Apache Doris helped Netease create a refined operation DMP system

Guide: Refined operation is a trend of the future Internet, which requires excellent data analysis. In this article, you will get knowledge of: the construction of Netease Lifease's DMP system and the application of Apache Doris.
Author | Xiaodong Liu, Lead Developer, Netease
Better data analysis enables users to get better experience. Currently, the normal analysis method is to build a user tags system to accurately generate user portraits and improve user experience. The topic we shared today is the practice of Netease DMP tags system.
About Netease and Lifease
NetEase (NASDAQ: NTES) is a leading Internet technology company in China, providing users with free emails, gaming, search engine services, news and entertainment, sports, e-commerce and other services.
Lifease is Netease's self-operated home furnishing e-commerce brand. Its products cover 8 categories in total: home life, apparel, food and beverages, personal care and cleaning, baby products, outdoor sport, digital home appliances, and Lifease's Special. In Q1 of 2022, Lifease launches "Pro " membership and other multiple memberships for different users. The number of Pro members has increased by 65% compared with the previous year.
About the DMP System
DMP system plays an important role in Lifease's data analysis. The data sources of DMP mainly include:
- Business logs of APPs, H5s, PCs and other terminals
- Basic data constructed within NetEase Group
- Data from products sold by third-party such as JD.com, Alibaba, and Bytedance Through data collection and data cleaning, the above data is ingested into data assets. Based on these data, DMP has created a system of functions, such as tag creation, grouping and portrait analysis, which supports the business including: intelligent product matching, user engagement, and user insight. In general, the DMP system concentrates on building a data-centric tagging system and portrait system to assist the business.
You can get basic knowledge of the DMP system starting from the concepts below:
- Tagging: Tagging is one of the user monitoring abilities to uniquely identify individual users across different browsers, devices, and user sessions. This approach to user tagging works by capturing available data in your application's page source: age, address, preference and other variables.
- Targeting: Target audience may be dictated by age, gender, income, location, interests or a myriad of other factors.
- User Portrait Analysis: User portrait analysis is to develop user profiles, actions and attributes after targeting audience. For instance, check the behavior paths and consumption models of users whose portraits are "City: Hangzhou, Gender: Female" on Lifease APP.
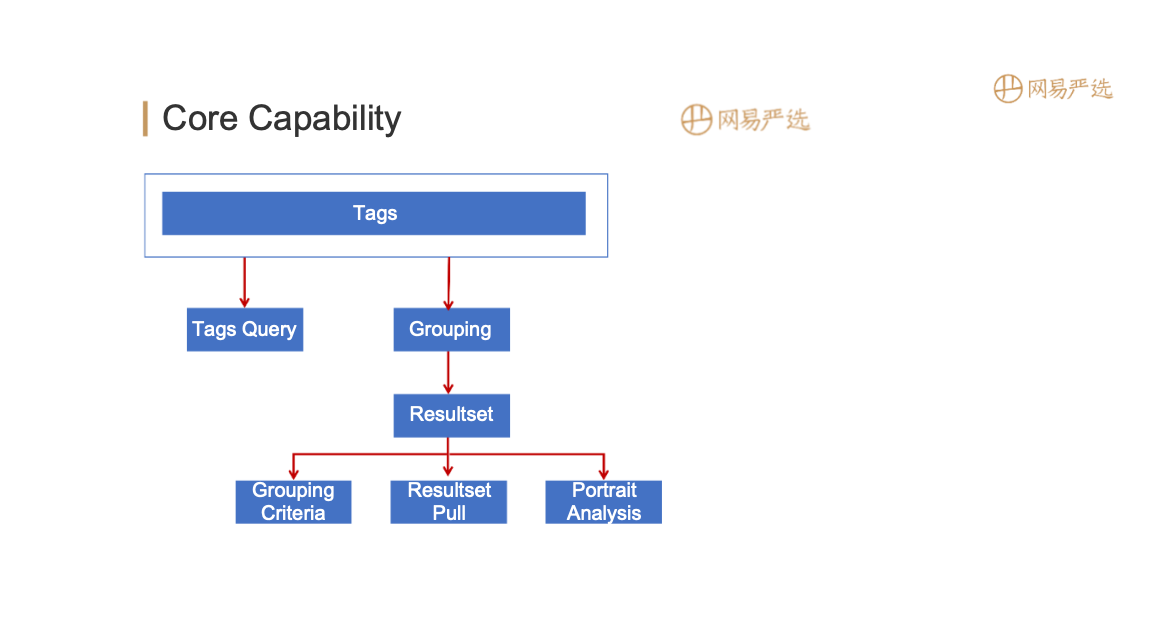
Llifease's tagging system mainly provides two core capabilities:
- Tag Query: the ability to query the specified tag of a specific entity, which is often used to display basic information.
- Targeting Audience: for both real-time and offline targets. Result after targeting is mainly used for:
- As Grouping Criteria: It can be used to tell if the user is in one or more specified groups. This occasionally occurs in scenarios such as advertising and contact marketing.
- Resultset Pull: Extract specified data to business system for customized development.
- Portrait Analysis: Analyze the behavioral and consumption models in specific groups of people for more refined operations.
The overall business process is as follows:
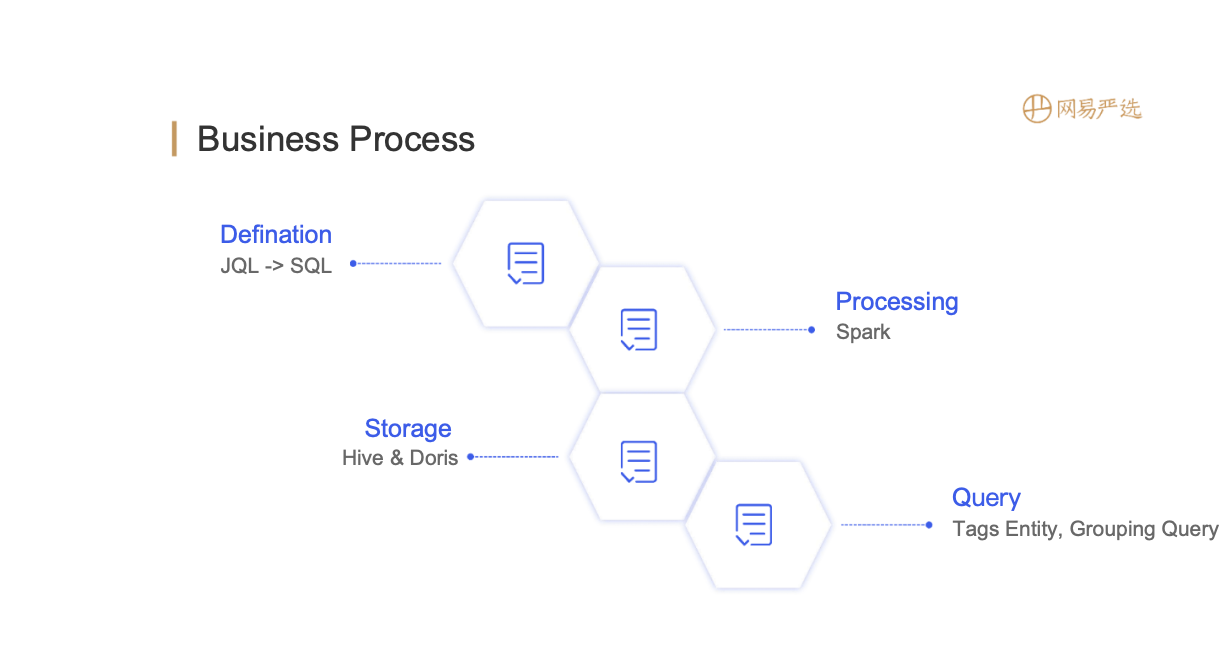
- First define the rules for tags and grouping;
- After defining the DSL, the task can be submitted to Spark for processing;
- After the processing is done, the results can be stored in Hive and Doris;
- Data from Hive or Doris can be queried and used according to the actual business needs.
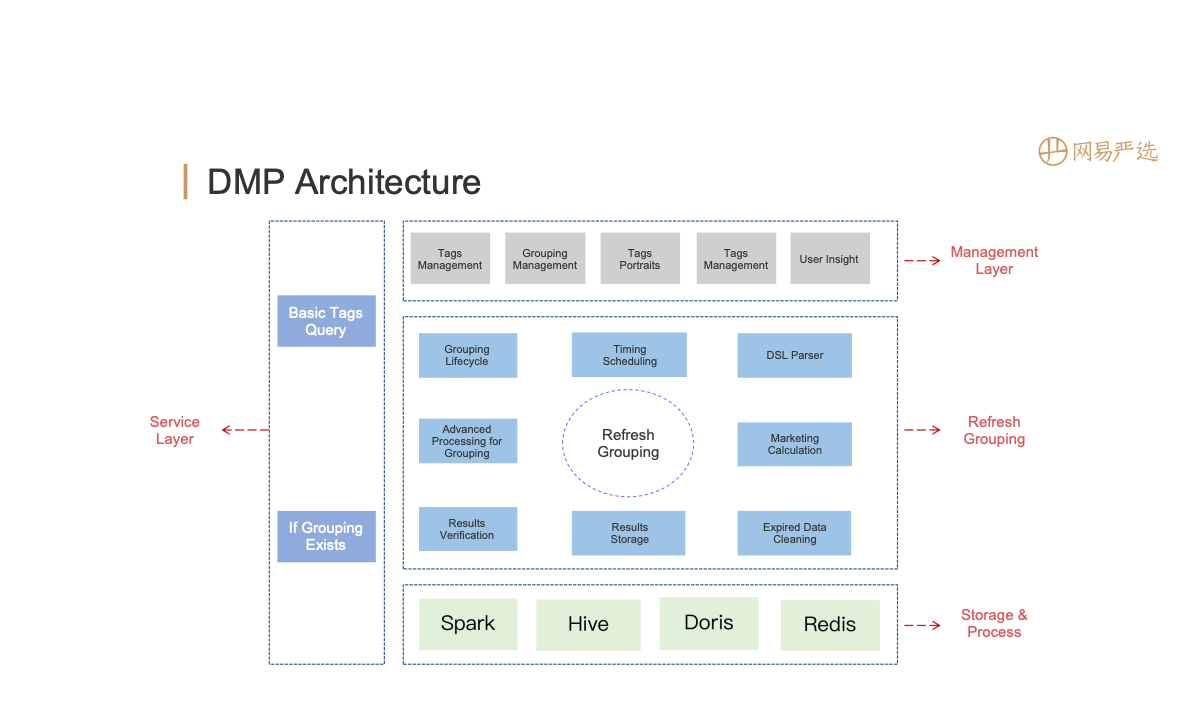
The DMP platform is divided into four modules: Processing&storage layer, scheduling layer, service layer, and metadata management. All tag meta-information is stored in the source data table; The scheduling layer schedules tasks for the entire business process: Data processing and aggregation are converted into basic tags, and the data in the basic tags and source tables are converted into something that can be used for data query through SQL; The scheduling layer dispatches tasks to Spark to process, and then stores results in both Hive and Doris. The service layer consists of four parts: tag service, entity grouping service, basic tag data service, and portrait analysis service.
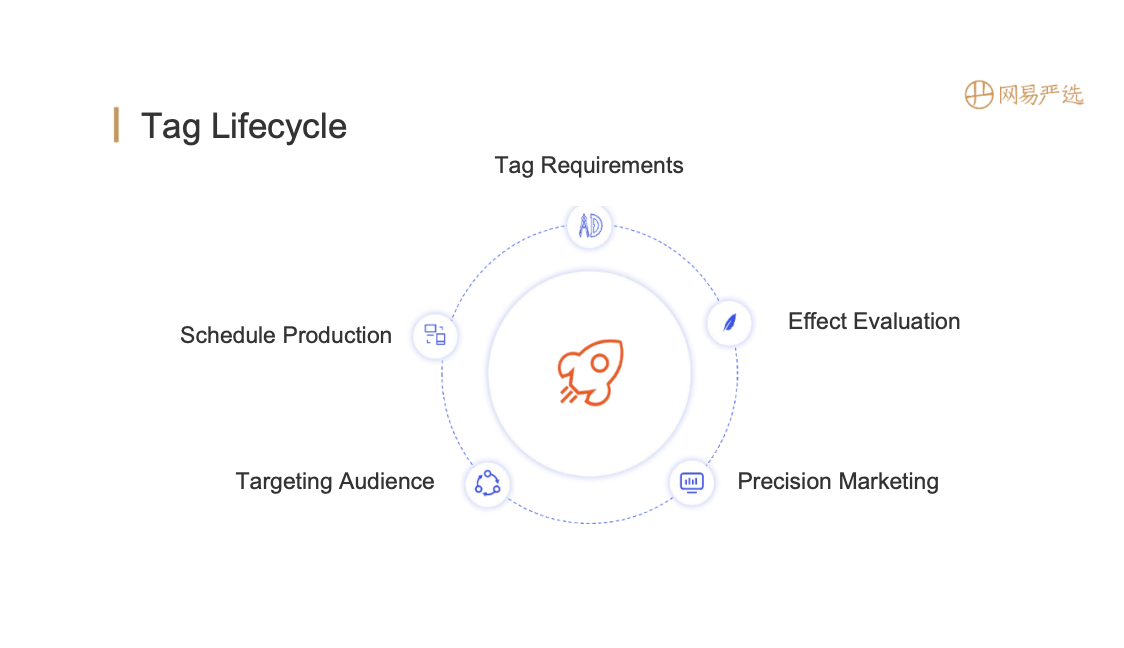
The lifecycle of tag consists of 5 phases:
- Tag requirements: At this stage, the operation team demands and the product manager team evaluates the rationality and urgency of the requirements.
- Scheduling production: Developers first sort out the data from ODS to DWD, which is the entire link of DM layer. Secondly, they build a model based on data, and at the same time, monitor the production process.
- Targeting Audience: After the tag is produced, group the audience by those tags.
- Precision marketing: Carry out precision marketing strategy to people grouped by.
- Effect evaluation: In the end, tage usage rate and use effect need to be evaluated for future optimization.
Production of Tags
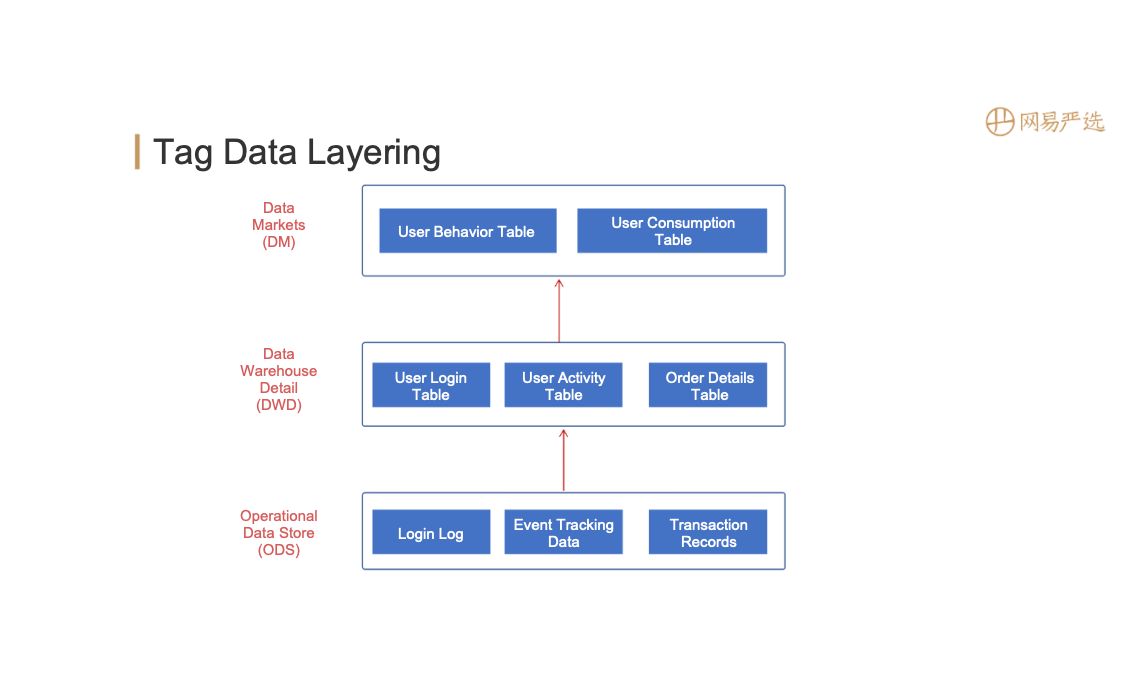
Tag data layering:
- The bottom layer is the ODS layer, including user login logs, event tracking records, transaction data, and Binlog data of various databases
- The data processed by the ODS layer, such as user login table, user activity table and order information table reaches the DWD detail layer
- The DWD layer data is aggregated to the DM layer and the tags are all implemented based on the DM layer data. At present, we have fully automated the data output from the original database to the ODS layer. And we also realized partial automation from the ODS layer to the DWD layer. And there are a small number of automated operations from the DWD to the DM layer, which will be our focus in the future.
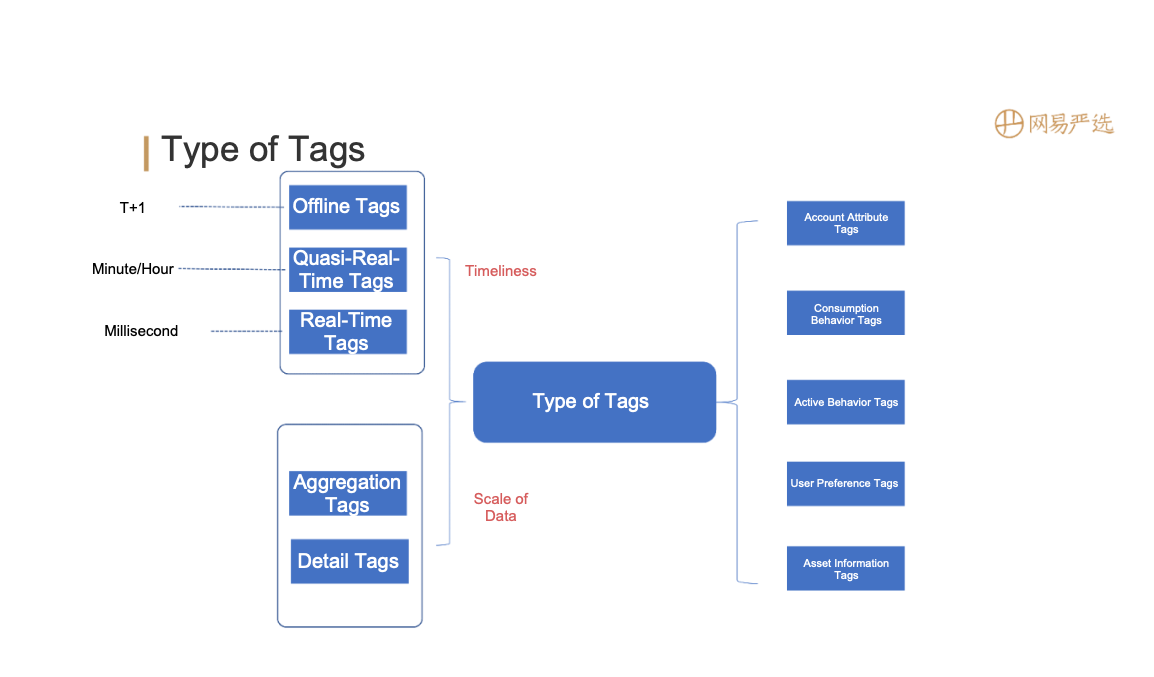
Tags are devided based on timeliness: offline tags, quasi-real-time tags and real-time tags. According to the scale of data, it is divided into: aggregation tags and detail tags. In other cases, tags can also be divided into: account attribute tags, consumption behavior tags, active behavior tags, user preference tags, asset information tags, etc.

It is inconvenient to use the data of the DM layer directly because the basic data is relatively primitive. The abstraction level is lacking and it is not easy to use. By combining basic data with AND, OR, and NOT, business tags are formed for further use, which can reduce the cost of understanding operations and make it easier to use.

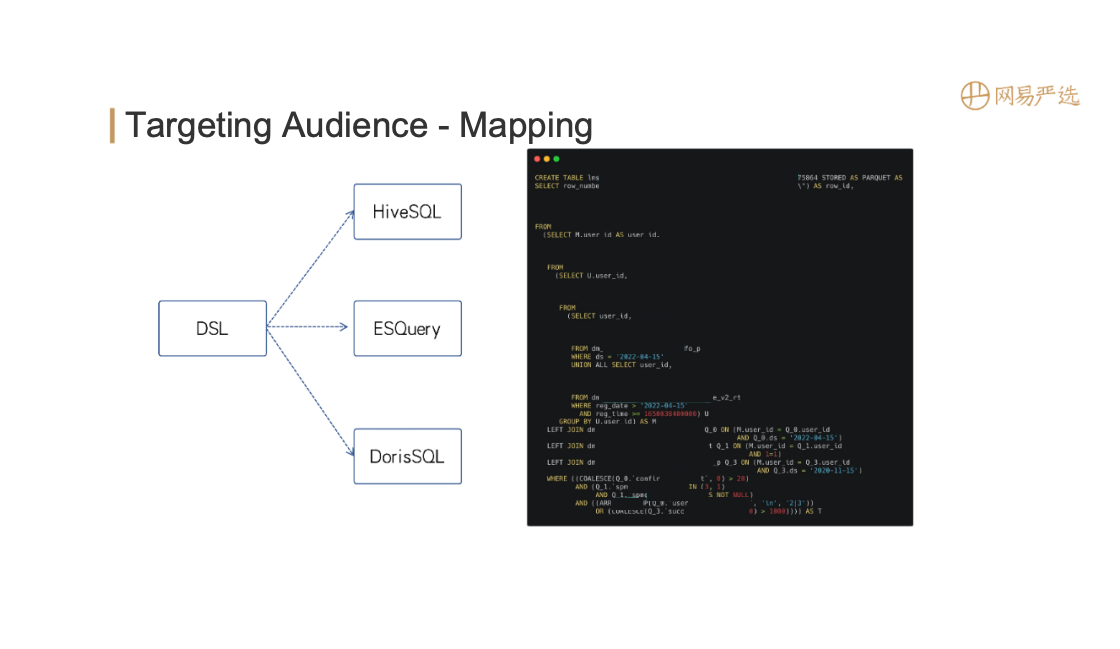
After the tags are merged, it is necessary to apply the tags to specific business scenarios, such as grouping. The configuration is shown on the left side of the figure above, which supports offline crowd packages and real-time behaviors (need to be configured separately). After configuration, generate the DSL rules shown on the right side of the figure above, expressed in Json format, which is more friendly to FE, and can also be converted into query statements of the datebase engine.
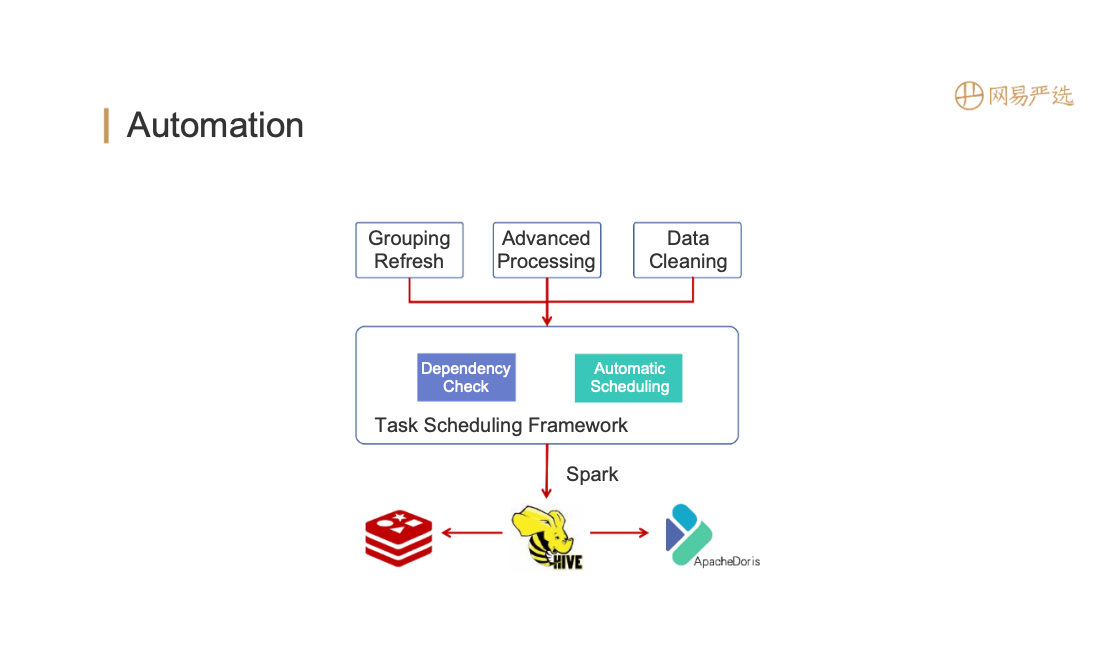
Tagging is partially automated. The degree of automation in grouping is relatively high. For example, group refresh can be done regularly every day; Advanced processing, such as intersection/merge/difference between groups; Data cleaning means timely cleaning up expired and invalid data.
Tags Storage
Lifease's DMP labeling system needs to carry relatively large customer end traffic, and has relatively high requirements for real-time performance. Our storage requirements include:
- Need support high-performance query to deal with large-scale customer end traffic
- Need support SQL to facilitate data analysis scenarios
- Need support data update mechanism
- Can store large amount of data
- Need support for extension functions to handle custom data structures
- Closely integrated with big data ecology
In the field of big data, multiple engines vary in different applicable scenarios. We used the popular engines in the chart below to optimize our database architecture for 2 times.
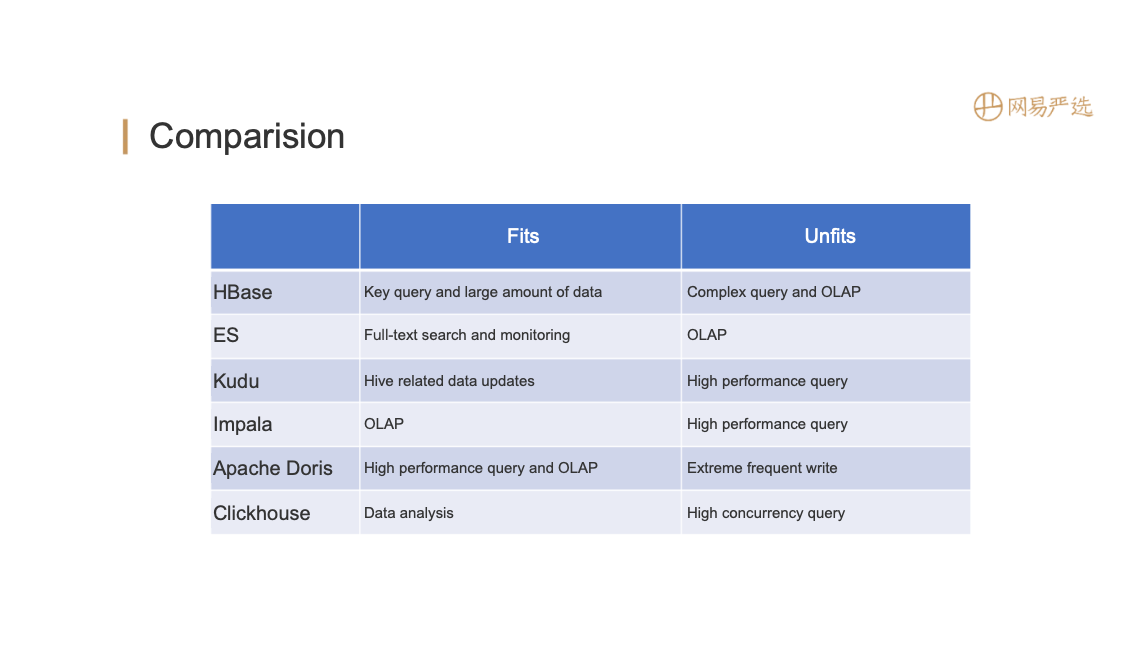
Our architecture V1.0 is shown below:
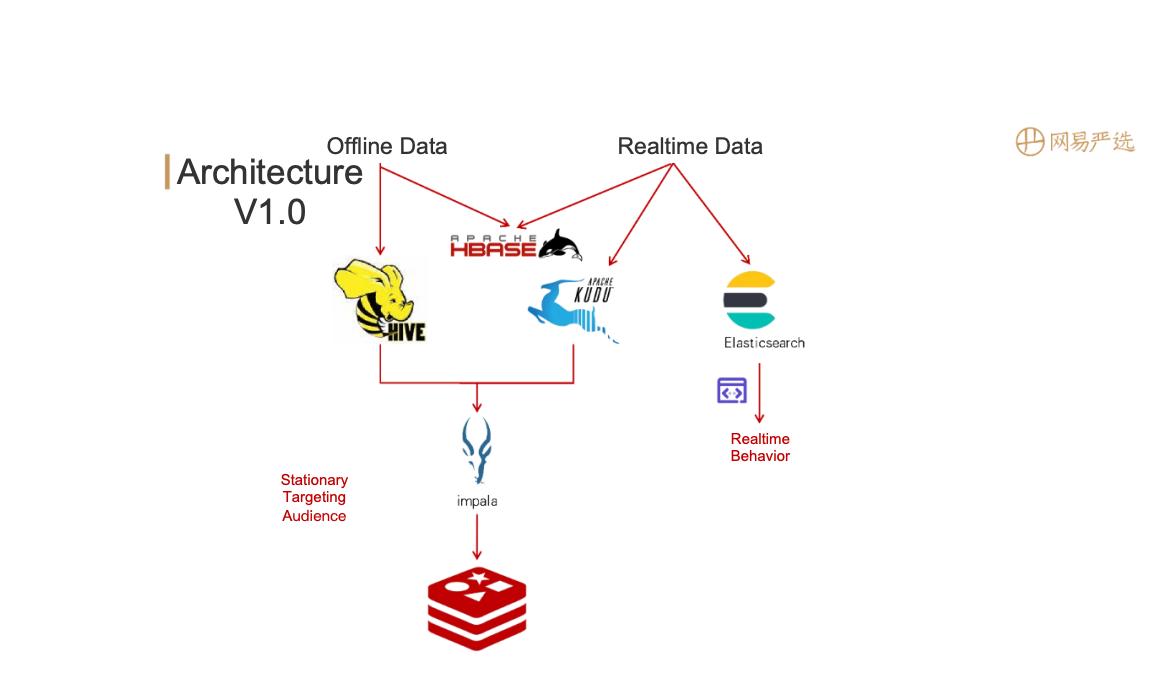
Most of the offline data is stored in Hive while a small part is stored in Hbase (mainly used for querying basic tags). Part of the real-time data is stored in Hbase for basic tags query and the rest is double-written into KUDU and Elasticsearch for real-time grouping and data query. The data offline is processed by Impala and cached in Redis. Disadvantages :
- Too many database engines.
- Double writing has hidden problems with data quality. One side may succeed while the other side fails, resulting in data inconsistency.
- The project is complex and maintainability is poor. In order to reduce the usage of engine and storage, we improved and implemented version 2.0 :
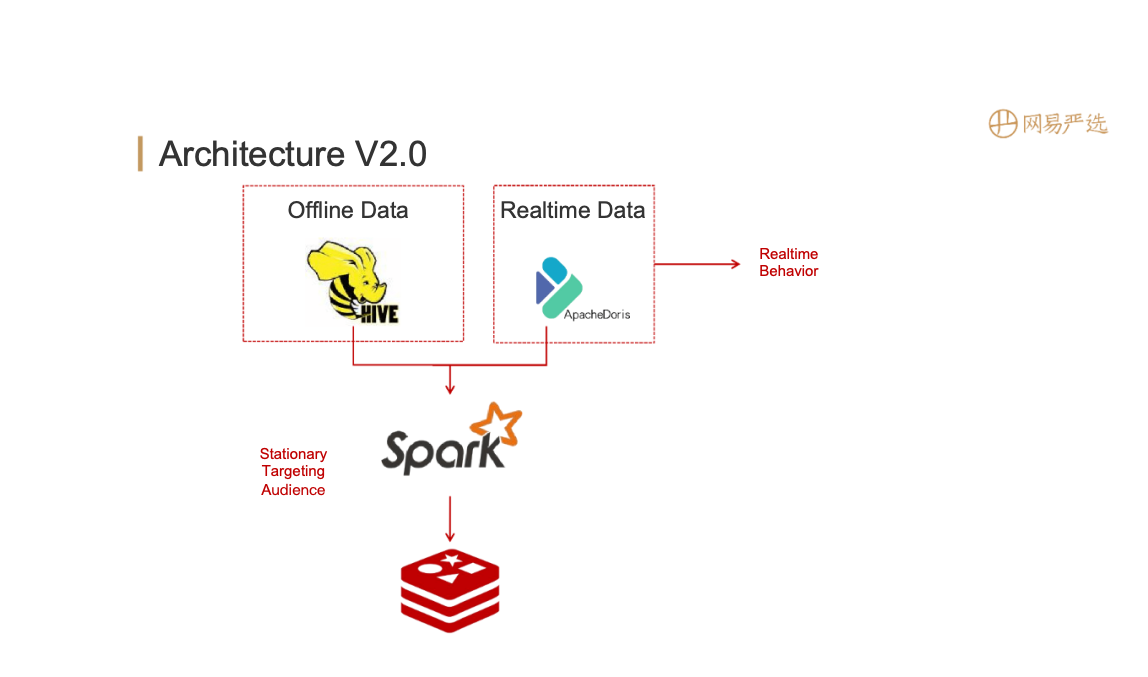
In storage architecture V2.0, Apache Doris is adopted. Offline data is mainly stored in Hive. At the same time, basic tags are imported into Doris, and real-time data as well. The query federation of Hive and Doris is performed based on Spark, and the results are stored in Redis. After this improvement, an storage engine which can manages offline and real-time data has been created. We are currently use Apache Doris 1.0, which enables : 1. The query performance can be controlled within 20ms at 99% 2. The query performance can be controlled within 50ms at 99.9%. Now the architecture is simplified, which greatly reduces operation and maintenance costs.
Advantages of Apache Doris in Practice
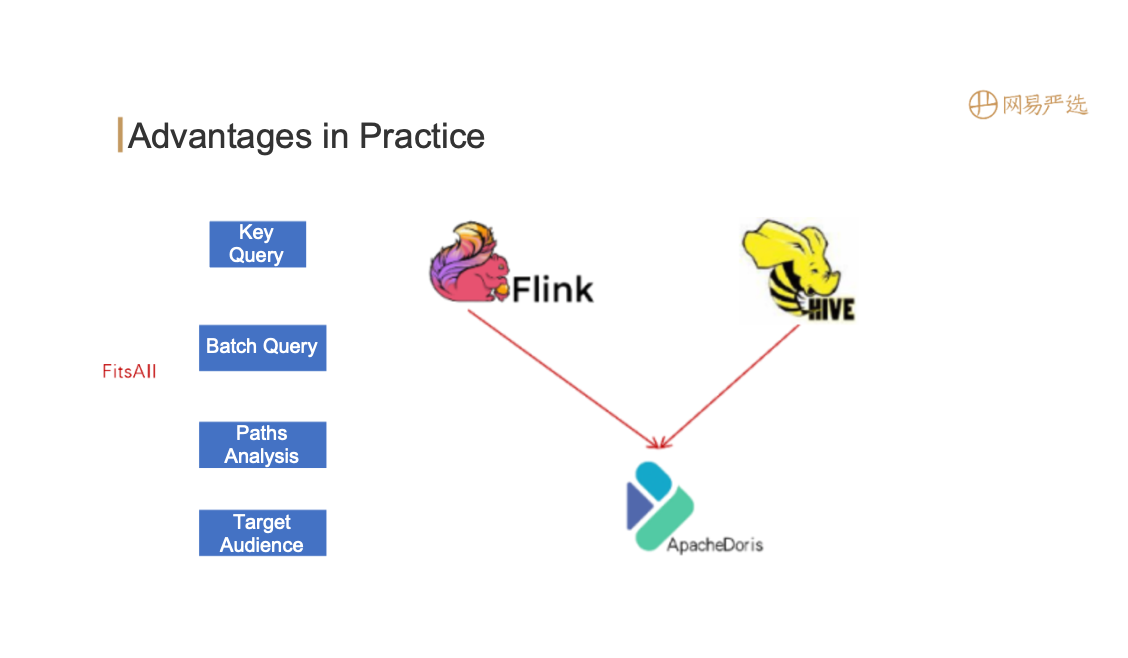
Lifeuse has adopted Apache Doris to check, batch query, path analyse and grouping. The advantages are as follows:
- The query federation performance of key query and a small number of tables exceeds 10,000 QPS, with RT99<50MS.
- The horizontal expansion capability is relatively strong and maintenance cost is relatively low.
- The offlin and real-time data are unified to reduce the complexity of the tags model.
The downside is that importing a large amount of small data takes up more resources. But this problem has been optimized in Doris 1.1. Apache Doris has greatly enhanced the data compaction capability in version 1.1, and can quickly complete aggregation of new data, avoiding the -235 error caused by too many versions of sharded data and the low query efficiency problems.
Future Plan
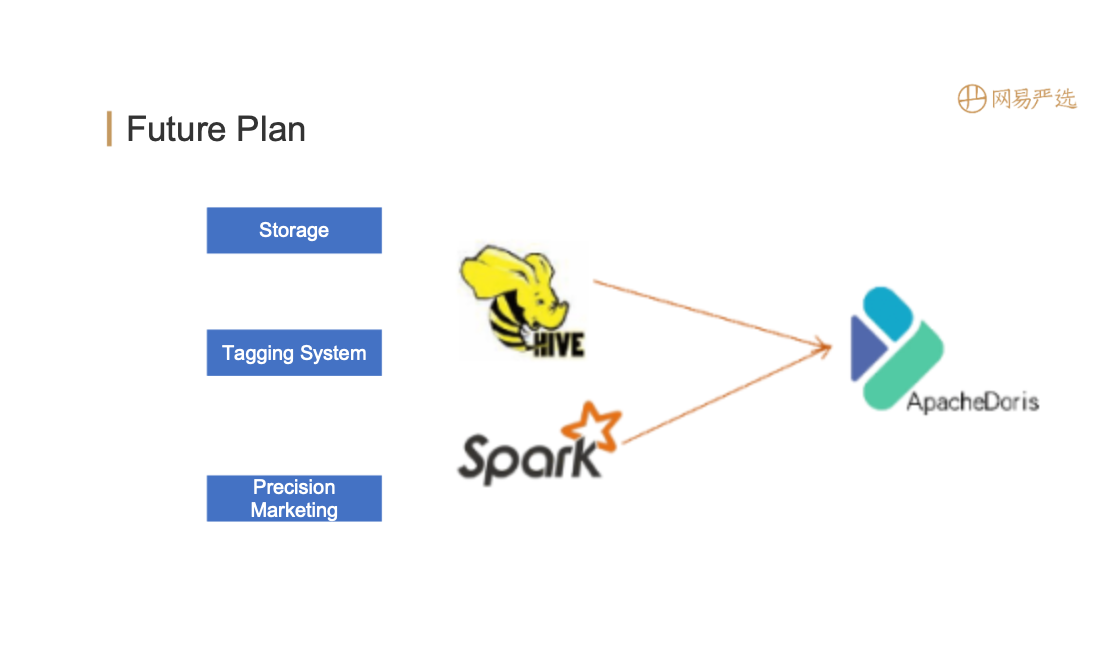
Hive and Spark are gradually turning into Apache Doris. Optimize the tagging system:
- Establish a rich and accurate tag evaluation system
- Improve tag quality and output speed
- Improve tag coverage More precision operation:
- Build a rich user analysis model
- Improve the user insight model evaluation system based on the frequency of use and user value
- Establish general image analysis capabilities to assist intelligent decision-making in operations