
Log analysis: how to digest 15 billion logs per day and keep big queries within 1 second
This data warehousing use case is about scale. The user is one of the world's biggest telecommunication service providers. Using Apache Doris, they deploy multiple petabyte-scale clusters on dozens of machines to support their 15 billion daily log additions from their over 30 business lines. Such a gigantic log analysis system is part of their cybersecurity management. For the need of real-time monitoring, threat tracing, and alerting, they require a log analytic system that can automatically collect, store, analyze, and visualize logs and event records.
From an architectural perspective, the system should be able to undertake real-time analysis of various formats of logs, and of course, be scalable to support the huge and ever-enlarging data size. The rest of this post is about what their log processing architecture looks like, and how they realize stable data ingestion, low-cost storage, and quick queries with it.
System Architecture
This is an overview of their data pipeline. The logs are collected into the data warehouse, and go through several layers of processing.
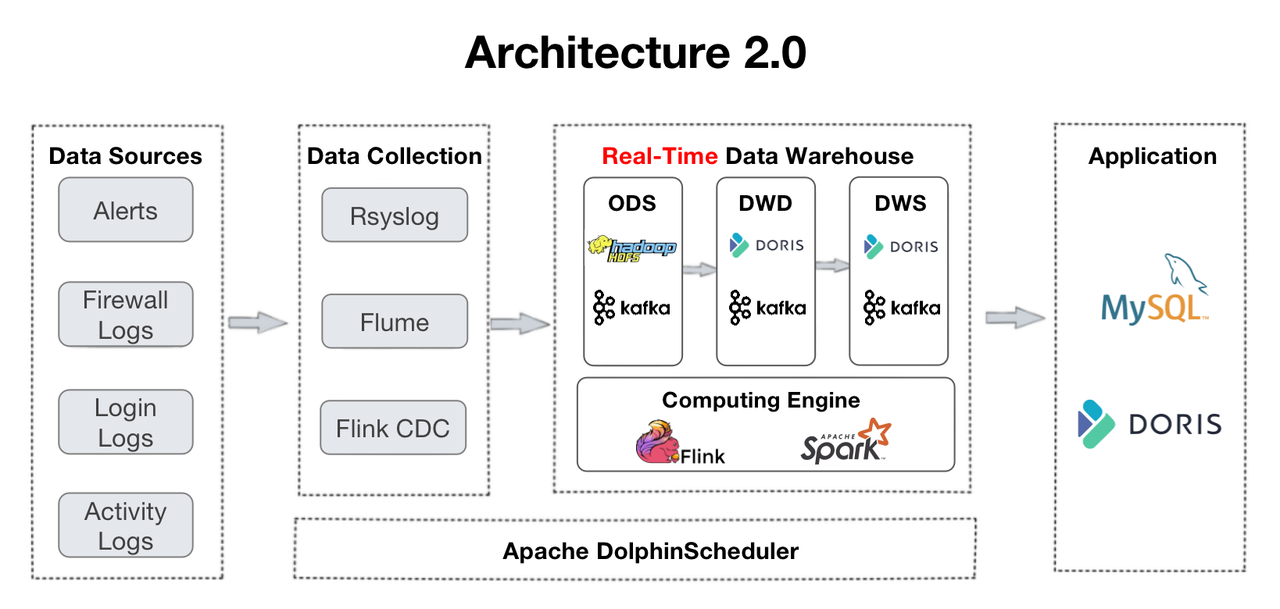
- ODS: Original logs and alerts from all sources are gathered into Apache Kafka. Meanwhile, a copy of them will be stored in HDFS for data verification or replay.
- DWD: This is where the fact tables are. Apache Flink cleans, standardizes, backfills, and de-identifies the data, and write it back to Kafka. These fact tables will also be put into Apache Doris, so that Doris can trace a certain item or use them for dashboarding and reporting. As logs are not averse to duplication, the fact tables will be arranged in the Duplicate Key model of Apache Doris.
- DWS: This layer aggregates data from DWD and lays the foundation for queries and analysis.
- ADS: In this layer, Apache Doris auto-aggregates data with its Aggregate Key model, and auto-updates data with its Unique Key model.
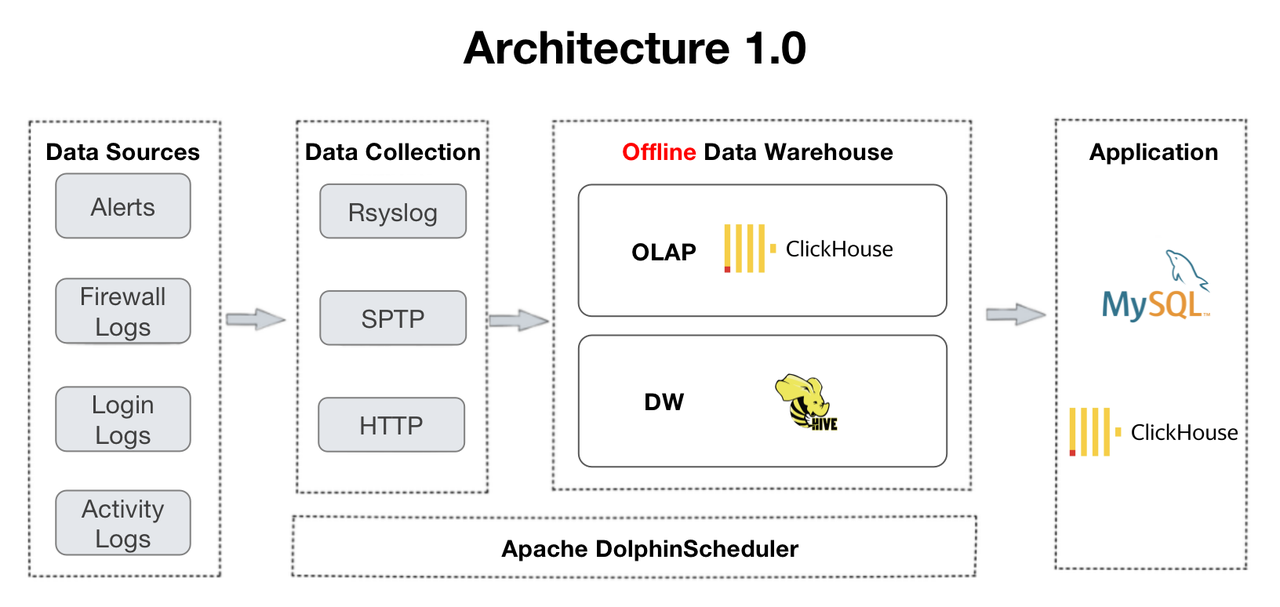
Architecture 2.0 evolves from Architecture 1.0, which is supported by ClickHouse and Apache Hive. The transition arised from the user's needs for real-time data processing and multi-table join queries. In their experience with ClickHouse, they found inadequate support for concurrency and multi-table joins, manifested by frequent timeouts in dashboarding and OOM errors in distributed joins.
Now let's take a look at their practice in data ingestion, storage, and queries with Architecture 2.0.
Real-Case Practice
Stable ingestion of 15 billion logs per day
In the user's case, their business churns out 15 billion logs every day. Ingesting such data volume quickly and stably is a real problem. With Apache Doris, the recommended way is to use the Flink-Doris-Connector. It is developed by the Apache Doris community for large-scale data writing. The component requires simple configuration. It implements Stream Load and can reach a writing speed of 200,000~300,000 logs per second, without interrupting the data analytic workloads.
A lesson learned is that when using Flink for high-frequency writing, you need to find the right parameter configuration for your case to avoid data version accumulation. In this case, the user made the following optimizations:
- Flink Checkpoint: They increase the checkpoint interval from 15s to 60s to reduce writing frequency and the number of transactions processed by Doris per unit of time. This can relieve data writing pressure and avoid generating too many data versions.
- Data Pre-Aggregation: For data of the same ID but comes from various tables, Flink will pre-aggregate it based on the primary key ID and create a flat table, in order to avoid excessive resource consumption caused by multi-source data writing.
- Doris Compaction: The trick here includes finding the right Doris backend (BE) parameters to allocate the right amount of CPU resources for data compaction, setting the appropriate number of data partitions, buckets, and replicas (too much data tablets will bring huge overheads), and dialing up
max_tablet_version_numto avoid version accumulation.
These measures together ensure daily ingestion stability. The user has witnessed stable performance and low compaction score in Doris backend. In addition, the combination of data pre-processing in Flink and the Unique Key model in Doris can ensure quicker data updates.
Storage strategies to reduce costs by 50%
The size and generation rate of logs also impose pressure on storage. Among the immense log data, only a part of it is of high informational value, so storage should be differentiated. The user has three storage strategies to reduce costs.
- ZSTD (ZStandard) compression algorithm: For tables larger than 1TB, specify the compression method as "ZSTD" upon table creation, it will realize a compression ratio of 10:1.
- Tiered storage of hot and cold data: This is supported by the new feature of Doris. The user sets a data "cooldown" period of 7 days. That means data from the past 7 days (namely, hot data) will be stored in SSD. As time goes by, hot data "cools down" (getting older than 7 days), it will be automatically moved to HDD, which is less expensive. As data gets even "colder", it will be moved to object storage for much lower storage costs. Plus, in object storage, data will be stored with only one copy instead of three. This further cuts down costs and the overheads brought by redundant storage.
- Differentiated replica numbers for different data partitions: The user has partitioned their data by time range. The principle is to have more replicas for newer data partitions and less for the older ones. In their case, data from the past 3 months is frequently accessed, so they have 2 replicas for this partition. Data that is 3~6 months old has two replicas, and data from 6 months ago has one single copy.
With these three strategies, the user has reduced their storage costs by 50%.
Differentiated query strategies based on data size
Some logs must be immediately traced and located, such as those of abnormal events or failures. To ensure real-time response to these queries, the user has different query strategies for different data sizes:
- Less than 100G: The user utilizes the dynamic partitioning feature of Doris. Small tables will be partitioned by date and large tables will be partitioned by hour. This can avoid data skew. To further ensure balance of data within a partition, they use the snowflake ID as the bucketing field. They also set a starting offset of 20 days, which means data of the recent 20 days will be kept. In this way, they find the balance point between data backlog and analytic needs.
- 100G~1T: These tables have their materialized views, which are the pre-computed result sets stored in Doris. Thus, queries on these tables will be much faster and less resource-consuming. The DDL syntax of materialized views in Doris is the same as those in PostgreSQL and Oracle.
- More than 100T: These tables are put into the Aggregate Key model of Apache Doris and pre-aggregate them. In this way, we enable queries of 2 billion log records to be done in 1~2s.
These strategies have shortened the response time of queries. For example, a query of a specific data item used to take minutes, but now it can be finished in milliseconds. In addition, for big tables that contain 10 billion data records, queries on different dimensions can all be done in a few seconds.
Ongoing Plans
The user is now testing with the newly added inverted index in Apache Doris. It is designed to speed up full-text search of strings as well as equivalence and range queries of numerics and datetime. They have also provided their valuable feedback about the auto-bucketing logic in Doris: Currently, Doris decides the number of buckets for a partition based on the data size of the previous partition. The problem for the user is, most of their new data comes in during daytime, but little at nights. So in their case, Doris creates too many buckets for night data but too few in daylight, which is the opposite of what they need. They hope to add a new auto-bucketing logic, where the reference for Doris to decide the number of buckets is the data size and distribution of the previous day. They've come to the Apache Doris community and we are now working on this optimization.