How does Apache Doris help AISPEECH build a data warehouse in AI chatbots scenario

Guide: In 2019, AISPEACH built a real-time and offline datawarehouse based on Apache Doris. Reling on its flexible query model, extremely low maintenance costs, high development efficiency, and excellent query performance, Apache Doris has been used in many business scenarios such as real-time business operations, AI chatbots analysis. It meets various data analysis needs such as device portrait/user label, real-time operation, data dashboard, self-service BI and financial reconciliation. And now I will share our experience through this article.
Author|Zhao Wei, Head Developer of AISPEACH's Big Data Departpment
Backgounds
AISPEACH is a professional conversational artificial intelligence company in China. It has full-link intelligent voice and language technology. It is committed to becoming a platform-based enterprise for full-link intelligent voice and language interaction. Recently it has developed a new generation of human-computer interaction platform DUI and artificial intelligence chip TH1520, providing natural language interaction solutions for partners in many industry scenarios such as Internet of Vehicles, IoT, government affairs and fintech.
Aspire introduced Apache Doris for the first time in 2019 and built a real-time and offline data warehouse based on Apache Doris. Compared with the previous architecture, Apache Doris has many advantages such as flexible query model, extremely low maintenance cost, high development efficiency and excellent query performance. Multiple business scenarios have been applied to meet various data analysis needs such as device portraits/user tags, real-time operation of business scenarios, data analysis dashboards, self-service BI, and financial reconciliation.
Architecture Evolution
Offline data analysis in the early business was our main requirement. Recently, with the continuous development of business, the requirements for real-time data analysis in business scenarios have become higher and higher. The early datawarehouse architecture failed to meet our requirements. In order to meet the higher requirements of business scenarios for query performance, response time, and concurrency capabilities, Apache Doris was officially introduced in 2019 to build a real-time and offline integrated datawarehouse architecture.
In the following I will introduce the evolution of the AISPEACH Data Warehouse architecture, and share the reasons why we chose Apache Doris to build a new architecture.
Early Data Warehouse Architecture
As shown in the architecture diagram below, the offline data warehouse is based on Hive + Kylin while the real-time data warehouse is based on Spark + MySQL.
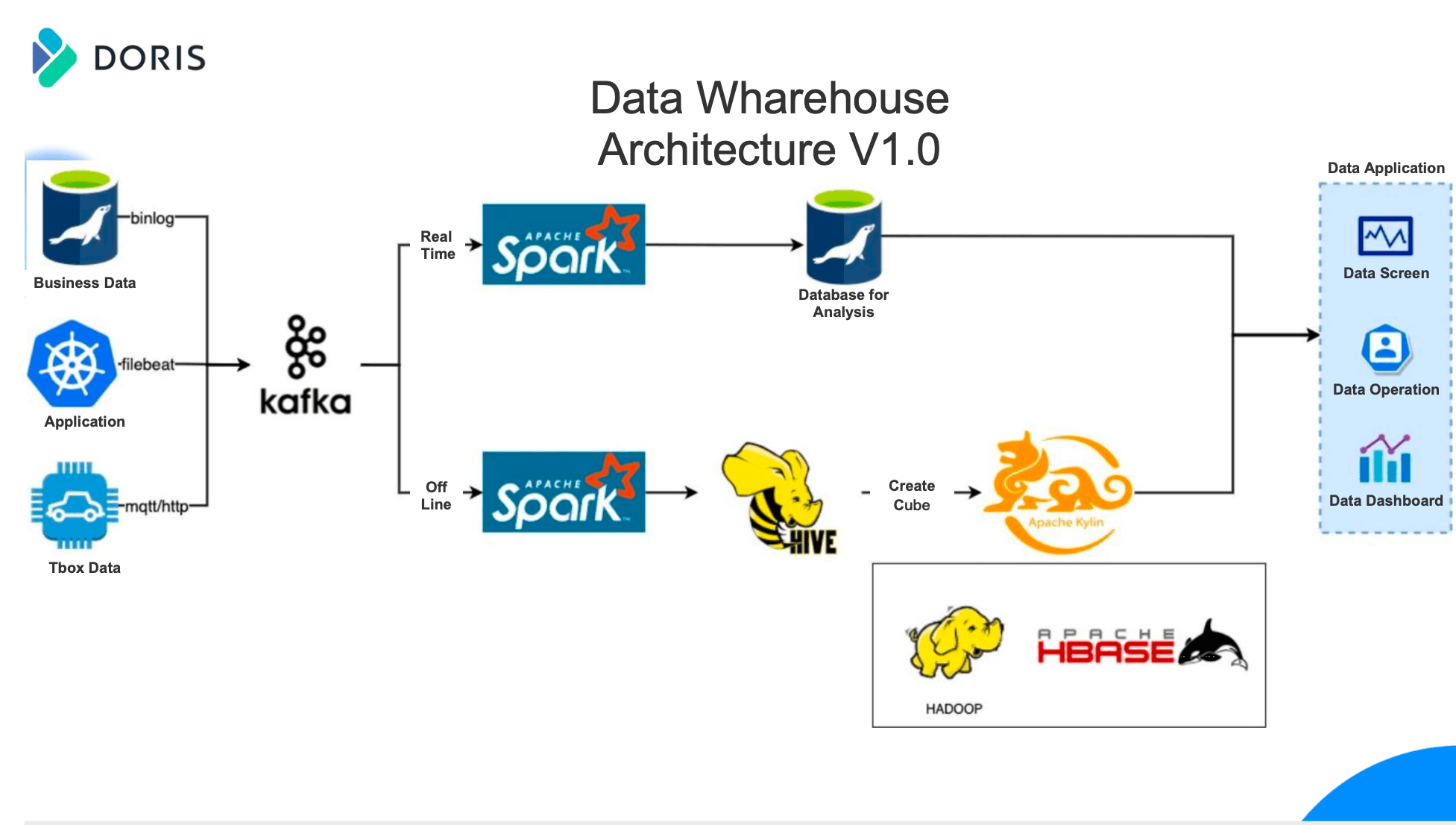
There are three main types of data sources in our business, business databases such as MySQL, application systems such as K8s container service logs, and logs of automotive T-Box. Data sources are first written to Kafka through various methods such as MQTT/HTTP protocol, business database Binlog, and Filebeat log collection. In the early time, the data will be divided into real-time and offline links after passing through Kafka. Real-time part has a shorter link. The data buffered by Kafka is processed by Spark and put into MySQL for further analysis. MySQL can basically meet the early analysis requirements. After data cleaning and processing by Spark, an offline datawarehouse is built in Hive, and Apache Kylin is used to build Cube. Before building Cube, it is necessary to design the data model in advance, including association tables, dimension tables, index fields, and aggregation functions. After construction through the scheduling system, we can finally use HBase to store the Cube.
Pain Points of Early Architecture:
-
There are many dependent components. Kylin strongly relies on Hadoop and HBase in versions 2.x and 3.x. The large number of application components leads to low development efficiency, many hidden dangers of architecture stability, and high maintenance costs.
-
The construction process of Kylin is complicated and the construction task always fail. When we do construction for Kylin, we always need to do the following: widen tables, de-duplicate columns, generate dictionaries, build cubes, etc. If there are 1000-2000 or more tasks per day, at least 10 or more tasks will fail to build, resulting in a lot of time to write automatic operation and maintenance scripts.
-
Dimension/dictionary expansion is heavy. Dimension expansion refers to the need for multiple analysis conditions and fields in some business scenarios. If many fields are selected in the data analysis model without pruning, it will lead to severe cube dimension expansion and longer construction time. Dictionary inflation means that in some scenarios, it takes a long time to do global accurate deduplication, which will make the dictionary construction bigger and bigger, and the construction time will become longer and longer, resulting in a continuous decline in data analysis performance.
-
The data analysis model is fixed and low in flexibility. In the actual application, if a calculation field or business scenario is changed, some or even all of the data needs to be backtracked.
-
Data detail query is not supported. The early data warehouse architecture could not provide detailed data query. The official Kylin solution is to relate to Presto for detailed query, which introduces another architecture and increases development costs.
Architecture Selection
In order to solve the problems above, we began to explore other datawarehouse architecture solutions. And we conducted a series of research on OLAP engines such as Apache Doris and Clickhouse, which are most widely used in the market.
As the original creator, SelectDB provides commercial products based on Apache Doris. With the new Apache Doris, SelectDB is now providing global users with a fully-managed database option for deployment.
Comparing with ClickHouse's heavy maintenance, various table types, and lack of support for associated queries, Apache Doris performed better. And combined with our OLAP analysis scenario, we finally decided to introduce Apache Doris.
New Data Warehouse Architecture
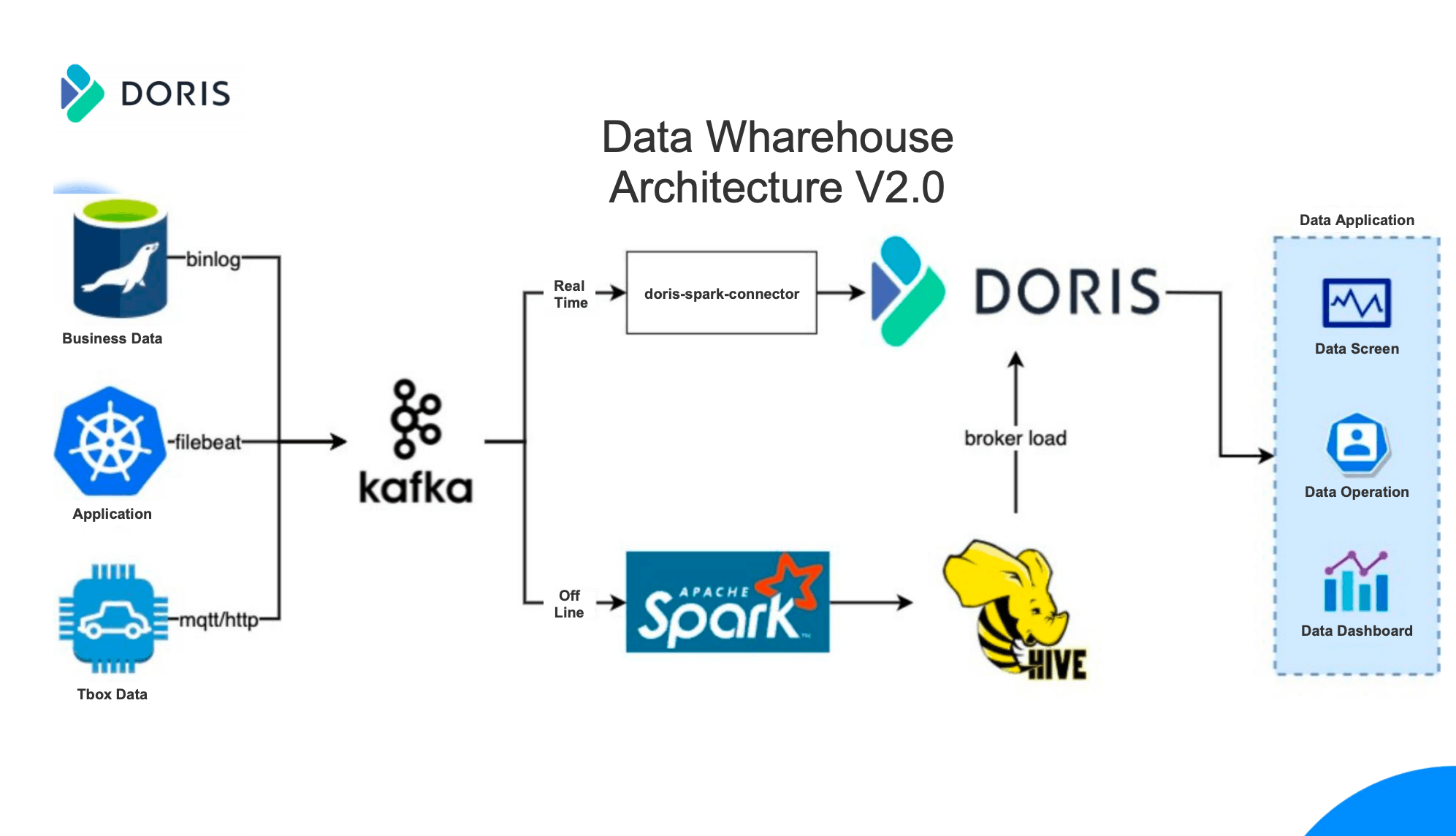
As shown in the figure above, we built a new real-time + offline data warehouse architecture based on Apache Doris. Unlike the previous architecture, real-time and offline data are processed separately and written to Apache Doris for analysis.
Due to some historical reasons, data migration is difficult. The offline data is basically consistent with the previous datawarehouse architecture, and it is entirely possible to directly build an offline data warehouse on Apache Doris.
Comparing with the earlier architecture, the offline data is cleaned and processed by Spark, which is possible to build data warehouse in Hive. Then the data stored in Hive can be written to Apache Doris through Broker Load. What I want to explain here is that the data import speed of Broker Load is very fast and it only takes 10-20 minutes to import 100-200G data into Apache Doris on a daily basis.
When it comes to the real-time data flow, the new architecture uses Doris-Spark-Connector to consume data in Kafka and write it to Apache Doris after simple tasks. As shown in the architecture diagram, real-time and offline data are analyzed and processed in Apache Doris, which meets the business requirements of data applications for both real-time and offline.
Benefits of the New Architecture:
-
Simplified operation, low maintenance cost, and does not depend on Hadoop ecological components. The deployment of Apache Doris is simple. There are only two processes of FE and BE. Both FE and BE processes can be scaled out. A single cluster supports hundreds of machines and tens of PB storage capacity. These two types of processes pass the consistency agreement to ensure high availability of services and high reliability of data. This highly integrated architecture design greatly reduces the operation and maintenance cost of a distributed system. The operation and maintenance time spent in the three years of using Doris is very small. Comparing with the previous architecture based on Kylin, the new architecture spends little time on operation and maintenance.
-
The difficulty of developing and troubleshooting problems is greatly reduced. The real-time and offline unified data warehouse based on Doris supports real-time data services, interactive data analysis, and offline data processing scenarios, which greatly reduces the difficulty of troubleshooting.
-
Apache Doris supports JOIN query in Runtime format. Runtime is similar to MySQL's table association, which is friendly to the scene where the data analysis model changes frequently, and solves the problem of low flexibility in the early structured data model.
-
Apache Doris supports JOIN, aggregation, and detailed query at the same time. Meanwhile, it solves the problem that data details could not be queried in the previous architecture.
-
Apache Doris supports multiple accelerated query methods. And it also supports rollup index, materialized view, and implements secondary index through rollup index to speed up query, which greatly improves query response time.
-
Apache Doris supports multiple types of Query Federation. And it supports Federation Query analysis on data lakes such as Hive, Iceberg, and Hudi, and also databases such as MySQL and Elasticsearch.
Applications
Apache Doris was first applied in real-time business and AI Chatbots analysis scenarios in AISPEACH. This chapter will introduce the requirements and applications of the two scenarios.
Real-time Business
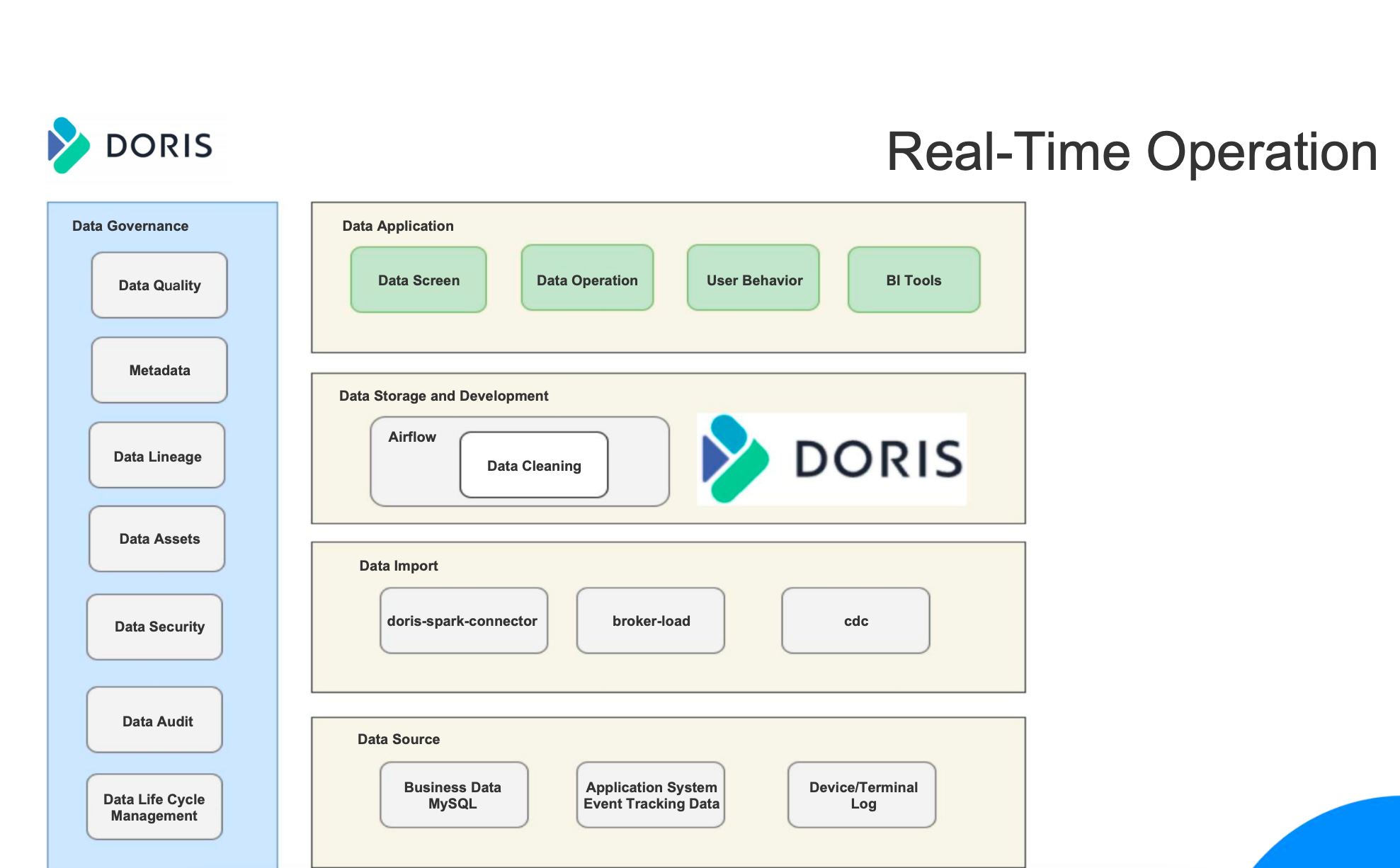
As shown in the figure above, the technical architecture of the real-time operation business is basically the same as the new version of the data warehouse architecture mentioned above:
-
Data Source: The data source is consistent in the new version with the architecture diagram in the new version, including business data in MySQL, event tracking data of the application system, device and terminal logs.
-
Data Import: Broker Load is used for offline data import, and Doris-Spark-Connector is used for real-time data import.
-
Data Storage and Development: Almost all real-time data warehouses are built on Apache Doris, and some offline data is placed on Airflow to perform DAG batch tasks.
-
Data Application: The top layer is the business analysis requirements, including large-screen display, real-time dashboard for data operation, user portrait, BI tools, etc.
In real-time operation business, there are two main requirements for data analysis:
-
Due to the large amount of real-time imported data, the query efficiency requirement is high.
-
In this scenario, a team of 20+ people is in charge. The data operation dashboard needs to be opened at the same time, so there will be relatively high requirements for real-time writing performance and query concurrency.
AI Chatbots Analysis
In addition, the second application of Apache Doris in AISPEACG is a AI Chatbots analysis.
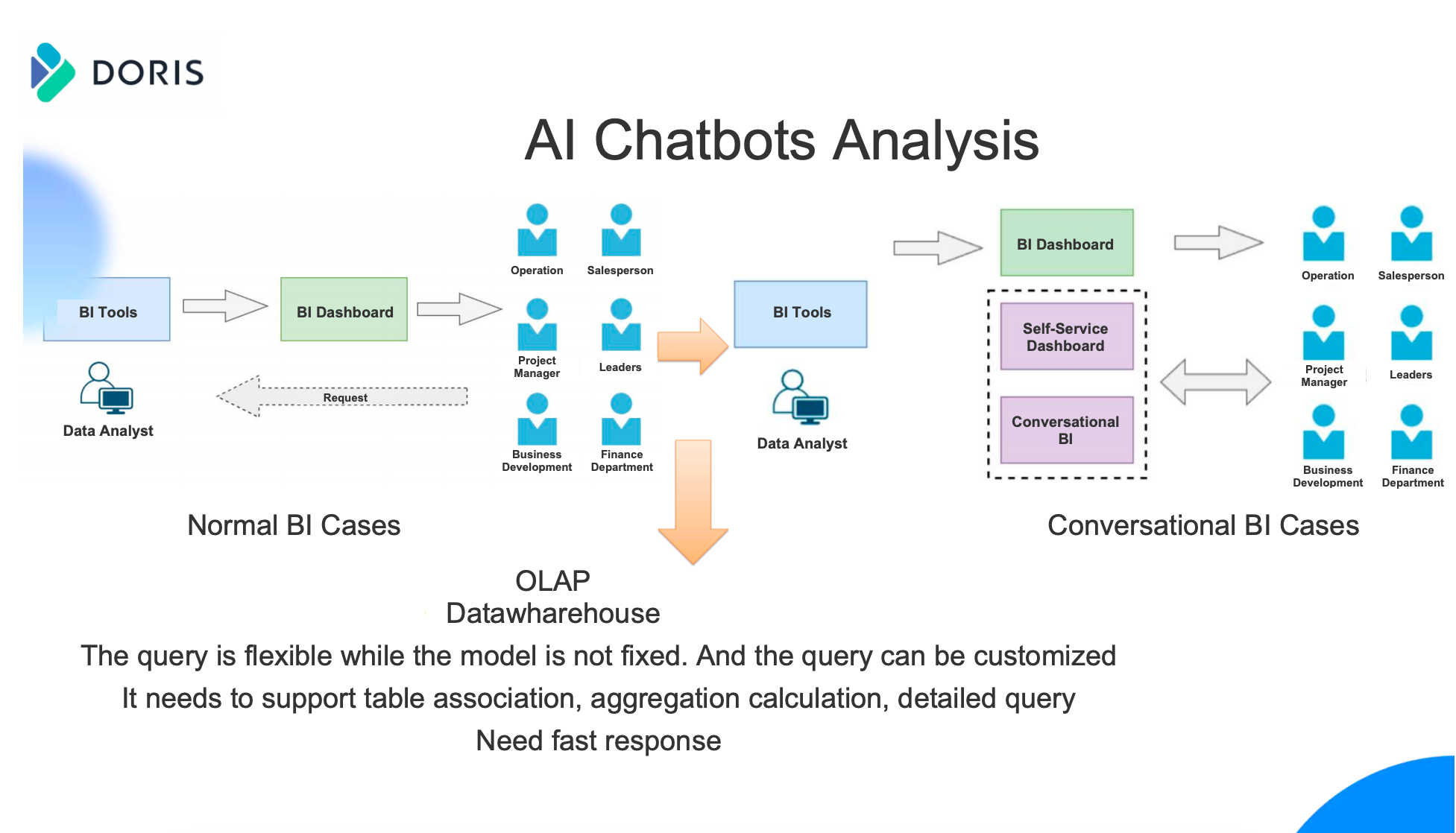
As shown in the figure above, different from normal BI cases, our users only needs to describe the data analysis needs by typing. Based on our company's NLP capabilities, AI Chatbots BI will convert natural language into SQL, which similar to NL2SQL technology. It should be noted that the natural language analysis used here is customized. Comparing with open source NL2SQL, the hit rate is high and the analysis is more precise. After the natural language is converted into SQL, the SQL will give Apache Doris query to get the analysis result. As a result, users can view detailed data in any cases at any time by typing. Compared with pre-computed OLAP engines such as Apache Kylin and Apache Druid, Apache Doris performs better for the following reasons:
-
The query is flexible and the model is not fixed, which supports customization.
-
It needs to support table association, aggregation calculation, and detailed query.
-
Response time needs to be fast.
Therefore, we have successfully implemented AI Chatbots analysis by using Apache Doris. At the same time, feedback on the application in our company is awesome.
Experience
Based on the above two scenarios, we have accumulated some experience and insights and I will share them with you now.
Datawarehouse Table Design:
-
Tables which contain about tens of millions of data(for reference, related to the size of the cluster) is better to use the Duplicate table type. The Duplicate table type supports aggregation and detailed query at the same time, without additional detailed tables required.
-
When the amount of data is relatively large, we suggest to use the Aggregate aggregation table type, build a rollup index on the aggregation table type, use materialized views to optimize queries, and optimize aggregation fields.
-
When the amount of data is large with many associated tables, ETL can be used to write wide tables, imports to Doris, combined with Aggregate to optimize the aggregation table type. Or we suggest you use the official Doris JOIN optimization refer to: https://doris .apache.org/en-US/docs/dev/advanced/join-optimization/doris-join-optimization
Storage:
We use SSD and HDD to separate hot and warm data storage. Data within the past year is stored in SSD, and data more than one year is stored in HDD. Apache Doris supports setting cooling time for partitions. The current solution is to set automatic synchronization to migrate historical data from SSD to HDD to ensure that the data within one year is placed in on the SSD.
Upgrade
Make sure to back up the metadata before upgrading. You can also use the method of starting a new cluster to back up the data files to a remote storage system such as S3 or HDFS through Broker, and then import the previous cluster data into the new cluster through backup and recovery.
Performance Comparison
Aspire started using Apache Doris from version 0.12. This year we completed the upgrade from version 0.15 to the latest version 1.1, and conducted performance tests based on real business data.
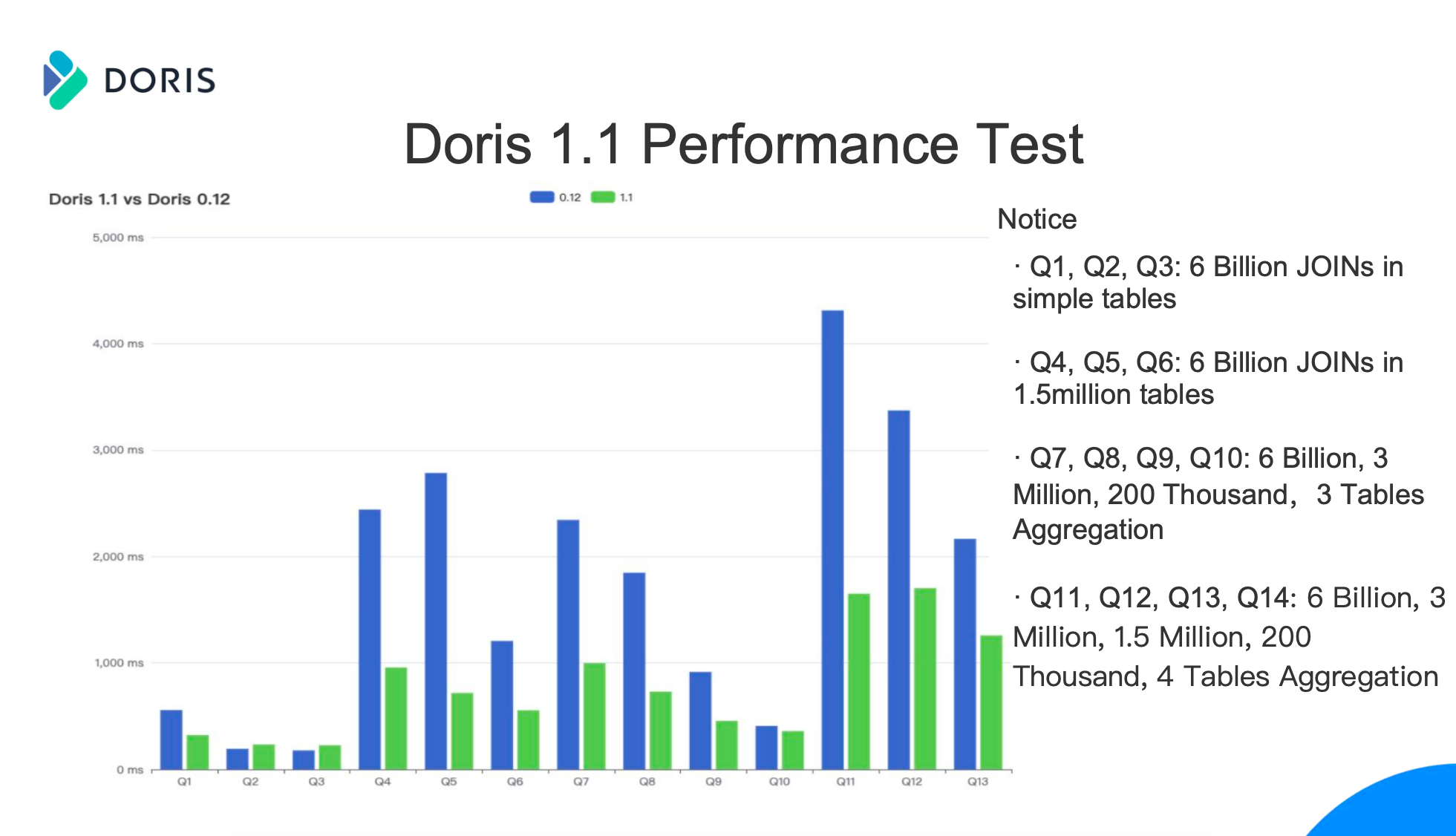
As can be seen from the test report, among the 13 SQLs test in total, the performance difference of the first 3 SQLs after the upgrade is not obvious, because these 3 scenarios are mainly simple aggregation functions, which do not require high performance of Apache Doris. Version 0.15 can meet demand. In the scenario after Q4, SQL is more complex while Group By needs multiple fields, aggregation functions and complex functions. Therefore, the performance improvement after upgrading is obvious to see: the average query performance is 2- 3 times. We highly recommend that you upgrade to the latest version of Apache Doris.
Summary and Benefits
-
Apache Doris supports the construction of offline plus real-time unified data warehouses. One ETL script can support both real-time and offline data warehouses, which greatly greatly improved efficiency, reduces storage costs, and avoids problems such as inconsistencies between offline and real-time indicators.
-
Apache Doris 1.1.x version fully supports vectorization, which improves the query performance by 2-3 times compared with the previous version. After testing, the query performance of Apache Doris version 1.1.x in the wide table is equal to that of ClickHouse.
-
Apache Doris is powerful and does not depend on other components. Compared with Apache Kylin, Apache Druid, ClickHouse, Apache Doris does not need a second component to fill the technical gap. Apache Doris supports aggregation, detailed queries, and associated queries. Currently, more than 90% of AISPEACH' analysis have migrated to Apache Doris. Thanks to this advantage, developers operate and maintain fewer components, which greatly reduces the cost of operation and maintenance.
-
It is extremely easy to use, supporting MySQL protocol and standard SQL, which greatly reduces user learning costs.
Special thanks to SelectDB, a company with products powered by Apache Doris, helps us work with the community and get sufficient technical support.