark Performance
We tested Apache Doris with YCSB (Yahoo! Cloud Serving Benchmark) to see how all these optimizations work.
Configurations and data size:
- Machines: a single 16 Core 64G cloud server with 4×1T hard drives
- Cluster size: 1 Frontend + 2 Backends
- Data volume: 100 million rows of data, with each row taking 1KB to store; preheated
- Table schema and query statement:
// Table creation statement:
CREATE TABLE `usertable` (
`YCSB_KEY` varchar(255) NULL,
`FIELD0` text NULL,
`FIELD1` text NULL,
`FIELD2` text NULL,
`FIELD3` text NULL,
`FIELD4` text NULL,
`FIELD5` text NULL,
`FIELD6` text NULL,
`FIELD7` text NULL,
`FIELD8` text NULL,
`FIELD9` text NULL
) ENGINE=OLAP
UNIQUE KEY(`YCSB_KEY`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`YCSB_KEY`) BUCKETS 16
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"in_memory" = "false",
"persistent" = "false",
"storage_format" = "V2",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true",
"disable_auto_compaction" = "false"
);
// Query statement:
SELECT * from usertable WHERE YCSB_KEY = ?
We run the test with the optimizations (row storage, short-circuit, and prepared statement) enabled, and then did it again with all of them disabled. Here are the results:
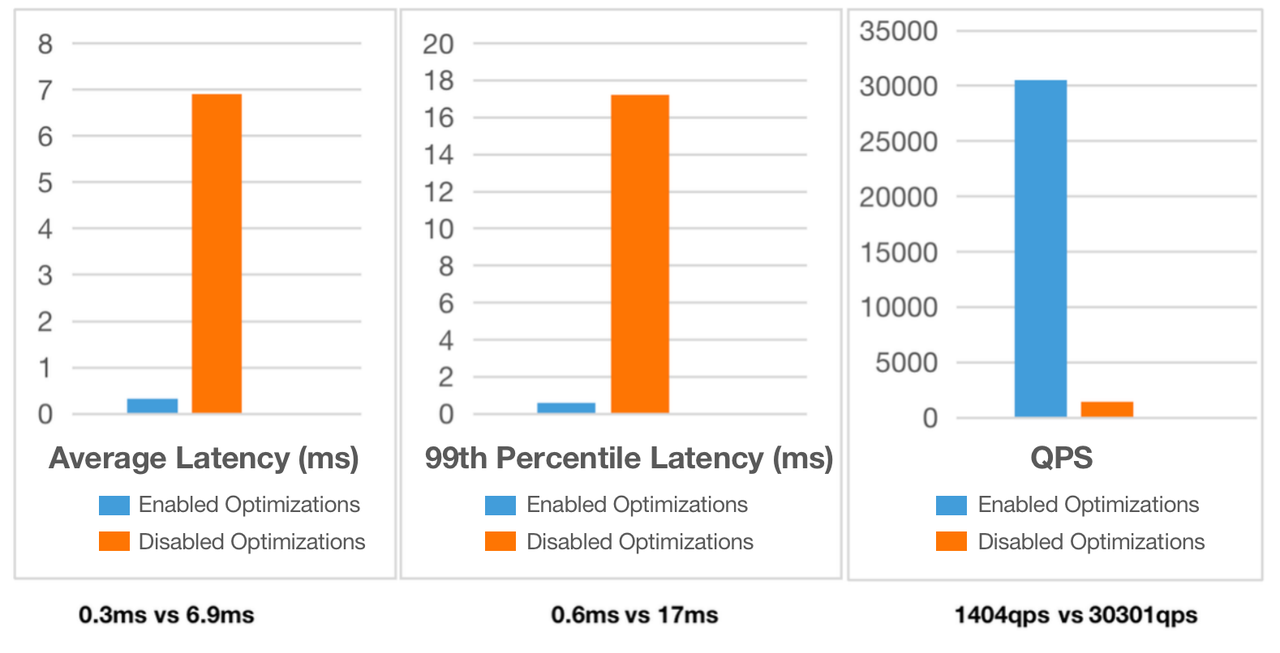
With optimizations enabled, the average query latency decreased by a whopping 96%, the 99th percentile latency was only 1/28 of that without optimizations, and it has achieved a query concurrency of over 30,000 QPS. This is a huge leap in performance and an over 20-time increase in concurrency.
Best Practice
It should be noted that these optimizations for point queries are implemented in the Unique Key model of Apache Doris, and you should enable Merge-on-Write and Light Schema Change for this model.
This is a table creation statement example for point queries:
CREATE TABLE `usertable` (
`USER_KEY` BIGINT NULL,
`FIELD0` text NULL,
`FIELD1` text NULL,
`FIELD2` text NULL,
`FIELD3` text NULL
) ENGINE=OLAP
UNIQUE KEY(`USER_KEY`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`USER_KEY`) BUCKETS 16
PROPERTIES (
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true",
);
Note:
- Enable
light_schema_changeto support JSONB row storage for encoding ColumnID - Enable
store_row_columnto store row storage format
For a primary key-based point query like the one below, after table creation, you can use row storage and short-circuit execution to improve performance to a great extent.
select * from usertable where USER_KEY = xxx;
To further unleash performance, you can apply prepared statement. If you have enough memory space, you can also enable row cache in the BE configuration.
Conclusion
In high-concurrency scenarios, Apache Doris realizes over 30,000 QPS per node after optimizations including row storage, short-circuit, prepared statement, and row cache. Also, Apache Doris is easily scaled out since it is built on MPP architecture, on top of which you can scale it up by upgrading the hardware and machine configuration. This is how Apache Doris manages to achieve both high throughput and high concurrency. It allows you to deal with various data analytic workloads on one single platform and experience quick data analytics for various scenarios. Thanks to the great efforts of the Apache Doris community and a group of excellent SelectDB engineers, Apache Doris 2.0 is about to be released soon.