A financial anti-fraud solution based on the Apache Doris data warehouse
Financial fraud prevention is a race against time. Implementation-wise, it relies heavily on the data processing power, especially under large datasets. Today I'm going to share with you the use case of a retail bank with over 650 million individual customers. They have compared analytics components including Apache Doris, ClickHouse, Greenplum, Cassandra, and Kylin. After 5 rounds of deployment and comparison based on 89 custom test cases, they settled on Apache Doris, because they witnessed a six-fold writing speed and faster multi-table joins in Apache Doris as compared to the mighty ClickHouse.
I will get into details about how the bank builds their fraud risk management platform based on Apache Doris and how it performs.
Fraud Risk Management Platform
In this platform, 80% of ad-hoc queries return results in less than 2 seconds, and 95% of them are finished in under 5 seconds. On average, the solution intercepts tens of thousands of suspicious transactions every day and avoids losses of millions of dollars for bank customers.
This is an overview of the entire platform from an architectural perspective.
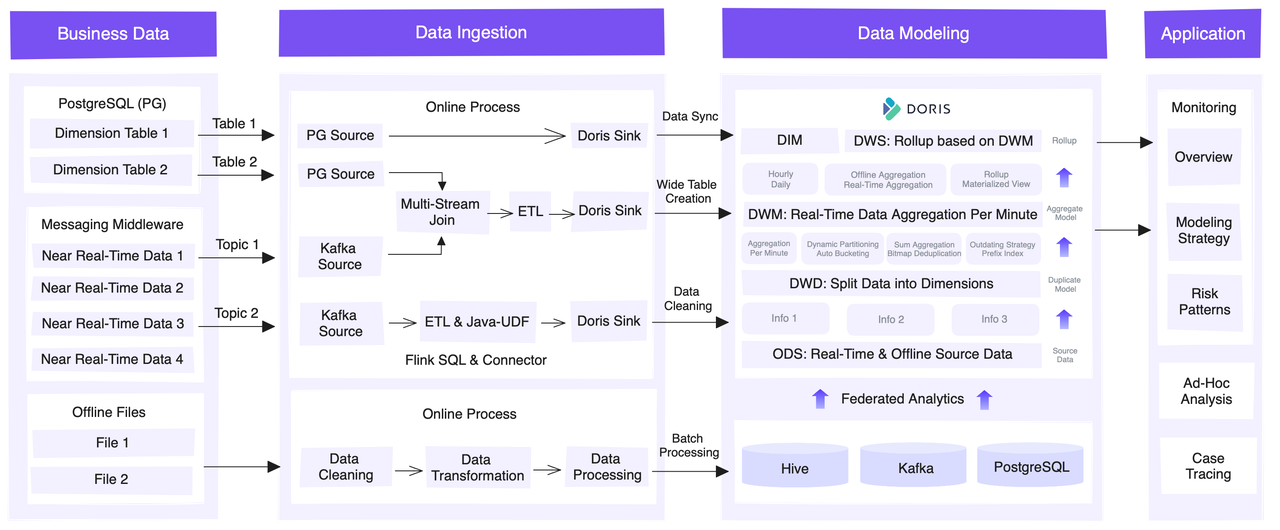
The source data can be roughly categorized as:
- Dimension data: mostly stored in PostgreSQL
- Real-time transaction data: decoupled from various external systems via Kafka message queues
- Offline data: directly ingested from external systems to Hive, making data reconciliation easy
For data ingestion, this is how they collect the three types of source data. First of all, they leverage the JDBC Catalog to to synchronize metadata and user data from PostgreSQL.
The transaction data needs to be combined with dimension data for further analysis. Thus, they employ a Flink SQL API to read dimension data from PostgreSQL, and real-time transaction data from Kafka. Then, in Flink, they do multi-stream joins and generate wide tables. For real-time refreshing of dimension tables, they use a Lookup Join mechanism, which dynamically looks up and refreshes dimension data when processing data streams. They also utilize Java UDFs to serve their specific needs in ETL. After that, they write the data into Apache Doris via the Flink-Doris-Connector.
The offline data is cleaned, transformed, and written into Hive, Kafka, and PostgreSQL, for which Doris creates catalogs as mappings, based on its Multi-Catalog capability, to facilitate federated analysis. In this process, Hive Metastore is in place to access and refresh data from Hive automatically.
In terms of data modeling, they use Apache Doris as a data warehouse and apply different data models for different layers. Each layer aggregates or rolls up data from the previous layer at a coarser granularity. Eventually, it produces a highly aggregated Rollup or Materialized View.
Now let me show you what analytics tasks are running on this platform. Based on the scale of monitoring and human involvement, these tasks can be divided into real-time risk reporting, multi-dimensional analysis, federated queries, and auto alerting.
Real-time risk report
When it comes to fraud prevention, what is diminishing the effectiveness of your anti-fraud efforts? It is incomplete exposure of potential risks and untimely risk identification. That's why people always want real-time, full-scale monitoring and reporting.
The bank's solution to that is built on Apache Flink and Apache Doris. First of all, they put together the 17 dimensions. After cleaning, aggregation, and other computations, they visualize the data on a real-time dashboard.
As for scale, it analyzes the workflows of over 10 million customers, 30,000 clerks, 10,000 branches, and 1000 products.
As for speed, the bank now has evolved from next-day data refreshing to near real-time data processing. Targeted analysis can be done within minutes instead of hours. The solution also supports complicated ad-hoc queries to capture underlying risks by monitoring how the data models and rules run.
Multi-dimensional analysis to identify risks
Case tracing is another common anti-fraud practice. The bank has a fraud model library. Based on the fraud models, they analyze the risks of each transaction and visualize the results in near real time, so their staff can take prompt measures if needed.
For that purpose, they use Apache Doris for multi-dimensional analysis of cases. They check the patterns of transactions, including sources, types, and time, for a comprehensive overview. During this process, they often need to combine over 10 filtering conditions of different dimensions. This is empowered by the ad-hoc query capabilities of Apache Doris. Both rule-based matching and list-based matching of cases can be done within seconds without manual efforts.
Federated queries to locate risk details
Apart from identifying risks from each transaction, the bank also receives risk reports from customers. In these cases, the corresponding transaction will be labeled as "risky", and it will be categorized and recorded in the ticketing system. The labels make sure that the high-risk transactions are promptly attended to.
One problem is that, the ticketing system is overloaded with such data, so it is not able to directly present all the details of the risky transactions. What needs to be done is to relate the tickets to the transaction details so the bank staff can locate the actual risks.
How is that implemented? Every day, Apache Doris traverses the incremental tickets and the basic information table to get the ticket IDs, and then it relates the ticket IDs to the dimension data stored in itself. At the end, the ticket details are presented at the frontend of Doris. This entire process takes only a few minutes. This is a big game change compared to the old time when they had to manually look up the suspicious transaction.
Auto alerting
Based on Apache Doris, the bank designs their own alerting rules, models, and strategies. The system monitors how everything runs. Once it detects a situation that matches the alert rules, it will trigger an alarm. They have also established a real-time feedback mechanism for the alerting rules, so if a newly added rule causes any negative effects, it will be adjusted or removed rapidly.
So far, the bank has added nearly 100 alerting rules for various risk types to the system. During the past two months, over 100 alarms were issued with over 95% accuracy in less than 5 seconds after the risk situation arises.
Conclusion
For a comprehensive anti-fraud solution, the bank conducts full-scale real-time monitoring and reporting for all their data workflows. Then, for each transaction, they look into the multiple dimensions of it to identify risks. For the suspicious transactions reported by the bank customers, they perform federated queries to retrieve the full details of them. Also, an auto alerting mechanism is always on patrol to safeguard the whole system. These are the various types of analytic workloads in this solution. The implementation of them rely on the capabilities of Apache Doris, which is a data warehouse designed to be an all-in-one platform for various workloads. If you try to build your own anti-fraud solution, the Apache Doris open source developers are happy to exchange ideas with you.