
Overview
This article introduces the differences, advantages, and applicable scenarios of the compute-storage coupled mode and compute-storage decoupled mode of Doris, providing a reference for users' selection.
The following sections will describe in detail how to deploy and use Apache Doris in the compute-storage decoupled mode. For information on deployment in compute-storage coupled mode, please refer to the Cluster Deployment section.
Compute-storage coupled VS decoupled
The overall architecture of Doris consists of two types of processes: Frontend (FE) and Backend (BE). The FE is primarily responsible for user request access, query parsing and planning, metadata management, and node management. The BE is responsible for data storage and query plan execution. (More information)
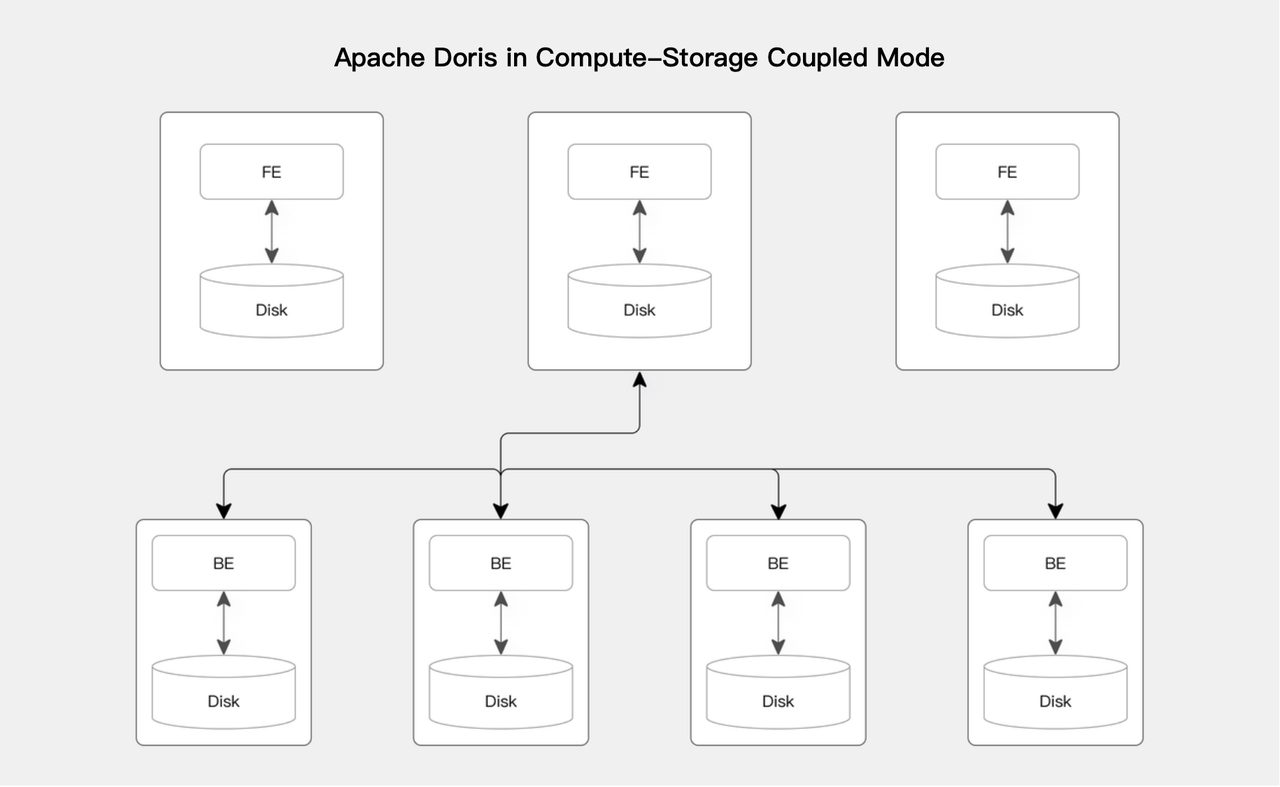
Compute-storage coupled
In the compute-storage coupled mode, the BE nodes perform both data storage and computation, and multiple BE nodes forms a massively parallel processing (MPP) distributed computing architecture.
Compute-storage decoupled
The BE nodes no longer store the primary data. Instead, the shared storage layer serves as the unified primary data storage. Additionally, to overcome the performance loss caused by the limitations of the underlying object storage system and the overhead of network transmission, Doris introduces a high-speed cache on the local compute nodes.
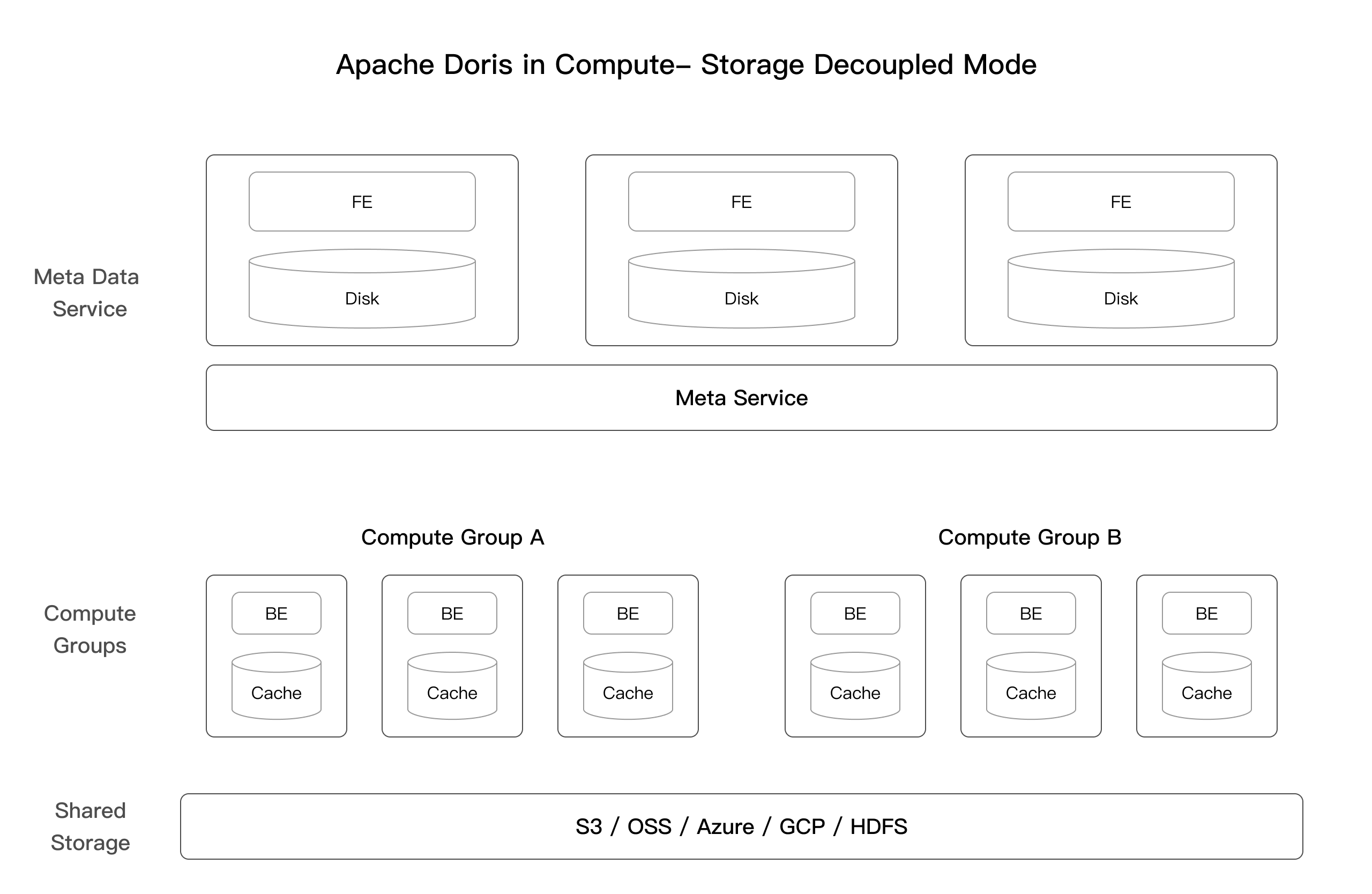
Meta data layer:
The FE stores metadata, job information, permissions, and other MySQL protocol-dependent data.
Meta Service is the Doris metadata service in the compute-storage decoupling mode. It is responsible for data import transaction processing, tablet meta, rowset meta, and cluster resource management. It is a stateless service that can scale horizontally.
Computation layer:
In the compute-storage decoupled mode, the BE nodes are stateless. They cache a portion of the tablet metadata and data to improve query performance.
A compute cluster is a collection of stateless BE nodes serving as the computing resources. Multiple compute clusters share a single set of data, and the compute clusters can be elastically scaled by adding or removing nodes as needed.
The concept of compute cluster in the compute-storage decoupled mode is distinct from the "cluster" discussed in the [Cluster Deployment] and [Create Cluster] sections.
In the context of the compute-storage decoupled mode, the "Compute Cluster" specifically refers to the collection of stateless BE nodes that serve as the computing resources, rather than the complete distributed system consisting of multiple Apache Doris nodes as described in the [Cluster Deployment] and [Create Cluster] sections.
Shared storage layer:
The shared storage layer stores the data files, including segment files and the inverted index files.
How to choose
Advantages of compute-storage coupled mode
- Simple deployment: Apache Doris does not depend on external shared file systems or object storage. It only requires the deployment of the FE and BE processes on physical servers to set up the cluster. The cluster can be scaled from a single node to hundreds of nodes. Such architecture also enhances system stability.
- High performance: When executing computations, the compute nodes in Apache Doris can directly access the local storage. This means it can fully utilize the machine I/O, and achieve higher query performance by reducing unnecessary network overhead.
Applicable scenarios of compute-storage coupled mode
- For simple usage or a quick trial of Doris, or for use in development and testing environments;
- When there is a lack of reliable shared storage options (HDFS, Ceph, or object storage, etc.);
- When different business teams in the company maintain Apache Doris independently, without dedicated DBA staff to manage the Doris cluster;
- When there is no requirement for high elastic scalability, no need for Kubernetes containerization, and no need to run on public or private clouds.
Advantages of compute-storage decoupled mode
- Elastic computing resources: Apache Doris allows using different scales of computing resources at different time points to serve different business requests. In simple terms, it supports on-demand computing resources to save costs.
- (Complete) isolation of workloads: Different business teams can have their computing resources isolated on top of shared data, providing both stability and high efficiency.
- Low storage costs: Decoupling computation and storage allows the use of object storage, HDFS, and other low-cost storage solutions.
Applicable scenarios of compute-storage decoupled mode
- When you have already adopted public cloud services;
- When you have reliable shared storage systems, such as HDFS, Ceph, and object storage;
- When you require high elastic scalability, Kubernetes containerization, or to run on a private cloud;
- High throughput shared storage capability, allowing multiple computing groups to share data
- When you have a dedicated team responsible for maintaining the company's entire data warehouse platform.