Auto-increment columns in databases: a simple magic that makes a big difference
Auto-increment column is a bread-and-butter feature of single-node transactional databases. It assigns a unique identifier for each row in a way that requires the least manual effort from users. With an auto-increment column in the table, whenever a new row is inserted into the table, the new row will be assigned with the next available value from the auto-increment sequence. This is an automated mechanism that makes database maintenance easy and reliable.
Auto-increment column is the bedrock of many features in databases:
-
Dictionary encoding: User IDs and Order IDs are often stored as strings. However, strings are not friendly to precise deduplication query execution. So for optimal performance, a common practice is to perform dictionary encoding on the strings and then construct a bitmap for aggregation operations. The role of an auto-increment column in this process is that it speeds up dictionary encoding and thus accelerates string deduplication.
-
Primary key generation: An auto-increment column is the perfect candidate for the primary key of a table. Primary keys must be unique and not empty, while auto-increment columns guarantee a unique identifier for each row.
-
Detailed data updates: Updating detail tables is tricky, but it can be easy if you add a auto-increment table to it. It gives each data record in the database a unique ID, which can work as the primary key, and then data updates can be done based on the primary key.
-
Efficient pagination: Pagination is often required in data display. It is typically implemented by the
limitoroffset+order bystatement in SQL queries. However, such implementation involves full data reading and sorting, which doesn't make so much sense in deep pagination queries (those with large offsets). This is when auto-increment columns come to the rescue. Like I said, it gives a unique identifier to each row, so the maximum identifier of the last page can be used as the filtering condition for the next page. Thus, it can avoid a lot of unnecessary data scanning and increase pagination efficiency.
The idea of auto-increment columns is intuitive, but when it comes to distributed databases, it becomes a different game, because it has to consider global transactions. As a distributed DBMS, Apache Doris provides an innovative and efficient auto-increment solution that does no harm to data writing performance.
To give AUTO_INCREMENT column a spin, follow this quick demo.
Syntax & usage
To enable an auto-increment column in Doris, add AUTO_INCREMENT property to the column in the table creation statement (CREAT-TABLE). You can specify a starting value for the auto-increment column via AUTO_INCREMENT(start_value); if not, the default starting value is 1.
For example, you can create a table in the Duplicate Key model, with one of the key columns being an auto-increment column.
CREATE TABLE `demo`.`tbl` (
// highlight-next-line
`id` BIGINT NOT NULL AUTO_INCREMENT,
`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Apart from a key column, you can also specify a value column as an auto-increment column (example below):
CREATE TABLE `demo`.`tbl` (
`uid` BIGINT NOT NULL,
`name` BIGINT NOT NULL,
// highlight-next-line
`id` BIGINT NOT NULL AUTO_INCREMENT,
`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY HASH(`uid`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
AUTO_INCREMENT is supported in both the Duplicate Key model and the Unique Key model. Usage in the latter is similar.
I will walk you down the rest of the road with the table below as an example:
CREATE TABLE `demo`.`tbl` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`name` varchar(65533) NOT NULL,
`value` int(11) NOT NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
When you ingest data into this table using an insert into statement, if the id column has no specified value in the original data file, it will be auto-filled with auto-increment values.
mysql> insert into tbl(name, value) values("Bob", 10), ("Alice", 20), ("Jack", 30);
Query OK, 3 rows affected (0.09 sec)
{'label':'label_183babcb84ad4023_a2d6266ab73fb5aa', 'status':'VISIBLE', 'txnId':'7'}
mysql> select * from tbl order by id;
+------+-------+-------+
| id | name | value |
+------+-------+-------+
| 1 | Bob | 10 |
| 2 | Alice | 20 |
| 3 | Jack | 30 |
+------+-------+-------+
3 rows in set (0.05 sec)
Similarly, when you ingest a data file test.csv by Stream Load, the id column will be auto-filled with auto-increment values, too.
test.csv:
Tom,40
John,50
curl --location-trusted -u user:passwd -H "columns:name,value" -H "column_separator:," -T ./test.csv http://{host}:{port}/api/{db}/tbl/_stream_load
select * from tbl order by id;
+------+-------+-------+
| id | name | value |
+------+-------+-------+
| 1 | Bob | 10 |
| 2 | Alice | 20 |
| 3 | Jack | 30 |
| 4 | Tom | 40 |
| 5 | John | 50 |
+------+-------+-------+
5 rows in set (0.04 sec)
Applicable scenarios
01 Dictionary encoding
In Apache Doris, the bitmap data type and the bitmap-related aggregations are implemented with RoaringBitmap, which can deliver high performance especially when dictionary encoding produces dense values.
As is mentioned, auto-increment columns enable fast dictionary encoding. I will put you into the context of user profiling to show you how that works.
For analysis of offline page views (PV) and unique visitors (UV), store the details in a user behavior table:
CREATE TABLE `demo`.`dwd_dup_tbl` (
`user_id` varchar(50) NOT NULL,
`dim1` varchar(50) NOT NULL,
`dim2` varchar(50) NOT NULL,
`dim3` varchar(50) NOT NULL,
`dim4` varchar(50) NOT NULL,
`dim5` varchar(50) NOT NULL,
`visit_time` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Create a dictionary table as follows leveraging AUTO_INCREMENT:
CREATE TABLE `demo`.`dictionary_tbl` (
`user_id` varchar(50) NOT NULL,
`aid` BIGINT NOT NULL AUTO_INCREMENT
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Load the existing user_id into the dictionary table, and create mappings from user_id to integer values.
insert into dictionary_tbl(user_id)
select user_id from dwd_dup_tbl group by user_id;
If you only need to load the incremental user_id into the dictionary table, you can use the following command. In practice, you can also use the Flink Doris Connector for data writing.
insert into dictionary_tbl(user_id)
select dwd_dup_tbl.user_id from dwd_dup_tbl left join dictionary_tbl
on dwd_dup_tbl.user_id = dictionary_tbl.user_id where dwd_dup_tbl.visit_time '2023-12-10' and dictionary_tbl.user_id is NULL;
Suppose you have your analytic dimensions as dim1, dim3, dim5, create a table in the Aggregate Key model to accommodate the results of data aggregation:
CREATE TABLE `demo`.`dws_agg_tbl` (
`dim1` varchar(50) NOT NULL,
`dim3` varchar(50) NOT NULL,
`dim5` varchar(50) NOT NULL,
`user_id_bitmap` BITMAP BITMAP_UNION NOT NULL,
`pv` BIGINT SUM NOT NULL
) ENGINE=OLAP
AGGREGATE KEY(`dim1`,`dim3`,`dim5`)
DISTRIBUTED BY HASH(`dim1`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Load the aggregated results into the table:
insert into dws_agg_tbl
select dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5, BITMAP_UNION(TO_BITMAP(dictionary_tbl.aid)), COUNT(1)
from dwd_dup_tbl INNER JOIN dictionary_tbl on dwd_dup_tbl.user_id = dictionary_tbl.user_id
group by dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5;
Then you query PV/UV using the following statement:
select dim1, dim3, dim5, bitmap_count(user_id_bitmap) as uv, pv from dws_agg_tbl;
02 Detailed data updates
In Doris, the Unique Key model is applicable to use cases with frequent data updates, while the Duplicate Key model is designed for detailed data storage with no data updating requirements.
However, in real life, users might need to update their detailed data sometimes, which can be hard to implement because the data tables don't come with unique key columns.
In this case, you can use an auto-increment column as the primary key for the detailed data.
For example, a financial institution keeps record of customer loans and writes it into a Duplicate Key table, in which one single user might have multiple borrowing records.
CREATE TABLE loan_records (
`user_id` VARCHAR(20) DEFAULT NULL COMMENT 'Customer ID',
`loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of loan',
`interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Interest rate',
`loan_start_date` DATE DEFAULT NULL COMMENT 'Start date of the loan',
`loan_end_date` DATE DEFAULT NULL COMMENT 'End date of the loan',
`total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of debt'
) DUPLICATE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Suppose that in a promotional campaign, the institution offers a 10% discount on interest rates to its existing customers. Correspondingly, there is a need to update the interest_rate and total_debt in the table.
For that sake, you can create a Unique Key table for the same data, but add an auto_id field and set it as the primary key.
CREATE TABLE loan_records (
`auto_id` BIGINT NOT NULL AUTO_INCREMENT,
`user_id` VARCHAR(20) DEFAULT NULL COMMENT 'Customer ID',
`loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of loan',
`interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Interest rate',
`loan_start_date` DATE DEFAULT NULL COMMENT 'Start date of the loan',
`loan_end_date` DATE DEFAULT NULL COMMENT 'End date of the loan',
`total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT 'Amount of debt'
) UNIQUE KEY(`auto_id`)
DISTRIBUTED BY HASH(`auto_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Now, write a few new records into the table and see what happens. (Note that you don't have to write in the auto_id field.)
INSERT INTO loan_records (user_id, loan_amount, interest_rate, loan_start_date, loan_end_date, total_debt) VALUES
('10001', 5000.00, 5.00, '2024-03-01', '2024-03-31', 5020.55),
('10002', 10000.00, 5.00, '2024-03-01', '2024-05-01', 10082.56),
('10003', 2000.00, 5.00, '2024-03-01', '2024-03-15', 2003.84),
('10004', 7500.00, 5.00, '2024-03-01', '2024-04-15', 7546.23),
('10005', 3000.00, 5.00, '2024-03-01', '2024-03-21', 3008.22),
('10002', 8000.00, 5.00, '2024-03-01', '2024-06-01', 8100.82),
('10007', 6000.00, 5.00, '2024-03-01', '2024-04-10', 6032.88),
('10008', 4000.00, 5.00, '2024-03-01', '2024-03-26', 4013.70),
('10001', 5500.00, 5.00, '2024-03-01', '2024-04-05', 5526.37),
('10010', 9000.00, 5.00, '2024-03-01', '2024-05-10', 9086.30);
Check with the select * from loan_records statement, and you can see a unique ID is already in place for each newly-ingested record:
mysql> select * from loan_records;
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| 1 | 10001 | 5000.00 | 5.00 | 2024-03-01 | 2024-03-31 | 5020.55 |
| 4 | 10004 | 7500.00 | 5.00 | 2024-03-01 | 2024-04-15 | 7546.23 |
| 2 | 10002 | 10000.00 | 5.00 | 2024-03-01 | 2024-05-01 | 10082.56 |
| 3 | 10003 | 2000.00 | 5.00 | 2024-03-01 | 2024-03-15 | 2003.84 |
| 6 | 10002 | 8000.00 | 5.00 | 2024-03-01 | 2024-06-01 | 8100.82 |
| 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 |
| 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 |
| 9 | 10001 | 5500.00 | 5.00 | 2024-03-01 | 2024-04-05 | 5526.37 |
| 5 | 10005 | 3000.00 | 5.00 | 2024-03-01 | 2024-03-21 | 3008.22 |
| 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
10 rows in set (0.01 sec)
Execute these two SQL statements to update interest_rate and total_debt, respectively:
update loan_records set interest_rate = interest_rate * 0.9 where user_id <= 10005;
update loan_records set total_debt = loan_amount + (loan_amount * (interest_rate / 100) * DATEDIFF(loan_end_date, loan_start_date) / 365);
Check again to see if the old records have been replaced by the new ones:
mysql> select * from loan_records order by auto_id;
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
| 1 | 10001 | 5000.00 | 4.50 | 2024-03-01 | 2024-03-31 | 5018.49 |
| 2 | 10002 | 10000.00 | 4.50 | 2024-03-01 | 2024-05-01 | 10075.21 |
| 3 | 10003 | 2000.00 | 4.50 | 2024-03-01 | 2024-03-15 | 2003.45 |
| 4 | 10004 | 7500.00 | 4.50 | 2024-03-01 | 2024-04-15 | 7541.61 |
| 5 | 10005 | 3000.00 | 4.50 | 2024-03-01 | 2024-03-21 | 3007.40 |
| 6 | 10002 | 8000.00 | 4.50 | 2024-03-01 | 2024-06-01 | 8090.74 |
| 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 |
| 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 |
| 9 | 10001 | 5500.00 | 4.50 | 2024-03-01 | 2024-04-05 | 5523.73 |
| 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |
+---------+---------+-------------+---------------+-----------------+---------------+------------+
10 rows in set (0.01 sec)
03 Efficient pagination
Imagine that you need to sort the data in a specific order and then retrieve record No. 90,001 to record No. 90,010. This means you have a large offset of 90,000. This is what we call a deep pagination query. Even though you only require a result set of 10 rows, the database system still has to read the entire dataset into memory and perform a full sorting.
For higher execution efficiency in deep pagination queries, you can harness the power of auto-increment columns. The main idea is to record the max_value from the unique_value column of the previous page, and push down predicates by where unique_value > max_value limit rows_per_page.
For example, during table creation, you enable an auto-increment column: unique_value, which gives each row an identifier.
CREATE TABLE `demo`.`records_tbl` (
`user_id` int(11) NOT NULL COMMENT "",
`name` varchar(26) NOT NULL COMMENT "",
`address` varchar(41) NOT NULL COMMENT "",
`city` varchar(11) NOT NULL COMMENT "",
`nation` varchar(16) NOT NULL COMMENT "",
`region` varchar(13) NOT NULL COMMENT "",
`phone` varchar(16) NOT NULL COMMENT "",
`mktsegment` varchar(11) NOT NULL COMMENT "",
`unique_value` BIGINT NOT NULL AUTO_INCREMENT
) DUPLICATE KEY (`user_id`, `name`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
In pagination queries, suppose that each page displays 100 results, this is how you retrieve the first page of the result set.
select * from records_tbl order by unique_value limit 100;
Use programs to record the maximum unique_value in the returned result. Suppose that the maximum is 99, you can query data from the second page using the following statement:
select * from records_tbl where unique_value > 99 order by unique_value limit 100;
If you need to query data from a deeper page, for example, page 101, which means it's hard to get the maximum unique_value from the previous page directly, then you can use the statement as follows:
select user_id, name, address, city, nation, region, phone, mktsegment
from records_tbl, (select unique_value as max_value from records_tbl order by unique_value limit 1 offset 9999) as previous_data
where records_tbl.unique_value > previous_data.max_value
order by unique_value limit 100;
Implementation
Typical OLTP databases perform incremental ID matching by their transaction mechanisms. However, in an MPP-based distributed database system like Apache Doris, such an approach can easily suffocate data writing performance.
That's why Apache Doris 2.1 innovates the implementation of auto-increment IDs. In a data ingestion task, one of the backend (BE) nodes will work as the coordinator, which is responsible for the allocation of auto-increment IDs. The coordinator BE requests a range of IDs in bulk from the frontend (FE). The FE makes sure that the ID ranges allocated to each BE do not overlap, thus guaranteeing the uniqueness of IDs.
I illustrate the process with the figure below. StreamLoad1 has BE1 as the coordinator. BE1 requests a batch of IDs (range: 1-1000) from the FE and caches the IDs locally. Once all 1000 IDs are allocated, BE1 will request a new batch from the FE. At the same time, StreamLoad 2 selects BE3 as the coordinator, and BE3 also requests IDs from the FE. Since IDs 1-1000 have already been allocated to BE1, the FE assigns IDs 1001-2000 to BE3.
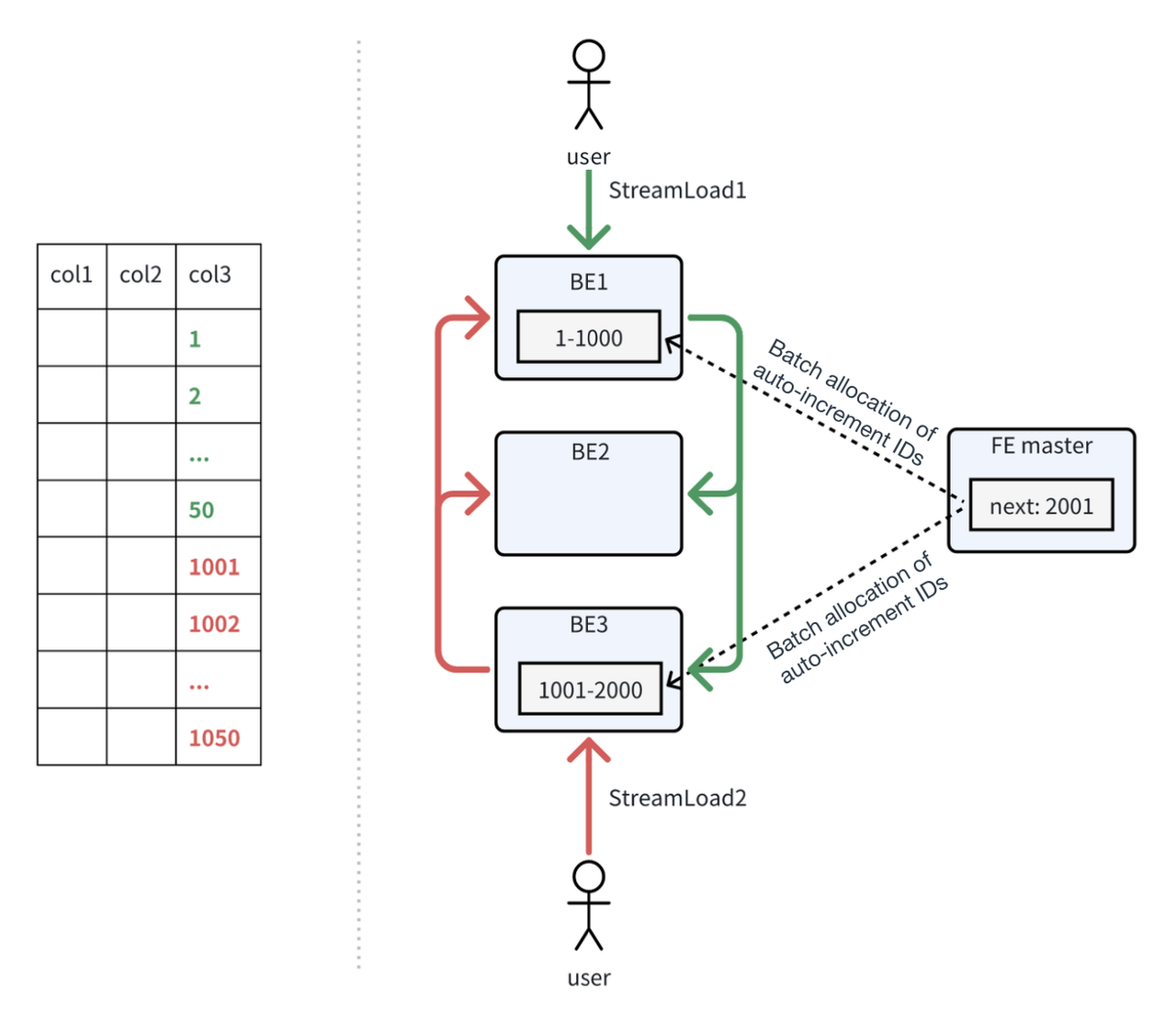
Suppose that StreamLoad1 and StreamLoad2 each write in 50 new data records, the auto-increment IDs assigned to them will be 1-50 and 1001-1050.
Suppose that StreamLoad3 arises later and selects BE1 as the coordinator, BE1 will assign IDs starting from 51 to the data written by StreamLoad3. From the user's side, they will see that rows written by StreamLoad3 get smaller ID numbers than those by StreamLoad2, even though StreamLoad2 precedes StreamLoad3 in time.
Note
Attention is required regarding:
-
Scope of uniqueness guarantee: Doris ensures that the values generated on an auto-increment column are unique within the table, but this only applies to values auto-filled by Doris. If a user explicitly inserts values into the auto-increment column, Doris cannot guarantee the uniqueness of those values.
-
Density and continuity of values: Doris ensures that the values generated by the auto-increment column are dense. However, for performance reasons, it cannot guarantee that the auto-filled values are continuous. This means there may be occurrences of value jumps in the auto-increment column. Additionally, since the auto-increment values are pre-allocated and cached in BE, the magnitude of the auto-increment values cannot reflect the order of data import.
Conclusion
AUTO_INCREMENT brings higher stability and reliability for Doris in large-scale data processing. If it sounds like something you need, download Apache Doris and try it out. For issues you come across along the way, join us in the Apache Doris developer and user community and we are happy to help.