Vector Search: What It Is, Examples, and How It Powers AI Applications
Quick Answer: What Is Vector Search?
Vector search is a search method that retrieves results based on semantic similarity rather than exact keyword matches.
Instead of matching words directly, vector search converts data—such as text, images, or logs—into numerical representations called embeddings (vectors). It then compares these vectors in a high-dimensional space to find the most similar results.
The key idea behind vector search is that similar meanings are represented by vectors that are close to each other.
The main characteristics of vector search include:
- Understanding user intent rather than exact wording
- Supporting unstructured data such as text and images
- Enabling AI applications like semantic search and RAG
How Vector Search Works (Step-by-Step)
Vector search follows a simple but powerful pipeline. Instead of matching exact words, it converts both the data and the query into numerical representations and then compares them based on similarity.
1. Convert Data into Embeddings
The first step is to convert raw data into embeddings.
Embeddings are numerical vectors generated by machine learning models that capture the semantic meaning of the input. These inputs can include:
- text documents
- product descriptions
- images
- logs or events
For example, two sentences with similar meanings may produce vectors that are located close to each other in vector space, even if they do not share the same keywords.
2. Store Vectors in a Vector Database
Once generated, these embeddings are stored in a vector database or another system that supports vector indexing.
Unlike traditional databases that are optimized for exact filtering, vector search systems are designed to store high-dimensional vectors and retrieve the nearest matches efficiently. This is especially important when dealing with millions or billions of embeddings.
In production systems, vector data is often stored alongside metadata such as:
- document ID
- timestamp
- category
- status
This allows vector search to be combined with structured filtering.
3. Convert the Query into a Vector
When a user submits a search query, the system applies the same embedding model to the query itself.
This produces a query vector that can be compared directly against the stored vectors. Because both the query and the data are represented in the same vector space, the system can search for semantic similarity rather than exact wording.
For example, a query like:
How to reduce database latency
may still retrieve content containing phrases such as:
improve query performance
speed up data access
even if the exact words do not match.
4. Perform Similarity Search
After the query vector is created, the system searches for the nearest vectors in the database.
This is typically done using similarity metrics such as:
- Cosine similarity: Measures how close two vectors are in direction.
- Euclidean distance: Measures the geometric straight-line distance between vectors.
- Dot product: Often used in embedding-based retrieval systems to measure magnitude and direction.
Because exact nearest-neighbor search can be expensive at large scale, most production systems use Approximate Nearest Neighbor (ANN) algorithms to speed up retrieval while keeping results highly relevant.
5. Re-rank and Return the Best Results
In many real-world AI systems, vector search is only the first retrieval step.
The initial results may then be:
- filtered using metadata
- combined with keyword search
- re-ranked by another model
This improves precision and ensures that the final results are both semantically relevant and contextually useful.
This is why modern AI search systems often use hybrid search, combining vector similarity with structured filters or keyword relevance.
In essence, vector search retrieves similar meaning, not just exact matches.
Vector Search vs. Keyword Search vs. Semantic Search
To understand where vector search fits in, it helps to compare it with two other commonly used approaches: keyword search and semantic search. While these terms are often used interchangeably, they actually represent different ways of thinking about search.
| Feature | Keyword Search | Semantic Search | Vector Search |
|---|---|---|---|
| Matching method | Exact keywords | Meaning (conceptual) | Meaning (vector similarity) |
| Technology | Inverted index (BM25) | NLP models | Embeddings + ANN |
| Accuracy | High precision | Moderate | High (context-aware) |
| Flexibility | Low | Medium | High |
| Typical tools | Elasticsearch | Search engines | Vector databases |
Vector Search vs. Keyword Search
Traditional keyword search is based on matching exact words. Systems like Elasticsearch use techniques such as inverted indexes and BM25 to find documents that contain the same terms as the query.
This approach works well when users know exactly what they are looking for. For example, if someone searches for a specific error code or product name, keyword search can return highly precise results very quickly.
However, keyword search struggles when the wording changes. If a user searches for “how to fix database performance,” a keyword-based system may miss relevant content that uses different phrasing like “optimize query latency” or “improve database speed.”
This is where vector search becomes useful.
Instead of matching words, vector search matches meaning. It converts both the query and the data into embeddings, and then retrieves results that are semantically similar—even if they don’t share the same keywords.
In practice, this means vector search can handle:
- synonyms
- paraphrased queries
- natural language input
But it also comes with trade-offs. While vector search is more flexible, it can sometimes return results that are less precise, especially without additional filtering or re-ranking.
Vector Search vs. Semantic Search
The difference between vector search and semantic search is more subtle, and often misunderstood.
Semantic search is not a specific technology—it’s a goal. It refers to the idea of understanding the intent behind a query, rather than just matching words. For example, recognizing that “cheap laptop” and “affordable notebook” mean the same thing.
Vector search is one of the most common ways to implement semantic search in modern systems.
By representing text as embeddings, vector search turns meaning into something that can be computed mathematically. This allows systems to compare concepts at scale and retrieve relevant results efficiently.
In modern AI systems, the two are closely connected:
- semantic search defines what the system is trying to do (understand meaning)
- vector search defines how the system actually does it (compute similarity using vectors)
You can see this clearly in applications like RAG (Retrieval-Augmented Generation). The system first interprets the user’s intent (semantic understanding), and then uses vector search to retrieve the most relevant pieces of information.
Vector Search Example
Vector search is already used in many real-world applications, often without users realizing it. Here are a few common examples that show how it works in practice.
Retrieval-Augmented Generation (RAG)
In AI systems such as ChatGPT-style assistants, vector search plays a critical role in retrieving relevant information.
When a user asks a question, the system:
- converts the query into an embedding
- searches for similar documents using vector search
- passes the retrieved context into the LLM
For example, if a user asks:
How do I fix high database latency?
The system may retrieve documents about:
- query optimization
- indexing strategies
- caching techniques
—even if those exact words do not appear in the query.
This can help reduce hallucinations and improve answer grounding, especially when the retrieval pipeline is well-designed.
Reverse Image Search
Vector search is also widely used in image-based applications.
When you upload an image, it is converted into a vector representation that captures visual features such as shapes, colors, and patterns. The system then finds images with similar vectors.
This is commonly used in:
- e-commerce (“find similar products”)
- visual search engines
- design and inspiration tools
Instead of matching metadata, the system understands visual similarity directly.
Recommendation Systems
Streaming platforms like Netflix or Spotify rely heavily on vector search to power recommendations.
Users and content are represented as vectors based on behavior, preferences, and attributes. The system then recommends items that are “close” in vector space.
For example:
- users who watch similar content → similar vectors
- movies with similar themes → similar vectors
This allows platforms to recommend content that feels relevant, even if users cannot explicitly describe what they want.
Vector Search Architecture (for AI Systems)
To understand why vector search is so important, it helps to look at how it fits into a modern AI system.
A typical architecture looks like this:
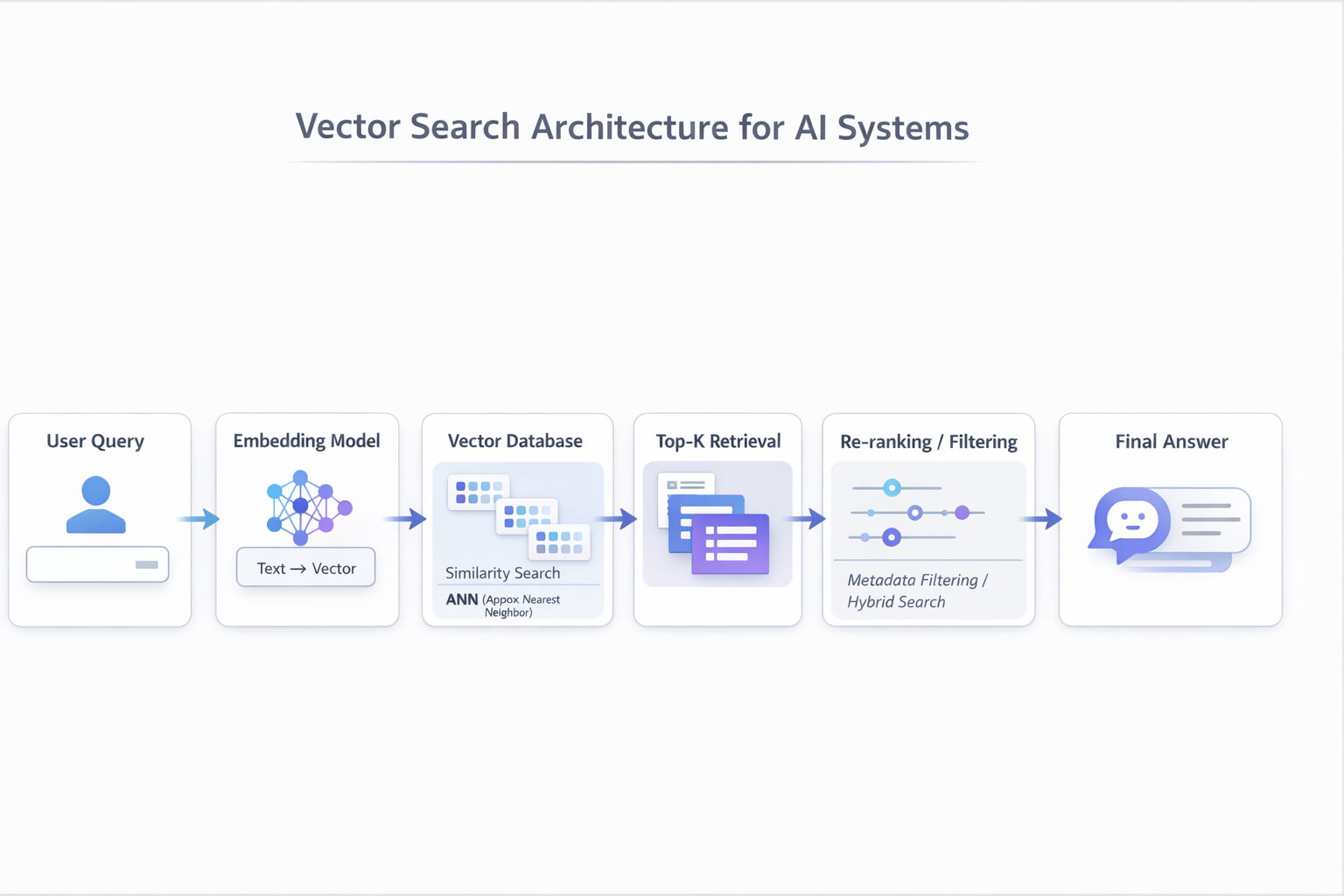
When a user submits a query, the system does not search it directly as text.
Instead:
- The query is converted into an embedding using a model (e.g., OpenAI, BERT, or other embedding models)
- The vector database retrieves the most similar items based on vector similarity.
- The system may apply additional filtering (e.g., time range, metadata)
- A re-ranking step improves precision by selecting the most relevant results
- The final results are passed into an LLM to generate a response
Why This Architecture Matters
Traditional keyword-based systems were originally optimized for lexical matching rather than semantic retrieval, so they may require additional components to support this kind of pipeline effectively.
They struggle with:
- natural language queries
- unstructured data
- semantic understanding
Vector search, on the other hand, enables:
- semantic retrieval at scale
- real-time AI applications
- integration with LLM workflows (RAG)
A Practical Insight
In real-world systems, vector search is rarely used alone.
Most production systems combine:
vector search + keyword search + structured filtering
This is known as hybrid search, and it balances:
- precision (keyword search)
- flexibility (vector search)
The Role of a Vector Search Database (And How to Choose)
Vector search is not just an algorithm—it requires a system that can store and retrieve high-dimensional vectors efficiently at scale. This is where vector search databases come in.
What Is a Vector Search Database?
A vector search database is a system specifically designed to handle embeddings and perform fast similarity search.
Unlike traditional databases that focus on exact matching and filtering, vector databases are optimized for:
- storing high-dimensional vectors (embeddings)
- performing nearest-neighbor search efficiently
- scaling to millions or billions of data points
In practical terms, a vector search database allows you to take a query, convert it into an embedding, and quickly find the most similar items—even in very large datasets.
Vector Search vs. Elasticsearch (and Traditional Search Systems)
Elasticsearch and similar systems were originally built for keyword-based search using inverted indexes.
This makes them extremely effective for:
- exact matches
- filtering and aggregation
- structured queries
However, their original strength lies in lexical retrieval, filtering, and aggregation rather than vector-native similarity search.
Modern versions of Elasticsearch now support vector search, but there is still a conceptual difference:
- Keyword search (Elasticsearch classic) → matches exact terms
- Vector search → matches semantic similarity
In real-world systems, these approaches are often combined.
For example, a system might use keyword search for precision and vector search for semantic relevance.
Dedicated Vector Databases vs. Integrated Databases
As vector search has grown, two main approaches have emerged.
Dedicated Vector Databases
Examples include Pinecone, Milvus, and Qdrant.
These systems are built specifically for vector similarity search and are typically easy to adopt for AI use cases.
They work well when:
- the primary requirement is vector retrieval
- the system is relatively simple
- structured filtering is minimal
However, they may require additional systems to handle analytics, filtering, or complex queries.
Integrated Analytical Databases
In real-world applications, vector search rarely exists in isolation.
Most production systems need to combine:
- vector search (for semantic similarity)
- metadata filtering (time, status, user, etc.)
- aggregation and analytics
- real-time data ingestion
For example, a real query might look like:
“Find logs similar to this error, from yesterday, where status = failed”
This is not just a vector search problem—it is a hybrid query that requires both semantic understanding and structured filtering. Some analytical databases, such as Apache Doris, follow this integrated approach by supporting vector similarity search together with real-time analytics, filtering, and aggregation in a single system. This allows teams to simplify architecture when building AI applications that require both semantic retrieval and structured queries.
How to Choose the Right Approach
Choosing between different types of vector search systems depends on your use case.
Choose a dedicated vector database if:
- your workload is primarily similarity search
- you are building a prototype or early-stage AI feature
An integrated analytical database may be a good fit if:
- you need vector retrieval together with filtering, analytics, and real-time data ingestion
- your workload involves logs, events, or operational analytics
- you want to reduce the number of systems used in a production pipeline
Limitations of Vector Search
Despite its advantages, vector search is not a perfect solution and comes with several practical limitations.
One of the main trade-offs is between accuracy and performance. Most production systems rely on Approximate Nearest Neighbor (ANN) algorithms to achieve fast retrieval at scale, but this means the results may not always be the exact closest matches.
Another challenge is computational cost. Generating embeddings and performing similarity search—especially across large datasets—can be resource-intensive, requiring optimized infrastructure and indexing strategies.
As data volume grows, latency can also become an issue. Maintaining low response times while searching millions or billions of vectors requires careful system design.
In addition, vector search alone may lack precision in certain scenarios. Because it focuses on semantic similarity, it can sometimes return results that are related but not strictly relevant. This is why many systems introduce a re-ranking step or combine vector search with structured filters.
In practice, most production systems use hybrid search, combining vector search with keyword search and filtering to balance relevance and precision.
Future of Vector Search
Vector search is evolving rapidly as AI systems become more complex and data-driven.
One clear trend is the rise of hybrid search, where vector similarity is combined with keyword matching and structured filtering. This approach allows systems to balance semantic understanding with precision, and is quickly becoming the default in production environments.
Another major shift is the adoption of Retrieval-Augmented Generation (RAG). As LLM-based applications become more common, vector search is increasingly used to retrieve external knowledge and improve model accuracy.
We are also seeing the emergence of AI agents and memory systems, where vector search is used to store and retrieve past interactions or contextual information. In this setting, vector databases effectively act as a form of long-term memory for AI systems.
At the infrastructure level, real-time vector analytics is becoming more important. Instead of working only on static datasets, modern systems need to handle streaming data, logs, and events while still supporting fast similarity search.
Overall, vector search is moving from a niche technique to a core component of modern AI and data infrastructure.
FAQ
Can SQL databases do vector search?
Yes, many modern databases support vector search either through extensions (such as pgvector) or built-in vector data types. However, performance and scalability depend on how well the system is optimized for high-dimensional similarity search.
What is hybrid search?
Hybrid search combines keyword search (for precision) with vector search (for semantic understanding). This approach is widely used in modern AI systems because it provides both accuracy and flexibility.