
Practice and optimization of Apache Doris in Xiaomi
Guide: Xiaomi Group introduced Apache Doris in 2019. At present, Apache Doris has been widely used in dozens of business departments within Xiaomi. A set of data ecology with Apache Doris has been formed. This article is transcribed from an online meetup speech of the Doris community, aiming to share the practice of Apache Doris in Xiaomi.
Author: ZuoWei, OLAP Engineer, Xiaomi

Xiaomi Corporation (“Xiaomi” or the “Group”; HKG:1810), a consumer electronics and smart manufacturing company with smartphones and smart hardware connected by an Internet of Things (IoT) platform. In 2021, Xiaomi's total revenue amounted to RMB328.3 billion(USD472,231,316,200), an increase of 33.5% year-over-year; Adjusted net profit was RMB22.0 billion(USD3,164,510,800), an increase of 69.5% year-over-year.
Due to the growing need of data analysis, Xiaomi Group introduced Apache Doris in 2019. As one of the earliest users of Apache Doris, Xiaomi Group has been deeply involved in the open-source community. After three years of development, Apache Doris has been widely used in dozens of business departments within Xiaomi, such as Advertising, New Retail, Growth Analysis, Dashboards, UserPortraits, AISTAR, Xiaomi Youpin. Within Xiaomi, a data ecosystem has been built around Apache Doris.
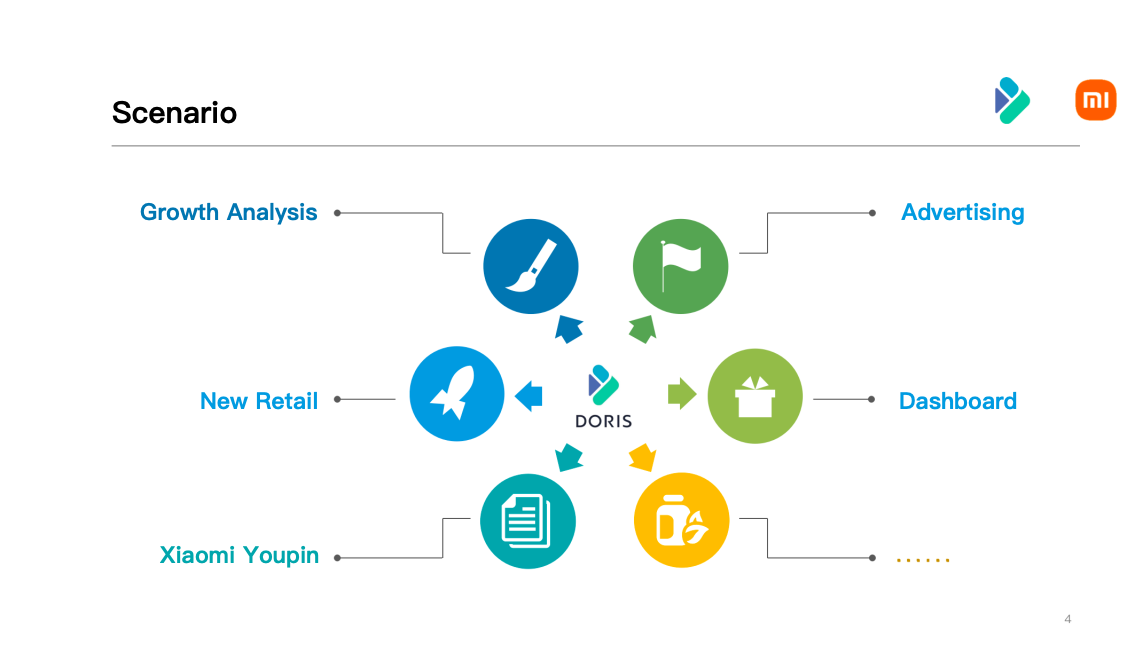
At present, Apache Doris already has dozens of clusters in Xiaomi, with an overall scale of hundreds of virtual machines . Among them, the largest single cluster reaches nearly 100 nodes, with dozens of real-time data synchronization tasks. And the largest daily increment of a single table rocket to 12 billion, supporting PB-level storage. And a single cluster can support more than 20,000 multi-dimensional analysis queries per day.
Architecture Evolution
The original intention of Xiaomi to introduce Apache Doris is to solve the problems encountered in user behavior analysis. With the development of Xiaomi's Internet business, the demand for growth analysis using user behavior data is becoming stronger and stronger. If each business branch builds its own growth analysis system, it will not only be costly, but also inefficient. Therefore, if there is a product that can help them stop worrying about underlying complex technical details, it would be great to have relevant business personnel focus on their own technical work. In this way, it can greatly improve work efficiency. Therefore, Xiaomi Big Data and the cloud platform jointly developed the growth analysis system called Growing Analytics (referred to as GA), which aims to provide a flexible multi-dimensional real-time query and analysis platform, which can manage data access and query solutions in a unified way, and help business branches to refine operation.
Previous Architecture
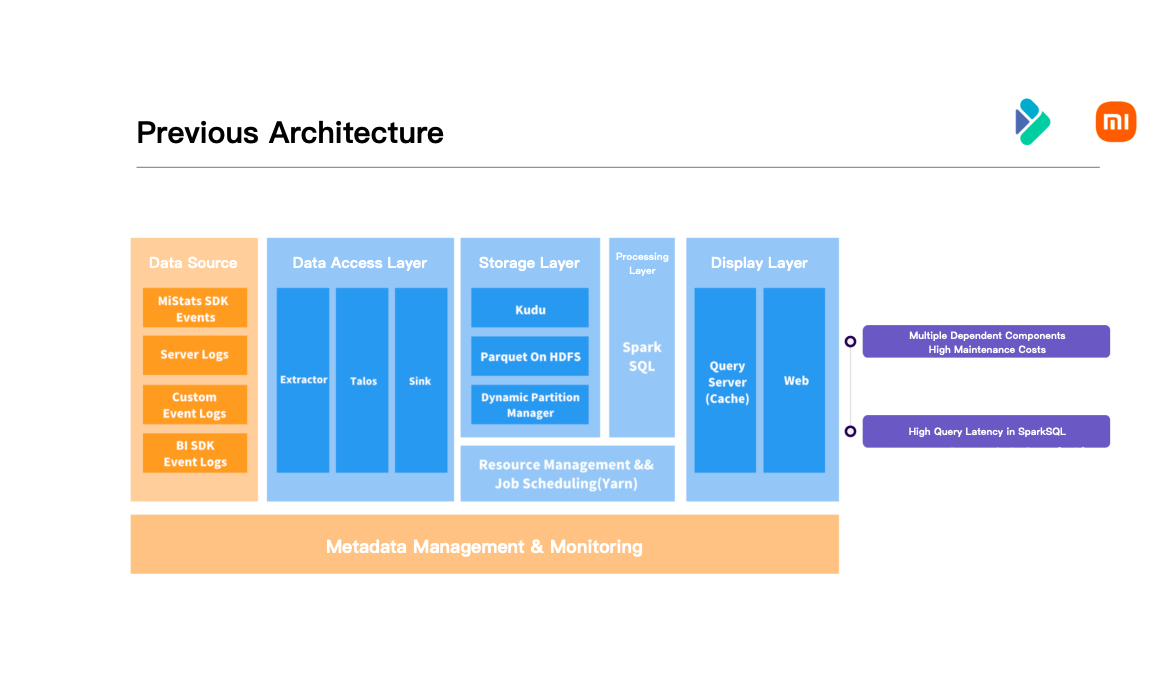
The growth analysis platform project was established in mid-2018. At that time, based on the consideration of development time and cost, Xiaomi reused various existing big data basic components (HDFS, Kudu, SparkSQL, etc.) to build a growth analysis query system based on Lambda architecture. The architecture of the first version of the GA system is shown in the figure below, including the following aspects:
- Data Source: The data source is the front-end embedded data and user behavior data.
- Data Access: The event tracking data is uniformly cleaned and ingested into Xiaomi's internal self-developed message queue, and the data is imported into Kudu through Spark Streaming.
- Storage: Separate hot and cold data in the storage layer. Hot data is stored in Kudu, and cold data is stored in HDFS. At the same time, partitioning is carried out in the storage layer. When the partition unit is day, part of the data will be cooled and stored on HDFS every night.
- Compute and Query: In the query layer, use SparkSQL to perform federated queries on the data on Kudu and HDFS, and finally display the query results on the front-end page.
At that time, the first version of the growth analysis platform helped us solve a series of problems in the user operation process, but there were also two problems:
Problem No.1: Scattered components
Since the historical architecture is based on the combination of SparkSQL + Kudu + HDFS, too many dependent components lead to high operation and maintenance costs. The original design is that each component uses the resources of the public cluster, but in practice, it is found that during the execution of the query job, the query performance is easily affected by other jobs in the public cluster, and query jitter is prone to occur, especially when reading data from the HDFS public cluster , sometimes slower.
Problem No.2: High resource consumption
When querying through SparkSQL, the latency is relatively high. SparkSQL is a query engine designed based on a batch processing system. In the process of exchanging data shuffle between each stage, it still needs to be placed on the disk, and the delay in completing the SQL query is relatively high. In order to ensure that SQL queries are not affected by resources, we ensure query performance by adding machines. However, in practice, we find that there is limited room for performance improvement. This solution cannot make full use of machine resources to achieve efficient queries. A certain waste of resources.
In response to the above two problems, our goal is to seek an MPP database that integrates computing and storage to replace our current storage and computing layer components. After technical selection, we finally decided to use Apache Doris to replace the older generation of historical architecture.
New Choice
Popular MPP-based query engines such as Impala and Presto, can efficiently support SQL queries, but they still need to rely on Kudu, HDFS, Hive Metastore and other storage system, which increase the operation and maintenance costs. At the same time, due to the separation of storage and compute, the query engine cannot easily find the data changes in the storage layer, resulting in bad performance in detailed query optimization. If you want to cache at the SQL layer, you cannot guarantee that the query results are up-to-date.
Apache Doris is a top-level project of the Apache Foundation. It is mainly positioned as a high-performance, real-time analytical database, and is mainly used to solve reports and multi-dimensional analysis. It integrates Google Mesa and Cloudera Impala technologies. We conducted an in-depth performance tests on Doris and communicated with the community many times. And finally, we determined to replace the previous computing and storage components with Doris.
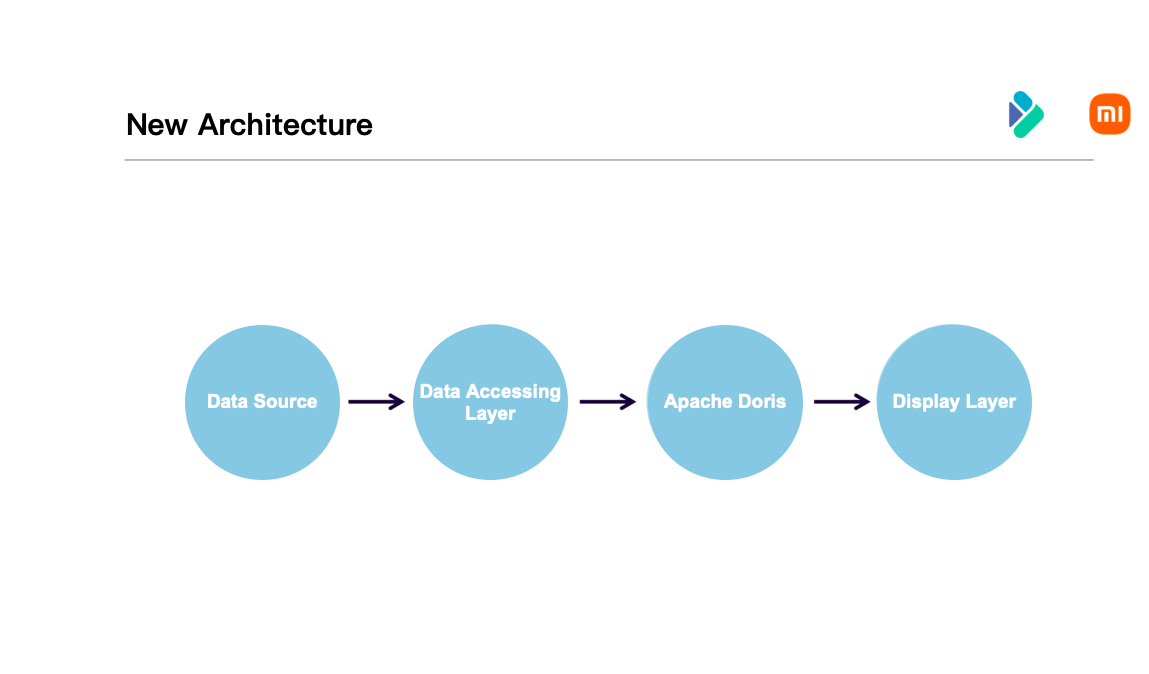
New Architecture Based on Apache Doris
The new architecture obtains event tracking data from the data source. Then data is ingested into Apache Doris. Query results can be directly displayed in the applications. In this way, Doris has truly realized the unification of computing, storage, and resource management tools.
We chose Doris because:
- Doris has excellent query performance and can meet our business needs.
- Doris supports standard SQL, and the learning cost is low.
- Doris does not depend on other external components and is easy to operate and maintain.
- The Apache Doris community is very active and friendly, crowded with contributors. It is easier for further versions upgrades and convenient for maintenance.
Query Performance Comparision between Apache Doris & Spark SQL
Note: The comparison is based on Apache Doris V0.13
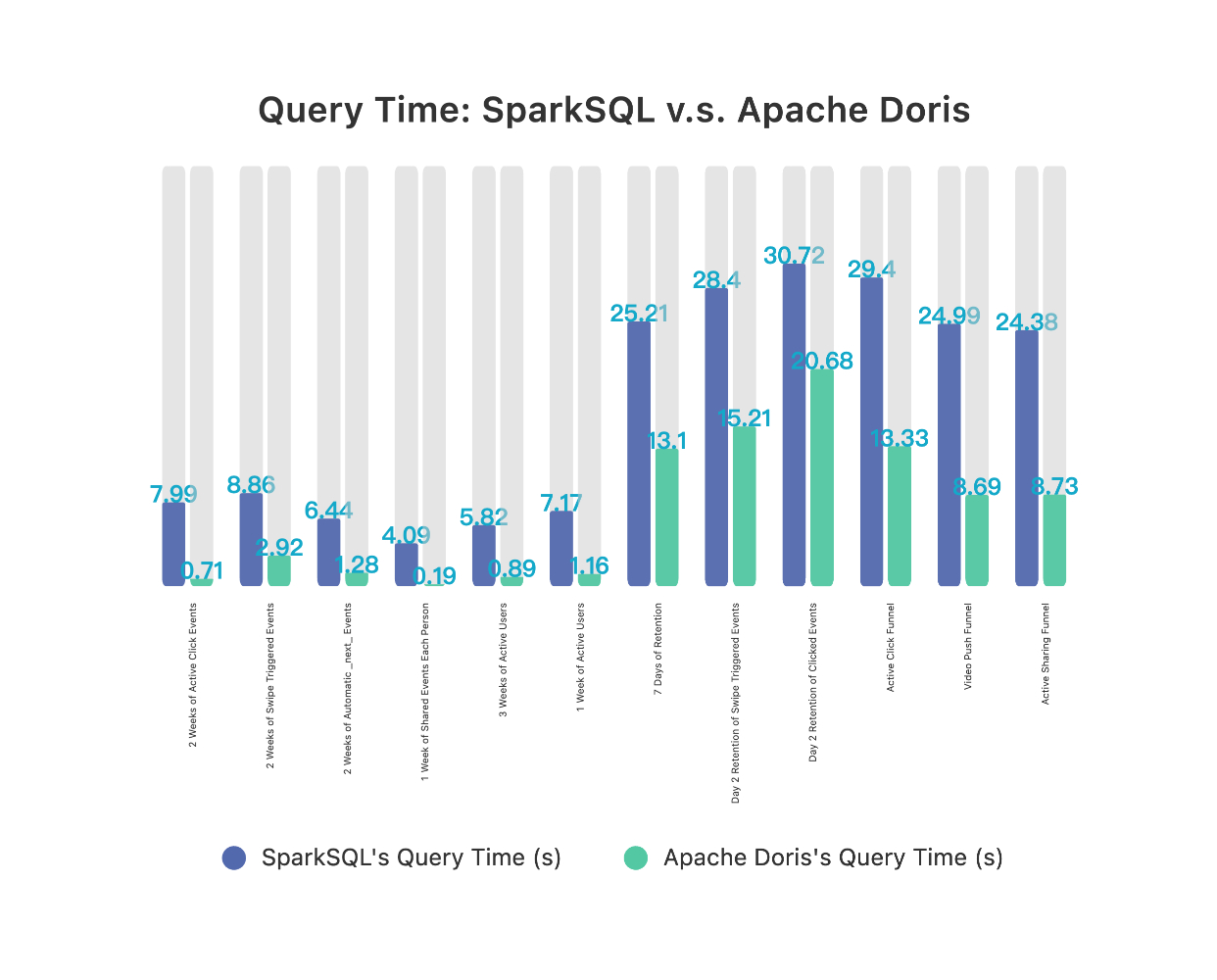
We selected a business model with an average daily data volume of about 1 billion, and conducted performance tests on Doris in different scenarios, including 6 event analysis scenarios, 3 retention analysis scenarios, and 3 funnel analysis scenarios. After comparing it with the previous architecture(SparkSQL+Kudu+HDFS), we found out:
- In the event analysis scenario, the average query time was reduced by 85%.
- In the scenarios of retention analysis and funnel analysis, the average query time was reduced by 50%.
Real Practice
Below we will introduce our experience of data import, data query, A/B test in the business application of Apache Doris.
Data Import
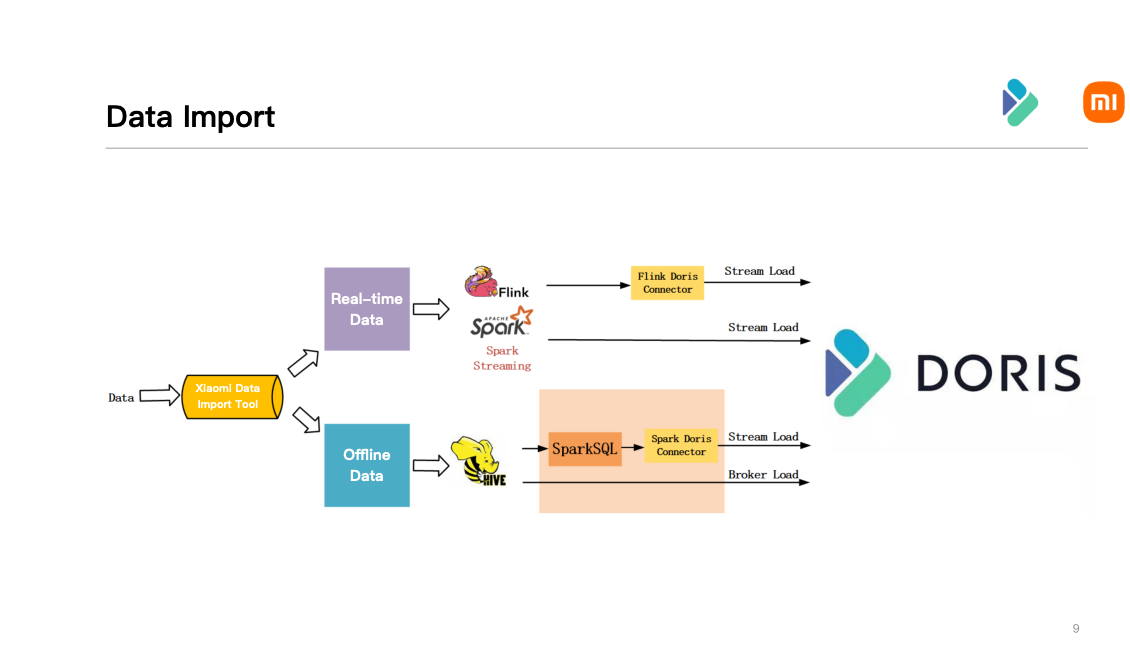
Xiaomi writes data into Doris mainly through Stream Load, Broker Load and a small amount of data by Insert. Usually data is generally ingested into the message queue first, which is divided into real-time and offline data.
How to write real-time data into Apache Doris:
After part of real-time data processed by Flink, they will be ingested into Doris through Flink-Doris-Connector provided by Apache Doris. The rest of the data is ingested through Spark Streaming. The bottom layer of these two writing approaches both rely on the Stream Load provided by Apache Doris.
How to write offline data into Apache Doris:
After offline data is partially ingested into Hive, they will be ingested into Doris through Xiaomi's data import tool. Users can directly submit Broker Load tasks to the Xiaomi's data import tool and import data directly into Doris, or import data through Spark SQL, which relies on the Spark-Doris-Connector provided by Apache Doris. Spark Doris Connector is actually the encapsulation of Stream Load.
Data Qurey
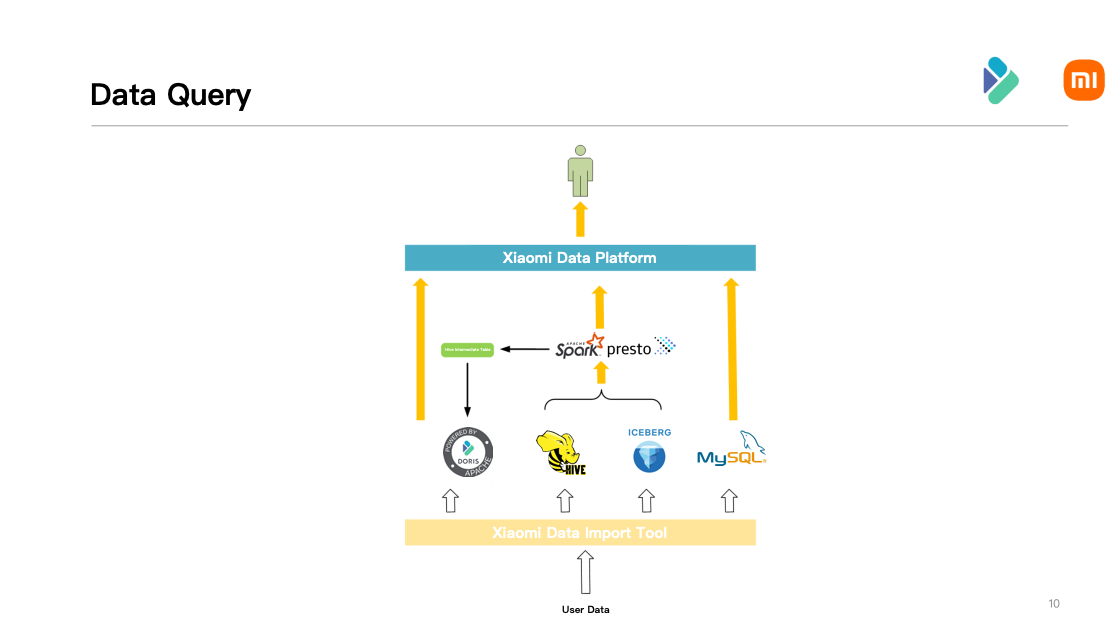
Users can query after data import is done. Inside Xiaomi, we query through our data platform. Users can perform visual queries on Doris through Xiaomi's data platform, and conduct user behavior analysis and user portrait analysis. In order to help our teams conduct event analysis, retention analysis, funnel analysis, path analysis and other behavioral analysis, we have added corresponding UDF (User Defined Function) and UDAF (User Defined Aggregate Function) to Doris.
In the upcoming version 1.2, Apache Doris adds the function of synchronizing metadata through external table, such as Hive/Hudi/Iceberg and Multi Catalog tool. External table query improves performance, and the ability to access external tables greatly increases ease of use. In the future, we will consider querying Hive and Iceberg data directly through Doris, which builds an architecture of datalake.
A/B Test
In real business, the A/B test is a method of comparing two versions of strategies against each other to determine which one performs better. A/B test is essentially an experiment where two or more variants of a page are shown to users at random, and statistical analysis. It is popular approach used to determine which variation performs better for a given conversion goal. Xiaomi's A/B test platform is an operation tool product that conducts the A/B test with experimental grouping, traffic splitting, and scientific evaluation to assist in decision making. Xiaomi's A/B test platform has several query applications: user deduplication, indicator summation, covariance calculation, etc. The query types will involve Count (distinct), Bitmap, Like, etc.
Apache Doris also provides services to Xiaomi's A/B test platform. Everyday, Xiaomi's A/B test platform needs to process a temendous amount of data with billions of queries. That's why Xiaomi's A/B test platform is eager to improve the query performance.
Apache Doris V1.1 released just in time and has fully supported vectorization in the processing and storage. Compared with the non-vectorized version, the query performance has been significantly improved. It is time to update Xiaomi's Doris cluster to the latest version. That's why we first launched the latest vectorized version of Doris on Xiaomi's A/B test platform.
Test before Launch
Note: The following tests are based on Apache Doris V1.1.2
We built a test cluster for Apache Doris V1.1.2, which is as big as that of the Xiaomi online Apache Doris V0.13 version, to test before the vectorization version goes online. The test is divided into two aspects: single SQL parrellel query test and batch SQL concurrent query test.
The configurations of the two clusters are exactly the same, and the specific configuration information is as follows:
- Scale: 3 FEs + 89 virtual machines
- CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz 16 cores 32 threads × 2
- Memory: 256GB
- Disk: 7.3TB × 12 HDD
Single SQL Parrellel Query Test
We choose 7 classic queries in the Xiaomi A/B test. For each query, we limited the time range to 1 day, 7 days, and 20 days for testing, where the daily partition data size is about 3.1 billion (the data volume is about 2 TB). The test results are shown in the figures:
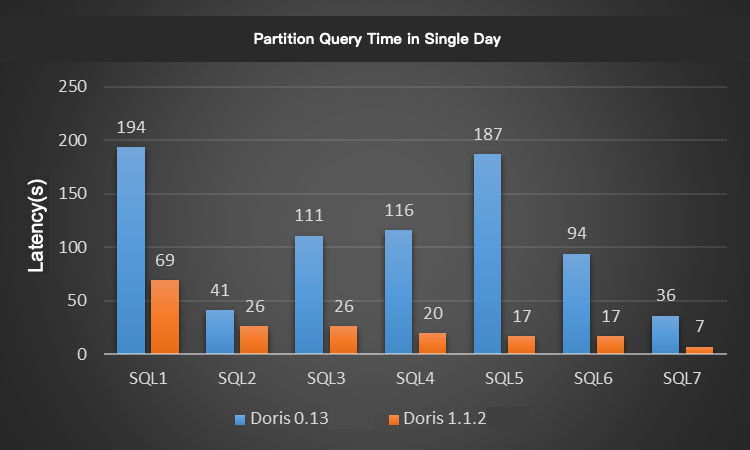
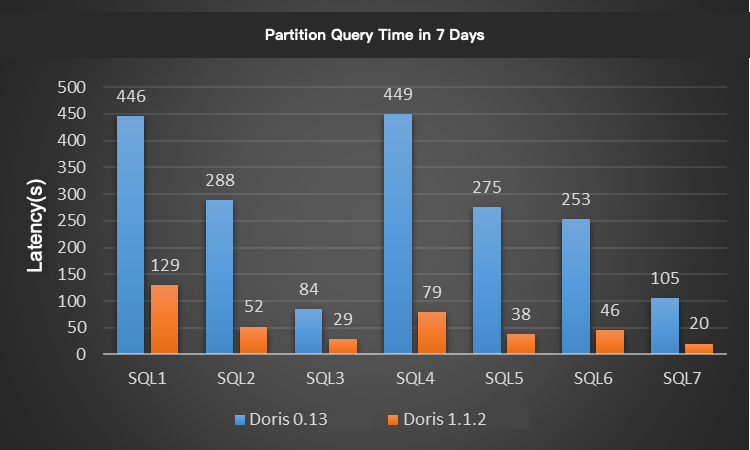
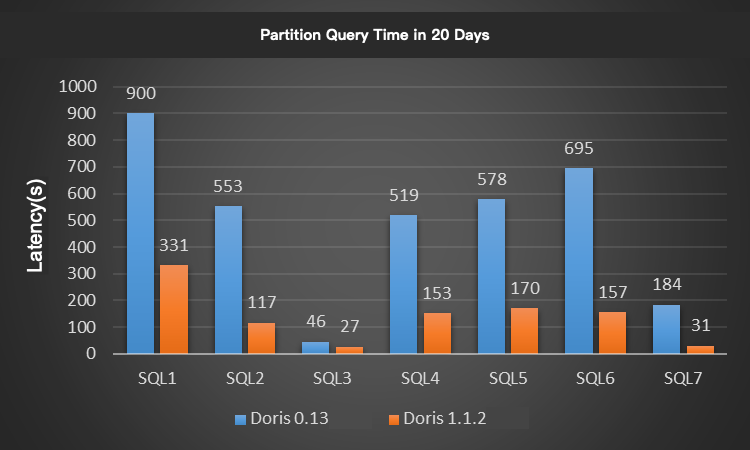
The Apache Doris V1.1.2 has at least 3~5 times performance improvement compared to the Xiaomi online Doris V0.13, which is remarkable.
Optimization
Note: The following tests are based on Apache Doris V1.1.2
Based on Xiaomi's A/B test business data, we tuned Apache Doris V1.1.2 and conducted concurrent query tests on the tuned Doris V1.1.2 and Xiaomi's online Doris V0.13. The test results are as follows.
Optimization in Test 1
We choose user deduplication, index summation, and covariance calculation query(the total number of SQL is 3245) in the A/B test to conduct concurrent query tests on the two versions. The single-day partition data of the table is about 3.1 billion (the amount of data is about 2 TB) and the query will be based on the latest week's data. The test results are shown in the figures:
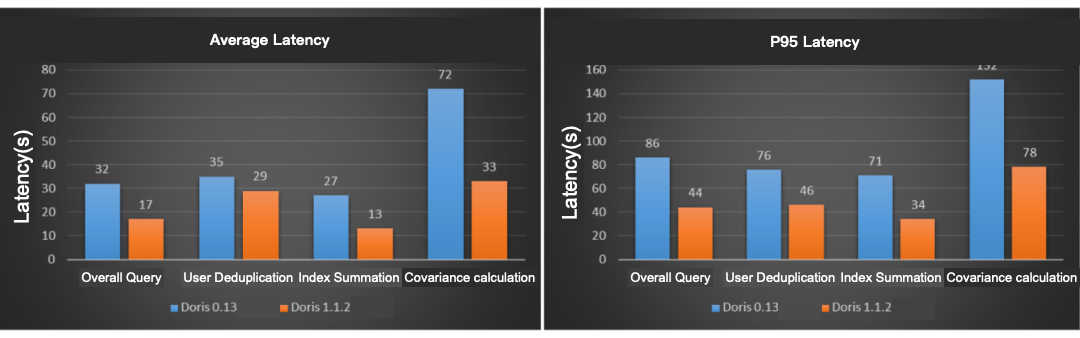
Compared with Apache Doris V0.13, the overall average latency of Doris V1.1.2 is reduced by about 48%, and the P95 latency is reduced by about 49%. In this test, the query performance of Doris V1.1.2 was nearly doubled compared to Doris V0.13.
Optimization in Test 2
We choose 7 A/B test reports to test the two versions. Each A/B test report is corresponded to two modules in Xiaomi A/B test platform and each module represents thousands of SQL query. Each report submits query tasks to the cluster where the two versions reside at the same concurrency. The test results are shown in the figure:
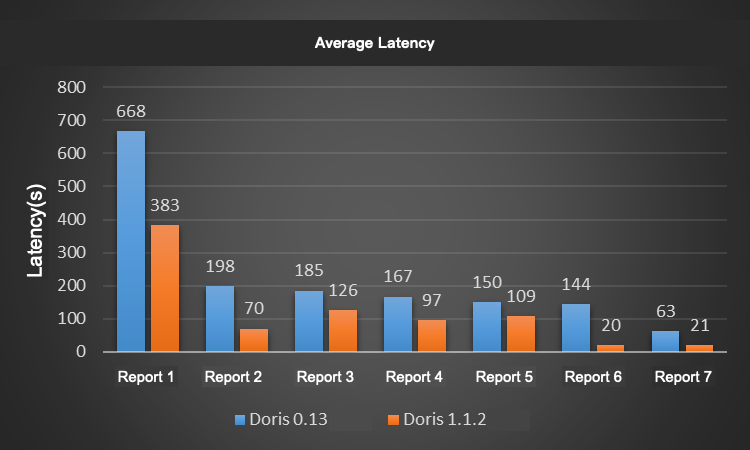
Compared with Doris V0.13, Doris V1.1.2 reduces the overall average latency by around 52%. In the test, the query performance of Doris V1.1.2 version was more than 1 time higher than that of Doris V0.13.
Optimization in Test 3
To verify the performance of the tuned Apache Doris V1.1.2 in other cases, we choose the Xiaomi user behavior analysis to conduct concurrent query performance tests of Doris V1.1.2 and Doris V0.13. We choose behavior analysis query for 4 days on October 24, 25, 26 and 27, 2022. The test results are shown in the figures:
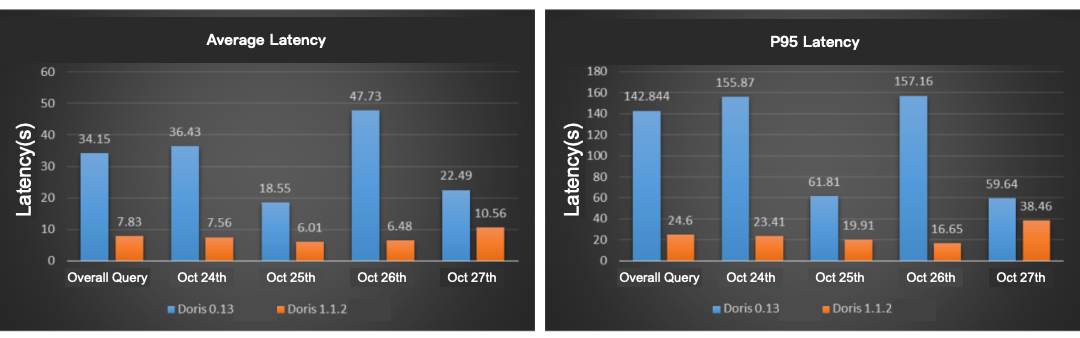
Compared with Doris V0.13, the overall average latency of Doris V1.1.2 has been reduced by about 77%, and the P95 latency has been reduced by about 83%. In this test, the query performance of Doris V1.1.2 version is 4~6 times higher than that of Doris V0.13.
Conclusion
Since we adopted Apache Doris in 2019, Apache Doris has currently served dozens of businesses and sub-brands within Xiaomi, with dozens of clusters and hundreds of nodes. It completes more than 10,000 user online analysis queries every day and is responsible for most of the online analysis in Xiaomi.
After performance test and tuning, Apache Doris V1.1.2 has met the launch requirements of the Xiaomi A/B test platform and does well in query performance and stability. In some cases, it even exceeds our expectations, such as the overall average latency being reduced by about 77% in our tuned version.
Meanwhile, some functions have in the above been released in Apache Doris V1.0 or V1.1, some PRs have been merged into the community Master Fork and should be released soon. Recently the activity of the community has been greatly enhanceed. We are glad to see that Apache Doris has become more and more mature, and stepped forward to an integrated datalake. We truly believe that in the future, more data analysis will be explored and realized within Apache Doris.
Contact Us
Apache Doris Website:http://doris.apache.org
Github Homepage:https://github.com/apache/doris
Email to DEV:dev@doris.apache.org