
Cross-cluster replication for read-write separation: story of a grocery store brand
This is about how a grocery store brand leverages the Cross-Cluster Replication (CCR) capability of Apache Doris to separate their data reading and writing workloads. In this case, where the freshness of groceries is guaranteed by the freshness of data, they use Apache Doris as their data warehouse to monitor and analyze their procurement, sale, and stock in real time for all their stores and supply chains.
Why they need CCR
A major part of the user's data warehouse (including the ODS, DWD, DWS, and ADS layers) is built within Apache Doris, which employs a micro-batch scheduling mechanism to coordinate data across the data warehouse layers. However, this is pressured by the burgeoning business of the grocery store brand. The data size they have to receive, store, and analyze is getting larger and larger. That means their data warehouse has to handle bigger data writing batches and more frequent data queries. However, task scheduling during query execution might lead to resource preemption, so any resource shortage can easily compromise performance or even cause task failure or system disruption.
Naturally, the user thought of separating the reading and writing workloads. Specifically, they want to replicate data from the ADS layer (which is cleaned, transformed, aggregated, and ready to be queried) to a backup cluster dedicated to query services. This is implemented by the CCR in Apache Doris. It prevents abnormal queries from interrupting data writing and ensures cluster stability.
Before CCR
Before CCR was available, they innovatively adopted the Multi-Catalog feature of Doris for the same purpose. Multi-Catalog allows users to connect Doris to various data sources conveniently. It is actually designed for federated querying, but the user drew inspiration from it. They wrote a script and tried to pull incremental data via Catalog. Their data synchronization pipeline is as follows:
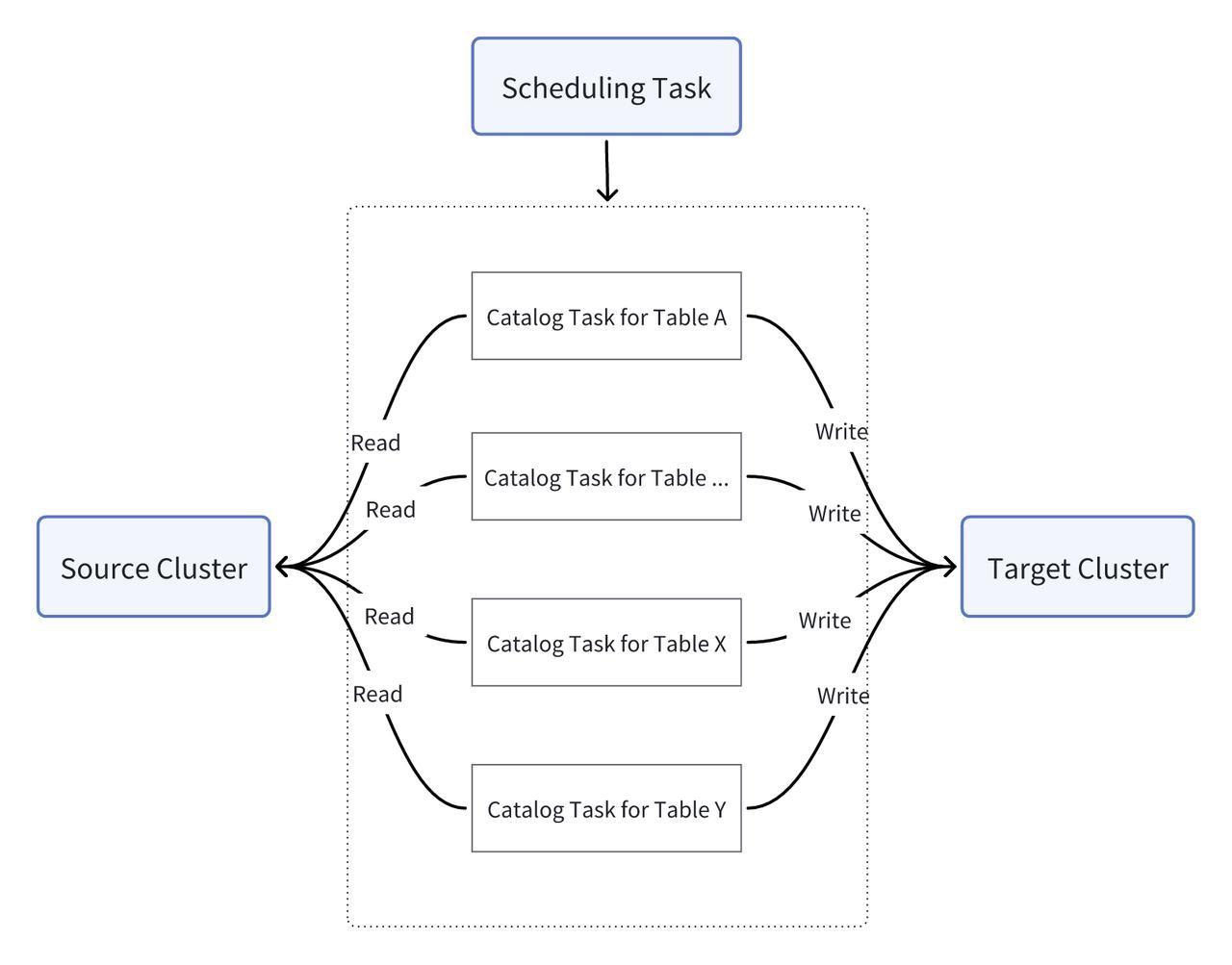
They loaded data from the source cluster to the target cluster by regular scheduling tasks. To identify incremental data, they added a last_update_time field to the tables. There were two downsides to this. Firstly, the data freshness of the target cluster was reliant on and hindered by the scheduling tasks. Secondly, for incremental data ingestion, in order to identify incremental data, the import SQL statement for every table has to include the logic to check the last_update_time field, otherwise the system just deletes and re-imports the entire table. Such requirement increases development complexity and data error rate.
CCR in Apache Doris
Just when they were looking for a better solution, Apache Doris released CCR in version 2.0. Compared to the alternatives they've tried, CCR in Apache Doris is:
-
Lightweight in design: The data synchronization tasks consume very few machine resources. They run smoothly without reducing the overall performance of Apache Doris.
-
Easy to use: It can be configured by one simple
POSTrequest. -
Unlimited in migration: Users can raise the upper limit of the data migration capabilities in CCR by optimizing their cluster configuration.
-
Consistent in data: The DDL statements executed in the source cluster can be automatically synchronized into the target cluster, ensuring data consistency.
-
Flexible in synchronization: It is able to perform both full data synchronization and incremental data synchronization.
To start CCR in Doris simply requires two steps. Step one is to enable binlogs in both the source cluster and the target cluster. Step two is to send the name of the database or table to be replicated. Then the system will start synchronizing full or incremental data. The detailed workflow is as follows:
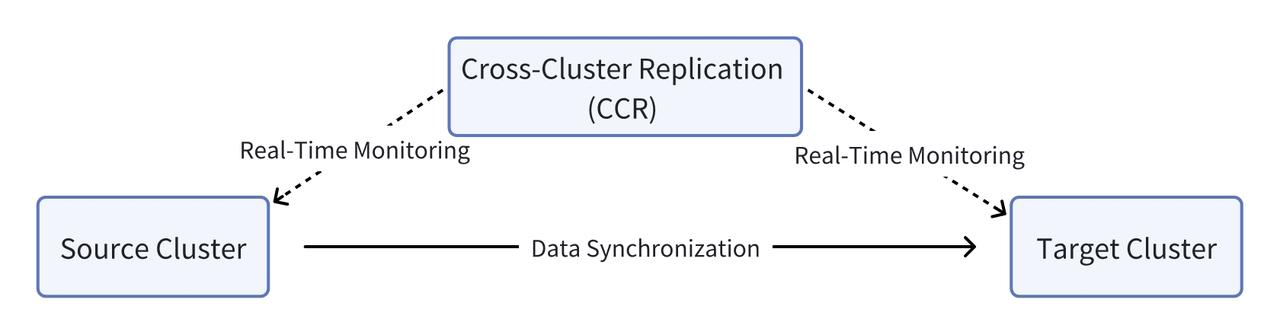
In the grocery store brand's case, they need to synchronize a few tables from the source cluster to the target cluster, each table having an incremental data size of about 50 million rows. After a month's trial run, the Doris CCR mechanism is proven to be stable and performant:
-
Higher stability and data accuracy: No replication failure has ever occurred during the trial period. Every data row is transferred and landed in the target cluster accurately.
-
Streamlined workflows:
- Before CCR: The user had to write SQL for each table and write data via Catalog; For tables without a
last_update_timefield, incremental data synchronization can only be implemented by full-table deletion and re-import.
Insert into catalog1.db.destination_table_1 select * from catalog1.db.source_table1 where time > xxx
Insert into catalog1.db.destination_table_2 select * from catalog1.db.source_table2 where time > xxx
…
Insert into catalog1.db.destination_table_x select * from catalog1.db.source_table_x- After CCR: It only requires one
POSTrequest to synchronize an entire database.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "demo",
"table": ""
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "ccrt",
"table": ""
}
}' http://127.0.0.1:9190/create_ccr - Before CCR: The user had to write SQL for each table and write data via Catalog; For tables without a
-
Faster data loading: With CCR, it only takes 3~4 seconds to ingest a day's incremental data, as compared to more than 30 seconds with the Catalog method. As for real-time synchronization, CCR can finish data ingestion in 1 second, without reliance on manual updates or regular scheduling.
Conclusion
Using CCR in Apache Doris, the grocery store brand separates reading and writing workloads into different clusters and thus improves overall system stability. This solution delivers a real-time data synchronization latency of about 1 second. To further ensure normal functioning, it has a real-time monitoring and alerting mechanism so any issue will be notified and attended to instantly, and a contingency plan to guarantee uninterrupted query services. It also supports partition-based data synchronization (e.g. ALTER TABLE tbl1 REPLACE PARTITION). With demonstrated effectiveness of CCR, they are planning to replicate more of their data assets for efficient and secure data usage.
CCR is also applicable when you need to build multiple data centers or derive a test dataset from your production environment. For further guidance on CCR, join the Apache Doris community.