Metadata Design
This document describes the overall architecture, storage structure, and data flow of Apache Doris FE metadata, along with implementation details, the startup procedure, and the crash recovery mechanism.
Terminology
| Term | Description |
|---|---|
| FE | Frontend, the frontend node of Doris. It receives and returns client requests, manages metadata and the cluster, and generates query plans. |
| BE | Backend, the backend node of Doris. It stores and manages data and executes query plans. |
| bdbje | Oracle Berkeley DB Java Edition. In Doris, bdbje persists metadata operation logs and provides FE high availability. |
Overall Architecture
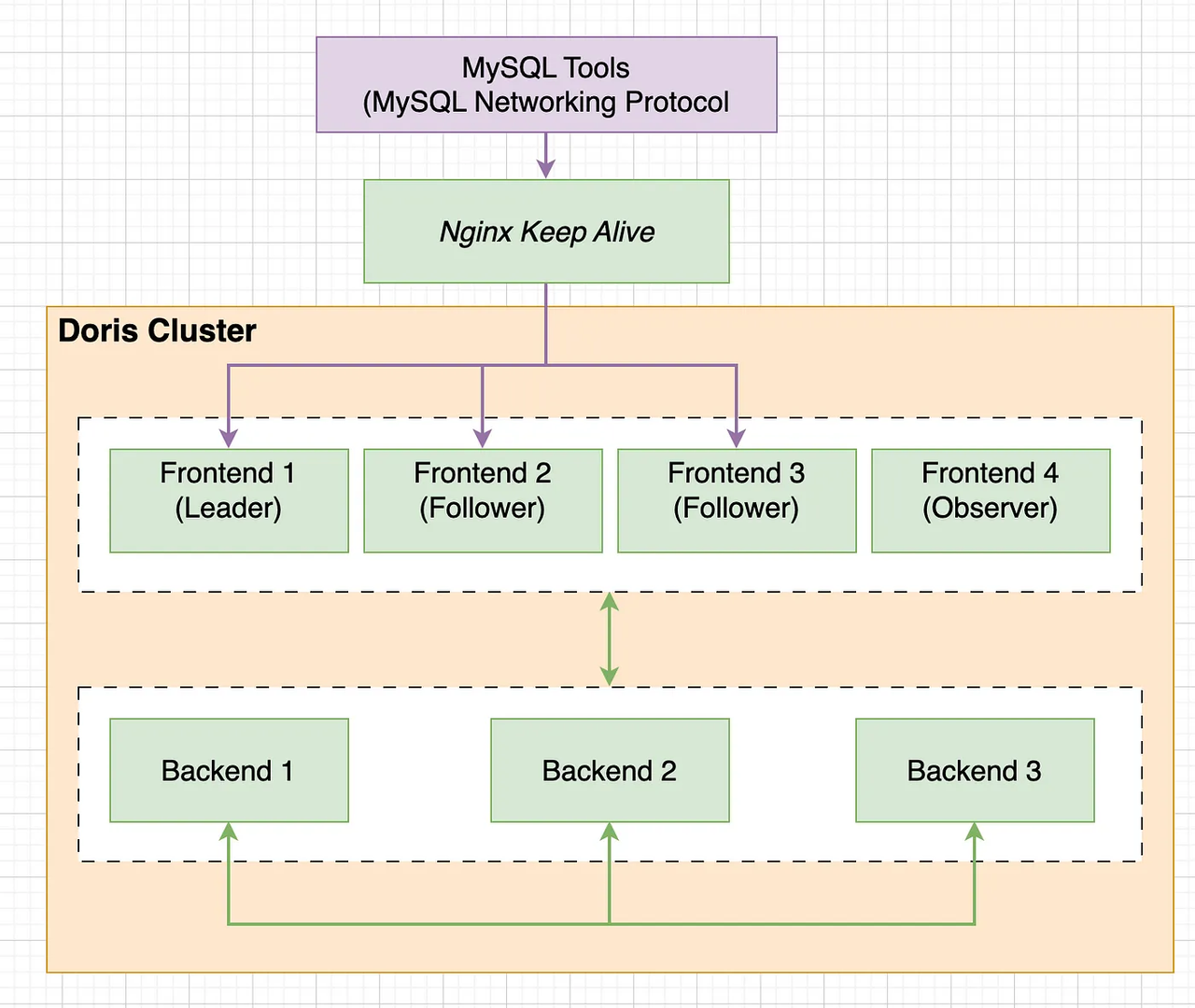
As shown above, Doris has a two-layer architecture. Multiple FEs form the first layer, providing horizontal scaling and high availability for the FE. Multiple BEs form the second layer, responsible for data storage and management. This document focuses on the design and implementation of metadata in the FE layer.
-
FE nodes are divided into two types: follower and observer. FEs perform leader election, data synchronization, and related work through bdbje (BerkeleyDB Java Edition).
-
Follower nodes elect a leader, which handles metadata write operations. When the leader node crashes, the remaining follower nodes elect a new leader to keep the service highly available.
-
Observer nodes only synchronize metadata from the leader and do not participate in elections. They can scale horizontally to extend the metadata read service.
Note: The concepts of follower and observer in Doris correspond to replica and observer in bdbje. Both names may appear in the text below.
Metadata Structure
Doris metadata is fully held in memory. Each FE maintains a complete metadata image in memory. In Baidu's internal deployment, a cluster with 2,500 tables and 1 million tablets (3 million replicas) uses only about 2 GB of memory for metadata. (Memory overhead for intermediate query objects, various job information, and so on must be estimated separately, but the overall memory footprint remains low.)
Metadata is stored in a tree-shaped hierarchy in memory, with auxiliary structures that enable fast access to metadata at each level.
The figure below shows what Doris metadata contains.
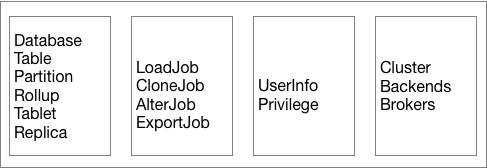
As shown above, Doris metadata stores four categories of data:
- User data information, including databases, table schemas, and tablet information.
- Various job information, such as load jobs, clone jobs, and schema change jobs.
- User and privilege information.
- Cluster and node information.
Data Flow
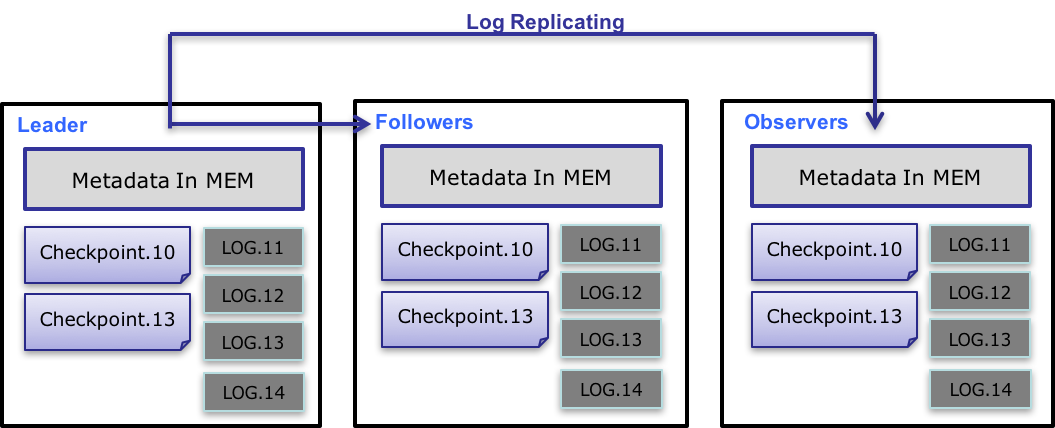
The metadata data flow works as follows:
-
Only the leader FE can write metadata. After a write operation modifies the leader's memory, it is serialized into a log entry and written to bdbje as a key-value pair. The key is a continuous integer that serves as the log id, and the value is the serialized operation log.
-
After the log is written to bdbje, bdbje replicates it to the other non-leader FE nodes according to its policy (write-majority or write-all). Non-leader FE nodes replay the log to update their own in-memory metadata image, completing metadata synchronization with the leader.
-
When the number of log entries on the leader reaches a threshold (10w entries by default) and the checkpoint thread schedule is met (60 seconds by default), the checkpoint reads the existing image file and the logs after it, replays a new metadata image copy in memory, and writes that copy to disk to form a new image. The reason for replaying a new image copy instead of writing the existing image directly is that writing the image requires a read lock, which would block write operations. As a result, each checkpoint uses twice the memory.
-
After the image file is generated, the leader notifies the other non-leader nodes that a new image is available. Non-leader nodes actively pull the latest image file over HTTP and replace the local old file.
-
Old logs in bdbje are deleted periodically after the image is generated.
Implementation Details
Metadata Directory
- The metadata directory is specified by the FE configuration item
meta_dir. - The
bdb/directory holds bdbje data. - The
image/directory holds image files.
The key files under the image/ directory are as follows:
| File | Description |
|---|---|
image.[logid] | The latest image file. The logid suffix indicates the id of the last log entry included in the image. |
image.ckpt | The image file currently being written. Once written successfully, it is renamed to image.[logid] and replaces the old image file. |
VERSION | Records the cluster_id, which uniquely identifies a Doris cluster. The cluster_id is a random 32-bit integer generated when the leader starts for the first time, and can also be specified through the FE configuration item cluster_id. |
ROLE | Records the FE's own role, which can only be FOLLOWER or OBSERVER. FOLLOWER indicates that the FE is an electable node. (Note: even the leader node has the role FOLLOWER.) |
Startup Procedure
-
On the first startup of an FE, if the start script is run without any parameters, the FE tries to start as the leader. The FE startup log eventually shows
transfer from UNKNOWN to MASTER. -
On the first startup of an FE, if the start script specifies the
--helperparameter pointing to a correct leader FE node, the FE first asks the leader over HTTP for its own role (the ROLE) and thecluster_id, then pulls the latest image file. After reading the image file and generating the metadata image, the FE starts bdbje to synchronize logs. Once synchronization is complete, it replays the logs after the image file in bdbje to produce the final metadata image.Note 1: When starting with the
--helperparameter, you must first add the FE on the leader using a mysql command, otherwise the startup fails with an error.Note 2:
--helpercan point to any follower node, not necessarily the leader.Note 3: While bdbje is synchronizing logs, the FE log shows
xxx detached. This indicates that log pulling is in progress and is expected. -
On a non-first startup of an FE, if the start script is run without any parameters, the FE determines its identity from the locally stored ROLE information. It also reads the leader information from the cluster information stored in the local bdbje, then reads the local image file and the logs in bdbje to generate the metadata image. (If the role recorded in the local ROLE does not match the one recorded in bdbje, an error is reported.)
-
On a non-first startup of an FE, if the start script specifies the
--helperparameter, the procedure is the same as the first startup: the FE first asks the leader for the role, but it then compares the result against the locally stored ROLE, and reports an error if they do not match.
Metadata Read, Write, and Synchronization
-
You can use mysql to connect to any FE node for metadata read and write access. If the connected node is a non-leader, it forwards the write operation to the leader. After the leader writes successfully, it returns the latest log id. The non-leader node then waits until its own replayed log id is greater than the returned log id before returning the success message to the client. This mechanism provides Read-Your-Write semantics on any FE node.
Note: Some non-write operations are also forwarded to the leader, such as
SHOW LOAD. These commands usually need to read the intermediate state of some jobs, and the intermediate state is not written to bdbje, so it does not exist in the memory of non-leader nodes. (Metadata synchronization between FEs relies entirely on bdbje log replay. If a metadata modification operation is not written to the bdbje log, the result of the modification cannot be observed on other non-leader nodes.) -
The leader node starts a
TimePrinterthread that periodically writes a key-value entry containing the current time to bdbje. The remaining non-leader nodes replay this log, read the time recorded in it, and compare it with their local time. If the local time lag exceeds the specified threshold (the configuration itemmeta_delay_toleration_second, with a write interval set to half of this value), the node enters an unreadable state. This mechanism prevents a non-leader node from continuing to serve stale metadata after losing contact with the leader for a long time. -
Metadata across FEs is only eventually consistent. Under normal conditions, the inconsistency window is on the order of milliseconds. Monotonic consistency of metadata access is guaranteed within the same session, but if the same client connects to different FEs, a metadata rollback can occur. (For batch-update systems, the impact of this issue is minor.)
Crash Recovery
| Scenario | Behavior |
|---|---|
| Leader node crashes | The remaining followers immediately elect a new leader to provide service. |
| Majority of follower nodes crash | Metadata cannot be written. If a write request arrives at this point, the current behavior is that the FE process exits directly. A future optimization will continue to provide read service in the unwritable state. |
| Observer node crashes | Has no impact on the state of any other node, nor on metadata reads or writes on other nodes. |