
Overview
Overview
CCR (Cross Cluster Replication) is a cross-cluster data synchronization mechanism that synchronizes data changes from the source cluster to the target cluster at the database or table level. It is mainly used to enhance the data availability of online services, isolate read and write loads, and build a dual-site, three-center architecture. CCR currently does not support the separation of computing and storage modes.
Applicable Scenarios
CCR is suitable for the following common scenarios:
-
Disaster Recovery Backup: Backing up enterprise data to another cluster and data center to ensure data recovery in case of business interruption or data loss. Industries such as finance, healthcare, and e-commerce typically require this high SLA disaster recovery backup.
-
Read-Write Separation: By separating data query operations from write operations, the mutual impact between reads and writes is reduced, enhancing service stability. In scenarios with high concurrency or heavy write pressure, adopting read-write separation can effectively distribute the load and improve database performance and stability.
-
Data Centralization: The headquarters of a group needs to manage and analyze data from branch offices located in different regions to avoid management chaos and decision-making errors caused by data inconsistency, thereby improving group management efficiency and decision quality.
-
Isolated Upgrades: When upgrading system clusters, using CCR allows for validation and testing in the new cluster, avoiding rollback difficulties caused by version compatibility issues. Users can gradually upgrade each cluster while ensuring data consistency.
-
Cluster Migration: When relocating a Doris cluster or replacing equipment, using CCR can synchronize data from the old cluster to the new cluster, ensuring data consistency during the migration process.
Job Categories
CCR supports two types of jobs:
- Database-Level jobs: Synchronize data for the entire database.
- Table-Level jobs: Only synchronize data for specified tables. Note that table-level synchronization does not support renaming or replacing tables. Each database in Doris can only run one snapshot job at a time, so full synchronization jobs for table-level synchronization need to be queued.
Principles and Architecture
Terminology
- Source Cluster: The cluster where the data source resides, usually the cluster where business data is written.
- Target Cluster: The target cluster for cross-cluster synchronization.
- binlog: The change log of the source cluster, which includes schema and data changes.
- Syncer: A lightweight process responsible for synchronizing data.
- Upstream: Refers to the upstream database in database-level jobs and the upstream table in table-level jobs.
- Downstream: Refers to the downstream database in database-level jobs and the downstream table in table-level jobs.
Architecture Description
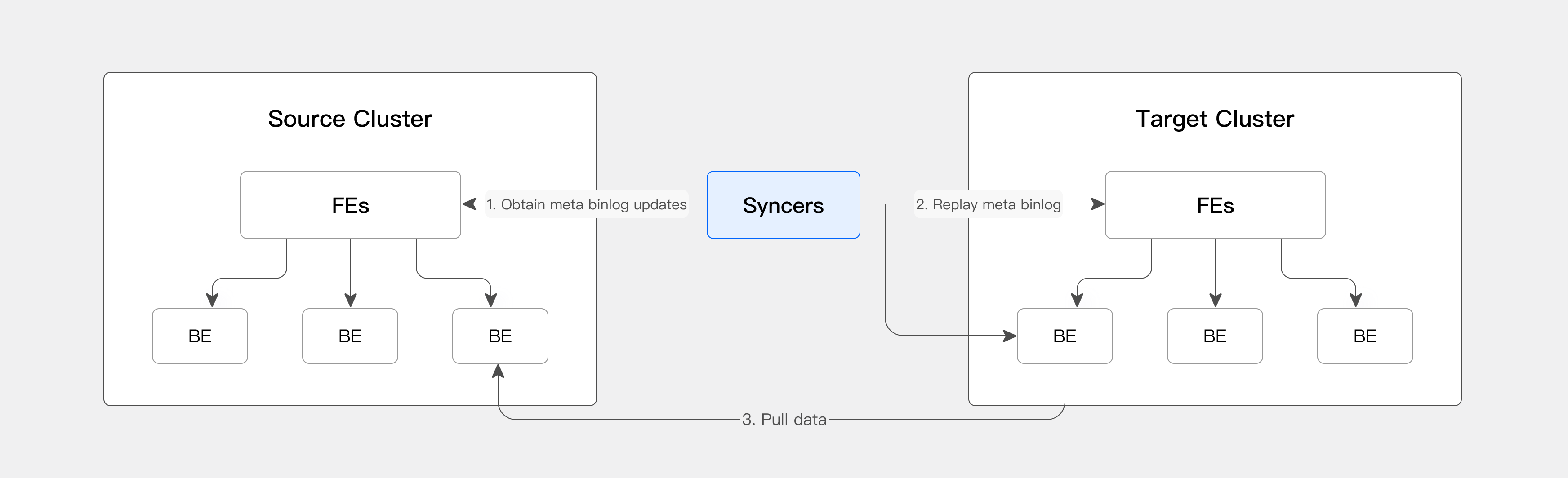
CCR mainly relies on a lightweight process: Syncer. The Syncer is responsible for obtaining binlogs from the source cluster and applying metadata to the target cluster, notifying the target cluster to pull data from the source cluster, thus achieving full synchronization and incremental synchronization.
Principles
-
Full Synchronization:
- CCR jobs will first perform full synchronization, copying the upstream data completely to the downstream.
-
Incremental Synchronization:
- After full synchronization is complete, CCR jobs will continue with incremental synchronization to maintain data consistency between upstream and downstream.
-
Restarting Full Synchronization:
- When encountering DDL operations that do not support incremental synchronization, CCR jobs will restart full synchronization. For specific DDL operations that do not support incremental synchronization, please refer to Feature Details.
- If the upstream binlog is interrupted due to expiration or other reasons, incremental synchronization will stop and restart full synchronization.
-
Restarting Full Synchronization:
- During full synchronization, incremental synchronization will be paused.
- After full synchronization is complete, the downstream data table will undergo atomic replacement to ensure data consistency.
- After full synchronization is complete, incremental synchronization will resume.
Synchronization Methods
CCR supports four synchronization methods:
| Synchronization Method | Principle | Trigger Timing |
|---|---|---|
| Full Sync | The upstream performs a full backup, and the downstream performs a restore. DB-level jobs trigger DB backups, and table-level jobs trigger table backups. | First synchronization or triggered by specific operations. For trigger conditions, please refer to Feature Details. |
| Partial Sync | The upstream performs table or partition-level backups, and the downstream performs table or partition-level restores. | Triggered by specific operations, for trigger conditions, please refer to Feature Details. |
| TXN | Incremental data synchronization, starting synchronization after the upstream commits. | Triggered by specific operations, for trigger conditions, please refer to Feature Details. |
| SQL | Replaying upstream SQL operations on the downstream. | Triggered by specific operations, for trigger conditions, please refer to Feature Details. |
Download
requirement: glibc >= 2.28
| Version | Arch | Tarball | SHA256 |
|---|---|---|---|
| 2.1 | ARM64 | ccr-syncer-2.1.10-rc07-arm64.tar.xz | 0620e71c59535546db194d83eccd1a08ffbdf3e6f7107a4f1734f013cc56a349 |
| 2.1 | X64 | ccr-syncer-2.1.10-rc07-x64.tar.xz | 783105dbd322451cd995ab327eca231654fec9db0ade899748c0d31fb1e00c40 |
| 3.0 | ARM64 | ccr-syncer-3.0.6-rc06-arm64.tar.xz | 97afaa6de13406dc32b7e8c46eb946ff41477baeb8865a702d1bef564c8c46e2 |
| 3.0 | X64 | ccr-syncer-3.0.6-rc06-x64.tar.xz | fcb8e63c309a1730bf592ebff2fbe0f713ffbf8624a8c6080627d691d9d472e1 |
| 4.0 | ARM64 | ccr-syncer-4.0.1-rc02-arm64.tar.xz | da8eee22b6bf174944dcf742618bebc809578e6427dd12c7634e96580891290f |
| 4.0 | X64 | ccr-syncer-4.0.1-rc02-x64.tar.xz | c87e7afe08e4b002badb92a6ce109c4cbd083f3a06ef0e54f8b4a606efee43b9 |