
Large-scale Performance Benchmark
This page summarizes large-scale benchmark results in both single-node and distributed deployments. The purpose of these tests is to show query behavior at different data scales, and to illustrate how Doris extends vector query capacity from single-node workloads to larger distributed deployments.
Test Matrix
- Single node: FE/BE separated, BE on one 16C64GB machine.
- Distributed: 3 BE nodes, each 16C64GB.
- Workloads:
- Performance768D10M
- Performance1536D5M
- Performance768D100M
Single-node Benchmark (16C64GB)
The single-node results provide a baseline for ANN query performance on medium-to-large datasets.
Import Performance
| Item | Performance768D10M | Performance1536D5M |
|---|---|---|
| Dimension | 768 | 1536 |
| metric_type | inner_product | inner_product |
| Rows | 10M | 5M |
| Batch config | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 | NUM_PER_BATCH=250000--stream-load-rows-per-batch 250000 |
| Import time | 76m41s | 41m |
show data all | 56.498 GB (25.354 GB + 31.145 GB) | 55.223 GB (25.346 GB + 29.878 GB) |
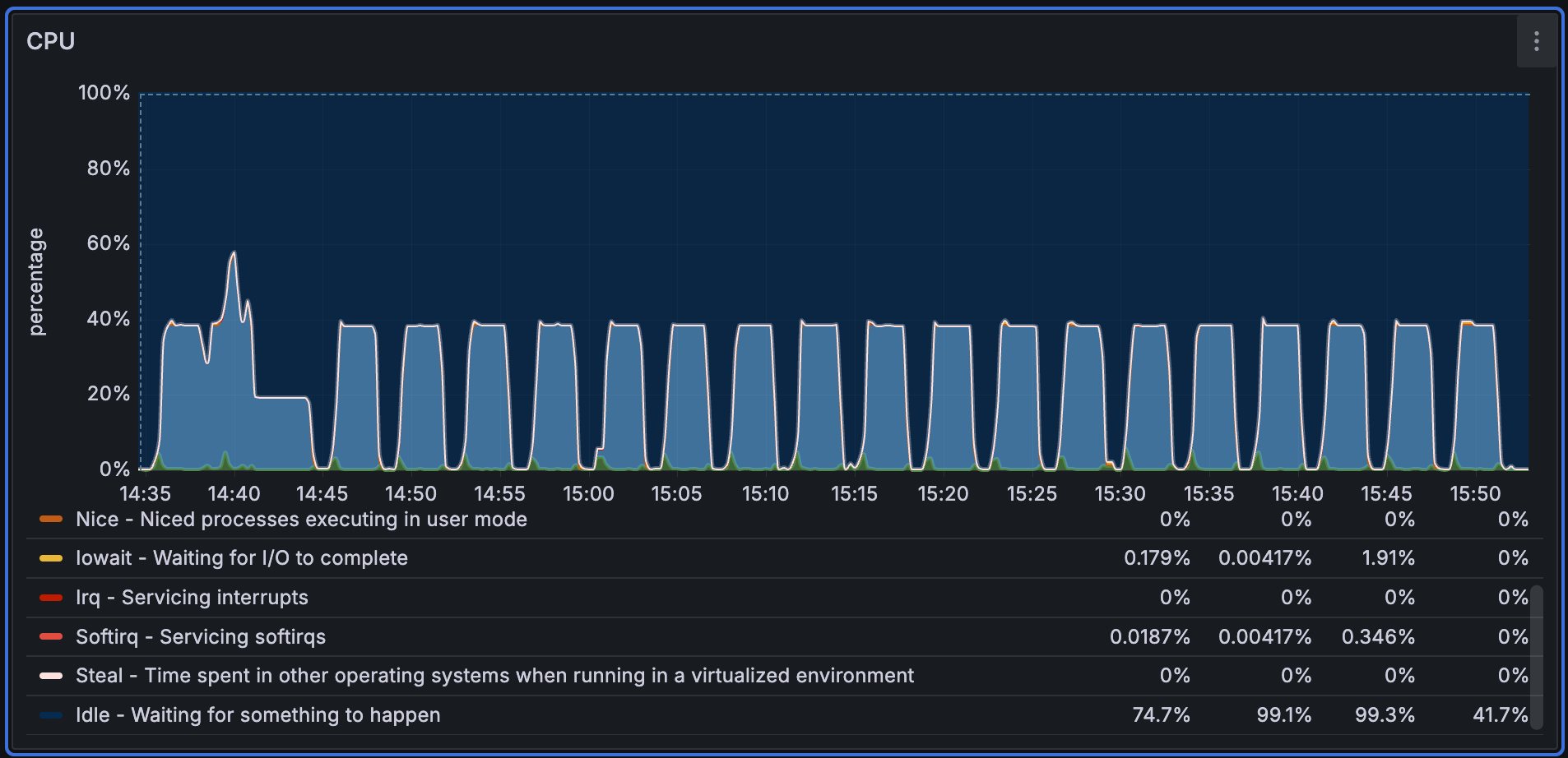
CPU utilization during import for Performance768D10M is shown below. The chart indicates that CPU usage remains relatively stable throughout ingestion.
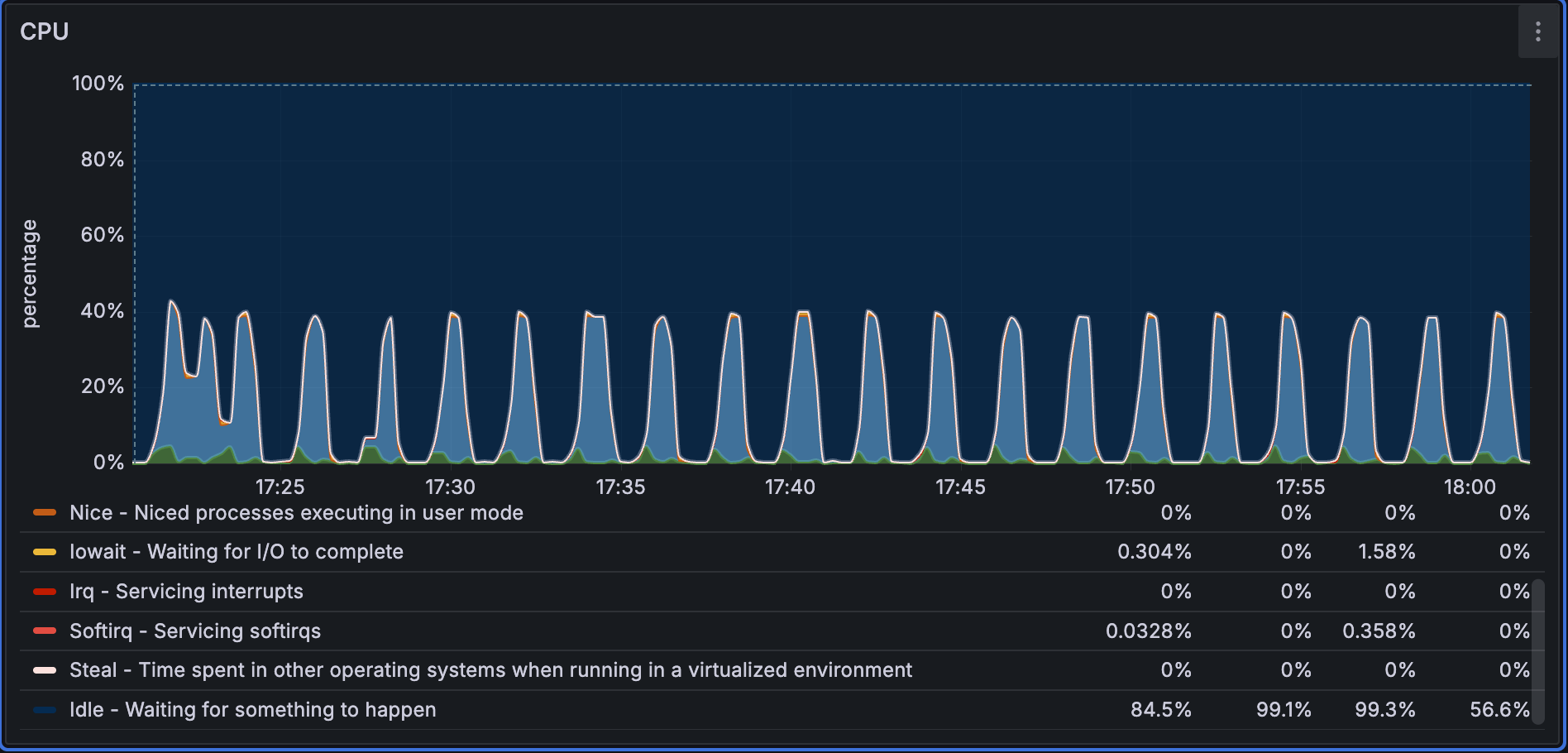
For Performance1536D5M, the dataset is smaller and the batch size is also smaller, so CPU utilization fluctuates more frequently during ingestion.
Query Performance
For the two single-node workloads, Doris reaches hundreds of QPS while maintaining high recall and low latency.
Summary
| Dataset | BestQPS | Recall@100 |
|---|---|---|
| Performance768D10M | 481.9356 | 0.9207 |
| Performance1536D5M | 414.7342 | 0.9677 |
Performance768D10M (inner_product, 10M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Avg Latency |
|---|---|---|---|---|
| 10 | 116.2000 | 0.0932 | 0.0933 | 0.0861 |
| 40 | 455.9485 | 0.1102 | 0.1225 | 0.0877 |
| 80 | 481.9356 | 0.2331 | 0.2674 | 0.1658 |
Performance1536D5M (inner_product, 5M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Avg Latency |
|---|---|---|---|---|
| 10 | 144.3221 | 0.0764 | 0.0800 | 0.0693 |
| 40 | 401.9732 | 0.1271 | 0.1404 | 0.0994 |
| 80 | 414.7342 | 0.2772 | 0.3222 | 0.1925 |
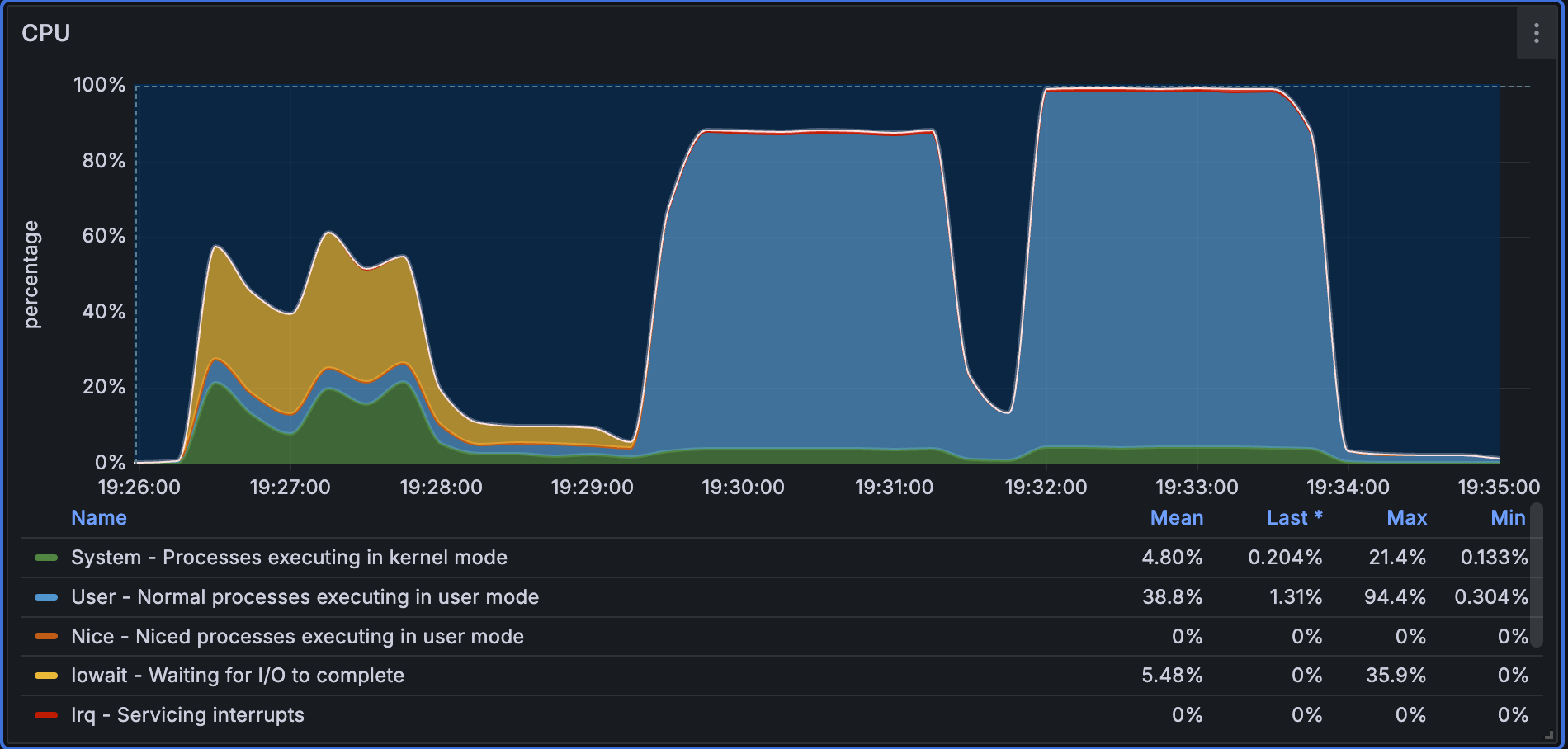
In the single-node query test, the cold-query phase needs to load the full index into memory, so CPU utilization is relatively low while the system waits for IO. During the warm-query phase, CPU utilization increases significantly and approaches 100%.
Distributed Benchmark (3 x 16C64GB)
The distributed test focuses on a larger dataset that exceeds the practical memory envelope of a single 16C64GB node.
For 3BE testing, Performance768D100M was selected. Since single-node memory is limited to 64GB, vector quantization is enabled to reduce memory usage. This test is intended to show how Doris sustains vector query capability at 100M scale through multi-BE deployment, rather than to provide a direct one-to-one comparison with the smaller single-node cases.
Import Performance
| Item | Value |
|---|---|
| Dataset | Performance768D100M |
| Rows | 100M |
| Dimension | 768 |
| Batch config | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 |
| Index properties | "dim"="768", "index_type"="hnsw", "metric_type"="l2_distance", "pq_m"="384", "pq_nbits"="8", "quantizer"="pq" |
| Build index time | 4h5min |
show data all | 198.809 GB (137.259 GB + 61.550 GB) |
Post-build distribution:
- 3 buckets
- 34 rowsets per bucket, each rowset about 1.99 GB
- 6 segments per rowset
Query Performance
Summary
| Metric | Value |
|---|---|
| BestQPS | 77.6247 |
| Recall@100 | 0.9294 |
Detailed results (l2_distance, 100M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Avg Latency |
|---|---|---|---|---|
| 10 | 46.5836 | 0.2628 | 0.2791 | 0.2145 |
| 20 | 75.3579 | 0.3251 | 0.3541 | 0.2651 |
| 30 | 77.6247 | 0.5222 | 0.5766 | 0.3860 |
| 40 | 76.6313 | 0.7089 | 0.7854 | 0.5212 |
During index build, CPU utilization stays around 50%, indicating that the build process does not saturate CPU resources for an extended period.
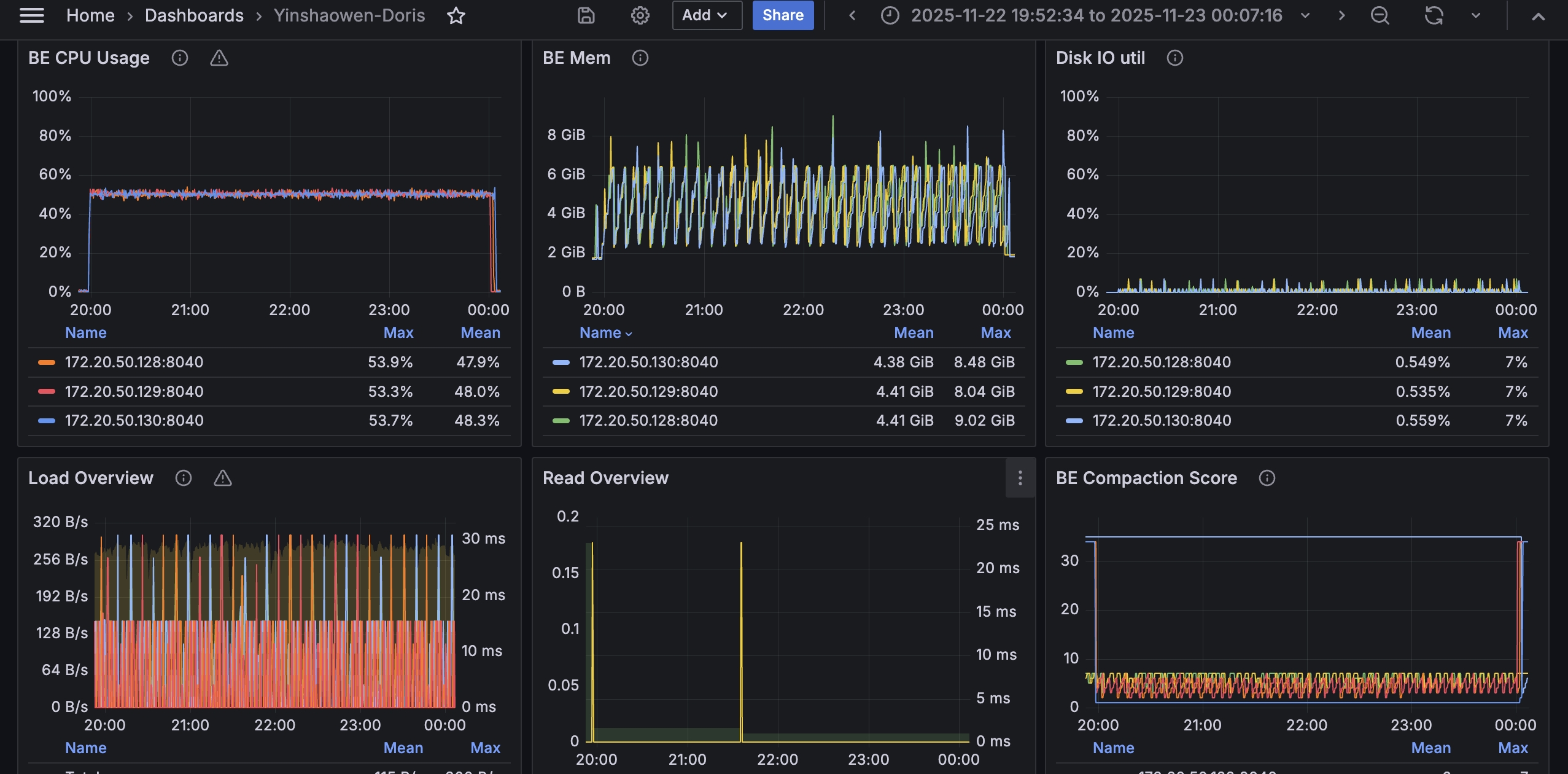
The chart below shows CPU utilization during the query phase. CPU usage stays at a relatively high level across the nodes, indicating that the distributed query workload makes good use of available compute resources.
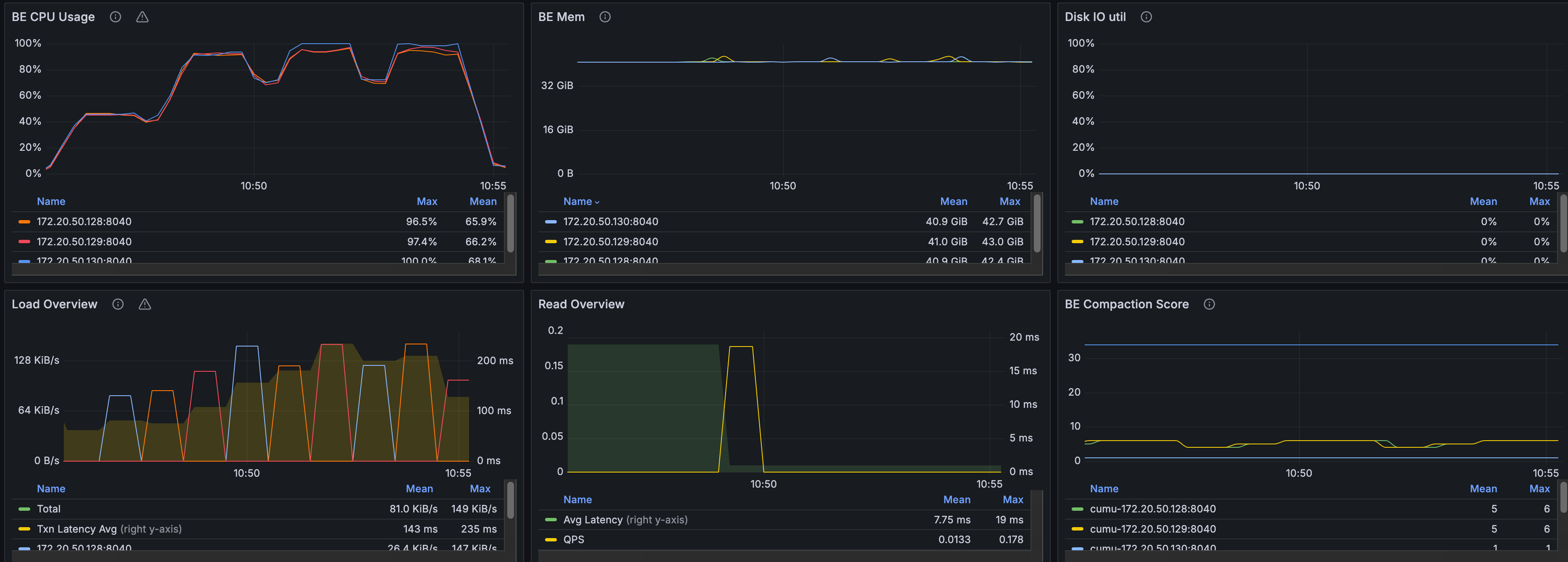
Summary
- On tens of millions of vectors, Doris provides strong ANN query performance on a single node, with hundreds of QPS and high recall.
- On a 100M-vector dataset, Doris continues to provide online vector query capability through multi-BE deployment.
- Because the test groups use different dataset sizes, distance metrics, and index settings, the results should be read as scale benchmarks rather than direct one-to-one performance comparisons.
Notes
- Metric types differ between the two test groups (
inner_productvsl2_distance), so absolute values should not be compared directly. - The single-node
Performance768D10Mresult at concurrency = 10 has been adjusted to exclude cold-query impact.
Reproduction
Single-node:
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D10M --stream-load-rows-per-batch 500000
export NUM_PER_BATCH=250000
vectordbbench doris ... --case-type Performance1536D5M --stream-load-rows-per-batch 250000
Distributed 3BE:
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D100M --stream-load-rows-per-batch 500000