Another big leap: Apache Doris 2.1.0 is released
Dear Apache Doris community, we are thrilled to announce the advent of Apache Doris 2.1.0. In this version, you can expect:
-
Higher out-of-the-box query performance: 100% faster speed proven by TPC-DS 1TB benchmark tests.
-
Improved data lake analytics capabilities: 4~6 times faster than Trino and Spark, compatibility with various SQL dialects for smooth migration, read/write interface based on Arrow Flight for 100 times faster data transfer.
-
Solid support for semi-structured data analysis: a newly-added Variant data type, support for more IP types, and a more comprehensive suite of analytic functions.
-
Materialized view with multiple tables: a new feature to accelerate multi-table joins, allowing transparent rewriting, auto refresh, materialized views of external tables, and direct query.
-
Enhanced real-time writing efficiency: faster data writing at scale powered by AUTO_INCREMENT column, AUTO PARTITION, forward placement of MemTable, and Group Commit.
-
Better workload management: optimizations of the Workload Group mechanism for higher performance stability and the display of SQL resource consumption in the runtime.
We appreciate the 237 contributors who made nearly 6000 commits in total to the Apache Doris project, and the nearly 100 enterprise users who provided valuable feedback. We will keep aiming for the stars with our agile release planning, and we appreciate your feedback in the Apache Doris developer and user community.
Download from GitHub: https://github.com/apache/doris/releases
Download from website: https://doris.apache.org/download
Higher performance
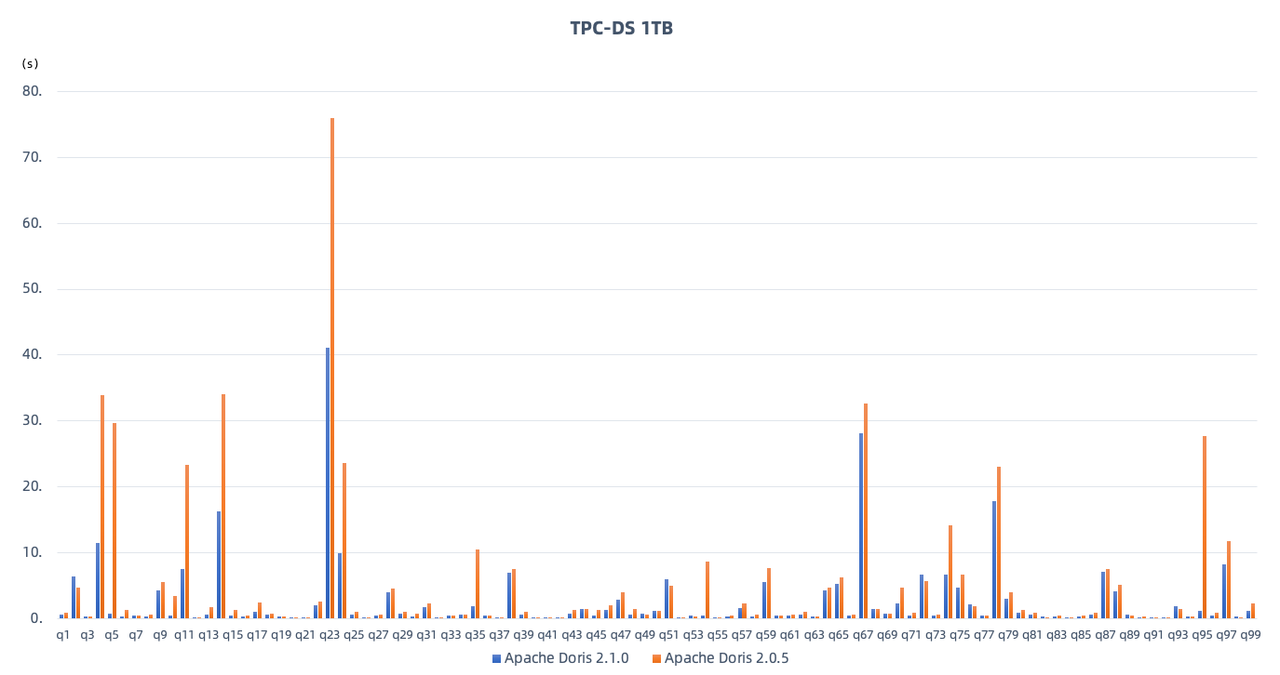
Apache Doris V2.1 makes a big leap in out-of-the-box query performance. It can deliver high performance even for complicated SQL queries without any fine-tuning. TPC-DS 1TB benchmark tests with 1 Frontend and 3 Backends (48C, 192G each) show that:
-
The total query execution time of V2.1.0 is 245.7s, up 100% from the 489.6s of V2.0.5;
-
V2.1 is more than twice as fast as V2.0.5 on one-third of the total 99 SQL queries, and outperforms V2.0.5 on over 80 of the SQL queries;
-
V2.1 delivers better performance in data filtering, sorting, aggregation, multi-table joins, sub-queries, and window function computation.
Meanwhile, we have compared Doris V2.1.0 against many other OLAP systems with the same hardware environment under various data sizes. Recurring results show that Doris is undoubtedly far ahead.
Smarter optimizer
In our last big release, we introduced a new query optimizer that enables fast performance for most use cases without any manual fine-tuning. Now, the V2.1 query optimizer is an upgrade on that basis. It comes with:
-
More solid infrastructure: We have improved the statistics-based inference and the cost model that underpin the query optimizer, so it can collect statistical information from a wider range to undertake more complicated optimization tasks.
-
Extended optimization rules: Absorbing feedback from our many actual use cases, we have improved many frequently used rules (operator pushdown, etc.) and introduced new rules to fit in more scenarios.
-
Enhanced enumeration framework: Building on Cascades and DPhyper, the V2.1 query optimizer has a clearer enumeration strategy that achieves a better balance between quality and efficiency. For example, we have dialed up the default limit of query plans in the enumeration table from 5 to 8, and then we have sharpened the DPhyper enumeration capabilities to produce better query plans.
Better heuristic optimization
In large-scale data analytics or data lake scenarios, it is always challenging and time-consuming to collect statistical information to provide references for query plans. For that, the V2.1 query optimizer, leveraging a combination of heuristic technologies, is able to generate high-quality query plans without statistical reference. Meanwhile, the RuntimeFilter is part of the trick. It is now more self-adaptive. It can self-adjust the predicates in expressions during execution, so it can enable higher performance without statistical information.
Parallel Adaptive Scan
A complex data query will involve large sums of data scanning, during which the scan I/O can be the bottleneck for query execution speed. That's why we have Parallel Scan, which means one scan thread can read multiple tablets (buckets). However, that is highly dependent on the bucket number you set for data partitioning in the first place. If the user has set an inappropriate number of buckets, the scan thread will not be able to work parallelly.
That's why we have adopted Parallel Adaptive Scan in Doris V2.1. What happens is that the tablets are pooled so the scanning process can be divided into a flexible number of threads based on the total number of rows. (The upper limit is 48 threads.) In this way, users no longer have to worry that their query speed might be dragged down by unreasonable bucket numbers.
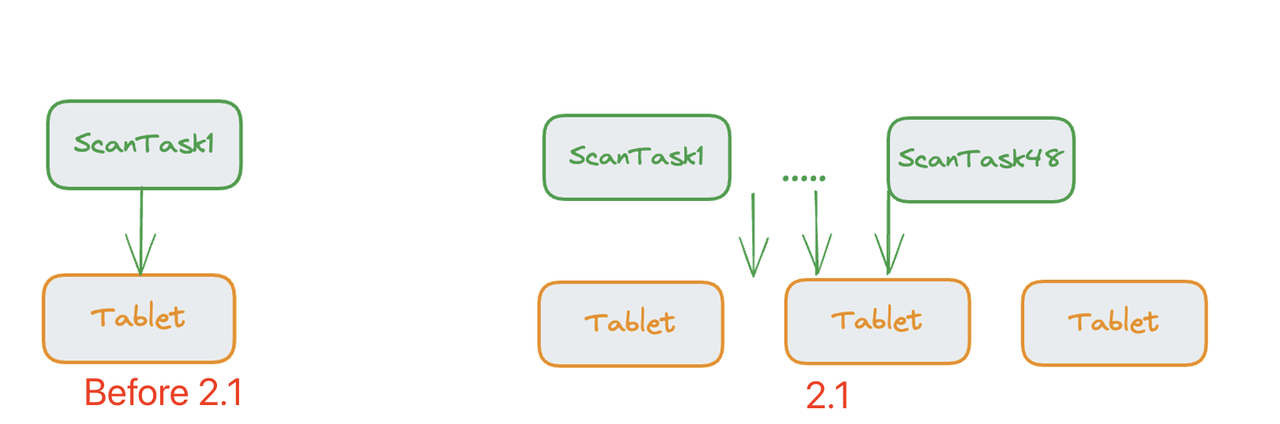
In 2.1 and future versions, we recommend that you set the number of buckets equal to the total number of disks in the cluster, in order to fully utilize the I/O resources of the entire cluster.
Parallel Adaptive Scan is currently available for the Duplicate Key model and the Merge-on-Write tables of the Unique Key model. We plan to add it to the Aggregate Key model and the Merge-on-Read tables of the Unique Key model in version 2.1.1.
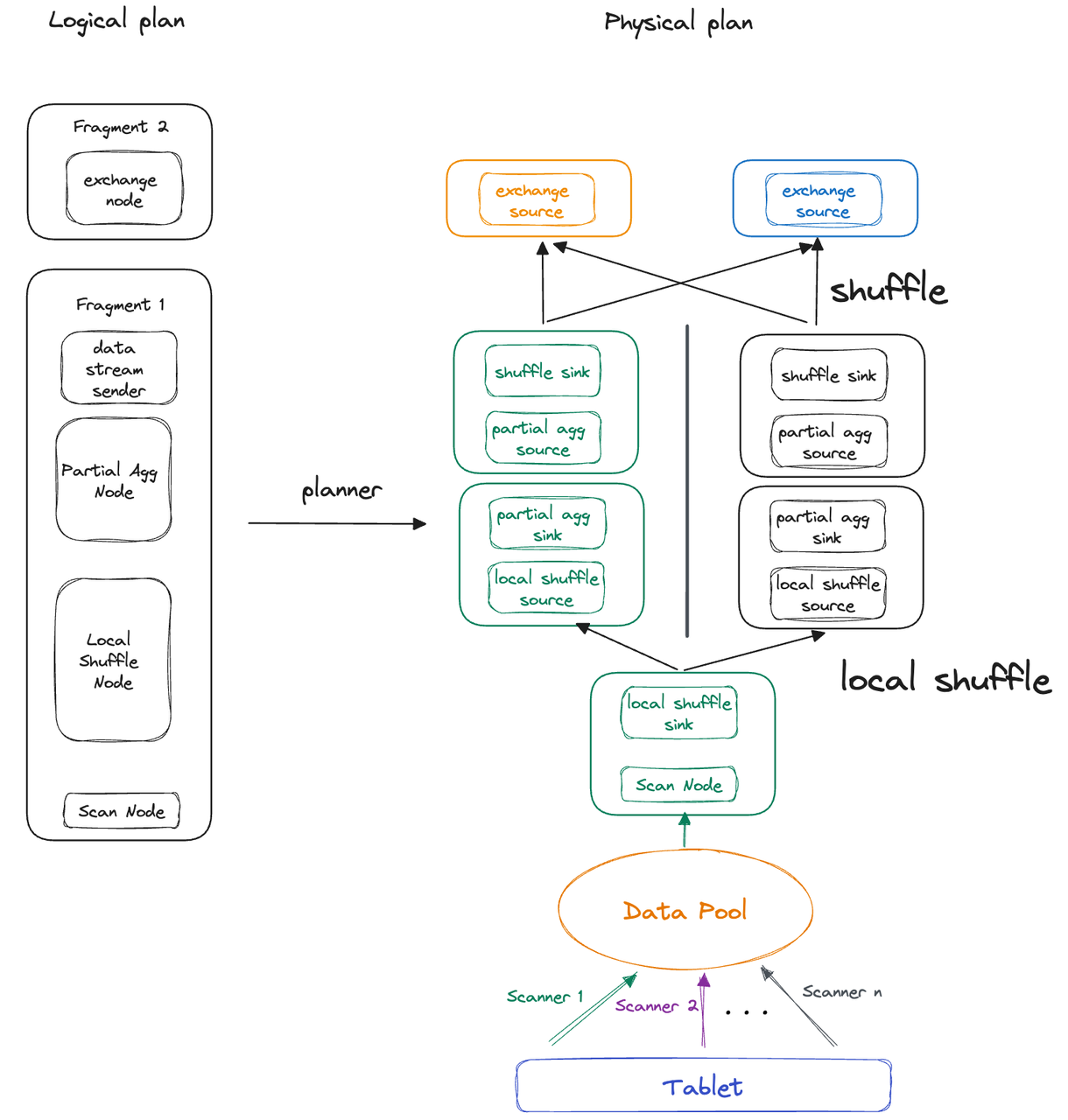
Local Shuffle
We have introduced Local Shuffle to prevent uneven data distribution. Benchmark tests show that Local Shuffle in combination with Parallel Adaptive Scan can guarantee fast query performance despite unreasonable bucket number settings upon table creation.
For queries across multiple instances, uneven data distribution can prolong the query execution time. To address data skew across instances on a single backend (BE), we have introduced Local Shuffle in V2.1. It aims to shuffle and distribute data as evenly as possible, thereby accelerating queries. For example, in a typical aggregation query, a Local Shuffle node will redistribute the data evenly across different pipeline tasks, before the data is aggregated.
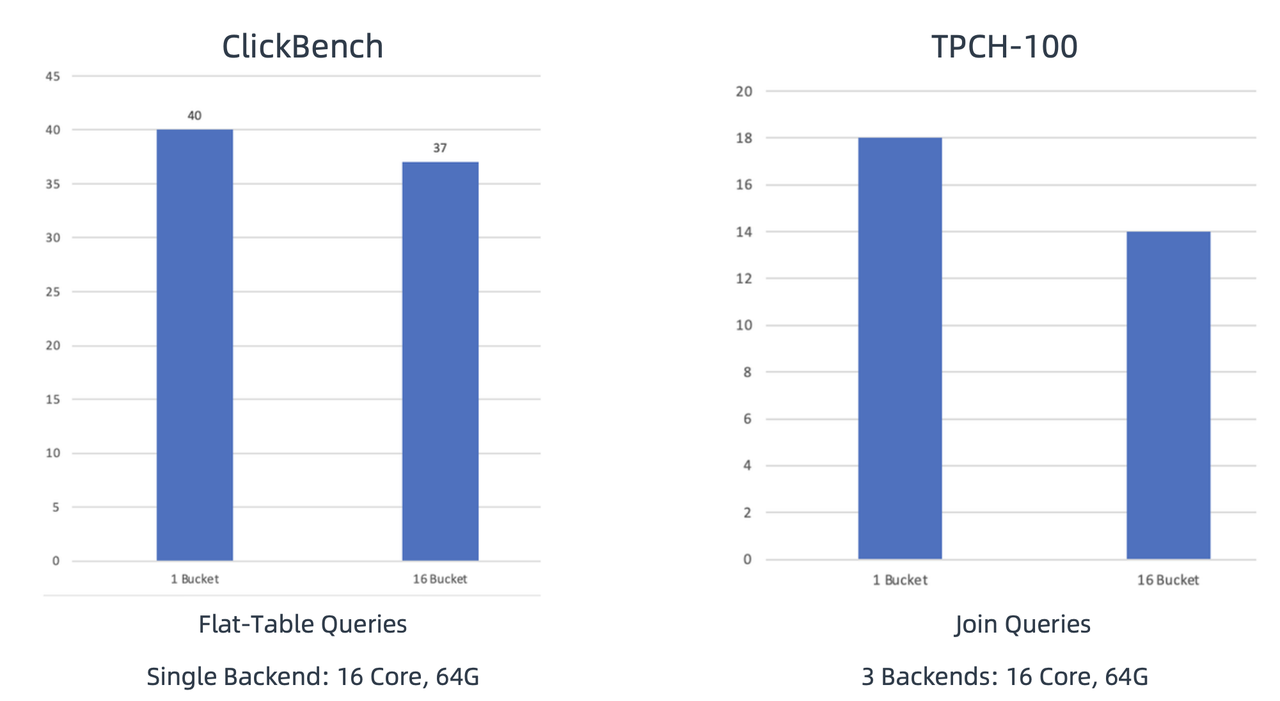
For a proof of concept, we have simulated unreasonable bucket number settings. Firstly, we use the ClickBench dataset and run flat-table queries with the bucket number being 1 and 16, respectively. Then, we use the TPC-H 100G dataset and run join queries with 1 bucket and 16 buckets in each partition, respectively. Results from the runs show minimal fluctuations, which means the combination of Parallel Adaptive Scan and Local Shuffle is able to guarantee high query performance even with inappropriately sharded or unevenly distributed data.
Increase performance on ARM
V2.1 is specifically adapted to and optimized for ARM architecture. Compared to Doris 2.0.3, it has achieved over 100% performance improvement on multiple test datasets:
-
ClickBench large flat-table queries: The execution time of 43 SQL queries for V2.1 adds up to 30.73 seconds, as compared to 102.36 seconds for V2.0.3, representing a 230% speedup.
-
TPC-H multi-table joins: The execution time of 22 SQL queries for V2.1 adds up to 90.4 seconds, as compared to 174.8 seconds for V2.0.3, representing a 93% speedup.
Improved data lake analytics capabilities
Data lake analytic performance
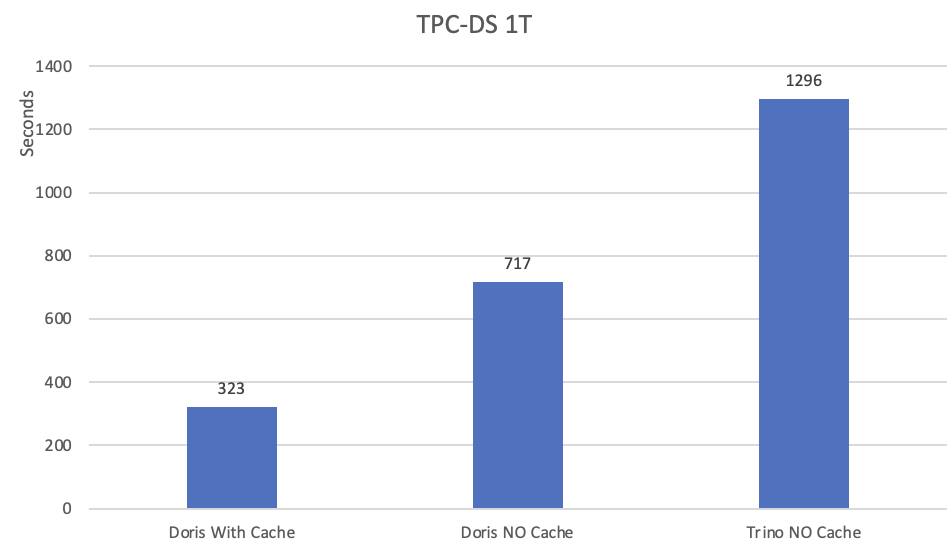
V2.1 also reaches new heights in data lake analysis. According to TPC-DS benchmark tests (1TB) of Doris V2.1 against Trino V435,
-
Without caching, Apache Doris is 45% faster than Trino, with their total execution time being 717s and 1296s, respectively. Specifically, Doris outperforms Trino in 80% of the total 99 SQL queries.
-
If you enable file cache, you can expect another 2.2-time speedup from Doris (323s). That is 4 times the speed of Trino, with a straight win in all 99 SQL queries.
In addition, TPC-DS 10TB benchmark tests show that Apache Doris 2.1 is 4.2 times as fast as Spark 3.5.0 and 6.1 times as Spark 3.3.1.
This is achieved by a series of optimizations in I/O for HDFS and object storage, parquet/ORC file reading, floating-point decompression, predicate pushdown, caching, and scan task scheduling. It is also built upon a more precise cost model in the optimizer and more accurate statistics collection for different data sources.
SQL dialects compatibility
SQL incompatibility used to bother our users when they migrated from their existing OLAP systems (built on Clickhouse, Trino, Presto, Hive, etc.) to Doris, because they had to modify and update a significant amount of business query logic. Also, if they tried to use Doris as a unified data analysis gateway, they would also need to integrate it with their Hive or Spark systems, and incompatible SQLs could make it tough.
To facilitate a smooth migration or integration, we have enabled SQL dialect conversion in V2.1. Users can continue using the SQL dialect they are used to after simply setting the SQL dialect type for the current session in Doris.
So far, the ClickHouse, Presto, Trino, Hive, and Spark SQL dialects have been supported in this experimental feature. For example, by set sql_dialect = "trino", you can perform queries using Trino SQL syntax, without any modifications. Tests in user production environment show that Doris V2.1 is compatible with 99% of Trino SQL.
High-speed data interface for 100-fold performance
Most big data systems today adopt columnar in-memory data formats and interact with other database systems using MySQL/JDBC/ODBC protocols. That means during data transfer, there is a need to covert the data from columnar format to row-based format to fit in with the MySQL/JDBC/ODBC protocols, and then vice versa. This serialization and deserialization process slows down the data transfer speed, which becomes more noticeable when the data size is huge, like in data science scenarios.
Apache Arrow is a columnar in-memory format designed for large-scale data processing. It has efficient data structures that facilitate faster data transfer across different systems. If both the source database and target client support Arrow Flight SQL protocol, data transfer between them will entail no data serialization and deserialization. That can cut down a huge chunk of overheads. Moreover, Arrow Flight can give full play to the multi-node and multi-core architecture to parallelize operations and thus increase throughputs.
![]()
Reading data from Apache Doris using Python used to be a complex process. Firslty, data blocks in Doris had to be converted from its columnar format into row-based bytes. Then, in the Python client, the data had to be deserialized into a Pandas data structure. These steps largely slow down data transfer.
Now this is revolutionized in Doris V2.1, where we provide a high-throughput data read/write interface based on Arrow Flight: HTTP Data API. Using Arrow Flight SQL, Doris converts the columnar data blocks into Arrow RecordBatch, which is also in columnar format. Then, in the Python client, Arrow RecordBatch is converted into column-oriented Pandas DataFrame. Both conversions are highly efficient and involve no serialization and deserialization.
This allows fast data access to Apache Doris by data science tools like Pandas and Numpy, which means Apache Doris can be seamlessly integrated with the entire AI and data science ecosystem. This unveils a future of endless possibilities.
conn = flight_sql.connect(uri="grpc://{FE_HOST}:{fe.conf:arrow_flight_sql_port}", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
According to our comparative tests using different MySQL clients for the common data types, the Arrow Flight SQL protocol delivers almost 100 times faster performance than the MySQL protocol in data transfer.
![]()
Other improvements
-
Paimon Catalog: upgrade to Paimon 0.6.0, optimized reading of Read Optimized tables, able to bring 10-fold speeds when Paimon data is fully merged
-
Iceberg Catalog: upgrade to Iceberg 1.4.3, fixed compatibility issues in AWS S3 authentication
-
Hudi Catalog: upgrade to Hudi 0.14.1, fixed compatibility issues in Hudi Flink Catalog
Materialized view with multiple tables
As a typical "trade disk space for time" strategy, materialized views pre-compute and store SQL query results so that when the same queries are requested, the materialized view table can directly provide the results. This increases query performance and reduces resource consumption by avoiding repetitive computation.
Previous versions of Doris offer strong consistency for single-table materialized views, ensuring atomicity between the base table and the materialized view table. They also support smart routing for query statements on materialized views, allowing for efficient query execution.
What's more exciting is that, in V2.1, we have introduced materialized views with multiple tables (also known asasynchronous materialized view). As the name implies, you can build a materialized view across tables. It can be based on full data or incremental data, and it can be refreshed manually or periodically. For multi-table joins or large data scale scenarios, the optimizer transparently rewrites queries based on the cost model and automatically searches for the right materialized view for optimal query performance. You can build asynchronous materialized views for external tables, and you can perform queries on these views directly. In other words, this can be a game changer for data warehouse layering, data modeling, job scheduling, and data processing.
Now let's get started:
1. Create the tables:
use tpch;
CREATE TABLE IF NOT EXISTS orders (
o_orderkey integer not null,
o_custkey integer not null,
o_orderstatus char(1) not null,
o_totalprice decimalv3(15,2) not null,
o_orderdate date not null,
o_orderpriority char(15) not null,
o_clerk char(15) not null,
o_shippriority integer not null,
o_comment varchar(79) not null
)
DUPLICATE KEY(o_orderkey, o_custkey)
PARTITION BY RANGE(o_orderdate)(
FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(o_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into orders values
(1, 1, 'ok', 99.5, '2023-10-17', 'a', 'b', 1, 'yy'),
(2, 2, 'ok', 109.2, '2023-10-18', 'c','d',2, 'mm'),
(3, 3, 'ok', 99.5, '2023-10-19', 'a', 'b', 1, 'yy');
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey integer not null,
l_partkey integer not null,
l_suppkey integer not null,
l_linenumber integer not null,
l_quantity decimalv3(15,2) not null,
l_extendedprice decimalv3(15,2) not null,
l_discount decimalv3(15,2) not null,
l_tax decimalv3(15,2) not null,
l_returnflag char(1) not null,
l_linestatus char(1) not null,
l_shipdate date not null,
l_commitdate date not null,
l_receiptdate date not null,
l_shipinstruct char(25) not null,
l_shipmode char(10) not null,
l_comment varchar(44) not null
)
DUPLICATE KEY(l_orderkey, l_partkey, l_suppkey, l_linenumber)
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into lineitem values
(1, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-17', '2023-10-17', '2023-10-17', 'a', 'b', 'yyyyyyyyy'),
(2, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-18', '2023-10-18', '2023-10-18', 'a', 'b', 'yyyyyyyyy'),
(3, 2, 3, 6, 7.5, 8.5, 9.5, 10.5, 'k', 'o', '2023-10-19', '2023-10-19', '2023-10-19', 'c', 'd', 'xxxxxxxxx');
CREATE TABLE IF NOT EXISTS partsupp (
ps_partkey INTEGER NOT NULL,
ps_suppkey INTEGER NOT NULL,
ps_availqty INTEGER NOT NULL,
ps_supplycost DECIMALV3(15,2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL
)
DUPLICATE KEY(ps_partkey, ps_suppkey)
DISTRIBUTED BY HASH(ps_partkey) BUCKETS 3
PROPERTIES (
"replication_num" = "1"
)
2. Create materialized view:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(l_shipdate)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
select l_shipdate, o_orderdate, l_partkey,
l_suppkey, sum(o_totalprice) as sum_total
from lineitem
left join orders on lineitem.l_orderkey = orders.o_orderkey
and l_shipdate = o_orderdate
group by
l_shipdate,
o_orderdate,
l_partkey,
l_suppkey;
To sum up, asynchronous materialized view in V2.1 supports:
-
Transparent rewriting: transparently rewrites common operators including Select, Where, Join, Group By, and Aggregation, for faster query speed. For example, in BI reporting, you can create materialized views for some particularly slow queries.
-
Auto refresh: periodic refresh, manual refresh, full refresh, (partition-based) incremental refresh.
-
Materialized view of external tables: You can build materialized views based on external data such as Hive, Hudi, and Iceberg tables. You can also synchronize data from data lakes into Doris internal tables via materialized views.
-
Direct query on materialized views: If you regard the making of materialized views as an ETL process, then the materialized views will be the result set of ETL. In this sense, materialized views can be seen as data tables, so users can conduct queries on them directly.
Enhanced storage
AUTO_INCREMENT column
AUTO_INCREMENT column is a common feature in OLTP databases. It provides an efficient way to automatically assign unique identifiers to newly inserted data rows. However, it is less commonly found in distributed OLAP databases because the value allocation for AUTO_INCREMENT columns involves global transactions.
As an MPP-based OLAP system, Apache Doris V2.1 implements AUTO_INCREMENT column with an innovative pre-allocation strategy. Leveraging the uniqueness guarantee provided by AUTO_INCREMENT, users can achieve efficient dictionary encoding and query pagination.
Dictionary encoding: AUTO_INCREMENT column is helpful for queries that require accurate deduplication, such as PV/UV calculation or user segmentation. Utilizing AUTO_INCREMENT column, you can create a dictionary table for string values like UserID or OrderID. Simply writing user data in batches or in real time to the dictionary table can generate a dictionary. Then, by applying various dimensional conditions, the corresponding bitmaps can be aggregated.
CREATE TABLE `demo`.`dictionary_tbl` (
`user_id` varchar(50) NOT NULL,
`aid` BIGINT NOT NULL AUTO_INCREMENT
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"enable_unique_key_merge_on_write" = "true"
);
Query pagination: Pagination is often necessary when displaying data on a webpage. Traditional pagination typically involves using limit, offset + order by in SQL queries. However, this can be inefficient in deep pagination queries, because even if only a small portion of the data is being requested, the database still needs to read and sort the entire dataset. This is addressed by AUTO_INCREMENT column. It generates a unique identifier for each row, remembers the maximum one from the previous page and uses it as a reference for retrieving the next page.
The following is an example, where unique_value is an AUTO INCREMENT column.
CREATE TABLE `demo`.`records_tbl2` (
`key` int(11) NOT NULL COMMENT "",
`name` varchar(26) NOT NULL COMMENT "",
`address` varchar(41) NOT NULL COMMENT "",
`city` varchar(11) NOT NULL COMMENT "",
`nation` varchar(16) NOT NULL COMMENT "",
`region` varchar(13) NOT NULL COMMENT "",
`phone` varchar(16) NOT NULL COMMENT "",
`mktsegment` varchar(11) NOT NULL COMMENT "",
`unique_value` BIGINT NOT NULL AUTO_INCREMENT
) DUPLICATE KEY (`key`, `name`)
DISTRIBUTED BY HASH(`key`) BUCKETS 10
PROPERTIES (
"replication_num" = "3"
);
In pagination display, where each page displays 100 records, this is how you can fetch the data of the first page:
select * from records_tbl2 order by unique_value limit 100;
The program marks down the maximum of unique_value in the returned result (assuming it is 99). This is how you can fetch the data of the second page:
select * from records_tbl2 where unique_value > 99 order by unique_value limit 100;
If you need data from the latter pages, for example, page 101, it will be difficult to retrieve the maximum unique_value of page 100, so this is how you can perform the query:
select key, name, address, city, nation, region, phone, mktsegment
from records_tbl2, (select unique_value as max_value from records_tbl2 order by uniuqe_value limit 1 offset 9999) as previous_data
where records_tbl2.uniuqe_value > previous_data.max_value
order by unique_value limit 100;
AUTO PARTITION
Before V2.1, Doris requires users to manually create data partitions before data ingestion, otherwise data loading will just fail. Now, to release burden on operation and maintenance, V2.1 allows AUTO PARTITION. Upon data ingestion, it detects whether a partition exists for the data based on the partitioning column. If not, it automatically creates one and starts data ingestion.
To apply AUTO PARTITION in Doris:
CREATE TABLE `DAILY_TRADE_VALUE`
(
`TRADE_DATE` datev2 NULL COMMENT 'Trade Date',
`TRADE_ID` varchar(40) NULL COMMENT 'Trade ID',
......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
AUTO PARTITION BY RANGE date_trunc(`TRADE_DATE`, 'year')
(
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
-
Currently, you can only specify one partitioning column for AUTO PARTITION, and it has to be NOT NULL.
-
It supports AUTO PARTITION by Range or by List. For the former, it supports
date_truncas the partitioning function, andDATEorDATETIMEformat for the partitioning column. For the latter, it does not support function calling, it supportsBOOLEAN,TINYINT,SMALLINT,INT,BIGINT,LARGEINT,DATE,DATETIME,CHAR, andVARCHARfor the partitioning column, and the values are enumeration values. -
For AUTO PARTITION by List, if there is no partition for a value in the partitioning column, Doris will create one for it.
100% faster INSERT INTO SELECT
INSERT INTO…SELECT is one of the most frequently used statements in ETL. It enables fast data migration, transformation, cleaning, and aggregation. That's why we've been optimizing its performance. In V2.0, we introduced Single Replica Load to reduce repetitive data writing and data compaction.
For further improvement, in V2.1, we have moved forward the execution of MemTable to reduce data ingestion overheads. Tests show that this can double the data ingestion speed in most cases compared to V2.0.
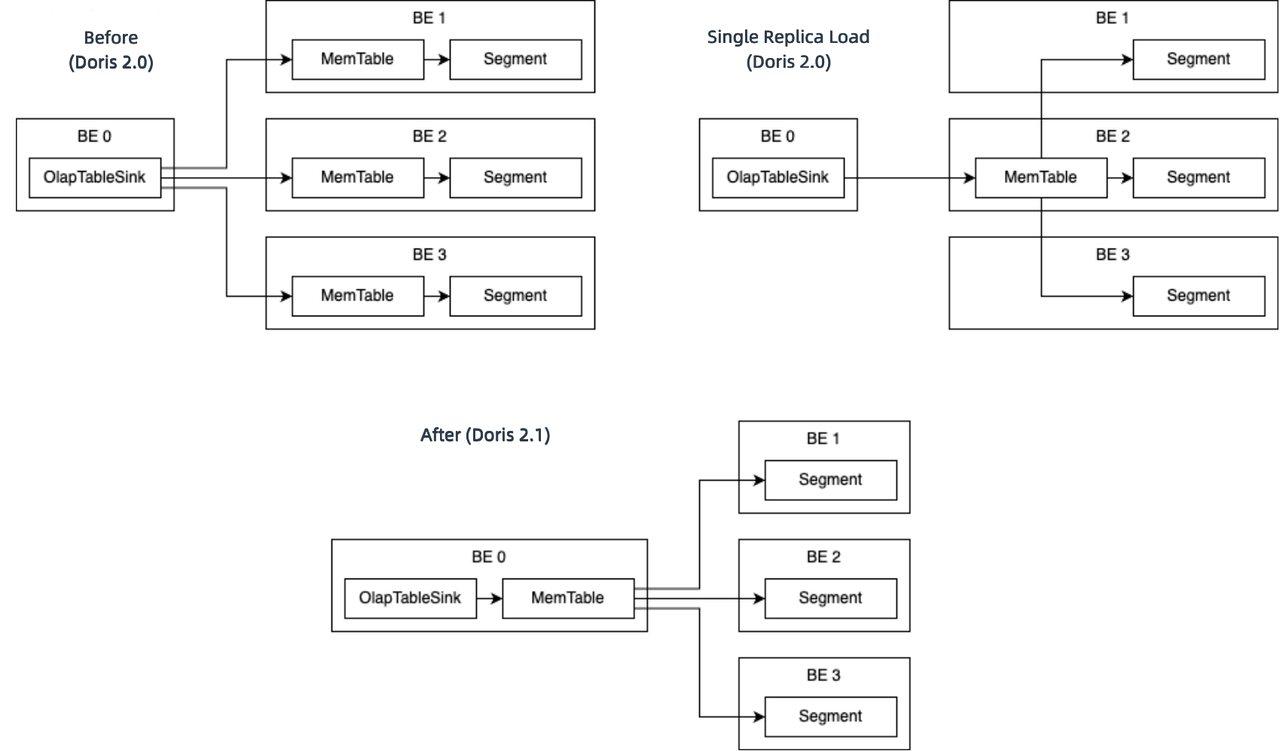
The process comparison before and after moving forward the execution of MemTable is illustrated above. The Sink node no longer sends encoded data blocks but instead processes MemTable locally and sends the generated segments to downstream nodes. This reduces the overheads caused by multiple data encoding and improves the speed and accuracy of memory backpressure. In addition, we have replaced Ping-Pong RPC with Streaming RPC so there will be less waiting during data transfer.
We've done tests to see how moving forward MemTable impacts data ingestion performance.
Test environment: 1 Frontend + 3 Backend, 16C 64G each node, 3 high-performance cloud disks (to make sure that disk I/O is not a bottleneck)
Test results:
In single-replica ingestion, the execution time of V2.1 is only 36% of what takes V2.0 to finish. In three-replica ingestion, that figure is 54%. This means, V2.1 has sped up the performance of INSERT INTO…SELECT by more than 100% in general.
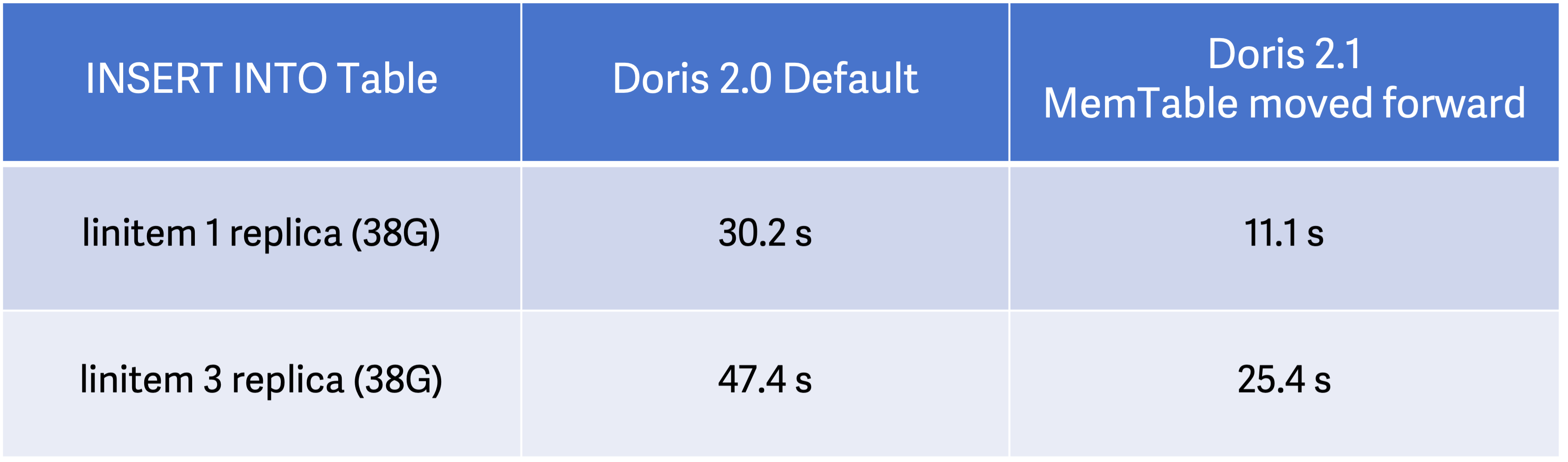
V2.1 moves forward the execution of MemTable by default, so you don't have to modify the data ingestion command. You can return to the old ingestion method by setting enable_memtable_on_sink_node=false in MySQL connection.
High-concurrency real-time data ingestion / Group Commit
For data writing, V2.1 has a back pressure mechanism to avoid excessive data versions, so as to reduce resource consumption caused by data version merging.
During data ingestion, data batches are written to an in-memory table and then written to disk as individual RowSet files. Each RowSet file corresponds to a specific data import version. The background compaction process automatically merges the RowSets, combining the small ones into a big one in order to increase query speed and reduce storage consumption. However, each compaction process consumes CPU, memory, and disk IO resources. The more frequently that data is written, the more RowSets are generated, and the more resources the compaction process consumes. The backpressure mechanism is a solution to this. It will throw a -235 error when there are too many data versions.
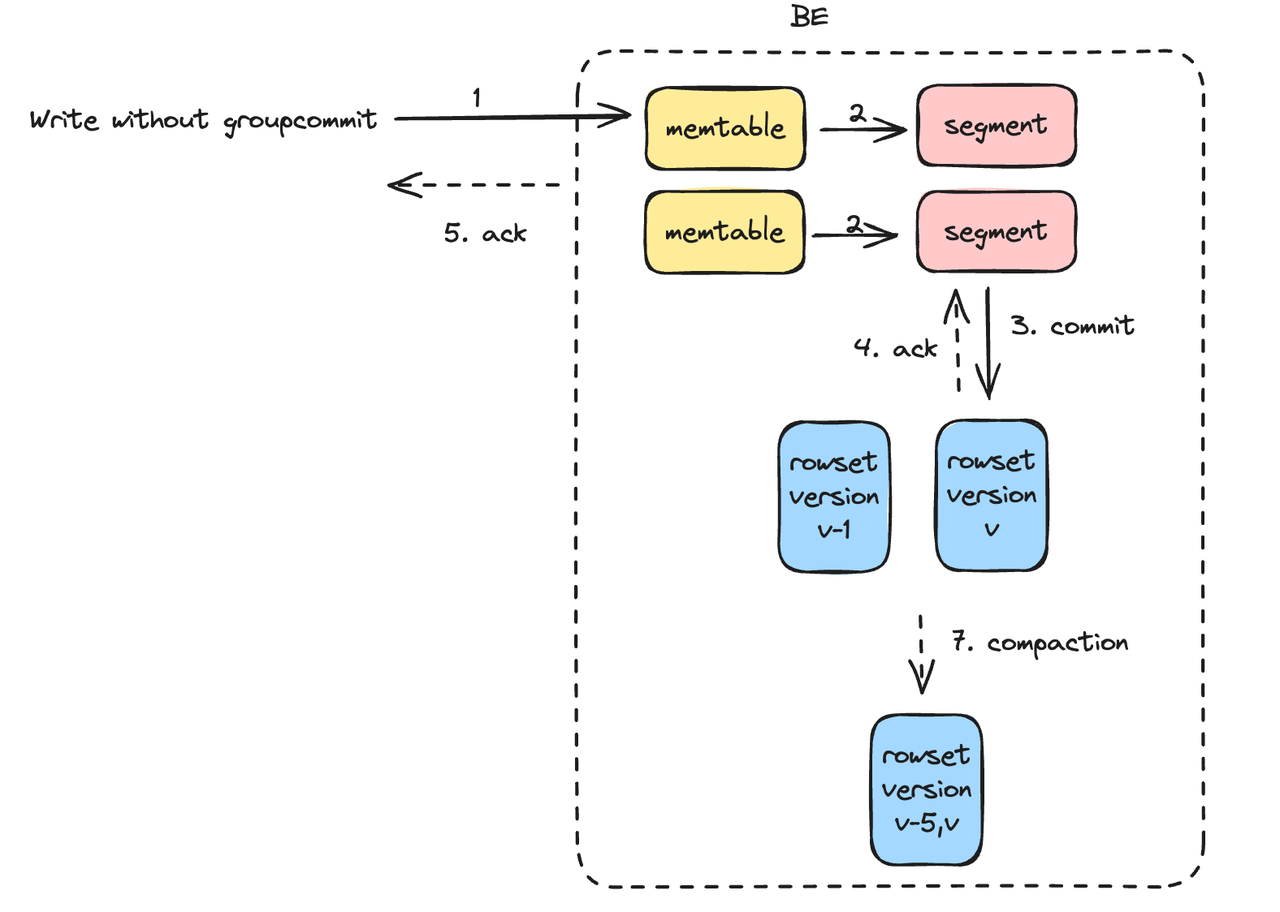
In addition, V2.1 supports Group Commit, which means to accumulate multiple data writings in the backend and commit them as one batch. In this way, users don't have to keep their writing frequency at a low level because Doris will merge multiple writings into one.
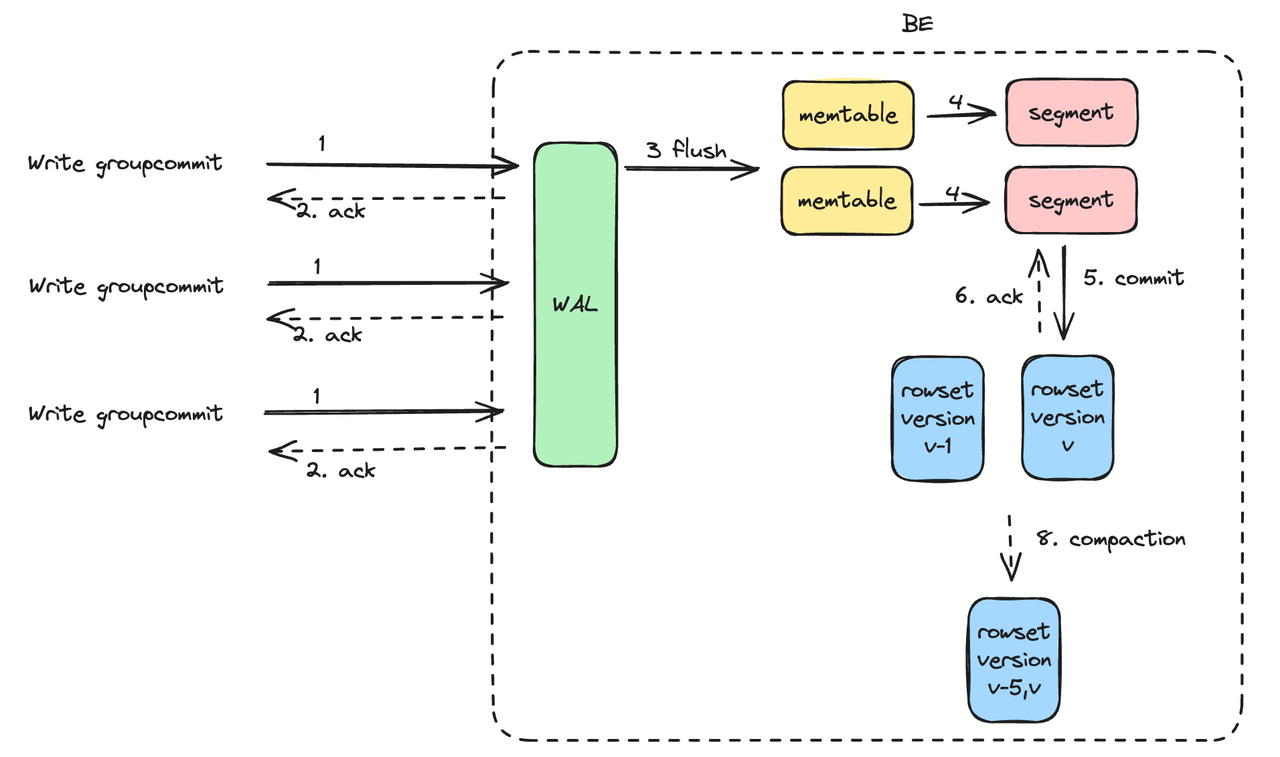
Group Commit so far supports two modes: sync_mode and async_mode. The sync_mode commits multiple imports within a single transaction, and then the data becomes immediately visible. While in the async_mode, data is first written to the Write-Ahead Log (WAL). Then Doris, based on the system load and the value of group_commit_interval, asynchronously commits the data, after which the data becomes visible. When a single import is huge, the system automatically switches to the sync_mode to prevent the WAL from occupying too much disk space.
Benchmark tests on Group Commit (async_mode) with JDBC ingestion and the Stream Load method present great results.
-
JDBC ingestion:
-
A 1 Frontend + 1 Backend cluster, TPC-H SF10 Lineitem table (22GB, 180 million rows);
-
At a concurrency level of 20, with each Insert involving less than 100 rows, Doris V2.1 reaches a writing speed of 106,900 row/s and a throughput of 11.46 MB/s. CPU usage of the Backend remains at 10%~20%.
-
-
Stream Load:
-
A 1 Frontend + 3 Backends cluster, httplogs (31GB, 247 million rows);
-
At a concurrency level of 10, with each writing involving less than 1MB, Doris returns a -235 error when disabling Group Commit. With Group Commit enabled, it delivers stable performance and reaches a writing speed of 810,000 row/s and a throughput of 104 MB/s.
-
At a concurrency level of 10, with each writing involving less than 10MB, enabling Group Commit increases the writing speed by 45% and the writing throughput by 79%.
-
See doc and full test results: https://doris.apache.org/docs/data-operate/import/group-commit-manual
Semi-structured data analysis
A new data type: Variant
Before V2.1, Doris processes semi-structured data in two ways:
-
It requires users to pre-define table schema, make a flat table, and parse the data before it is loaded into Doris. This method ensures fast data writing and avoids parsing upon query execution. The downside is the lack of flexibility. Any change to the table schema will require a lot of maintenance efforts.
-
It accommodates semi-structured data with JSON or stores it as JSON strings. Raw JSON data is ingested into Doris without any pre-processing and is parsed by functions upon query execution. This option requires no extra effort from the users, but you might need to put up with inefficient data parsing and reading.
V2.1 supports a new data type named Variant. It can accommodate semi-structured data such as JSON as well as compound data structures that contain various data types such as integers, strings, and booleans. Users don't have to pre-define the exact data types for a Variant column in the table schema.
The Variant type is handy when processing nested data structures, where the structure can change dynamically. During data writing, it is capable of auto-inference for columns based on what is given, after which it merges them into the existing table schema, and stores the JSON keys and their corresponding values as dynamic sub-columns.
You can include both Variant columns and static columns with pre-defined data types in the same table. This provides greater flexibility in storage and queries. Additionally, the Variant type is empowered by the columnar storage, vectorized execution engine, and query optimizer for high efficiency in queries and storage.
Use Variant in Doris:
-- No index
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
table_properties;
-- Create index for the v column, specify the parser
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT,
INDEX idx_var(v) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
)
table_properties;
-- Perform queries, access sub-columns using`[]`
SELECT v["properties"]["title"] from ${table_name}
Variant VS JSON
In Apache Doris, JSON data is stored in a binary JSONB format, and the entire JSON row is stored in segments in a row-oriented way. However, with the Variant type, it automatically infers the data type upon data writing and stores the JSON data in a columnar method. Thus, no parsing is needed during queries.
Furthermore, the Variant type is optimized for sparse JSON scenarios. It only extracts frequently occurring columns. The sparse columns are stored in a separate format.
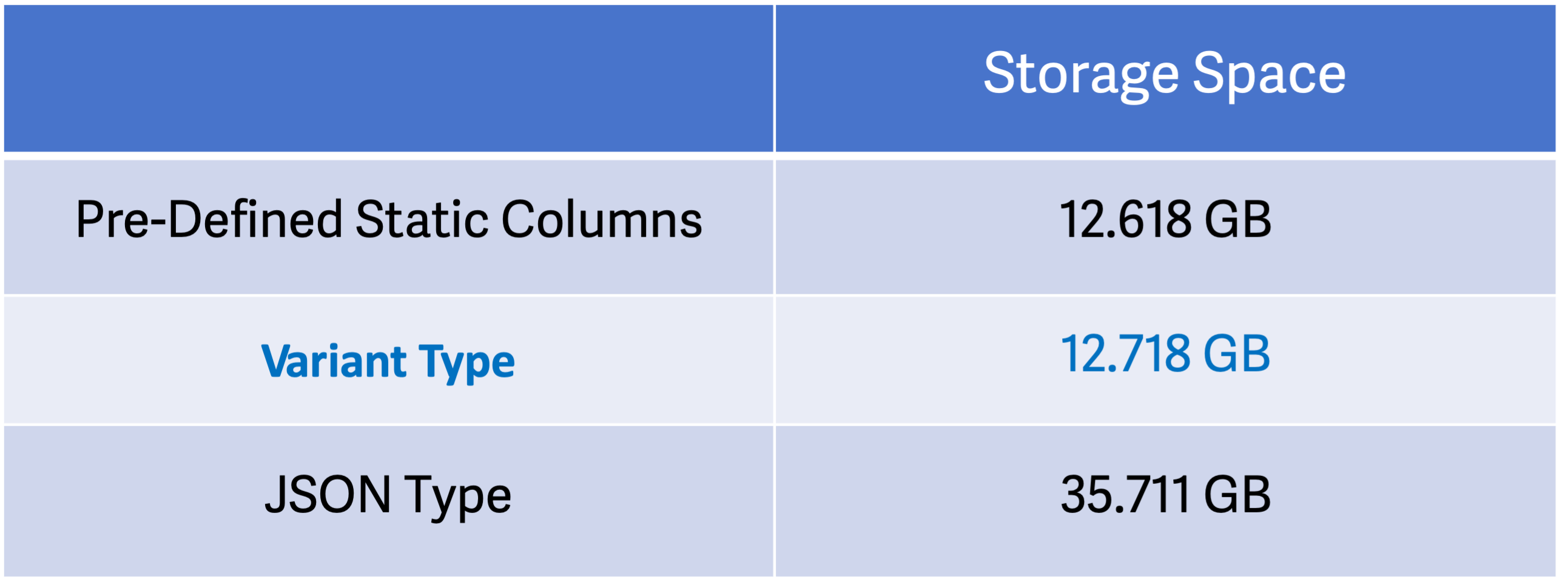
Tests prove that data in Variant columns takes up the same storage space as data in static columns, which is only 35% of that in JSON format. The Variant type should be a more cost-effective choice in low-cardinality scenarios.
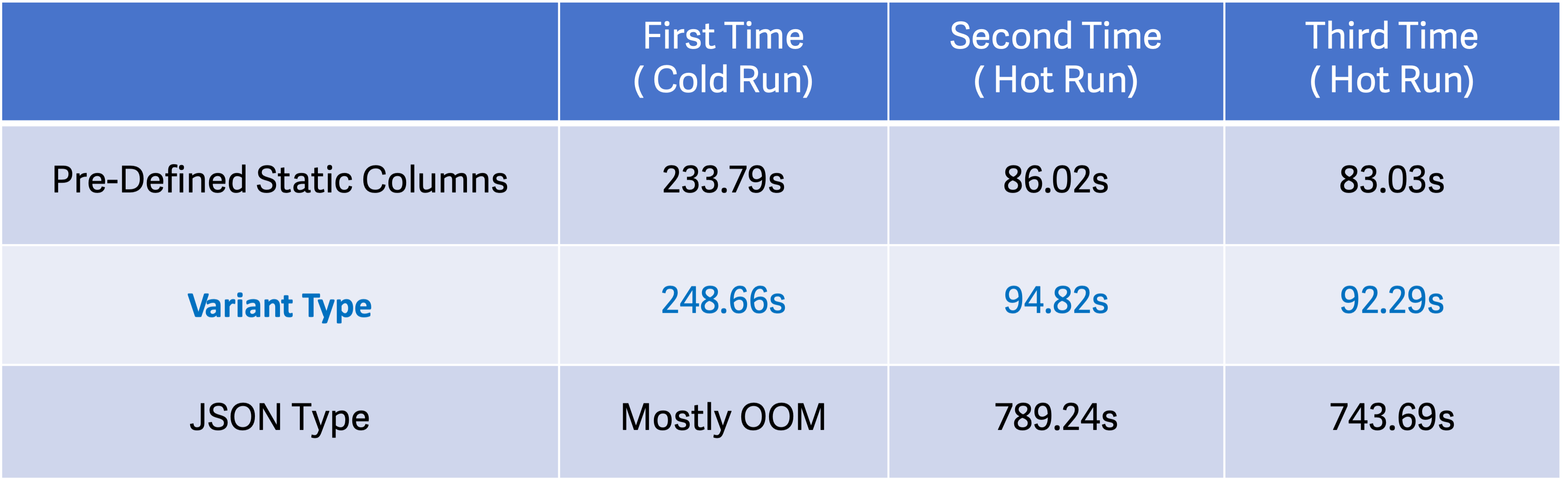
In terms of query performance, the Variant type enables 8 times higher query speed than JSON in hot runs and even more in cold runs.
-
Currently, the Variant type is not supported in the Aggregate Key model of Doris. It can not be the primary key or sorting key in a Unique Key model table or Duplicate model table;
-
It is recommended to go with the RANDOM mode or Group Commit for higher writing performance;
-
It is recommended to extract non-standard JSON types such as date or decimal as static fields to enable higher performance;
-
In columnar format, arrays of two or more dimensions, as well as arrays with nested objects, will be stored as JSONB encoding, resulting in lower performance than native arrays;
-
Queries involving filtering or aggregation require the use of Cast, where the storage layer will provide hints for the storage engine for predicate pushdown based on the storage type and the Cast type and thus accelerate queries.
IP types
IP address is a widely used field in statistical analysis for network traffic monitoring. Doris V2.1 provides native support for IPv4 and IPv6. It stores IP data in binary format, which cuts down storage space usage by 60% compared to IP string in plain texts. Along with these IP types, we have added over 20 functions for IP data processing, including:
-
IPV4_NUM_TO_STRING: It converts a big-endian representation of an IPv4 address of Int16, Int32, or Int64 into its corresponding string representation;
-
IPV4_CIDR_TO_RANGE: It receives an IPv4 address and a CIDR-containing Int16 value, and returns a structure containing two IPv4 fields, representing the lower range (min) and upper range (max) of the subnet, respectively;
-
INET_ATON: It retrieves a string containing an IPv4 address in the format of A.B.C.D, where A, B, C, and D are decimal numbers separated by periods.
See IPV6 for more information.
More powerful functions for compound data types
V2.1 provides more supported data types:
explode_map: supports exploding rows into columns for the Map data type (only with the new optimizer)
Each key-value pair in the Map field is expanded into a separate row, with the Map field replaced by two separate fields representing the key and value. The explode_map function should be used in conjunction with Lateral View. You can apply multiple Lateral Views. The result is a Cartesian product.
This is how it is used:
-- Create table
CREATE TABLE `sdu` (
`id` INT NULL,
`name` TEXT NULL,
`score` MAP<TEXT,INT> NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
-- Insert data
insert into sdu values (0, "zhangsan", {"Chinese":"80","Math":"60","English":"90"});
insert into sdu values (1, "lisi", {"null":null});
insert into sdu values (2, "wangwu", {"Chinese":"88","Math":"90","English":"96"});
insert into sdu values (3, "lisi2", {null:null});
insert into sdu values (4, "amory", NULL);
mysql> select name, course_0, score_0 from sdu lateral view explode_map(score) tmp as course_0,score_0;
+----------+----------+---------+
| name | course_0 | score_0 |
+----------+----------+---------+
| zhangsan | Chinese | 80 |
| zhangsan | Math | 60 |
| zhangsan | English | 90 |
| lisi | null | NULL |
| wangwu | Chinese | 88 |
| wangwu | Math | 90 |
| wangwu | English | 96 |
| lisi2 | NULL | NULL |
+----------+----------+---------+
mysql> select name, course_0, score_0, course_1, score_1 from sdu lateral view explode_map(score) tmp as course_0,score_0 lateral view explode_map(score) tmp1 as course_1,score_1;
+----------+----------+---------+----------+---------+
| name | course_0 | score_0 | course_1 | score_1 |
+----------+----------+---------+----------+---------+
| zhangsan | Chinese | 80 | Chinese | 80 |
| zhangsan | Chinese | 80 | Math | 60 |
| zhangsan | Chinese | 80 | English | 90 |
| zhangsan | Math | 60 | Chinese | 80 |
| zhangsan | Math | 60 | Math | 60 |
| zhangsan | Math | 60 | English | 90 |
| zhangsan | English | 90 | Chinese | 80 |
| zhangsan | English | 90 | Math | 60 |
| zhangsan | English | 90 | English | 90 |
| lisi | null | NULL | null | NULL |
| wangwu | Chinese | 88 | Chinese | 88 |
| wangwu | Chinese | 88 | Math | 90 |
| wangwu | Chinese | 88 | English | 96 |
| wangwu | Math | 90 | Chinese | 88 |
| wangwu | Math | 90 | Math | 90 |
| wangwu | Math | 90 | English | 96 |
| wangwu | English | 96 | Chinese | 88 |
| wangwu | English | 96 | Math | 90 |
| wangwu | English | 96 | English | 96 |
| lisi2 | NULL | NULL | NULL | NULL |
+----------+----------+---------+----------+---------+
explode_map_outer and explode_outer serve the same purpose. They display rows with NULL values in the Map-type columns.
mysql> select name, course_0, score_0 from sdu lateral view explode_map_outer(score) tmp as course_0,score_0;
+----------+----------+---------+
| name | course_0 | score_0 |
+----------+----------+---------+
| zhangsan | Chinese | 80 |
| zhangsan | Math | 60 |
| zhangsan | English | 90 |
| lisi | null | NULL |
| wangwu | Chinese | 88 |
| wangwu | Math | 90 |
| wangwu | English | 96 |
| lisi2 | NULL | NULL |
| amory | NULL | NULL |
+----------+----------+---------+
IN: supports theSTRUCTdata type (only with the new optimizer)
The IN predicate supports Struct type data constructed using the struct()function as the left parameter. It also allows selecting a column that contains Struct type data from a table. It supports a Struct-type array constructed using the struct() function as the right parameter.
It is an efficient alternative to WHERE clauses with many OR conditions. For example, instead of using expressions like (a = 1 and b = '2') or (a = 1 and b = '3') or (...), you can use struct(a,b) in (struct(1, '2'), struct(1, '3'), ...).
mysql> select struct(1,"2") in (struct(1,3), struct(1,"2"), struct(1,1), null);
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>) IN (NULL, cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 1) as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 3) as STRUCT<col1:TINYINT,col2:TEXT>)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
mysql> select struct(1,"2") not in (struct(1,3), struct(1,"2"), struct(1,1), null);
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ( not cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>) IN (NULL, cast(struct(1, '2') as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 1) as STRUCT<col1:TINYINT,col2:TEXT>), cast(struct(1, 3) as STRUCT<col1:TINYINT,col2:TEXT>))) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 0 |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
MAP_AGG: It receives expr1 as the key, expr2 as the corresponding value, and returns a MAP.
Workload management
Hard isolation of resources
On the basis of the Workload Group mechanism, which imposes a soft limit on the resources that a workload group can use, Doris 2.1 introduces a hard limit on CPU resource consumption for workload groups as a way to ensure higher stability in query performance. This means that regardless of the overall CPU availability on the physical machine, workload groups configured with hard limits cannot exceed the maximum CPU usage specified in the configuration. In this way, as long as there is no significant change in user query workload, there will be stable query performance. A caveat is that, in addition to CPU usage, memory, I/O, and resource contention at the software level will all impact query execution. Thus, when the cluster switches between idle and heavy load, even with CPU hard limits configured, there might still be fluctuations in query performance. However, you can still expect better performance from the hard limits than the soft limits.
Note
-
In Doris V2.0, CPU resource isolation was implemented based on a priority queue. In V2.1, this relies on the CGroup mechanism. Therefore, please note that you should configure the CGroups in advance after upgrading from V2.0 to V2.1.
-
Currently, the Workload Group mechanism supports query-query workload isolation and ingestion-query isolation. Note that if you need to impose hard limits on import workloads, you should enable
memtable_on_sink_node. -
Users need to specify either soft limits or hard limits for the current cluster using a switch. Currently, it is not supported to run both modes on the same cluster. In the future, we will consider bringing in simultaneous support for both modes based on user feedback.
See Workload Group.
TopSQL
V2.1 allows users to check the most resource-consuming SQL queries in the runtime. This can be a big help when handling cluster load spikes caused by unexpected large queries.
mysql [(none)]>desc function active_queries();
+------------------------+--------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------+------+-------+---------+-------+
| BeHost | TEXT | No | false | NULL | NONE |
| BePort | BIGINT | No | false | NULL | NONE |
| QueryId | TEXT | No | false | NULL | NONE |
| StartTime | TEXT | No | false | NULL | NONE |
| QueryTimeMs | BIGINT | No | false | NULL | NONE |
| WorkloadGroupId | BIGINT | No | false | NULL | NONE |
| QueryCpuTimeMs | BIGINT | No | false | NULL | NONE |
| ScanRows | BIGINT | No | false | NULL | NONE |
| ScanBytes | BIGINT | No | false | NULL | NONE |
| BePeakMemoryBytes | BIGINT | No | false | NULL | NONE |
| CurrentUsedMemoryBytes | BIGINT | No | false | NULL | NONE |
| ShuffleSendBytes | BIGINT | No | false | NULL | NONE |
| ShuffleSendRows | BIGINT | No | false | NULL | NONE |
| Database | TEXT | No | false | NULL | NONE |
| FrontendInstance | TEXT | No | false | NULL | NONE |
| Sql | TEXT | No | false | NULL | NONE |
+------------------------+--------+------+-------+---------+-------+
The active_queries() function records the audit information of queries running on various Backends in Doris. You can query active_queries() like querying a regular table. It supports operations including querying, filtering with predicates, sorting, and joining. Common metrics captured by this function include the SQL execution time, CPU time, peak memory usage on a single Backend, data volume scanned, and data volume shuffled during the query execution. It also allows rolling up to the Backend level to examine the global resource consumption of SQL queries.
Note that only the SQL in the runtime will be displayed. The SQLs that finish execution will be written into the audit logs (fe.audit.log, mostly) instead. A few frequently used SQLs are as follows:
Check the top N longest-running SQLs in the cluster
select QueryId,max(QueryTimeMs) as query_time from active_queries() group by QueryId order by query_time desc limit 10;
Check the top N most CPU-consuming SQLs in the cluster
select QueryId, sum(QueryCpuTimeMs) as cpu_time from active_queries() group by QueryId order by cpu_time desc limit 10
Check the top N SQLs with the most scan rows and their execution time
select t1.QueryId,t1.scan_rows, t2.query_time from
(select QueryId, sum(ScanRows) as scan_rows from active_queries() group by QueryId order by scan_rows desc limit 10) t1
left join (select QueryId,max(QueryTimeMs) as query_time from active_queries() group by QueryId) t2 on t1.QueryId = t2.QueryId
Check the load of all Backends and sort them in descending order based on CPU time/scan rows/shuffle bytes.
select BeHost,sum(QueryCpuTimeMs) as query_cpu_time, sum(ScanRows) as scan_rows,sum(ShuffleSendBytes) as shuffle_bytes from active_queries() group by BeHost order by query_cpu_time desc,scan_rows desc ,shuffle_bytes desc limit 10
Check the top N SQL queries with the highest peak memory usage on a single Backend.
select QueryId,max(BePeakMemoryBytes) as be_peak_mem from active_queries() group by QueryId order by be_peak_mem desc limit 10;
Currently, the main displayed workload types include Select and Insert Into...Select. The iterative versions of V2.1 are expected to support displaying the resource usage of Stream Load and Broker Load.
Others
Decimal 256
For users in the financial sector or high-end manufacturing, V2.1 supports a high-precision data type: Decimal, which supports up to 76 significant digits (To enable this experimental feature, please set enable_decimal256=true.)
Example:
CREATE TABLE `test_arithmetic_expressions_256` (
k1 decimal(76, 30),
k2 decimal(76, 30)
)
DISTRIBUTED BY HASH(k1)
PROPERTIES (
"replication_num" = "1"
);
insert into test_arithmetic_expressions_256 values
(1.000000000000000000000000000001, 9999999999999999999999999999999999999999999998.999999999999999999999999999998),
(2.100000000000000000000000000001, 4999999999999999999999999999999999999999999999.899999999999999999999999999998),
(3.666666666666666666666666666666, 3333333333333333333333333333333333333333333333.333333333333333333333333333333);
Query and result:
select k1, k2, k1 + k2 a from test_arithmetic_expressions_256 order by 1, 2;
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
| k1 | k2 | a |
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
| 1.000000000000000000000000000001 | 9999999999999999999999999999999999999999999998.999999999999999999999999999998 | 9999999999999999999999999999999999999999999999.999999999999999999999999999999 |
| 2.100000000000000000000000000001 | 4999999999999999999999999999999999999999999999.899999999999999999999999999998 | 5000000000000000000000000000000000000000000001.999999999999999999999999999999 |
| 3.666666666666666666666666666666 | 3333333333333333333333333333333333333333333333.333333333333333333333333333333 | 3333333333333333333333333333333333333333333336.999999999999999999999999999999 |
+----------------------------------+-------------------------------------------------------------------------------+-------------------------------------------------------------------------------+
3 rows in set (0.09 sec)
The Decimal256 type consumes more CPU resources so the queries might not be as fast compared to other data types.
Job scheduler
According to user feedback, there is a recurring need for scheduled job execution, such as:
-
Periodic backup;
-
Scheduled data expiration;
-
Periodic import jobs: scheduling incremental or full data synchronization jobs using the Catalog feature;
-
Regular ETL: such as loading data from a flat table into a specified table on a scheduled basis, pulling data from detailed tables and storing it in aggregate tables at specific intervals, and performing scheduled denormalization for tables in the ODS layer and updates to the existing flat table.
Despite the availability of various external scheduling systems such as Airflow and DolphinScheduler, there still exists a consistency challenge. When an external scheduling system triggers an import job in Doris and successfully executes it, but unexpectedly experiences a crash. In this case, since the external scheduling system fails to retrieve the execution result, it assumes the schedule has failed. Then it will trigger its fault tolerance mechanism. Either retries or a direct failure will result in:
-
Waste of resources: Since the scheduling system can mistakenly consider a job as failed, it might reschedule the execution of a job that has already succeeded, resulting in unnecessary resource consumption.
-
Data duplication or loss: On the one hand, retrying the import job might lead to duplicate data imports, resulting in data redundancy or inconsistency. On the other hand, if the job is marked as failed, it can result in the neglect or loss of data that has actually been successfully imported.
-
Time delay: After the fault tolerance mechanism is triggered, extra time is needed for job scheduling and retries, prolonging the overall data processing time.
-
Compromised system stability: Frequent retries or immediate failures can increase the load on both the scheduling system and Doris, thereby undermining the stability and performance of the system.
V2.1 provides a good option for regular job scheduling: Doris Job Scheduler. It can trigger the pre-defined operations on schedule or at fixed intervals. The Doris Job Scheduler is accurate to the second. In addition to consistency guarantee for data writing, it provides:
-
Efficiency: The Doris Job Scheduler can schedule jobs and events at specified time intervals to ensure efficient data processing. By employing the time wheel algorithm, it guarantees precise triggering of events at a granularity of seconds.
-
Flexibility: It offers multiple scheduling options, such as scheduling at intervals of minutes, hours, days, or weeks. It supports both one-time scheduling and recurring (cyclic) event scheduling. For the latter, you can specify the start and end times for the scheduling period.
-
Event pool and high-performance processing queues: It utilizes Disruptor for a high-performance producer-consumer model to minimize job overload.
-
Traceable scheduling records: It stores the latest job execution records (configurable), which users can view via a simple command.
-
High availability: On the basis of the Doris high availability mechanism, the jobs are easily self-recoverable.
An example of creating a scheduled job:
// Execute an insert statement every day from 2023-11-17 to 2038
CREATE
JOB e_daily
ON SCHEDULE
EVERY 1 DAY
STARTS '2023-11-17 23:59:00'
ENDS '2038-01-19 03:14:07'
COMMENT 'Saves total number of sessions'
DO
INSERT INTO site_activity.totals (time, total)
SELECT CURRENT_TIMESTAMP, COUNT(*)
FROM site_activity.sessions where create_time >= days_add(now(),-1) ;
Doris Job Scheduler only supports Insert operations on internal tables currently. See CREATE-JOB.
Behavior changed
-
The Unique Key model enables Merge-on-Write by default, which means
enable_unique_key_merge_on_write=truewill be included as a default setting when a table is created in the Unique Key model. -
Since inverted index has proven to be more performant than bitmap index, V2.1 and future versions stop supporting bitmap index. Existing bitmap indexes will remain effective but new creation is not allowed. We will remove bitmap index-related code in the future.
-
cpu_resource_limitis no longer supported. It is to put a limit on the number of scanner threads on Doris Backend. Since the Workload Group mechanism also supports such settings, the already configuredcpu_resource_limitwill be invalid. -
Segment compaction is enabled by default. This means Doris supports compaction of multiple segments in the same rowset, which is useful in single-batch ingestion of large datasets.
-
Audit log plug-in
-
Since V2.1.0, Doris has a built-in audit log plug-in. Users can simply enable or disable it by setting the
enable_audit_pluginparameter. -
If you have already installed your own audit log plug-in, you can either continue using it after upgrading to Doris V2.1, or uninstall it and use the one in Doris. Please note that the audit log table will be relocated after switching plug-in.
-
For more details, please see doc: https://doris.apache.org/docs/admin-manual/audit-plugin
-
Credits
Special thanks to the following contributors for making this happen:
morrySnow, Gabriel39, BiteTheDDDDt, kaijchen, starocean999, morningman, jackwener, zy-kkk, englefly, Jibing-Li, XieJiann, yujun777, Mryange, HHoflittlefish777, LiDongyangLi, HappenLee, zhangstar333, lihangyu, zclllyybb, amory, bobhan1, AKIRA, zhangdong, ZouXinyiZou, HuJerryHu, yiguolei, airborne12, wangbo, jacktengg, jacktengg, TangSiyang2001, BePPPower, Yukang-Lian, mymeiyi, liugddx, kaka11chen, AshinGau, DrogonJackDrogon, wsjz, seuhezhiqiang, zhannngchen, shuke987, KassieZ, huanghaibin, zzzxl1993, Nitin-Kashyap, AlexYue, dataroaring, seawinde, walter, xzj7019, xiaokang, SWJTU-ZhangLei, liaoxin01, dutyu, wuwenchihdu, LiBinfeng-01, daidai, qidaye, mch_ucchi, zhangguoqiang, zhengyu, plat1ko, LemonLiTree, ixzc, deardeng, yiguolei, catpineapple, LingAdonisLing, DongLiang-0, whuxingying, Tanya-W, Yulei-Yang, zzzzzzzs, caoliang-web, xueweizhang, yangshijie, Luwei, lsy3993, xy720, HowardQin, DeadlineFen, Petrichor, caiconghui, KirsCalvinKirs, SunChenyangSun, ChouGavinChou, Luzhijing, gnehil, wudi, zhiqqqq, zfr95, zxealous, kkop, yagagagaga, Chester, LuGuangmingLu, Lightman, Xiaocc, taoxutao, yuanyuan8983, KirsCalvinKirs, DuRipeng, GoGoWen, JingDas, camby, camby, Euporia, rohitrs1983, felixwluo, wudongliang, FreeOnePlus, PaiVallishPai, XuJianxu, seuhezhiqiang, luozenglin, 924060929, HB, LiuLijiaLiu, Ma1oneZhang, bingquanzhao, chunping, echo-dundun, feiniaofeiafei, walter, yongjinhou, zgxme, zhangy5, httpshirley, ChenyangSunChenyang, ZenoYang, ZhangYu0123, hechao, herry2038, jayhua, koarz, nanfeng, LiChuangLi, LiuGuangdongLiu, Jeffrey, liuJiwenliu, Stalary, DuanXujianDuan, HuZhiyuHu, jiafeng.zhang, nanfeng, py023, xiongjx, yuxuan-luo, zhaoshuo, XiaoChangmingXiao, ElvinWei, LiuHongLiu, QiHouliangQi, Hyman-zhao, HelgeLarsHelge, Uniqueyou, YangYAN, acnot, amory, feifeifeimoon, flynn, gohalo, htyoung, realize096, shee, wangqt, xyfsjq, zzwwhh, songguangfan, 467887319, BirdAmosBird, ZhuArmandoZhu, CanGuan, ChengDaqi2023, ChinaYiGuan, gitccl, colagy, DeadlineFen, Doris-Extras, HonestManXin, q763562998, guardcrystal, Dragonliu2018, ZhaoLongZhao, LuoMetaLuo, Miaohongkai, YinShaowenYin, Centurybbx, hongkun-Shao, Wanghuan, Xinxing, XueYuhai, Yoko, HeZhangJianHe, ZhongJinHacker, alan_rodriguez, allenhooo, beat4ocean, bigben0204, chen, czzmmc, dalong, deadlinefen, didiaode18, dong-shuai, feelshana, fornaix, hammer, xuke-hat, hqx871, i78086, irenesrl, julic20s, kindred77, lihuigang, wenluowen, lxliyou001, CSTGluigi, ranxiang327, shysnow, sunny, vhwzIs, wangtao, wangtianyi2004, wyx123654, xuefengze, xiangran0327, xy, yimeng, ytwp, yujian, zhangstar333, figurant, sdhzwc, LHG41278, zlw5307