Stream Load
Stream Load supports importing local files or data streams into Doris over HTTP. Stream Load is a synchronous import method: it returns the import result after execution, so you can determine whether the import succeeded from the response. In general, you can use Stream Load to import files smaller than 10 GB. For larger files, split them first and then import each part with Stream Load. Stream Load guarantees the atomicity of a batch of import tasks: either all rows are imported successfully, or none are.
Compared with single-concurrency imports that use curl directly, the dedicated import tool Doris Streamloader is recommended. It is a dedicated client tool for importing data into Doris that provides multi-concurrency import capabilities and reduces the time required for large data volume imports. See the Doris Streamloader documentation for usage and practical details.
Use cases
Stream Load is suitable for the following typical scenarios:
- Importing local or remote CSV, JSON, Parquet, or ORC files into Doris.
- Continuously writing data through programs (Java, Go, Python, and so on) over HTTP streams.
- Cases that require atomicity of a single import job (all rows succeed or all fail).
- Single files that are typically smaller than 10 GB. For larger files, split them before importing or use Doris Streamloader.
When importing CSV files, distinguish clearly between null values and empty strings:
- Null value (null): represented by
\N. For example,a,\N,bmeans the middle column is null. - Empty string: when there are no characters between two delimiters, the value is an empty string. For example, in
a,,b, there are no characters between the two commas, so the middle column is an empty string.
Basic principles
When using Stream Load, an import job is initiated to an FE node over HTTP. The FE redirects the request in a round-robin manner to a BE node for load balancing. You can also send the HTTP request directly to a specific BE node. In Stream Load, Doris designates one node as the Coordinator. The Coordinator node is responsible for receiving data and distributing it to other nodes.
The following diagram shows the main flow of Stream Load:
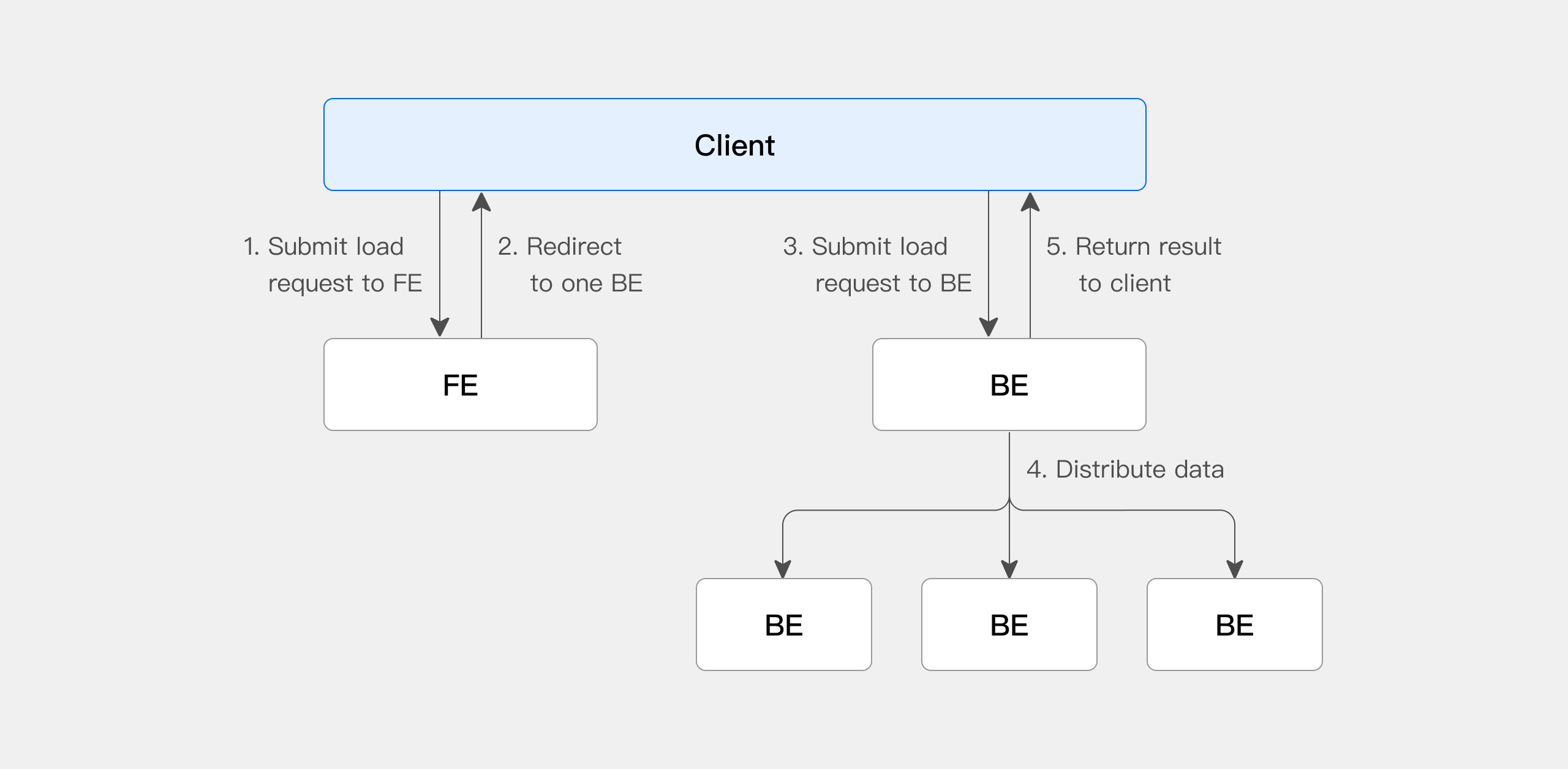
The execution flow is as follows:
- The Client submits a Stream Load import job request to the FE.
- The FE chooses a BE in round-robin order as the Coordinator node responsible for scheduling the import job, and returns an HTTP redirect to the Client.
- The Client connects to the Coordinator BE node and submits the import request.
- The Coordinator BE distributes data to the corresponding BE nodes. After the import completes, it returns the import result to the Client.
- The Client can also designate a BE node directly as the Coordinator and have it distribute the import job.
Quick start
Stream Load is submitted and transferred over HTTP. The following examples use the curl tool to demonstrate how to submit an import job through Stream Load.
Prerequisites
Stream Load requires INSERT privilege on the target table. If the user does not have INSERT privilege, grant it with the GRANT command.
Create an import job
Import CSV data
-
Create the import data
Create a CSV file
streamload_example.csvwith the following content:1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64 -
Create the target Doris table
Create the table to be imported in Doris with the following statement:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Start the import job
You can submit a Stream Load import job with the
curlcommand.curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_loadStream Load is a synchronous import method, and the import result is returned to the user directly.
{
"TxnId": 3,
"Label": "123",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 70,
"ReadDataTimeMs": 2,
"WriteDataTimeMs": 48,
"CommitAndPublishTimeMs": 52
} -
View the imported data
mysql> select count(*) from testdb.test_streamload;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
Import JSON data
-
Create the import data
Create a JSON file
streamload_example.jsonwith the following content:[
{"userid":1,"username":"Emily","userage":25},
{"userid":2,"username":"Benjamin","userage":35},
{"userid":3,"username":"Olivia","userage":28},
{"userid":4,"username":"Alexander","userage":60},
{"userid":5,"username":"Ava","userage":17},
{"userid":6,"username":"William","userage":69},
{"userid":7,"username":"Sophia","userage":32},
{"userid":8,"username":"James","userage":64},
{"userid":9,"username":"Emma","userage":37},
{"userid":10,"username":"Liam","userage":64}
] -
Create the target Doris table
Create the table to be imported in Doris with the following statement:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Start the import job
You can submit a Stream Load import job with the
curlcommand.curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:124" \
-H "Expect:100-continue" \
-H "format:json" -H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_loadNoteIf the JSON file content is not a JSON array but one JSON object per line, add the headers
-H "strip_outer_array:false"and-H "read_json_by_line:true". To import the JSON object at the root node of the JSON file, setjsonpathsto$., for example:-H "jsonpaths:[\"$.\"]".Stream Load is a synchronous import method, and the import result is returned to the user directly.
{
"TxnId": 7,
"Label": "125",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 471,
"LoadTimeMs": 52,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 11,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 23,
"CommitAndPublishTimeMs": 16
}
View import jobs
By default, Stream Load returns synchronously to the Client, so the system does not record Stream Load history jobs. To enable recording, add the configuration enable_stream_load_record=true in be.conf. For details, see BE configuration.
After this is configured, you can view completed Stream Load tasks with the show stream load command.
mysql> show stream load from testdb;
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| Label | Db | Table | ClientIp | Status | Message | Url | TotalRows | LoadedRows | FilteredRows | UnselectedRows | LoadBytes | StartTime | FinishTime | User | Comment |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
| 12356 | testdb | test_streamload | 192.168.88.31 | Success | OK | N/A | 10 | 10 | 0 | 0 | 118 | 2023-11-29 08:53:00.594 | 2023-11-29 08:53:00.650 | root | |
+-------+--------+-----------------+---------------+---------+---------+------+-----------+------------+--------------+----------------+-----------+-------------------------+-------------------------+------+---------+
1 row in set (0.00 sec)
Cancel an import job
Users cannot manually cancel a Stream Load. Stream Load is automatically canceled by the system when it times out or encounters an import error.
Bind a Compute Group
You can specify the Compute Group on which Stream Load runs.
Storage-compute separation mode
In storage-compute separation mode, you can specify the Compute Group as follows:
-
Specify it through an HTTP Header parameter.
-H "cloud_cluster:cluster1"Starting from Doris 4.0.0, you can also use the
compute_groupparameter:-H "compute_group:cluster1" -
Specify the Compute Group in the user properties bound to the Stream Load. If both the user property and the HTTP Header specify a Compute Group, the one specified in the Header takes precedence.
set property for user1 'default_compute_group'='cluster1'; -
If neither the user properties nor the HTTP Header specifies a Compute Group, one is selected from the Compute Groups that the user bound to the Stream Load has access to. If the user has no accessible Compute Group, the import fails.
Storage-compute integrated mode
In storage-compute integrated mode, only the user properties bound to the Stream Load can be used to specify the Compute Group. If no Compute Group is specified in the user properties, the Compute Group named default is selected.
set property for user1 'resource_tags.location'='group_1';
Reference
Import command
The Stream Load import syntax is as follows:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" [-H ""...] \
-T <file_path> \
-XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Stream Load supports both HTTP chunked import and HTTP non-chunked import. For non-chunked imports, Content-Length must be specified to indicate the length of the uploaded content, which guarantees the integrity of the data.
Import configuration parameters
FE configuration
1. stream_load_default_timeout_second
| Item | Description |
|---|---|
| Default value | 259200 (s) |
| Dynamic configuration | Yes |
| FE Master-only configuration | Yes |
Description: The default timeout for Stream Load. The timeout for an import task (in seconds). If the import task does not complete within the configured timeout, the system cancels it and the task becomes CANCELLED. If the source file cannot be imported within the specified time, you can set a separate timeout in the Stream Load request, or adjust the FE parameter stream_load_default_timeout_second to set the global default timeout.
BE configuration
1. streaming_load_max_mb
| Item | Description |
|---|---|
| Default value | 10240 (MB) |
| Dynamic configuration | Yes |
Description: The maximum import size for Stream Load. If the user's source file exceeds this value, adjust the BE parameter streaming_load_max_mb.
Header parameters
Import parameters can be passed through the HTTP Header. The parameters are described as follows:
| Tag | Parameter description |
|---|---|
| label | Specifies the label for this import. Data with the same label cannot be imported more than once. If no label is specified, Doris generates one automatically. By specifying a label, you avoid duplicate imports of the same data. By default, Doris keeps import job labels for three days; you can adjust the retention period with label_keep_max_second. For example, to specify the label 123 for this import, use the command -H "label:123". Using labels prevents duplicate imports of the same data. It is strongly recommended that the same batch of data uses the same label so that duplicate requests for the same batch are accepted only once, ensuring At-Most-Once semantics. When the import job for a label is in CANCELLED state, the label can be used again. |
| column_separator | Specifies the column separator in the import file. The default is \t. For invisible characters, use \x as a prefix and represent the separator in hexadecimal. A combination of multiple characters can also be used as the column separator. For example, the Hive file separator \x01 is specified with the command -H "column_separator:\x01". |
| line_delimiter | Specifies the line delimiter in the import file. The default is \n. A combination of multiple characters can also be used as the line delimiter. For example, to specify \n as the line delimiter, use the command -H "line_delimiter:\n". |
| columns | Specifies the mapping between the columns in the import file and the columns in the table. If the columns in the source file correspond exactly to the columns in the table, this field does not need to be specified. If the source file does not correspond to the table schema, this field is needed for some data conversion. There are two forms of column: directly corresponding to the field in the import file, using the field name directly; or representing a derived column, with the syntax column_name = expression. For detailed examples, see Data conversion during import. |
| where | Used to extract part of the data. If you want to filter out unneeded data, use this option. For example, to import only data where column k1 equals 20180601, specify -H "where: k1 = 20180601" during import. |
| max_filter_ratio | The maximum tolerable ratio of data that can be filtered out (for example, due to data not being well-formed). The default is zero tolerance. The value range is 0 to 1. If the import error rate exceeds this value, the import fails. Rows that are filtered out by the where condition are not counted as malformed data. For example, to maximize the import of all correct data (100% tolerance), specify the command -H "max_filter_ratio:1". |
| partitions | Specifies the partitions involved in this import. If you can determine the partitions to which the data corresponds, it is recommended to specify this option. Data that does not satisfy these partitions is filtered out. For example, to import to partitions p1 and p2, specify the command -H "partitions: p1, p2". |
| timeout | Specifies the import timeout in seconds. The default is 600 seconds. The valid range is 1 second to 259200 seconds. For example, to set the import timeout to 1200 s, specify the command -H "timeout:1200". |
| strict_mode | Specifies whether to enable strict mode for this import. It is disabled by default. For example, to enable strict mode, specify the command -H "strict_mode:true". |
| timezone | Specifies the time zone used for this import. The default is the current time zone of the cluster. This parameter affects the results of all time-zone-related functions involved in the import. For example, to set the import time zone to Africa/Abidjan, specify the command -H "timezone:Africa/Abidjan". |
| exec_mem_limit | The import memory limit. The default is 2 GB. The unit is bytes. |
| format | Specifies the data format for this import. The default is CSV. The following formats are currently supported: CSV, JSON, arrow, csv_with_names (supports filtering out the first row of the CSV file), csv_with_names_and_types (supports filtering out the first two rows of the CSV file), Parquet, and ORC. For example, to specify the import data format as JSON, use the command -H "format:json". |
| jsonpaths | There are two ways to import JSON data: simple mode, used when jsonpaths is not specified, which requires the JSON data to be of object type; and matching mode, used when JSON data is relatively complex and the corresponding values must be matched through the jsonpaths parameter. In simple mode, the keys in the JSON must correspond one-to-one with the column names in the table. For example, the JSON data {"k1":1, "k2":2, "k3":"hello"} requires k1, k2, and k3 to correspond to columns in the table. |
| strip_outer_array | When strip_outer_array is set to true, the JSON data starts with an array object and the array is flattened. The default is false. When the outermost layer of the JSON data is an array represented by [], set strip_outer_array to true. For example, with the data [{"k1" : 1, "v1" : 2},{"k1" : 3, "v1" : 4}], after strip_outer_array is set to true, two rows are generated when imported into Doris. |
| json_root | json_root is a valid jsonpath string that specifies the root node of the JSON document. The default value is "". |
| merge_type | The merge type for the data. Three types are supported: - APPEND (default): all data in this batch is appended to the existing data. - DELETE: deletes all rows whose keys match those in this batch. - MERGE: must be used together with a delete condition. Data that matches the delete condition is processed with DELETE semantics, and the rest is processed with APPEND semantics.For example, to specify MERGE mode: -H "merge_type: MERGE" -H "delete: flag=1". |
| delete | Only meaningful with MERGE; specifies the deletion condition for the data. |
| function_column.sequence_col | Applies only to the UNIQUE KEYS model. Within the same key columns, ensures that the value column is REPLACE'd in the order of the source_sequence column. source_sequence can be a column in the data source or a column in the table schema. |
| fuzzy_parse | Boolean. When set to true, JSON is parsed using the first row as the schema. Enabling this option can improve the efficiency of JSON imports, but it requires that the order of the keys in all JSON objects is the same as that in the first row. The default is false. Used only for the JSON format. |
| num_as_string | Boolean. When set to true, numeric types are converted to strings when parsing JSON data, ensuring that the import is performed without precision loss. |
| read_json_by_line | Boolean. When set to true, supports reading one JSON object per line. The default value is false. |
| send_batch_parallelism | Integer. Sets the parallelism for sending batch data. If the value of the parallelism exceeds the BE configuration max_send_batch_parallelism_per_job, the BE acting as the coordinator uses the value of max_send_batch_parallelism_per_job. |
| hidden_columns | Specifies the hidden columns included in the import data. Effective when Columns is not included in the Header. Multiple hidden columns are separated by commas. The system imports the data using the data specified by the user. In the example below, the last column in the import data is __DORIS_SEQUENCE_COL__. hidden_columns: __DORIS_DELETE_SIGN__,__DORIS_SEQUENCE_COL__ |
| load_to_single_tablet | Boolean. When set to true, supports loading the data of a single task into only one tablet of the corresponding partition. The default value is false. This parameter can be set only when loading data into an OLAP table with random bucketing. |
| compress_type | Specifies the compression format of the file. Currently, only CSV file compression is supported. The supported compression formats are gz, lzo, bz2, lz4, lzop, and deflate. |
| trim_double_quotes | Boolean. The default value is false. When set to true, trims the outermost double quotes of every field in the CSV file. |
| skip_lines | Integer. The default value is 0. Skips the first several lines of the CSV file. This parameter is invalid when format is set to csv_with_names or csv_with_names_and_types. |
| comment | String. The default value is empty. Adds extra information to the task. |
| enclose | Specifies the enclosing character. When the CSV data fields contain line or column separators, you can specify a single-byte character as the enclosing character to prevent unintended truncation. For example, with the column separator , and the enclosing character ', given the data "a,'b,c'", then b,c is parsed as one field. Note: when enclose is set to ", trim_double_quotes must be set to true. |
| escape | Specifies the escape character. Used to escape characters in fields that are the same as the enclosing character. For example, with the data "a,'b,'c'" and the enclosing character ', to parse b,'c as one field, specify a single-byte escape character such as \\ and modify the data to "a,'b,\\'c'". |
| memtable_on_sink_node | Whether to enable MemTable forward when importing data. The default is false. |
| unique_key_update_mode | The update mode on a Unique table. Currently effective only for Merge-On-Write Unique tables. Three types are supported: UPSERT, UPDATE_FIXED_COLUMNS, and UPDATE_FLEXIBLE_COLUMNS. UPSERT: imports data with upsert semantics. UPDATE_FIXED_COLUMNS: imports data using partial column update. UPDATE_FLEXIBLE_COLUMNS: imports data using flexible partial column update. |
| partial_update_new_key_behavior | The way newly inserted rows are handled when performing partial column updates or flexible column updates on a Unique table. Two types are available: APPEND and ERROR.- APPEND: allows new rows to be inserted.- ERROR: import fails and reports an error when inserting a new row. |
Import return value
Stream Load is a synchronous import method, and the import result is returned to the user through the response of the import request, as shown below:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}
The return result parameters are described in the following table:
| Parameter name | Description |
|---|---|
| TxnId | The ID of the import transaction. |
| Label | The label of the import job, specified by -H "label:<label_id>". |
| Status | The final status of the import: - Success: the import succeeded. - Publish Timeout: the import is complete, but the data may be visible with delay; no retry is needed. - Label Already Exists: the label is duplicated; a new label is needed. - Fail: the import failed. |
| ExistingJobStatus | The status of the existing import job corresponding to the label. This field is shown only when Status is Label Already Exists. With this status, you can find the status of the import job for the existing label. RUNNING means the job is still running; FINISHED means the job succeeded. |
| Message | The import error message. |
| NumberTotalRows | The total number of rows processed by the import. |
| NumberLoadedRows | The number of rows successfully imported. |
| NumberFilteredRows | The number of rows that did not pass data quality checks. |
| NumberUnselectedRows | The number of rows filtered out by the where condition. |
| LoadBytes | The number of bytes imported. |
| LoadTimeMs | The import completion time, in milliseconds. |
| BeginTxnTimeMs | The time spent requesting the FE to start a transaction, in milliseconds. |
| StreamLoadPutTimeMs | The time spent requesting the FE to obtain the import data execution plan, in milliseconds. |
| ReadDataTimeMs | The time spent reading data, in milliseconds. |
| WriteDataTimeMs | The time spent performing the data write, in milliseconds. |
| CommitAndPublishTimeMs | The time spent requesting the FE to commit and publish the transaction, in milliseconds. |
| ErrorURL | If there are data quality issues, view the specific error rows by visiting this URL. |
You can use ErrorURL to view import data that failed because of poor data quality. Use the command curl "<ErrorURL>" to view the error data information directly.
Import examples
Set the import timeout and maximum import size
The import task timeout (in seconds). If the import task does not complete within the configured timeout, the system cancels it and the task becomes CANCELLED. You can adjust the Stream Load import timeout by specifying the timeout parameter or by adding the parameter stream_load_default_timeout_second in fe.conf.
Before importing, calculate the import timeout based on the file size. For example, for a 100 GB file, with an estimated import speed of 50 MB/s:
Import time ~= 100GB / 50MB/s ~= 2048s
The following command creates a Stream Load import task with timeout set to 3000 s:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "timeout:3000" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Set the maximum tolerated error ratio
Doris import tasks can tolerate a portion of malformed data. The tolerance ratio is set by max_filter_ratio. The default is 0, which means that if a single row of incorrect data exists, the entire import task fails. If you want to ignore some problematic data rows, set this parameter to a value between 0 and 1, and Doris automatically skips rows whose data format is incorrect. For details on how the tolerance ratio is calculated, see the Data conversion documentation.
The following command creates a Stream Load import task with max_filter_ratio set to 0.4:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.4" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Set import filter conditions
During the import, you can use the WHERE parameter to filter the imported data conditionally. Filtered-out data is not counted in the filter ratio calculation and does not affect the max_filter_ratio setting. After the import is complete, you can find the number of filtered rows in num_rows_unselected.
The following command creates a Stream Load import task with a WHERE filter condition:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "where:age>=35" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import data into specified partitions
Import data from a local file into partitions p1 and p2 of the table, allowing a 20% error rate.
curl --location-trusted -u <doris_user>:<doris_password> \
-H "label:123" \
-H "Expect:100-continue" \
-H "max_filter_ratio:0.2" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-H "partitions: p1, p2" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Specify the import time zone
The DATETIME-related types represent only absolute points in time and do not contain time-zone information; they do not change with the Doris system time zone. Therefore, time-zone-aware data is handled in a unified way during import: it is converted to data in a specified target time zone. In the Doris system, the time zone is the one represented by the session variable time_zone.
In imports, the target time zone is specified by the timezone parameter. This variable replaces the session variable time_zone when time-zone conversions occur and when time-zone-sensitive functions are evaluated. Therefore, unless there are special circumstances, the timezone setting in the import transaction should match the current Doris cluster's time_zone. This means all time data with time zones is converted to that time zone.
For example, if the Doris system time zone is +08:00 and the time column in the import data contains two rows, 2012-01-01 01:00:00+00:00 and 2015-12-12 12:12:12-08:00, then specifying -H "timezone: +08:00" for the import transaction converts both rows to that time zone, producing 2012-01-01 09:00:00 and 2015-12-13 04:12:12.
For more information about time zones, see the Time zone documentation.
Import using streaming
Stream Load is based on the HTTP protocol, so it supports programs such as Java, Go, and Python writing data to it as a stream. This is why it is named Stream Load.
The following uses a bash pipeline command to demonstrate this usage; the imported data is generated by a program rather than from a local file.
seq 1 10 | awk '{OFS="\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load
Skip the first line of a CSV during import
File data:
id,name,age
1,doris,20
2,flink,10
Skip the first line during import by specifying format=csv_with_names:
curl --location-trusted -u root -T test.csv -H "label:1" -H "format:csv_with_names" -H "column_separator:," http://host:port/api/testDb/testTbl/_stream_load
Use merge_type to perform a Delete operation
There are three import types in Stream Load: APPEND, DELETE, and MERGE. They can be adjusted by specifying the merge_type parameter. To delete all rows whose keys match the import data, use the following command:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
If the data in the table before the import is:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 3 | 2 | tom | 2 |
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
The import data is:
3,2,tom,0
After the import, the matching row is deleted from the table, and the result set becomes:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
Use merge_type to perform a Merge operation
Setting merge_type to MERGE merges the imported data into the table. MERGE semantics must be used together with a DELETE condition. Rows that match the DELETE condition are processed with DELETE semantics, and the rest are appended to the table with APPEND semantics. For example, the following operation deletes the row whose siteid is 1, and adds the rest of the data to the table:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: MERGE" \
-H "delete: siteid=1" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
If the data before the import is:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 5 | 3 | helen | 3 |
| 1 | 1 | jim | 2 |
+--------+----------+----------+------+
The import data is:
2,1,grace,2
3,2,tom,2
1,1,jim,2
After the import, the row with siteid = 1 is deleted, and the rows with siteid 2 and 3 are added to the table:
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 4 | 3 | bush | 3 |
| 2 | 1 | grace | 2 |
| 3 | 2 | tom | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
Specify the Sequence column for Merge during import
When a Sequence column is set on a Unique Key table, within the same key columns the Sequence column value is used as the basis for the order in which the REPLACE aggregation function performs replacement; a larger value can replace a smaller value. When marking deletions on this kind of table based on DORIS_DELETE_SIGN, you must ensure the same key and that the Sequence column value is greater than or equal to the current value. By specifying the function_column.sequence_col parameter together with merge_type: DELETE, you can perform a delete operation:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "merge_type: DELETE" \
-H "function_column.sequence_col: age" \
-H "column_separator:," \
-H "columns: name, gender, age" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Suppose the table has the following structure:
mysql> SET show_hidden_columns=true;
Query OK, 0 rows affected (0.00 sec)
mysql> DESC table1;
+------------------------+--------------+------+-------+---------+---------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+--------------+------+-------+---------+---------+
| name | VARCHAR(100) | No | true | NULL | |
| gender | VARCHAR(10) | Yes | false | NULL | REPLACE |
| age | INT | Yes | false | NULL | REPLACE |
| __DORIS_DELETE_SIGN__ | TINYINT | No | false | 0 | REPLACE |
| __DORIS_SEQUENCE_COL__ | INT | Yes | false | NULL | REPLACE |
+------------------------+--------------+------+-------+---------+---------+
4 rows in set (0.00 sec)
Suppose the data in the original table is:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
1. Sequence parameter takes effect: the imported Sequence column is greater than or equal to the existing value in the table
The import data is:
li,male,10
Because function_column.sequence_col: age is specified and age is greater than or equal to the existing column value in the table, the original row is deleted, and the data in the table becomes:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
2. Sequence parameter does not take effect: the imported Sequence column is less than or equal to the existing value in the table
The import data is:
li,male,9
Because function_column.sequence_col: age is specified but age is less than the existing column value in the table, the DELETE operation does not take effect; the data in the table remains unchanged, and the row with primary key li is still visible:
+-------+--------+------+
| name | gender | age |
+-------+--------+------+
| li | male | 10 |
| wang | male | 14 |
| zhang | male | 12 |
+-------+--------+------+
The row is not deleted because, at the underlying dependency level, the system first checks rows with the same key, externally exposes the row with the larger Sequence column value, and then checks whether the DORIS_DELETE_SIGN value of that row is 1. If it is 1, it is hidden externally; if it is 0, it is still readable.
Import data containing enclosing characters
When CSV data contains separators or column separators, you can specify a single-byte character as the enclosing character to prevent truncation.
In the following data, the column contains the separator ,:
Zhang San,30,'Shanghai City, Huangpu District, Dagu Road'
By specifying the enclosing character ', "Shanghai City, Huangpu District, Dagu Road" can be specified as a single field:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
If the enclosing character also appears in the field, for example, to treat "Shanghai City, Huangpu District, 'Dagu Road" as one field, escape the character in the column first:
Zhang San,30,'Shanghai City, Huangpu District, \'Dagu Road'
The escape parameter can be used to specify a single-byte escape character, such as \ in the example below:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:," \
-H "enclose:'" \
-H "escape:\\" \
-H "columns:username,age,address" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import data into a table with DEFAULT CURRENT_TIMESTAMP fields
The following example imports data into a table whose fields contain DEFAULT CURRENT_TIMESTAMP.
Table schema:
CREATE TABLE testDb.testTbl (
`id` BIGINT(30) NOT NULL,
`order_code` VARCHAR(30) DEFAULT NULL COMMENT '',
`create_time` DATETIMEv2(3) DEFAULT CURRENT_TIMESTAMP
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;
JSON data format:
{"id":1,"order_Code":"avc"}
Import command:
curl --location-trusted -u root -T test.json -H "label:1" -H "format:json" -H 'columns: id, order_code, create_time=CURRENT_TIMESTAMP()' http://host:port/api/testDb/testTbl/_stream_load
Import JSON data in simple mode
When the JSON fields correspond one-to-one with the column names in the table, you can import JSON data into the table by specifying "strip_outer_array:true" and "format:json".
For example, the table is defined as:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
The field names in the import data correspond one-to-one with the field names in the table:
[
{"user_id":1,"name":"Emily","age":25},
{"user_id":2,"name":"Benjamin","age":35},
{"user_id":3,"name":"Olivia","age":28},
{"user_id":4,"name":"Alexander","age":60},
{"user_id":5,"name":"Ava","age":17},
{"user_id":6,"name":"William","age":69},
{"user_id":7,"name":"Sophia","age":32},
{"user_id":8,"name":"James","age":64},
{"user_id":9,"name":"Emma","age":37},
{"user_id":10,"name":"Liam","age":64}
]
You can import the JSON data into the table with the following command:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import complex JSON data in matching mode
When JSON data is complex and cannot correspond one-to-one with the column names in the table, or when there are extra columns, you can specify the jsonpaths parameter to perform column name mapping for matching imports. For example, given the following data:
[
{"userid":1,"hudi":"lala","username":"Emily","userage":25,"userhp":101},
{"userid":2,"hudi":"kpkp","username":"Benjamin","userage":35,"userhp":102},
{"userid":3,"hudi":"ji","username":"Olivia","userage":28,"userhp":103},
{"userid":4,"hudi":"popo","username":"Alexander","userage":60,"userhp":103},
{"userid":5,"hudi":"uio","username":"Ava","userage":17,"userhp":104},
{"userid":6,"hudi":"lkj","username":"William","userage":69,"userhp":105},
{"userid":7,"hudi":"komf","username":"Sophia","userage":32,"userhp":106},
{"userid":8,"hudi":"mki","username":"James","userage":64,"userhp":107},
{"userid":9,"hudi":"hjk","username":"Emma","userage":37,"userhp":108},
{"userid":10,"hudi":"hua","username":"Liam","userage":64,"userhp":109}
]
By specifying the jsonpaths parameter, you can match the specified columns:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Specify the JSON root node for import
If the JSON data contains nested JSON fields, you must specify the root node of the JSON to import. The default value is "".
For the following data, the goal is to import the data inside the comment column into the table:
[
{"user":1,"comment":{"userid":101,"username":"Emily","userage":25}},
{"user":2,"comment":{"userid":102,"username":"Benjamin","userage":35}},
{"user":3,"comment":{"userid":103,"username":"Olivia","userage":28}},
{"user":4,"comment":{"userid":104,"username":"Alexander","userage":60}},
{"user":5,"comment":{"userid":105,"username":"Ava","userage":17}},
{"user":6,"comment":{"userid":106,"username":"William","userage":69}},
{"user":7,"comment":{"userid":107,"username":"Sophia","userage":32}},
{"user":8,"comment":{"userid":108,"username":"James","userage":64}},
{"user":9,"comment":{"userid":109,"username":"Emma","userage":37}},
{"user":10,"comment":{"userid":110,"username":"Liam","userage":64}}
]
First, use the json_root parameter to set the root node to comment, and then use the jsonpaths parameter to complete the column name mapping:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format:json" \
-H "strip_outer_array:true" \
-H "json_root: $.comment" \
-H "jsonpaths:[\"$.userid\", \"$.username\", \"$.userage\"]" \
-H "columns:user_id,name,age" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import Array data type
The following data contains an array type:
1|Emily|[1,2,3,4]
2|Benjamin|[22,45,90,12]
3|Olivia|[23,16,19,16]
4|Alexander|[123,234,456]
5|Ava|[12,15,789]
6|William|[57,68,97]
7|Sophia|[46,47,49]
8|James|[110,127,128]
9|Emma|[19,18,123,446]
10|Liam|[89,87,96,12]
Import the data into the following table schema:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NOT NULL COMMENT "ID",
name VARCHAR(20) NULL COMMENT "name",
arr ARRAY<int(10)> NULL COMMENT "array"
)
DUPLICATE KEY(typ_id)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
With a Stream Load task, you can import the ARRAY type from a text file directly into the table:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "column_separator:|" \
-H "columns:typ_id,name,arr" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import Map data type
When the import data contains a Map type, as in the following example:
[
{"user_id":1,"namemap":{"Emily":101,"age":25}},
{"user_id":2,"namemap":{"Benjamin":102,"age":35}},
{"user_id":3,"namemap":{"Olivia":103,"age":28}},
{"user_id":4,"namemap":{"Alexander":104,"age":60}},
{"user_id":5,"namemap":{"Ava":105,"age":17}},
{"user_id":6,"namemap":{"William":106,"age":69}},
{"user_id":7,"namemap":{"Sophia":107,"age":32}},
{"user_id":8,"namemap":{"James":108,"age":64}},
{"user_id":9,"namemap":{"Emma":109,"age":37}},
{"user_id":10,"namemap":{"Liam":110,"age":64}}
]
Import the data into the following table schema:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "ID",
namemap Map<STRING, INT> NULL COMMENT "namemap"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
With a Stream Load task, you can import the Map type from a text file directly into the table:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "format: json" \
-H "strip_outer_array:true" \
-T streamload_example.json \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import Bitmap data type
During import, when Bitmap-type data is encountered, you can use to_bitmap to convert the data into Bitmap, or use the bitmap_empty function to populate a Bitmap.
For example, the import data is:
1|koga|17723
2|nijg|146285
3|lojn|347890
4|lofn|489871
5|jfin|545679
6|kon|676724
7|nhga|767689
8|nfubg|879878
9|huang|969798
10|buag|97997
Import the data into the following table that contains a Bitmap type:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
hou VARCHAR(10) NULL COMMENT "one",
arr BITMAP BITMAP_UNION NOT NULL COMMENT "two"
)
AGGREGATE KEY(typ_id,hou)
DISTRIBUTED BY HASH(typ_id,hou) BUCKETS 10;
You can use to_bitmap to convert the data into the Bitmap type:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "Expect:100-continue" \
-H "columns:typ_id,hou,arr,arr=to_bitmap(arr)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Import HLL data type
You can use the hll_hash function to convert data into the HLL type. Given the following data:
1001|koga
1002|nijg
1003|lojn
1004|lofn
1005|jfin
1006|kon
1007|nhga
1008|nfubg
1009|huang
1010|buag
Import it into the following table:
CREATE TABLE testdb.test_streamload(
typ_id BIGINT NULL COMMENT "ID",
typ_name VARCHAR(10) NULL COMMENT "NAME",
pv hll hll_union NOT NULL COMMENT "hll"
)
AGGREGATE KEY(typ_id,typ_name)
DISTRIBUTED BY HASH(typ_id) BUCKETS 10;
Import using the hll_hash function:
curl --location-trusted -u <doris_user>:<doris_password> \
-H "column_separator:|" \
-H "columns:typ_id,typ_name,pv=hll_hash(typ_id)" \
-T streamload_example.csv \
-XPUT http://<fe_ip>:<fe_http_port>/api/testdb/test_streamload/_stream_load
Column mapping, derived columns, and filtering
Doris supports rich column transformation and filtering operations in import statements, and supports most built-in functions. For details on how to use this feature, see the Data conversion documentation.
Enable strict mode for import
The strict_mode property is used to set whether the import task runs in strict mode. This property affects the results of column mapping, transformation, and filtering. For more about strict mode, see the Strict mode documentation.
Perform partial column update or flexible partial column update during import
For how to express partial column updates during import, see the Column update documentation.
FAQ
Does Stream Load support manual cancellation?
No. Stream Load is automatically canceled by the system when it times out or encounters an import error; users cannot manually cancel a running Stream Load job.
Is there a size limit for a single Stream Load file?
It is recommended that a single import file be no larger than 10 GB. For larger files, split the file before importing. You can also adjust the BE configuration parameter streaming_load_max_mb to raise the single import limit, or use Doris Streamloader for multi-concurrency imports to improve performance.
How do I query historical Stream Load jobs?
By default, the system does not record Stream Load history jobs. Set enable_stream_load_record=true in be.conf, restart, and then use show stream load from <db> to view the history.
How do I handle the "Label Already Exists" error?
This error indicates that the same label has already been used. You can determine the status of the existing job through the ExistingJobStatus field in the response:
RUNNING: the job is still running; wait for it to complete.FINISHED: the job has completed successfully; no retry is needed.- If it is CANCELLED, the same label can be used to start a new import.
It is recommended that the same batch of data always uses the same label, to ensure At-Most-Once semantics and avoid duplicate imports.
What if an import fails because of data format errors?
You can locate and handle the issue as follows:
- View the specific error rows through the
ErrorURLfield in the response:curl "<ErrorURL>". - Increase
max_filter_ratio(range 0 to 1) appropriately to tolerate some malformed data. - Check whether null values (
\N) and empty strings (no characters between two delimiters) in the CSV are used correctly. - Check whether the column separator, line delimiter, enclosing character (
enclose), and escape character (escape) configurations match the actual content of the file.
How do I handle import timeouts (CANCELLED)?
Estimate a reasonable timeout based on the data volume:
Import time ~= File size / Estimated import speed (for example, 50MB/s)
You can adjust the timeout in two ways:
- For a single import: use the Header parameter
-H "timeout:3000". - Globally: adjust the FE parameter
stream_load_default_timeout_second.
How do I distinguish null values from empty strings in CSV?
| Type | Representation | Example | Meaning of the middle column |
|---|---|---|---|
| Null value | Use \N | a,\N,b | Middle column is null |
| Empty string | No characters between two delimiters | a,,b | Middle column is an empty string |