Group Commit
Group commit load does not introduce a new data import method, but an extension of INSERT INTO tbl VALUS(...), Stream Load and Http Stream. It is a way to improve the write performance of Doris with high-concurrency and small-data writes. Your application can directly use JDBC to do high-concurrency insert operation into Doris, at the same time, combining PreparedStatement can get even higher performance. In logging scenarios, you can also do high-concurrency Stream Load or Http Stream into Doris.
Group Commit Mode
Group Commit provides 3 modes:
off_mode
Disable group commit, keep the original behavior for INSERT INTO VALUES, Stream Load and Http Stream.
sync_mode
Doris groups multiple loads into one transaction commit based on the group_commit_interval table property. The load is returned after the transaction commit. This mode is suitable for high-concurrency writing scenarios and requires immediate data visibility after the load is finished.
async_mode
Doris writes data to the Write Ahead Log (WAL) firstly, then the load is returned. Doris groups multiple loads into one transaction commit based on the group_commit_interval table property, and the data is visible after the commit. To prevent excessive disk space usage by the WAL, it automatically switches to sync_mode. This is suitable for latency-sensitive and high-frequency writing.
The number of WALs can be viewed through the FE HTTP interface, as detailed here. Alternatively, you can search for the keyword wal in the BE metrics.
Basic operations
If the table schema is:
CREATE TABLE `dt` (
`id` int(11) NOT NULL,
`name` varchar(50) NULL,
`score` int(11) NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
Use JDBC
To reduce the CPU cost of SQL parsing and query planning, we provide the PreparedStatement in the FE. When using PreparedStatement, the SQL and its plan will be cached in the session level memory cache and will be reused later on, which reduces the CPU cost of FE. The following is an example of using PreparedStatement in JDBC:
- Setup JDBC url and enable server side prepared statement
url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500
- Set
group_commitsession variable, there are two ways to do it:
- Add
sessionVariables=group_commit=async_modein JDBC url
url = url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500&sessionVariables=group_commit=async_mode
- Use
SET group_commit = async_mode;command
try (Statement statement = conn.createStatement()) {
statement.execute("SET group_commit = async_mode;");
}
- Using
PreparedStatement
private static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
private static final String URL_PATTERN = "jdbc:mysql://%s:%d/%s?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500&sessionVariables=group_commit=async_mode";
private static final String HOST = "127.0.0.1";
private static final int PORT = 9087;
private static final String DB = "db";
private static final String TBL = "dt";
private static final String USER = "root";
private static final String PASSWD = "";
private static final int INSERT_BATCH_SIZE = 10;
private static void groupCommitInsertBatch() throws Exception {
Class.forName(JDBC_DRIVER);
// add rewriteBatchedStatements=true and cachePrepStmts=true in JDBC url
// set session variables by sessionVariables=group_commit=async_mode in JDBC url
try (Connection conn = DriverManager.getConnection(
String.format(URL_PATTERN, HOST, PORT, DB), USER, PASSWD)) {
String query = "insert into " + TBL + " values(?, ?, ?)";
try (PreparedStatement stmt = conn.prepareStatement(query)) {
for (int j = 0; j < 5; j++) {
// 10 rows per insert
for (int i = 0; i < INSERT_BATCH_SIZE; i++) {
stmt.setInt(1, i);
stmt.setString(2, "name" + i);
stmt.setInt(3, i + 10);
stmt.addBatch();
}
int[] result = stmt.executeBatch();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
Note: Due to the high frequency of INSERT INTO statements, a large amount of audit logs might be printed, which could impact overall performance. By default, the audit log for prepared statements is disabled. You can control whether to print the audit log for prepared statements by setting a session variable.
# Configure the session variable to enable printing the audit log for prepared statements. By default, it is set to false, which disables printing the audit log for prepared statements.
set enable_prepared_stmt_audit_log=true;
For more usage on JDBC, refer to Using Insert to Synchronize Data.
Using Golang for Group Commit
Golang has limited support for prepared statements, so we can manually batch the statements on the client side to improve the performance of Group Commit. Below is an example program.
package main
import (
"database/sql"
"fmt"
"math/rand"
"strings"
"sync"
"sync/atomic"
"time"
_ "github.com/go-sql-driver/mysql"
)
const (
host = "127.0.0.1"
port = 9038
db = "test"
user = "root"
password = ""
table = "async_lineitem"
)
var (
threadCount = 20
batchSize = 100
)
var totalInsertedRows int64
var rowsInsertedLastSecond int64
func main() {
dbDSN := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?parseTime=true", user, password, host, port, db)
db, err := sql.Open("mysql", dbDSN)
if err != nil {
fmt.Printf("Error opening database: %s\n", err)
return
}
defer db.Close()
var wg sync.WaitGroup
for i := 0; i < threadCount; i++ {
wg.Add(1)
go func() {
defer wg.Done()
groupCommitInsertBatch(db)
}()
}
go logInsertStatistics()
wg.Wait()
}
func groupCommitInsertBatch(db *sql.DB) {
for {
valueStrings := make([]string, 0, batchSize)
valueArgs := make([]interface{}, 0, batchSize*16)
for i := 0; i < batchSize; i++ {
for i = 0; i < batchSize; i++ {
valueStrings = append(valueStrings, "(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)")
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, "N")
valueArgs = append(valueArgs, "O")
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, "DELIVER IN PERSON")
valueArgs = append(valueArgs, "SHIP")
valueArgs = append(valueArgs, "N/A")
}
}
stmt := fmt.Sprintf("INSERT INTO %s VALUES %s",
table, strings.Join(valueStrings, ","))
_, err := db.Exec(stmt, valueArgs...)
if err != nil {
fmt.Printf("Error executing batch: %s\n", err)
return
}
atomic.AddInt64(&rowsInsertedLastSecond, int64(batchSize))
atomic.AddInt64(&totalInsertedRows, int64(batchSize))
}
}
func logInsertStatistics() {
for {
time.Sleep(1 * time.Second)
fmt.Printf("Total inserted rows: %d\n", totalInsertedRows)
fmt.Printf("Rows inserted in the last second: %d\n", rowsInsertedLastSecond)
rowsInsertedLastSecond = 0
}
}
INSERT INTO VALUES
- async_mode
# Config session variable to enable the async group commit, the default value is off_mode
mysql> set group_commit = async_mode;
# The retured label is start with 'group_commit', which is the label of the real load job
mysql> insert into dt values(1, 'Bob', 90), (2, 'Alice', 99);
Query OK, 2 rows affected (0.05 sec)
{'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'}
# The returned label and txn_id are the same as the above, which means they are handled in on load job
mysql> insert into dt(id, name) values(3, 'John');
Query OK, 1 row affected (0.01 sec)
{'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'}
# The data is not visible
mysql> select * from dt;
Empty set (0.01 sec)
# After about 10 seconds, the data is visible
mysql> select * from dt;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Bob | 90 |
| 2 | Alice | 99 |
| 3 | John | NULL |
+------+-------+-------+
3 rows in set (0.02 sec)
- sync_mode
# Config session variable to enable the sync group commit
mysql> set group_commit = sync_mode;
# The retured label is start with 'group_commit', which is the label of the real load job.
# The insert costs at least the group_commit_interval_ms of table property.
mysql> insert into dt values(4, 'Bob', 90), (5, 'Alice', 99);
Query OK, 2 rows affected (10.06 sec)
{'label':'group_commit_d84ab96c09b60587_ec455a33cb0e9e87', 'status':'PREPARE', 'txnId':'3007', 'query_id':'fc6b94085d704a94-a69bfc9a202e66e2'}
# The data is visible after the insert is returned
mysql> select * from dt;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Bob | 90 |
| 2 | Alice | 99 |
| 3 | John | NULL |
| 4 | Bob | 90 |
| 5 | Alice | 99 |
+------+-------+-------+
5 rows in set (0.03 sec)
- off_mode
mysql> set group_commit = off_mode;
Stream Load
If the content of data.csv is:
6,Amy,60
7,Ross,98
- async_mode
# Add 'group_commit:async_mode' configuration in the http header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:async_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load
{
"TxnId": 7009,
"Label": "group_commit_c84d2099208436ab_96e33fda01eddba8",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 35,
"StreamLoadPutTimeMs": 5,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 26
}
# The returned 'GroupCommit' is 'true', which means this is a group commit load
# The retured label is start with 'group_commit', which is the label of the real load job
- sync_mode
# Add 'group_commit:sync_mode' configuration in the http header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:sync_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load
{
"TxnId": 3009,
"Label": "group_commit_d941bf17f6efcc80_ccf4afdde9881293",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 10044,
"StreamLoadPutTimeMs": 4,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 10038
}
# The returned 'GroupCommit' is 'true', which means this is a group commit load
# The retured label is start with 'group_commit', which is the label of the real load job
See Stream Load for more detailed syntax used by Stream Load.
Http Stream
- async_mode
# Add 'group_commit:async_mode' configuration in the http header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:async_mode" -H "sql:insert into db.dt select * from http_stream('column_separator'=',', 'format' = 'CSV')" http://{fe_host}:{http_port}/api/_http_stream
{
"TxnId": 7011,
"Label": "group_commit_3b45c5750d5f15e5_703428e462e1ebb0",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 65,
"StreamLoadPutTimeMs": 41,
"ReadDataTimeMs": 47,
"WriteDataTimeMs": 23
}
# The returned 'GroupCommit' is 'true', which means this is a group commit load
# The retured label is start with 'group_commit', which is the label of the real load job
- sync_mode
# Add 'group_commit:sync_mode' configuration in the http header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:sync_mode" -H "sql:insert into db.dt select * from http_stream('column_separator'=',', 'format' = 'CSV')" http://{fe_host}:{http_port}/api/_http_stream
{
"TxnId": 3011,
"Label": "group_commit_fe470e6752aadbe6_a8f3ac328b02ea91",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 10066,
"StreamLoadPutTimeMs": 31,
"ReadDataTimeMs": 32,
"WriteDataTimeMs": 10034
}
# The returned 'GroupCommit' is 'true', which means this is a group commit load
# The retured label is start with 'group_commit', which is the label of the real load job
See Stream Load for more detailed syntax used by Http Stream.
Group commit condition
The data will be automatically committed either when the time interval (default is 10 seconds) or the data size (default is 64 MB) conditions meet.
Modify the time interval condition
The default group commit interval is 10 seconds. Users can modify the configuration of the table:
# Modify the group commit interval to 2 seconds
ALTER TABLE dt SET ("group_commit_interval_ms" = "2000");
Modify the data size condition
The default group commit data size is 64 MB. Users can modify the configuration of the table:
# Modify the group commit data size to 128MB
ALTER TABLE dt SET ("group_commit_data_bytes" = "134217728");
Limitations
-
When the group commit is enabled, some
INSERT INTO VALUESsqls are not executed in the group commit way if they meet the following conditions:-
Transaction insert, such as
BEGIN,INSERT INTO VALUES,COMMIT -
Specify the label, such as
INSERT INTO dt WITH LABEL {label} VALUES -
Expressions within VALUES, such as
INSERT INTO dt VALUES (1 + 100) -
Column update
-
Tables that do not support light schema changes
-
-
When the group commit is enabled, some
Stream LoadandHttp Streamare not executed in the group commit way if they meet the following conditions:-
Two phase commit
-
Specify the label by set header
-H "label:my_label" -
Column update
-
Tables that do not support light schema changes
-
-
For unique table, because the group commit can not guarantee the commit order, users can use sequence column to ensure the data consistency.
-
The limit of
max_filter_ratio-
For non group commit load, filter_ratio is calculated by the failed rows and total rows when load is finished. If the filter_ratio does not match, the transaction will not commit
-
In the group commit mode, multiple user loads are executed by one internal load. The internal load will commit all user loads.
-
Currently, group commit supports a certain degree of max_filter_ratio semantics. When the total number of rows does not exceed group_commit_memory_rows_for_max_filter_ratio (configured in
be.conf, defaulting to10000rows), max_filter_ratio will work.
-
-
The limit of WAL
-
For async_mode group commit, data is written to the Write Ahead Log (WAL). If the internal load succeeds, the WAL is immediately deleted. If the internal load fails, data is recovery by importing the WAL.
-
Currently, WAL files are stored only on one disk of one BE. If the BE's disk is damaged or the file is mistakenly deleted, it may result in data loss.
-
When decommissioning a BE node, please use the
DECOMMISSIONcommand to safely decommission the node. This prevents potential data loss if the WAL files are not processed before the node is taken offline. -
For async_mode group commit writes, to protect disk space, it switches to sync_mode under the following conditions:
-
For an import with large amount of data: exceeding 80% of the disk space of a WAL directory.
-
Chunked stream loads with an unknown data amount.
-
Insufficient disk space, even with it is an import with small amount of data.
-
-
During hard weight schema changes (adding or dropping columns, modifying varchar length, and renaming columns are lightweight schema changes, others are hard weight), to ensure WAL file is compatibility with the table's schema, the final stage of metadata modification in FE will reject group commit writes. Clients get
insert table ${table_name} is blocked on schema changeexception and can retry the import.
-
Relevant system configuration
BE configuration
group_commit_wal_path
- The
WALdirectory of group commit. - Default: A directory named
walis created under each directory of thestorage_root_path. Configuration examples:group_commit_wal_path=/data1/storage/wal;/data2/storage/wal;/data3/storage/wal
group_commit_memory_rows_for_max_filter_ratio
- Description: The
max_filter_ratiolimit can only work if the total rows ofgroup commitis less than this value. - Default: 10000
Performance
We have separately tested the write performance of group commit in high-concurrency scenarios with small data volumes using Stream Load and JDBC (in async mode).
Stream Load
Environment
-
1 Front End (FE) server: Alibaba Cloud with 8-core CPU, 16GB RAM, and one 100GB ESSD PL1 SSD.
-
3 Backend (BE) servers: Alibaba Cloud with 16-core CPU, 64GB RAM, and one 1TB ESSD PL1 SSD.
-
1 Test Client: Alibaba Cloud with 16-core CPU, 64GB RAM, and one 100GB ESSD PL1 SSD.
-
The version for testing is Doris-2.1.5.
DataSet
httplogs, 31 GB, 247249096 (247 million) rows
Test Tool
Test Method
- Setting different single-concurrency data size and concurrency num between
non group_commitandgroup_commit=async modemodes.
Test Result
| Load Way | Single-concurrency Data Size | Concurrency | Cost Seconds | Rows / Seconds | MB / Seconds |
|---|---|---|---|---|---|
| group_commit | 10 KB | 10 | 3306 | 74,787 | 9.8 |
| group_commit | 10 KB | 30 | 3264 | 75,750 | 10.0 |
| group_commit | 100 KB | 10 | 424 | 582,447 | 76.7 |
| group_commit | 100 KB | 30 | 366 | 675,543 | 89.0 |
| group_commit | 500 KB | 10 | 187 | 1,318,661 | 173.7 |
| group_commit | 500 KB | 30 | 183 | 1,351,087 | 178.0 |
| group_commit | 1 MB | 10 | 178 | 1,385,148 | 182.5 |
| group_commit | 1 MB | 30 | 178 | 1,385,148 | 182.5 |
| group_commit | 10 MB | 10 | 177 | 1,396,887 | 184.0 |
| non group_commit | 1 MB | 10 | 2824 | 87,536 | 11.5 |
| non group_commit | 10 MB | 10 | 450 | 549,442 | 68.9 |
| non group_commit | 10 MB | 30 | 177 | 1,396,887 | 184.0 |
In the above test, the CPU usage of BE fluctuates between 10-40%.
The group_commit effectively enhances import performance while reducing the number of versions, thereby alleviating the pressure on compaction.
JDBC
Environment
1 Front End (FE) server: Alibaba Cloud with an 8-core CPU, 16GB RAM, and one 100GB ESSD PL1 SSD.
1 Backend (BE) server: Alibaba Cloud with a 16-core CPU, 64GB RAM, and one 500GB ESSD PL1 SSD.
1 Test Client: Alibaba Cloud with a 16-core CPU, 64GB RAM, and one 100GB ESSD PL1 SSD.
The testing version is Doris-2.1.5.
Disable the printing of prepared statement audit logs to enhance performance.
DataSet
- The data of tpch sf10
lineitemtable, 20 files, 14 GB, 120 million rows
Test Method
Test Method
- Use
txtfilereaderwtite data tomysqlwriter, config different concurrenncy and rows for perINSERTsql.
Test Result
| Rows per insert | Concurrency | Rows / Second | MB / Second |
|---|---|---|---|
| 100 | 10 | 107,172 | 11.47 |
| 100 | 20 | 140,317 | 14.79 |
| 100 | 30 | 142,882 | 15.28 |
In the above test, the CPU usage of BE fluctuates between 10-20%, FE fluctuates between 60-70%.
Insert into Sync Mode Small Batch Data
Machine Configuration
- 1 Front-End (FE): Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 500GB ESSD PL1 cloud disk
- 5 Back-End (BE) nodes: Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 1TB ESSD PL1 cloud disk.
- 1 Testing Client: Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 100GB ESSD PL1 cloud disk
- Test version: Doris-2.1.5
Dataset
-
The data of tpch sf10
lineitemtable. -
The create table statement is
CREATE TABLE IF NOT EXISTS lineitem (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 32
PROPERTIES (
"replication_num" = "3"
);
Testing Tool
JMeter Parameter Settings as Shown in the Images
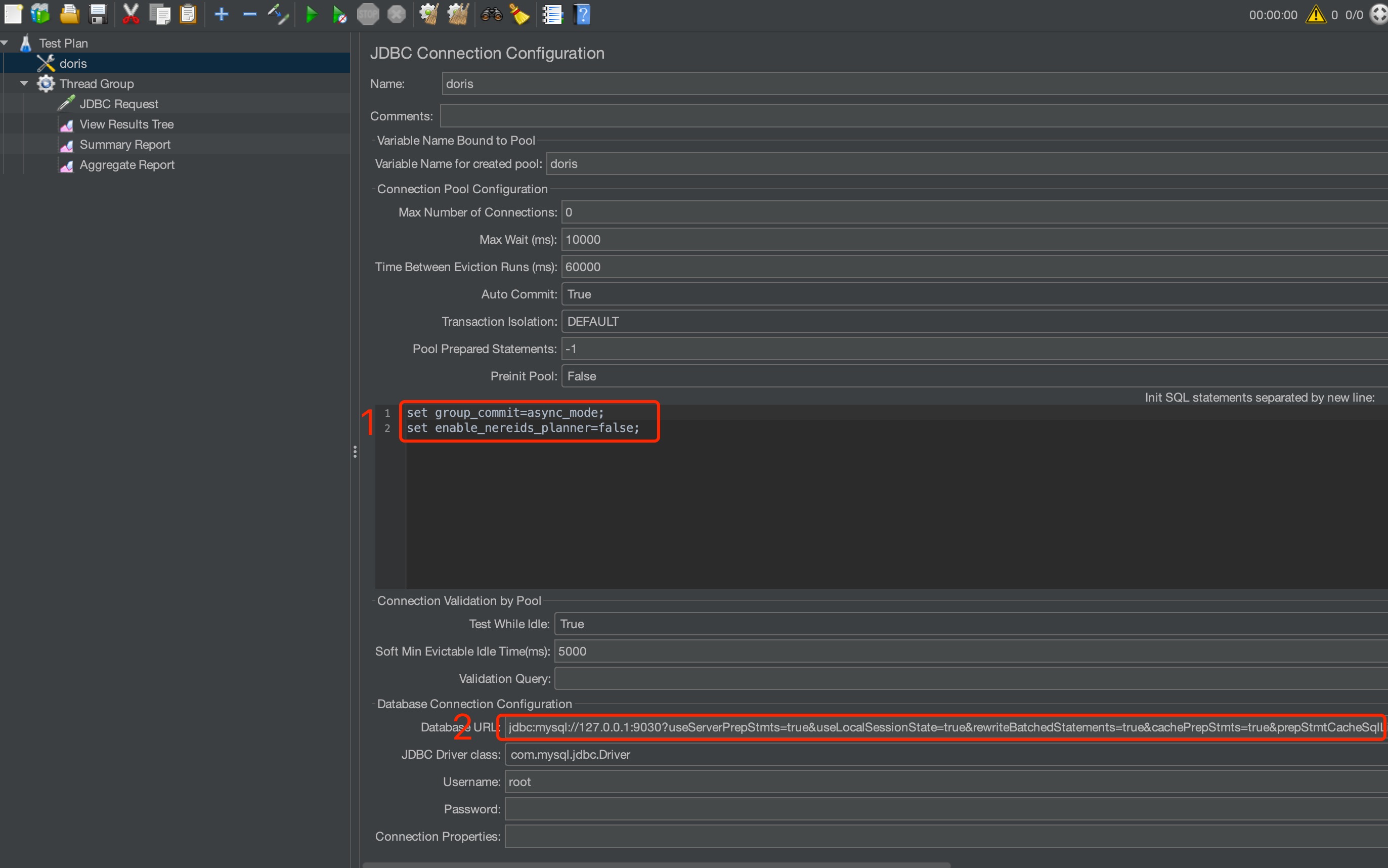
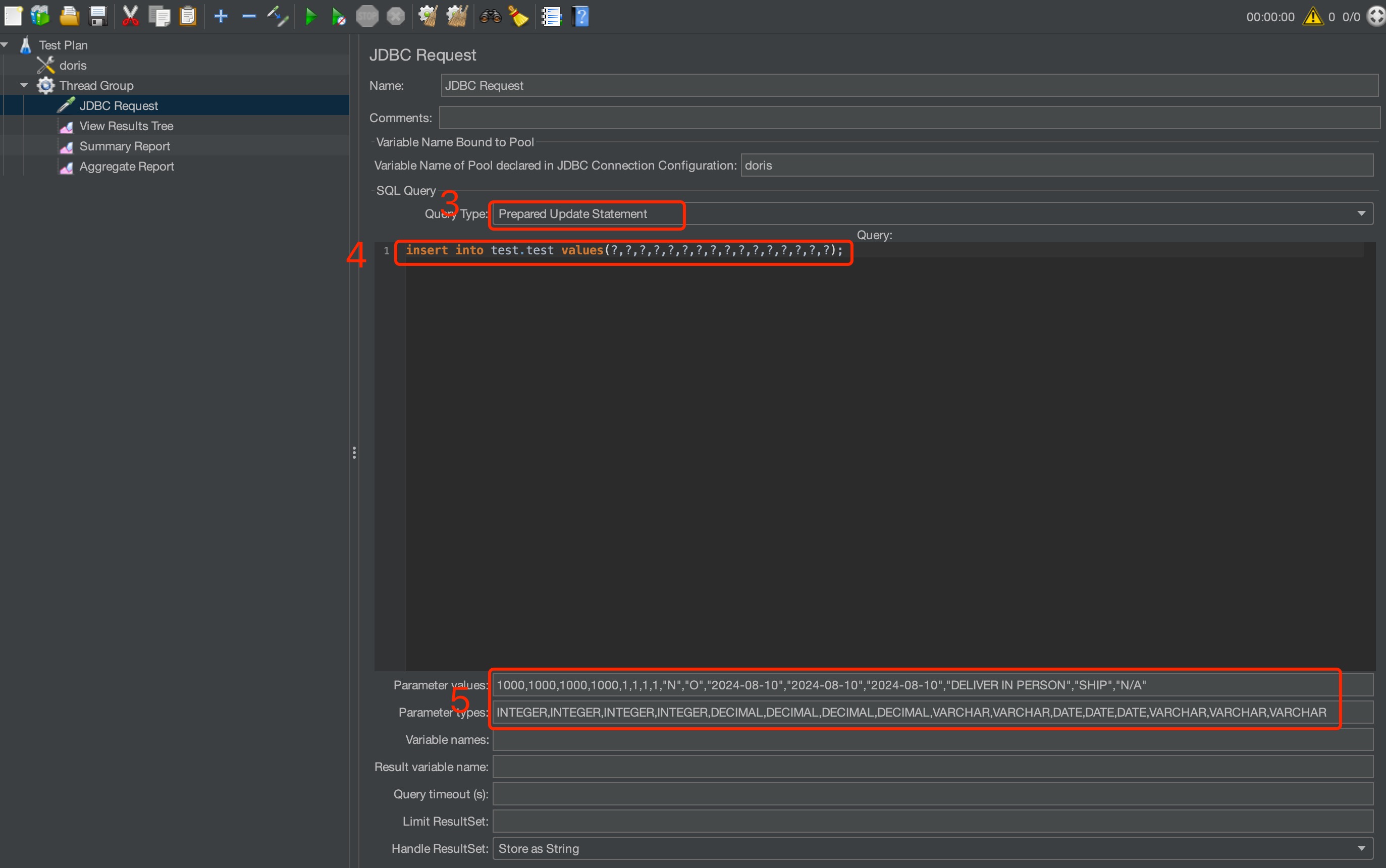
-
Set the Init Statement Before Testing: set group_commit=async_mode and set enable_nereids_planner=false.
-
Enable JDBC Prepared Statement: Complete URL: jdbc:mysql://127.0.0.1:9030?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=50&sessionVariables=group_commit=async_mode&sessionVariables=enable_nereids_planner=false.
-
Set the Import Type to Prepared Update Statement.
-
Set the Import Statement.
-
Set the Values to Be Imported: Ensure that the imported values match the data types one by one.
Testing Methodology
- Use JMeter to write data into Doris. Each thread writes 1 row of data per execution using the insert into statement.
Test Results
-
Data unit: rows per second.
-
The following tests are divided into 30, 100, and 500 concurrency.
Performance Test with 30 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 321.5 | 307.3 | 285.8 | 224.3 |
Performance Test with 100 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 1175.2 | 1108.7 | 1016.3 | 704.5 |
Performance Test with 500 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 3289.8 | 3686.7 | 3280.7 | 2609.2 |
Insert into Sync Mode Large Batch Data
Machine Configuration
-
1 Front-End (FE): Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 500GB ESSD PL1 cloud disk
-
5 Back-End (BE) nodes: Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 1TB ESSD PL1 cloud disk.
-
1 Testing Client: Alibaba Cloud, 16-core CPU, 64GB RAM, 1 x 100GB ESSD PL1 cloud disk
-
Test version: Doris-2.1.5
Dataset
- Insert into statement for 1000 rows:
insert into tbl values(1,1)...(1000 rows omitted)
Testing Tool
Testing Methodology
- Use JMeter to write data into Doris. Each thread writes 1000 row of data per execution using the insert into statement.
Test Results
-
Data unit: rows per second.
-
The following tests are divided into 30, 100, and 500 concurrency.
Performance Test with 30 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group commit internal | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 92.2K | 85.9K | 84K | 83.2K |
Performance Test with 100 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group commit internal | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 70.4K | 70.5K | 73.2K | 69.4K |
Performance Test with 500 Concurrent Users in Sync Mode, 5 BEs, and 3 Replicas
| Group commit internal | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 46.3K | 47.7K | 47.4K | 46.5K |
