
Slash your cost by 90% with Apache Doris Compute-Storage Decoupled Mode
In the age of data-driven decision-making, the exponential growth of data volume and the ever-evolving demands for analytics pose great challenges. Data streams in from diverse sources (such as application logs, network interactions, and mobile devices), spanning structured, semi-structured, and unstructured formats. This diversity places pressure on storage and analytical systems. Meanwhile, the surge in demand for real-time analytics and exploratory queries requires systems to deliver millisecond-level responsiveness while achieving optimal cost efficiency and elastic scalability.
Apache Doris emerged in the era of integrated storage and computation, built on a classic Shared Nothing architecture. In this design, storage and computation are co-located on Backend (BE) nodes, leveraging an MPP (Massively Parallel Processing) distributed computing model. This architecture delivers key advantages, including high availability, simplified deployment, seamless horizontal scalability, and exceptional real-time analytical performance.
For real-time analytics and small-scale data processing, Apache Doris stands out with predictable, stable low-latency performance, making it an indispensable solution. However, when scaling to large-scale data processing, it encounters certain challenges, primarily in:
- Relatively high costs & low elasticity: Balancing storage and compute resources remains a big challenge. Storage capacity must be sufficient to accommodate all data, while compute resources need to handle query workloads efficiently. However, dynamically scaling clusters is often time-consuming, prompting enterprises to over-provision resources to ensure stability. This approach simplifies operations but leads to resource waste and increased costs.
- Limited workload isolation: Since Apache Doris 2.0, Workload Groups provide soft isolation, while Resource Groups offer a degree of hard isolation. However, neither mechanism ensures complete physical isolation, which can impact performance in multi-tenant or resource-intensive environments.
- Operational complexity: Managing an OLAP system with built-in distributed storage requires not only overseeing compute nodes but also ensuring efficient storage administration. Storage management is inherently complex, and misconfigurations or improper operations can lead to data loss, making maintenance highly demanding.
Even so, in the absence of stable and large-scale storage support, a integrated storage-compute architecture remains the optimal choice.
As cloud infrastructure matures, enterprises increasingly seek deeper Apache Doris integration with public clouds, private clouds, and Kubernetes (K8s) container platforms to unlock greater elasticity and flexibility. Public clouds offer mature object storage with on-demand compute resources, eliminating the need for pre-allocated space, while private clouds leverage technologies like K8s and MinIO to build scalable resource platforms. This evolution in cloud infrastructure has also accelerated Apache Doris’ transition to a storage-compute decoupled architecture, enabling lower costs, high elasticity, and enhanced workload isolation.
Apache Doris Compute-Storage Decoupled Mode
Since version 3.0, Apache Doris has supported both the compute-storage decoupled mode and the compute-storage coupled mode.
01 Compute-Storage Decoupled
In the compute-storage decoupled mode, Apache Doris adopts a three-tier architecture consisting of three layers: shared storage, compute groups, and meta data service:
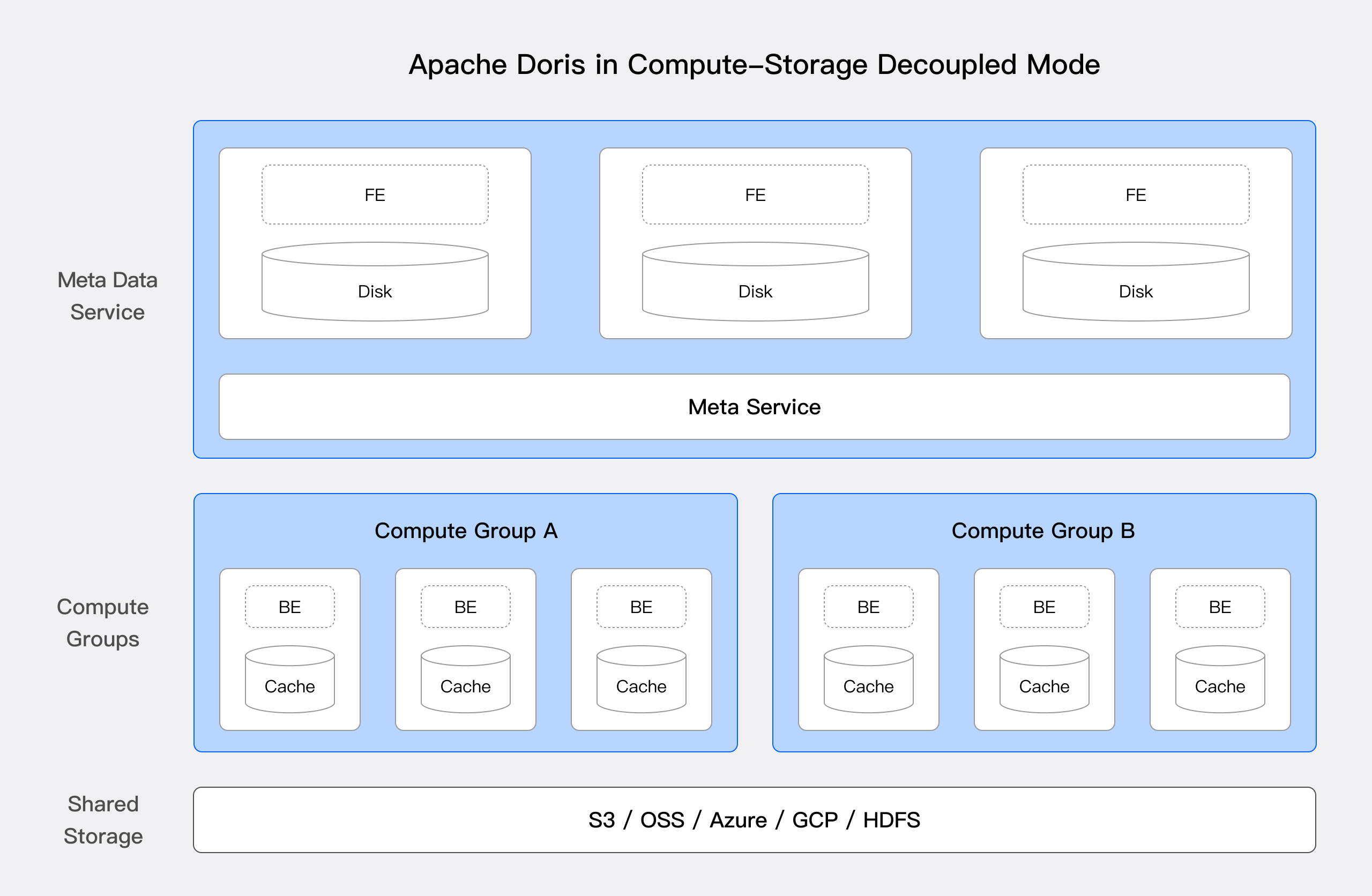
Shared Storage Layer
Data is persisted in the shared storage layer, allowing compute nodes to access and share data seamlessly. This design enhances compute node flexibility and reduces operational overhead. Leveraging mature and reliable shared storage results in ultra-low storage costs and high data reliability. Whether using public cloud object storage or enterprise-managed shared storage, this approach greatly reduces the maintenance complexity of Apache Doris.
Compute Groups
The compute layer consists of multiple compute groups responsible for executing query plans. Each query is executed within a single compute group, ensuring isolation and scalability. Compute nodes are stateless, utilizing local disks as high-speed caches to accelerate queries while sharing the same data and metadata services. Each compute group operates independently, supporting on-demand scaling, and local caches remain isolated to ensure workload separation and performance consistency.
Meta Data Service
The meta data layer manages system meta data, including databases, tables, schemas, rowset meta data, and transaction information, with support for horizontal scaling. Future iterations of Apache Doris’ compute-storage decoupled mode will introduce stateless Frontend (FE) nodes, where memory consumption is decoupled from cluster size. This evolution will eliminate memory bottlenecks, allowing FE nodes to operate with minimal memory requirements.
02 Architecture Design
Traditional compute-storage decoupling approaches typically store both data and meta data in shared storage while centralizing transaction management on a single FE node. However, this design introduces several challenges:
- Write performance bottlenecks: The two-phase commit protocol, driven by FE Master, incurs high latency and low throughput.
- Small file proliferation: Frequent meta data writes generate excessive small files, leading to system instability and inflated storage costs.
- Scalability constraints: Since FE nodes manage meta data in memory, an increasing number of Tablets amplifies memory pressure, eventually causing write bottlenecks.
- Data deletion risks: Relying on delta computation with timeout-based mechanisms for deletion introduces challenges in synchronizing writes and deletions. As a result, there is a risk of unintended data loss due to misalignment between ongoing writes and scheduled deletions.
Compared to traditional approaches, Apache Doris effectively addresses these challenges through a shared meta data service:
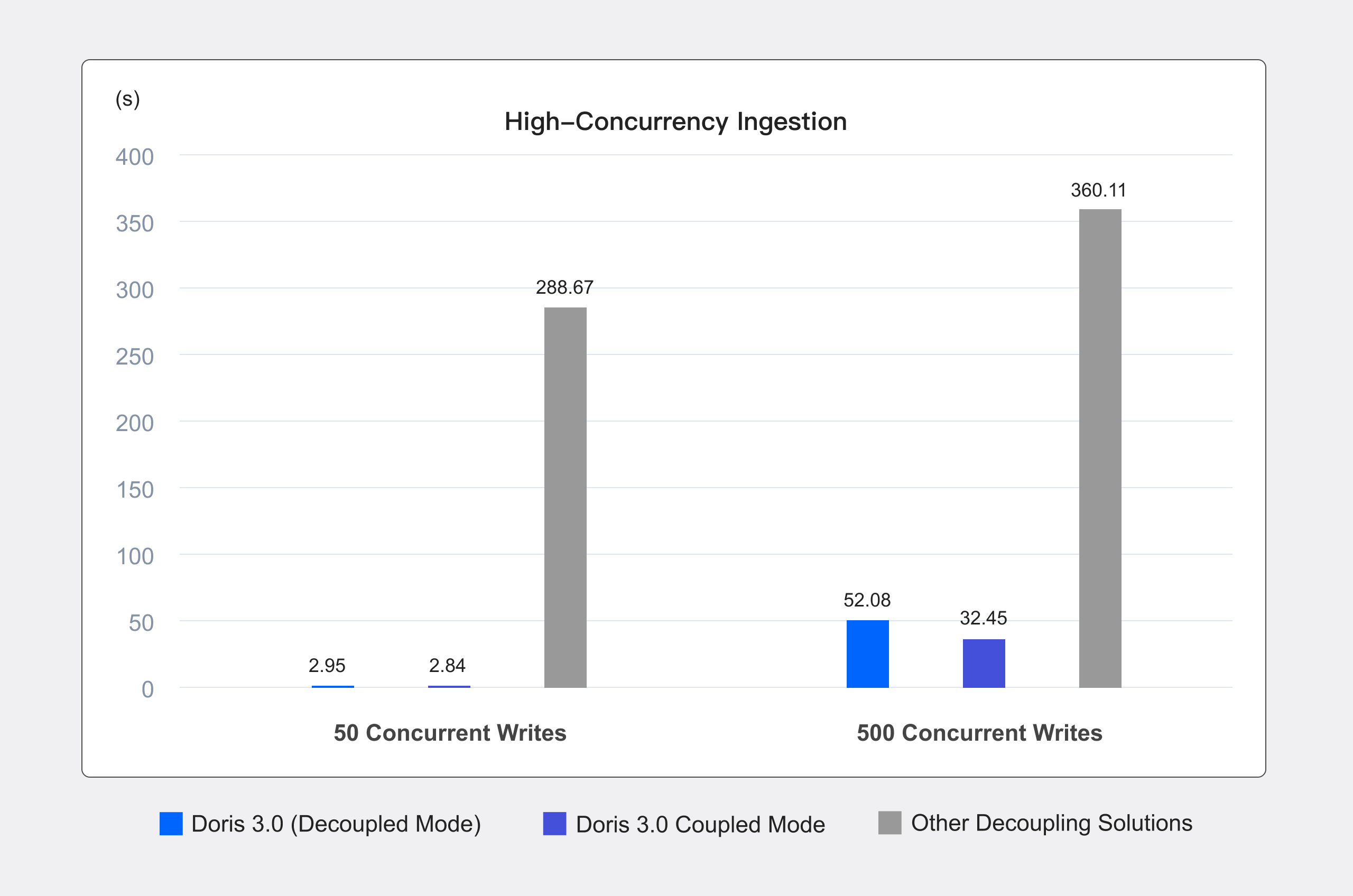
- Real-time ingestion: The meta data service provides a globally consistent view, enabling low-latency, high-throughput writes. Benchmarks show that the Apache Doris compute-storage decoupled mode achieves 100X higher performance than other solutions at 50 concurrent writes and 11X higher performance at 500 concurrent writes.
- Optimized small file management: Data is written to shared storage, while meta data is handled by the meta data service. This effectively reduces small file overheads. Tests indicate that the Apache Doris compute-storage decoupled mode generates only 1/2 the number of write files compared to other industry solutions.
- Enhanced scalability: In future versions of Apache Doris, FE metadata will be moved to the meta data service to eliminate cluster scaling limitations and ensure seamless expansion.
- Reliable data deletion: Doris employs a forward deletion mechanism based on a globally consistent view. This ensures mutual exclusion between writes and deletions, thus eliminating the risk of accidental data loss.
03 What makes it stand out
The Apache Doris compute-storage decoupled architecture provide values for users in three aspects: cost efficiency, elasticity, and workload isolation.
Firstly, it brings a 90% cost reduction compared to the compute-storage coupled mode.
- Pay-as-you-go: Unlike traditional coupled architectures, there’s no need to pre-provision compute and storage resources. Storage costs scale with actual usage, while compute resources can be dynamically adjusted based on demand.
- Single-replica storage: Instead of maintaining three replicas in costly block storage, data is stored as a single replica in low-cost object storage, with hot data cached in block storage for performance. This dramatically reduces storage footprint and hardware costs. For example, S3 costs only 25% to 50% of AWS EBS.
- Lower resource consumption: In compute-storage decoupled mode, compaction operations only process a single data replica, thus largely reducing resource usage compared to multi-replica environments.
Secondly, with a stateless compute node design, Doris enables on-demand resource scaling to meet fluctuating workloads efficiently.
- Elastic auto-scaling: Compute resources can be dynamically scaled to accommodate traffic spikes or workload variations. When demand increases, Doris can rapidly scale out compute nodes; when demand drops, resources scale down automatically, avoiding unnecessary costs.
- Fine-grained compute resource allocation: Doris allows compute nodes to be strategically assigned to specific compute groups based on workload requirements. For example, high-performance nodes handle complex queries and high-concurrency workloads, while standard nodes manage lightweight queries and infrequent requests.
Thirdly, Doris provides efficient resource scheduling and workload isolation mechanisms.
- Cross-business isolation: Different business units can be assigned dedicated compute groups with physical isolation, so workloads operate on dedicated resources without interference.
- Offline workload isolation: Large-scale batch processing tasks can be segregated into dedicated compute groups, so users can leverage low-cost resources for offline data processing without impacting real-time business performance.
- Read-write isolation: Doris allows dedicated compute groups for read and write operations to ensure consistent query response times even under high write loads.
Benchmarking and comparison
To provide a clear evaluation of the compute-storage decoupled architecture of Apache Doris, we conducted a series of benchmark tests across multiple dimensions, including data ingestion, query performance, and resource cost efficiency.
01 Ingestion performance
High-concurrency ingestion
We compared Apache Doris' coupled and decoupled modes with other mainstream solutions under the same compute resources. The tests measured real-time ingestion performance under two levels of concurrency:
- 50 concurrent writes: Ingesting 250 files, each containing 20,000 rows.
- 500 concurrent writes: Ingesting 10,000 files, each containing 500 rows.
Test results:
- At 50 concurrent writes, Doris' compute-storage decoupled mode performed on par with the coupled mode while achieving 100X the write performance of other industry compute-storage decoupled solutions.
- At 500 concurrent writes, Doris' decoupled mode experienced a slight performance drop compared to the coupled mode, yet still maintained an 11X advantage over other compute-storage decoupled architectures.
Batch data ingestion
To evaluate batch data ingestion efficiency, we conducted tests using TPC-H 1TB and TPC-DS 1TB datasets, comparing the compute-storage coupled and decoupled modes of Apache Doris. Data was loaded using S3 Load. Under default configurations, multiple tables were ingested sequentially, and the total ingestion time was measured for comparison.
Hardware configuration:
- Cluster size: 4 compute instances (1 FE, 3 BE)
- CPU: 48 cores per instance
- Memory: 192GB per instance
- Network Bandwidth: 21 Gbps
- Storage: Enhanced SSD
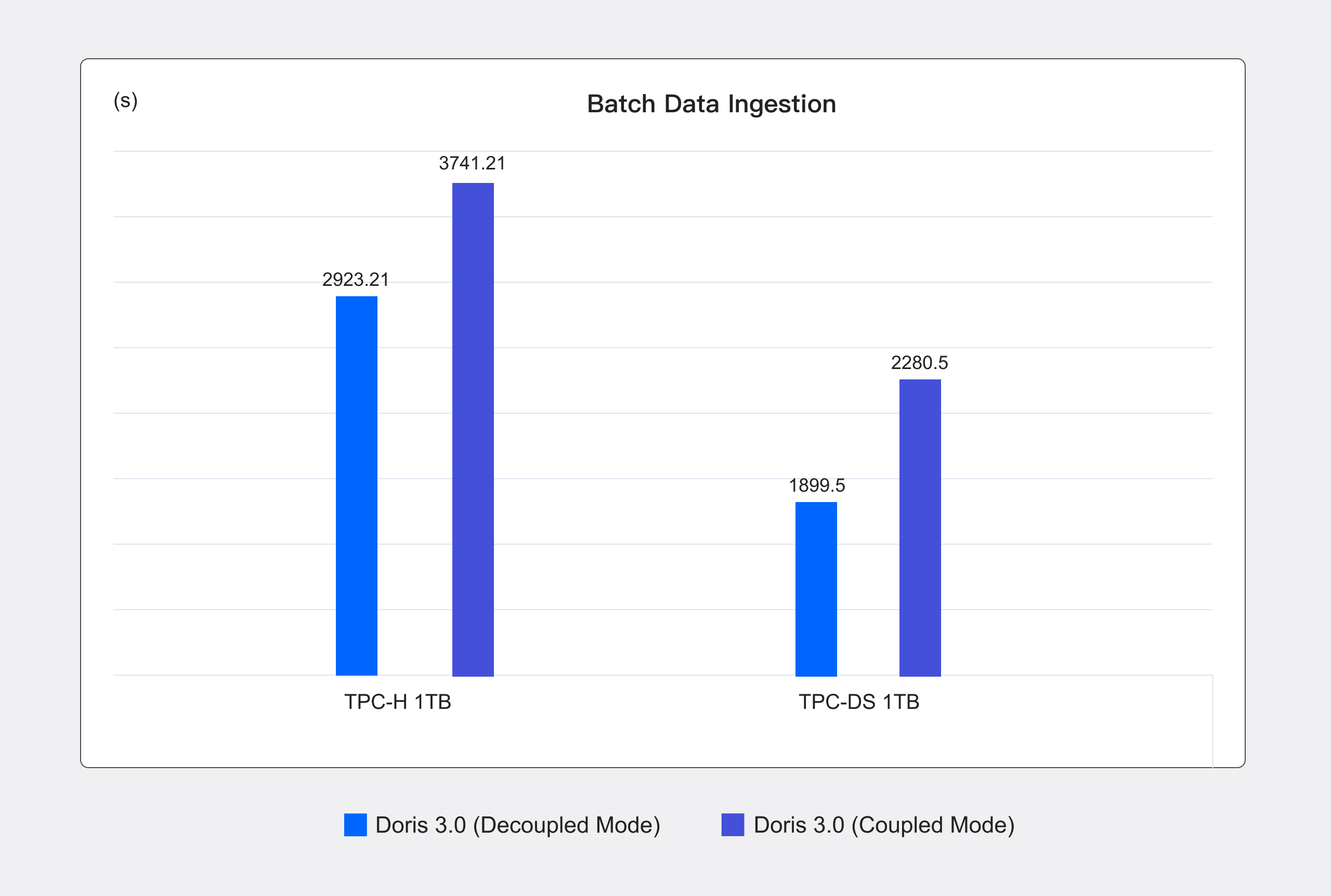
As is shown, even when using a single replica in both architectures, the compute-storage decoupled mode outperforms the coupled mode in batch data ingestion by 20.05% and 27.98% in the two benchmarks, respectively. (In real-world deployments, the coupled mode typically adopts a three-replica strategy. This further amplifies the write performance gains of the decoupled mode.)
02 Query Performance
In the compute-storage decoupled mode, Apache Doris leverages a multi-tier caching mechanism to accelerate queries. It improves overall query efficiency by speeding up data access and minimizing reliance on shared storage. The cache hierarchy includes:
- Doris Page Cache: In-memory caching of decompressed data.
- Linux Page Cache: In-memory caching of compressed data.
- Local Disk Cache: Persistent caching of compressed data.
Hardware configuration:
- Cluster size: 4 compute instances (1 FE, 3 BE)
- CPU: 48 cores per instance
- Memory: 192GB per instance
- Network Bandwidth: 21 Gbps
- Storage: Enhanced SSD
We conducted performance benchmarking under different caching scenarios in both compute-storage coupled and decoupled modes. Using the TPC-DS 1TB dataset, the test results are as follows:
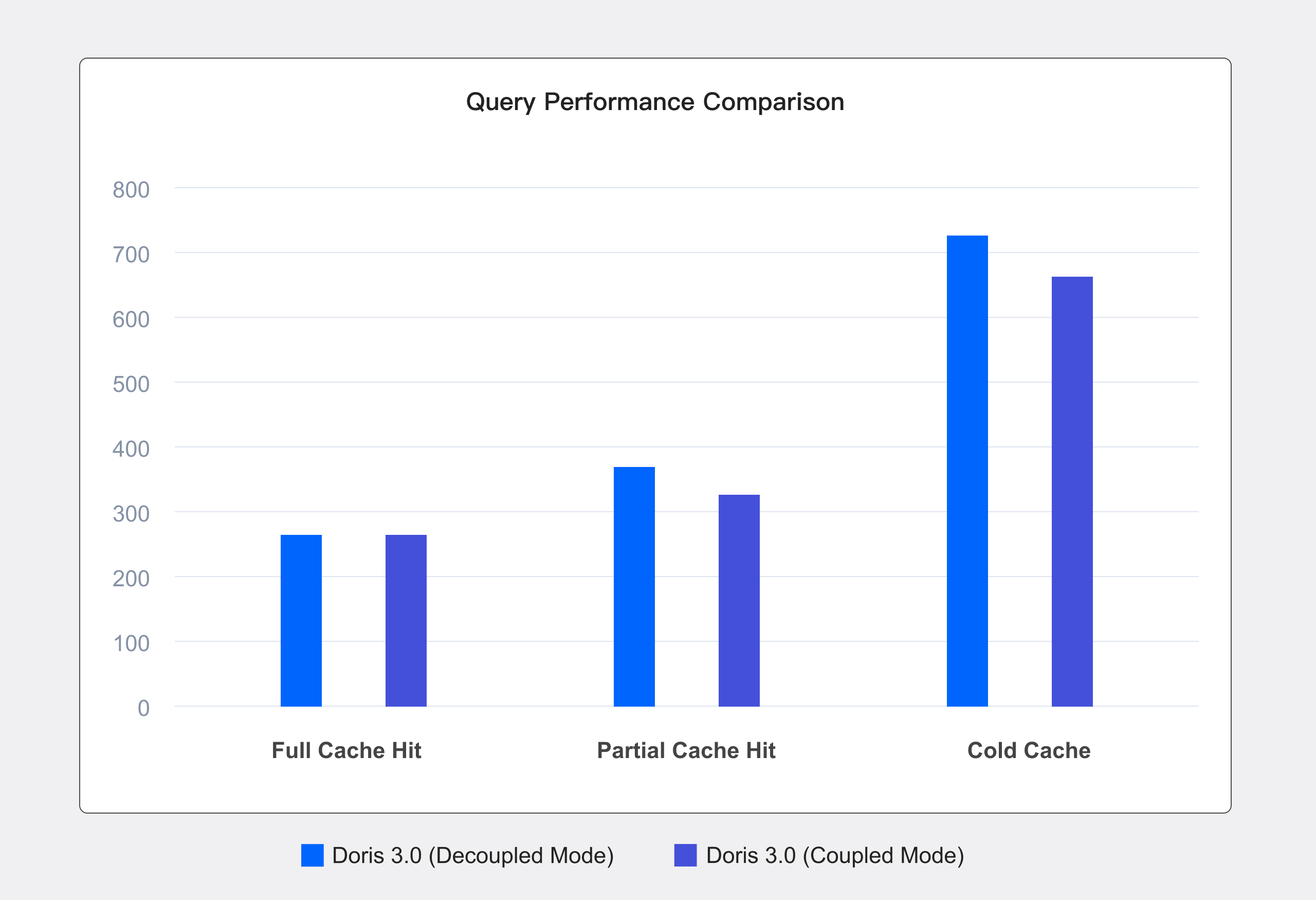
- Full cache hit: We execute the query twice and measure the runtime of the second execution, ensuring that all data is preloaded into the cache. Query performance in compute-storage decoupled mode matches that of the coupled architecture with no performance degradation.
- Partial cache hit (This scenario best reflects real-world usage.): Before the test begins, all caches are cleared, and we measure the runtime of the first execution while data is gradually loaded into the cache. Compared to the coupled architecture, query performance remains nearly identical, with an overall performance overhead of about 10%.
- No cache hit: All caches are cleared before each SQL execution, ensuring that every query runs without cached data. Compared to the coupled architecture, query performance sees an approximate 35% degradation.
03 Resource Cost
Operational cost for online workloads
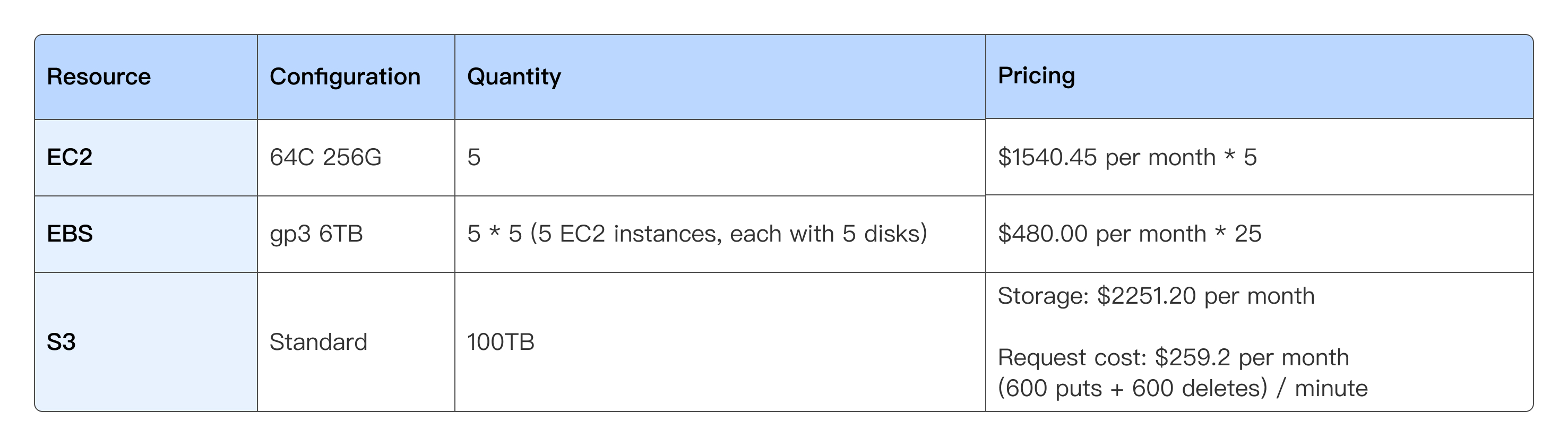
Taking a real-world enterprise workload as an example, we compare the cost differences between compute-storage coupled and decoupled modes in Apache Doris.
- Compute-storage coupled mode: The dataset in Doris has a size of 100TB per replica, resulting in a total of 300TB with three replicas. To prevent frequent scaling operations from impacting business stability, disk usage is maintained at about 50%. Thus, the monthly resource cost amounts to $36,962.7 (as detailed below).

- Compute-storage decoupled mode: With the same data scale, adopting the compute-storage decoupled model only requires storing a single replica in object storage, while hot data is cached on local disks. As shown below, the monthly resource cost is reduced to $22,212.65, achieving a 40% cost savings.
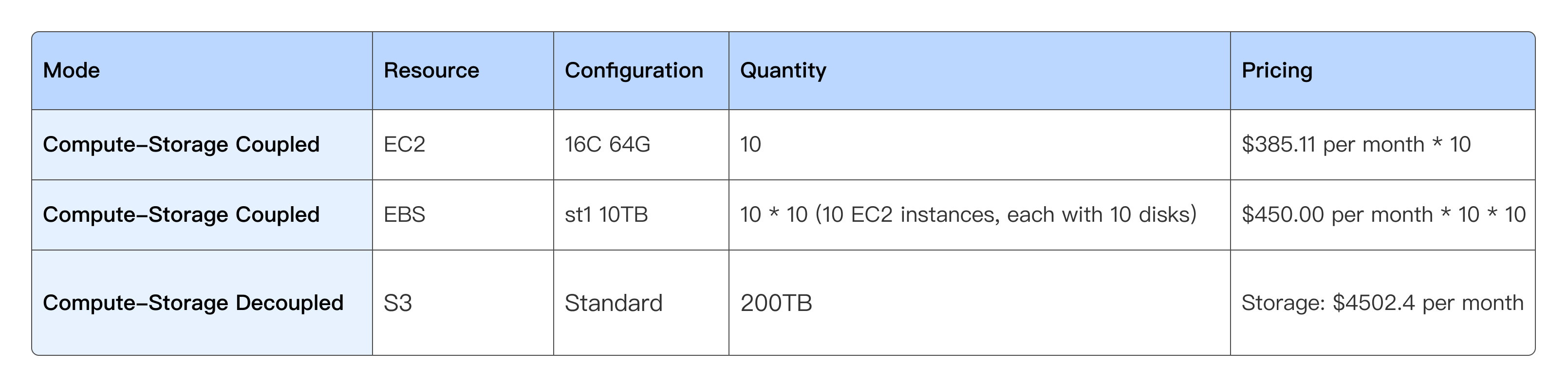
Historical data cost
For example, with 200TB of historical data, the resource utilization under both the compute-storage coupled and decoupled modes is shown below. The coupled model incurs a monthly cost of $48,851.10, whereas the decoupled model reduces the cost to just $4,502.40—cutting expenses by over 90%.
What's next
Powered by compute-storage decoupling, Apache Doris excels in real-time analytics, lakehouse analytics, observability and log storage & analysis. Looking ahead, Apache Doris will continue to enhance its capabilities in this mode. We will introduce new features such as snapshots, time travel, and Cross-Cluster Replication (CCR) support, and achieve stateless FE to further improve system stability and usability.
If you're interested in Apache Doris' compute-storage decoupled mode and its future development, we invite you to join the #compute-storage-decoupled channel in the Apache Doris Slack community, where you can connect with core developers and users. We look forward to your thoughts and contributions!
Join us live on March 27 for more insights into the Apache Doris compute-storage decoupled mode!