How Apache Doris supercharges Cisco WebEx’s data platform
Cisco WebEx is one of the world’s leading real-time conferencing platforms. It is trusted by over 95% of Fortune 500 companies and supports more than 1.5 million meetings daily.
The growing user base and data volume drives WebEx to build a data platform with stronger capabilities.
It has replaced its complex, multi-system architecture (Trino, Pinot, Iceberg, Kyuubi) with a unified solution based on Apache Doris. Doris now powers both its data lakehouse and query engine, improving performance and stability while reducing costs by 30%. This new architecture already supports critical projects in Cisco like CCA Peak Ports, dashboards, and unified authentication.
Why Cisco turned to Apache Doris
It all started with their old data architecture.
Platform 1.0: Trino, Kyuubi, Pinot, Iceberg
Previously, WebEx used Kafka for data ingestion, a Unified Data Platform (UDP) to schedule Spark and Flink jobs, and Iceberg for data management. Queries were served by Trino and Kyuubi, while Pinot handled OLAP.

While this setup worked, its complexity gave birth to issues like:
- Maintenance difficulty: Maintaining multiple databases simultaneously made operations complex and error-prone.
- Poor resource utilization: Multiple systems led to data redundancy and scattered query entry points, so CPU and memory were often underused or inefficiently allocated.
- Data inconsistency: Inconsistent calculations across different systems produced conflicting results, which were frustrating.
- Data governance challenges: The fragmented metadata sources and varied formats made it difficult to ensure accuracy, consistency, and trust across the platform.
Given these challenges, the most urgent need for Cisco was to consolidate their technology stack and reduce system complexity.
Platform 2.0: Apache Doris
After evaluating several solutions, they found Apache Doris to be an ideal fit because it offers data lakehouse capabilities through its Multi-Catalog feature. Multi-Catalog enables unified analytics across diverse data sources (including Hive, Iceberg, Hudi, Paimon, Elasticsearch, MySQL, Oracle, and SQL Server) without physically centralizing the data.
So they replace Apache Iceberg with Apache Doris as the data lakehouse, and also use Doris as the unified analytics engine instead of the combination of Trino, Kyuubi, and Pinot.

Apache Doris can query data in place without moving it. This eliminates data transfers and unlocks real-time analytics. The benefits are clear:
- There are less dependency chains and integration overhead.
- Complex ETL and Spark Load processes are replaced by Doris' Routine Load, where Doris directly and continuously consumes data from Kafka.
- A single Doris cluster now replaces multiple legacy systems, removing redundant storage and improving CPU and memory utilization. As a result, infrastructure costs are cut by 30%.
- Fewer moving parts mean fewer points of failure. Simplified architecture enhances system stability and reduces the burden on engineering teams.
While we’ve covered the technical wins from the architecture overhaul, let’s not forget that data architecture exists to serve the business. So how has this transformation actually moved the needle for Cisco’s business?
Unity drives efficiency
Fresher data and faster report generation
The CCA Peak Ports project in Cisco is designed to generate reconciliation reports between WebEx and its partners based on the Peak Ports billing model.
The Apache Doris–based transformation has simplified the data processing pipeline. As a result:
- Data freshness: The report is updated the next day instead of two days later.
- Query performance: A report can be generated within 5 minutes instead of 10 minutes.
Old solution
The old system relied on raw tables in an Oracle database as the data source. A series of stored procedures were executed to generate intermediate results. Then, a scheduled task written in Java further processed these intermediate results and wrote the final output to a Kafka message queue. Finally, a Spark job synchronized the data from Kafka to Iceberg to provide report services.
New solution
All data is pre-stored in Kafka. Then, using the Doris Kafka Connector and Routine Load, data is directly ingested from Kafka topics into Doris, where it is integrated into detailed tables to form the DWD (Data Warehouse Detail) layer. Pre-scheduled Spark jobs then perform deep analysis and transformation on the DWD data. The final results are written into the DWS (Data Warehouse Summary) layer, enabling business-side analytics and report generation directly through Doris.
Less failures and higher reliability
Cisco designs a dashboard system to provide an overview of data governance, with a particular focus on the WebEx data asset landscape and related analytical metrics. It serves as a data foundation to support business decision-making for the management team.
Old solution
In the early stages of the data governance platform, the system relied on scheduled Spark jobs to extract data for schema analysis and lineage analysis. The results were then sent to Kafka, and subsequently ingested in real time by Pinot for further processing and visualization. However, data exchange and synchronization across multiple components led to additional overhead and latency.
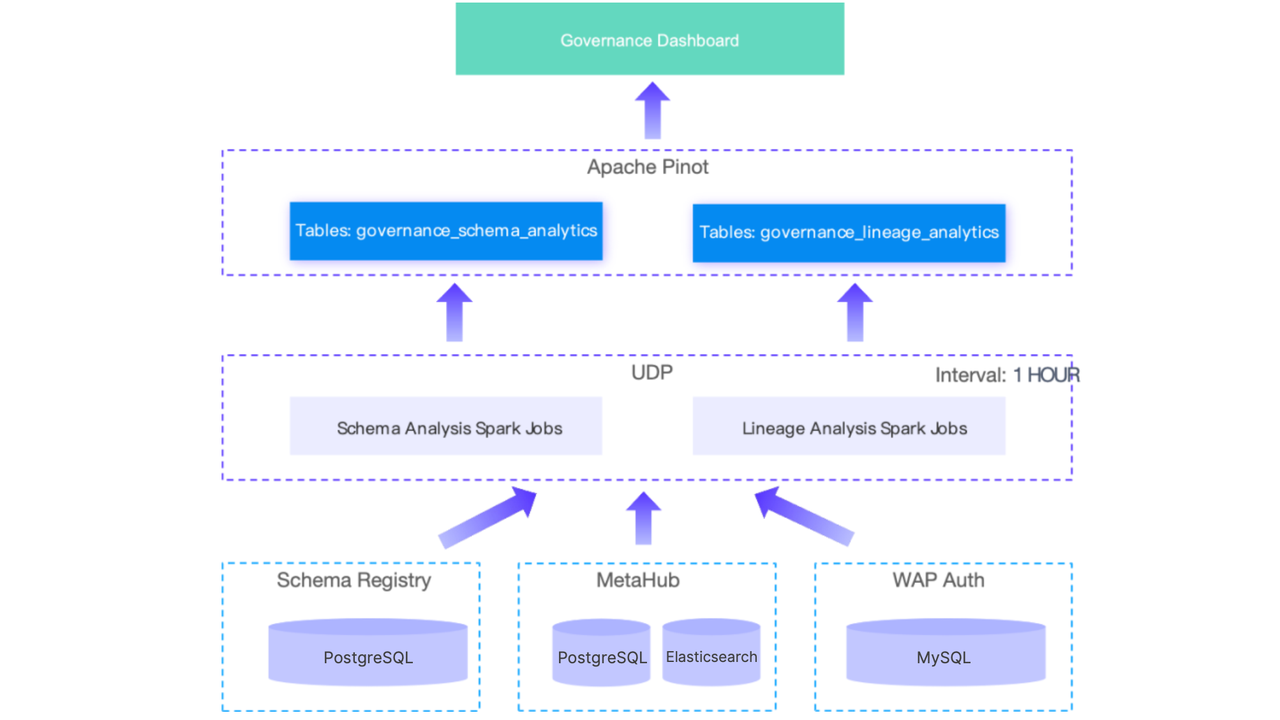
New solution
Pinot is replaced by Apache Doris. Leveraging the Multi-Catalog capability in Apache Doris, data is extracted from each engine through scheduled Doris tasks, and then written into primary key tables and aggregate tables.
This approach eliminates the need to maintain 11 separate Spark jobs, allowing the entire data pipeline to be created and managed within Doris.
In addition, the new architecture reduces dependency on CPU and memory resources previously required by the UDP, avoiding job failures caused by occasional resource constraints. Compared to Pinot, Doris consistently consumes fewer resources for the same queries, thereby improving reliability and stability of results.

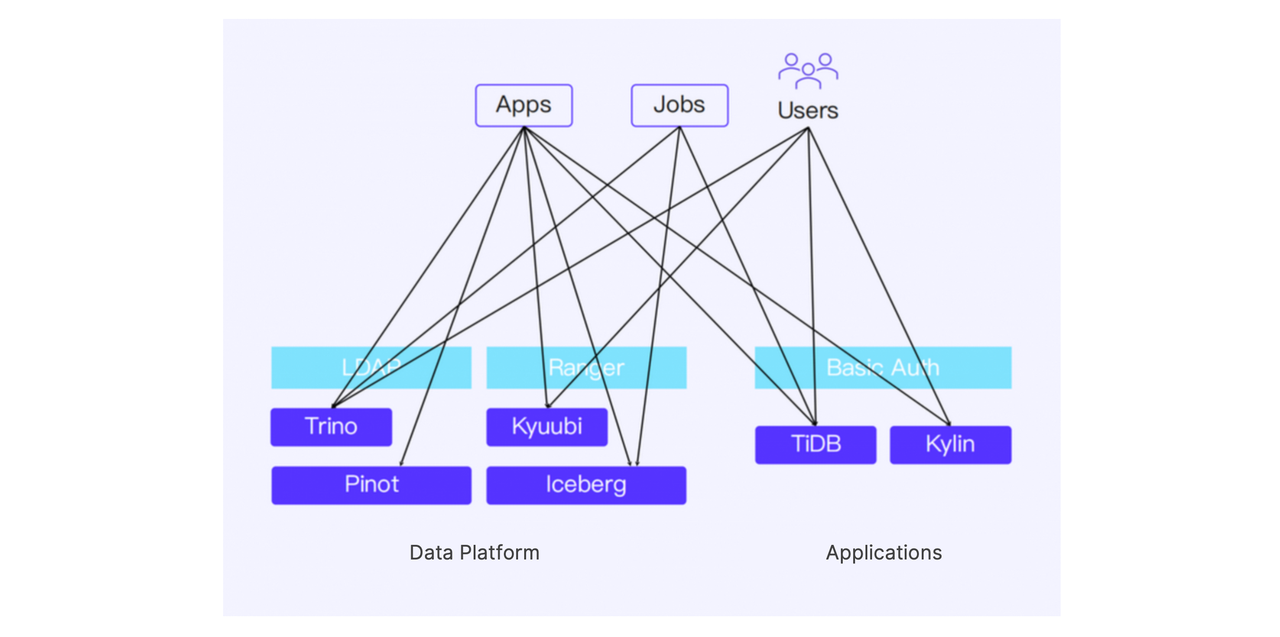
Unified access control: one platform instead of three
Old solution
In the early authentication and authorization setup, problems exist such as fragmented query entry points and varying query complexity across users. This not only led to inefficient resource utilization, but also increased the risk of resource-intensive queries degrading the performance of others.
From the user’s perspective, additional friction came from the need to manage connections across multiple systems, each with inconsistent password update cycles. As a result, users frequently had to reapply for authentication and authorization, consuming significant time and effort.
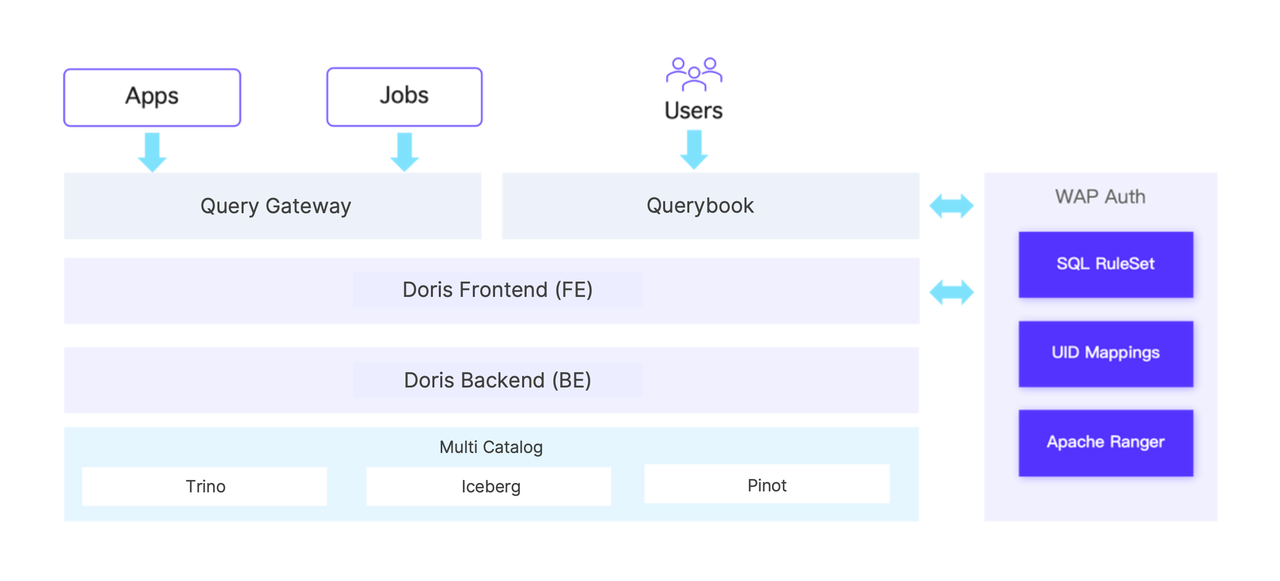
New solution
The new system adopts Doris as a unified query service and enables centralized data access across multiple engines, including Trino, Iceberg, and Pinot.
To enhance usability, a Querybook service was introduced for all users, providing a consistent interface for querying data from the data lake. Additionally, a unified authentication and authorization service, Web Auth, was built on top of Apache Ranger, and integrated with Doris for seamless access control.
Previously, users and administrators had to request and approve permissions across three separate platforms (LDAP, Ranger, and the database). Now, access is managed centrally through WAP Auth.
Furthermore, a SQL Ruleset Module was developed within Web Auth to synchronize rule definitions with Doris. This enables interception of high-risk SQL queries, helping prevent potential resource abuse.
Use case summary
Cisco currently operates five Doris clusters with dozens of nodes for its WebEx data platform, which supports an average of over 100,000 queries per day for online services, with daily real-time data ingestion reaching more than 5TB.
The adoption of Doris has not only contributed to cost reduction and efficiency gains, but has also driven broader exploration in the platform’s architecture and business expansion strategy. These include gradually migrating more business and application-layer workloads from their old data lakehouse into Doris, replacing self-managed analytic storage solutions such as TiDB and Kylin with Doris, and exploring emerging use cases such as AI on Doris and Doris on Paimon.
If you're looking to integrate Apache Doris into your data architecture and leverage its powerful capabilities, join the community for discussions, advice, and technical support!
