
Transforming Data During Load
Doris provides powerful data transformation capabilities during data loading, which can simplify data processing workflows and reduce dependency on additional ETL tools. It mainly supports four types of transformations:
-
Column Mapping: Map source data columns to different columns in the target table.
-
Column Transformation: Transform source data in real-time using functions and expressions.
-
Pre-filtering: Filter out unwanted raw data before column mapping and transformation.
-
Post-filtering: Filter the final results after column mapping and transformation.
Through these built-in data transformation functions, you can improve loading efficiency and ensure consistency in data processing logic.
Load Syntax
Stream Load
Configure data transformation by setting the following parameters in HTTP headers:
| Parameter | Description |
|---|---|
columns | Specify column mapping and transformation |
where | Specify post-filtering |
Note: Stream Load does not support pre-filtering.
Example:
curl --location-trusted -u user:passwd \
-H "columns: k1, k2, tmp_k3, k3 = tmp_k3 + 1" \
-H "where: k1 > 1" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
Broker Load
Implement data transformation in SQL statements using the following clauses:
| Clause | Description |
|---|---|
column list | Specify column mapping, format: (k1, k2, tmp_k3) |
SET | Specify column transformation |
PRECEDING FILTER | Specify pre-filtering |
WHERE | Specify post-filtering |
Example:
LOAD LABEL test_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE `test_tbl`
(k1, k2, tmp_k3)
PRECEDING FILTER k1 = 1
SET (
k3 = tmp_k3 + 1
)
WHERE k1 > 1
)
WITH S3 (...);
Routine Load
Implement data transformation in SQL statements using the following clauses:
| Clause | Description |
|---|---|
COLUMNS | Specify column mapping and transformation |
PRECEDING FILTER | Specify pre-filtering |
WHERE | Specify post-filtering |
Example:
CREATE ROUTINE LOAD test_db.label1 ON test_tbl
COLUMNS(k1, k2, tmp_k3, k3 = tmp_k3 + 1),
PRECEDING FILTER k1 = 1,
WHERE k1 > 1
...
Insert Into
Insert Into can directly perform data transformation in the SELECT statement, using the WHERE clause for data filtering.
Column Mapping
Column mapping is used to define the correspondence between source data columns and target table columns. It can handle the following scenarios:
- The order of source data columns and target table columns is inconsistent
- The number of source data columns and target table columns is inconsistent
Implementation Principle
Column mapping implementation can be divided into two steps:
- Step 1: Data Source Parsing - Parse raw data into intermediate variables based on data format
- Step 2: Column Mapping and Assignment - Map intermediate variables to target table fields by column name
The following are processing flows for three different data formats:
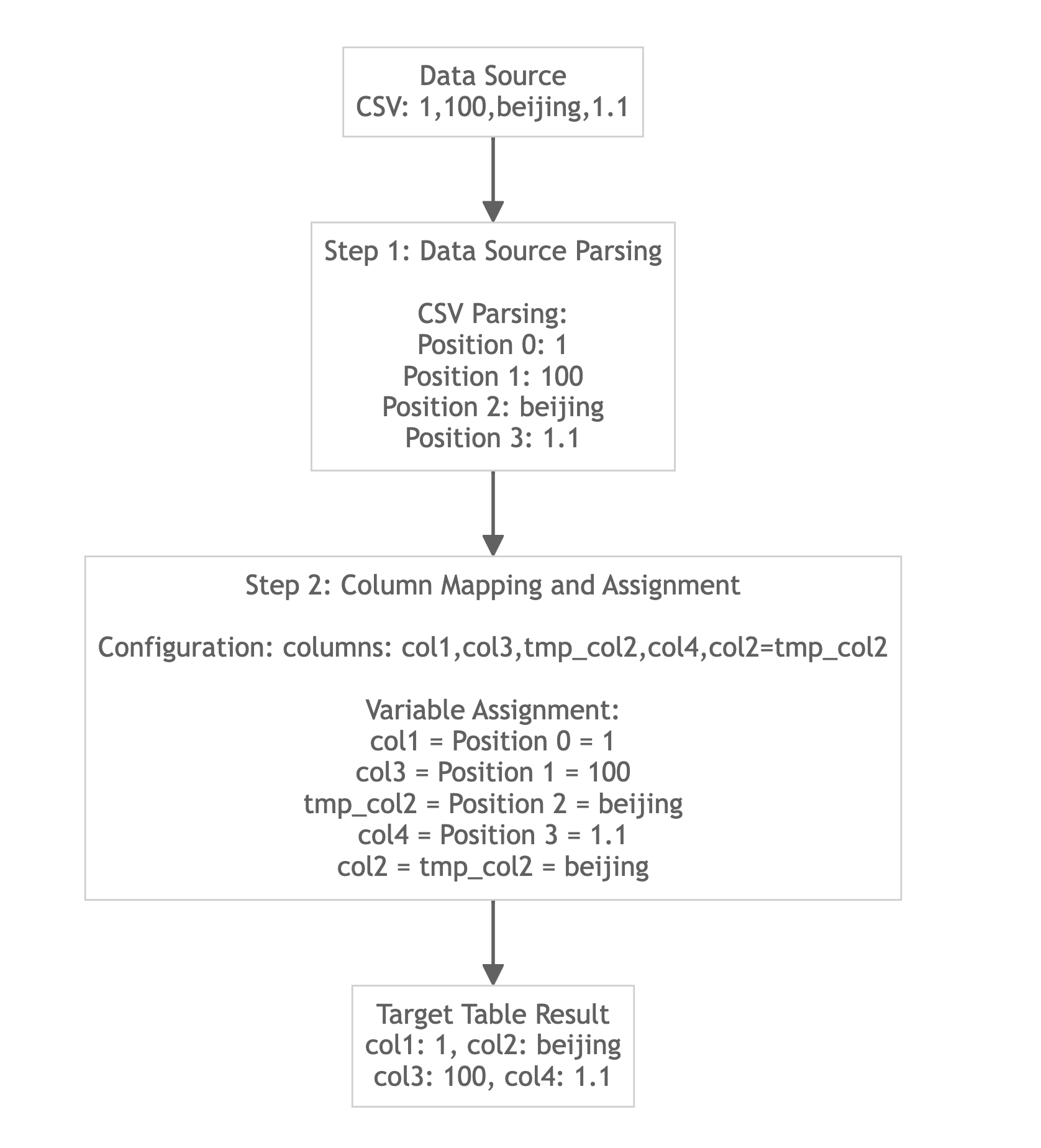
Load CSV Format Data
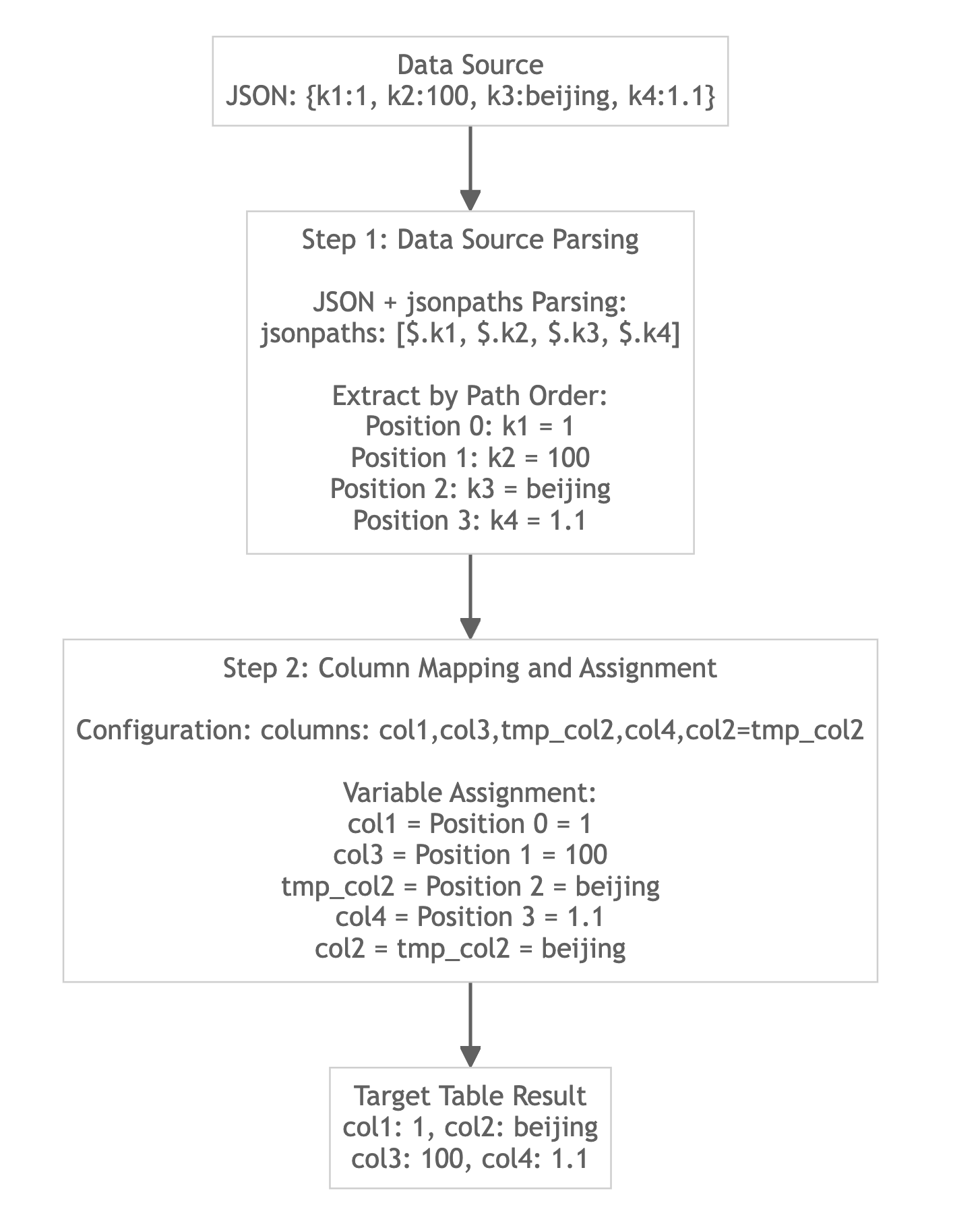
Load JSON Format Data with Specified jsonpaths
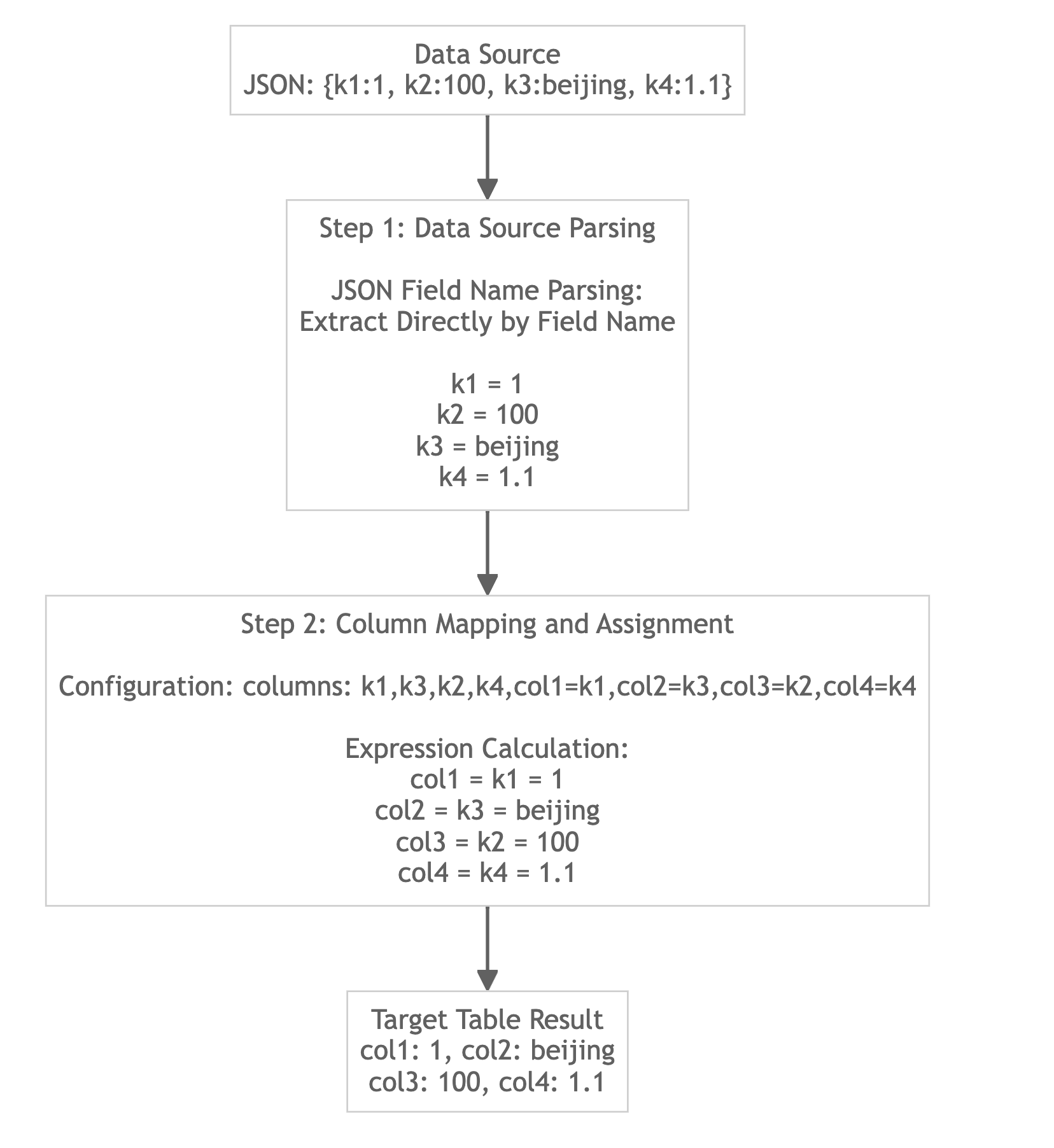
Load JSON Format Data without Specified jsonpaths
Load JSON Data with Specified jsonpaths
Assume the following source data (column headers are for illustration only, no actual headers exist):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
Create Target Table
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
Load Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:col1, col3, col2, col4" \
-H "jsonpaths:[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(col1, col3, col2, col4)
PROPERTIES
(
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]"
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(col1, col3, col2, col4)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.k1\", \"$.k2\", \"$.k3\", \"$.k4\"]",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
Query Results
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
Load JSON Data without Specified jsonpaths
Assume the following source data (column headers are for illustration only, no actual headers exist):
{"k1":1,"k2":"100","k3":"beijing","k4":1.1}
{"k1":2,"k2":"200","k3":"shanghai","k4":1.2}
{"k1":3,"k2":"300","k3":"guangzhou","k4":1.3}
{"k1":4,"k2":"\\N","k3":"chongqing","k4":1.4}
Create Target Table
CREATE TABLE example_table
(
col1 INT,
col2 STRING,
col3 INT,
col4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(col1)
DISTRIBUTED BY HASH(col1) BUCKETS 1;
Load Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "columns:k1, k3, k2, k4,col1 = k1, col2 = k3, col3 = k2, col4 = k4" \
-H "format:json" \
-H "read_json_by_line:true" \
-T data.json \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.json")
INTO TABLE example_table
FORMAT AS "json"
(k1, k3, k2, k4)
SET (
col1 = k1,
col2 = k3,
col3 = k2,
col4 = k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4, col1 = k1, col2 = k3, col3 = k2, col4 = k4),
PROPERTIES
(
"format" = "json",
"read_json_by_line" = "true"
)
FROM KAFKA (...);
Query Results
mysql> SELECT * FROM example_table;
+------+-----------+------+------+
| col1 | col2 | col3 | col4 |
+------+-----------+------+------+
| 1 | beijing | 100 | 1.1 |
| 2 | shanghai | 200 | 1.2 |
| 3 | guangzhou | 300 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+-----------+------+------+
Adjusting Column Order
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to map the columns as follows:
column1 -> k1
column2 -> k3
column3 -> k2
column4 -> k4
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
-X PUT \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k3, k2, k4)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
Query Results
mysql> select * from example_table;
+------+-----------+------+------+
| k1 | k2 | k3 | k4 |
+------+-----------+------+------+
| 2 | shanghai | 200 | 1.2 |
| 4 | chongqing | NULL | 1.4 |
| 3 | guangzhou | 300 | 1.3 |
| 1 | beijing | 100 | 1.1 |
+------+-----------+------+------+
Source File Columns Exceed Table Columns
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has three columns: k1, k2, and k3. We only need the first, second, and fourth columns from the source file, with the following mapping relationship:
column1 -> k1
column2 -> k2
column4 -> k3
To skip certain columns in the source file, you can use any column name that does not exist in the target table during column mapping. These column names can be customized and are not restricted. The data in these columns will be automatically ignored during loading.
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 DOUBLE
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u usr:passwd \
-H "column_separator:," \
-H "columns: k1,k2,tmp_skip,k3" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k2, tmp_skip, tmp_k3)
SET (
k1 = tmp_k1,
k2 = tmp_k2,
k3 = tmp_k3
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_skip, k3),
PROPERTIES
(
"format" = "csv",
"column_separator" = ","
)
FROM KAFKA (...);
Note: The
tmp_skipin the example can be replaced with any name, as long as it is not in the column definition of the target table.
Query Results
mysql> select * from example_table;
+------+------+------+
| k1 | k2 | k3 |
+------+------+------+
| 1 | 100 | 1.1 |
| 2 | 200 | 1.2 |
| 3 | 300 | 1.3 |
| 4 | NULL | 1.4 |
+------+------+------+
Source File Columns Less Than Table Columns
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has five columns: k1, k2, k3, k4, and k5. We only need the first, second, third, and fourth columns from the source file, with the following mapping relationship:
column1 -> k1
column2 -> k3
column3 -> k2
column4 -> k4
k5 uses the default value
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE,
k5 INT DEFAULT 2
) ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1,k3,k2,k4" \
-T data.csv \
http://<fe_ip>:<fe_http_port>/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label_broker
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k3, tmp_k2, tmp_k4)
SET (
k1 = tmp_k1,
k3 = tmp_k3,
k2 = tmp_k2,
k4 = tmp_k4
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k3, k2, k4),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
Note:
- If k5 has a default value, it will be filled with the default value
- If k5 is a nullable column but has no default value, it will be filled with NULL
- If k5 is a non-nullable column and has no default value, the load will fail
Query Results
mysql> select * from example_table;
+------+-----------+------+------+------+
| k1 | k2 | k3 | k4 | k5 |
+------+-----------+------+------+------+
| 1 | beijing | 100 | 1.1 | 2 |
| 2 | shanghai | 200 | 1.2 | 2 |
| 3 | guangzhou | 300 | 1.3 | 2 |
| 4 | chongqing | NULL | 1.4 | 2 |
+------+-----------+------+------+------+
Column Transformation
Column transformation allows users to transform column values in the source file, supporting the use of most built-in functions. Column transformation is usually defined together with column mapping, i.e., first map the columns and then transform them.
Transforming Source File Column Values Before Loading
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to transform the column values as follows:
column1 -> k1
column2 * 100 -> k3
column3 -> k2
column4 -> k4
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 STRING,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k3, k2, k4)
SET (
k3 = tmp_k3 * 100
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k3, k2, k4, k3 = tmp_k3 * 100),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
Query Results
mysql> select * from example_table;
+------+------+-------+------+
| k1 | k2 | k3 | k4 |
+------+------+-------+------+
| 1 | beijing | 10000 | 1.1 |
| 2 | shanghai | 20000 | 1.2 |
| 3 | guangzhou | 30000 | 1.3 |
| 4 | chongqing | NULL | 1.4 |
+------+------+-------+------+
Using Case When Function for Conditional Column Transformation
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to transform the column values as follows:
column1 -> k1
column2 -> k2
column3 -> k3 (transformed to area id)
column4 -> k4
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4, k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
Query Results
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
Handling NULL Values in Source Files
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to transform the column values as follows:
column1 -> k1 (transform NULL to 0)
column2 -> k2
column3 -> k3
column4 -> k4
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp_k2, tmp_k3, k4)
SET (
k2 = ifnull(tmp_k2, 0),
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp_k2, tmp_k3, k4, k2 = ifnull(tmp_k2, 0), k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END),
COLUMNS TERMINATED BY ","
FROM KAFKA (...);
Query Results
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 3 | 300 | 3 | 1.3 |
| 4 | 0 | 4 | 1.4 |
+------+------+------+------+
Pre-filtering
Pre-filtering is the process of filtering out unwanted raw data before column mapping and transformation. This feature is only supported in Broker Load and Routine Load.
Pre-filtering has the following application scenarios:
- Filtering before transformation
Scenarios where filtering is needed before column mapping and transformation, allowing for the removal of unwanted data before processing.
- Filtering columns that do not exist in the table, only as filtering indicators
For example, source data contains multiple tables' data (or multiple tables' data is written to the same Kafka message queue). Each row of data has a column indicating which table the data belongs to. Users can use pre-filtering conditions to filter out the corresponding table data for loading.
Pre-filtering has the following limitations:
- Column filtering restrictions
Pre-filtering can only filter independent simple columns in the column list and cannot filter columns with expressions. For example: when the column mapping is (a, tmp, b = tmp + 1), column b cannot be used as a filter condition.
- Data processing restrictions
Pre-filtering occurs before data transformation, using raw data values for comparison, and raw data is treated as string type. For example: for data like \N, it will be compared directly as the \N string, rather than being converted to NULL before comparison.
Example 1: Using Numeric Conditions for Pre-filtering
This example demonstrates how to filter source data using simple numeric comparison conditions. By setting the filter condition k1 > 1, we can filter out unwanted records before data transformation.
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
Pre-filtering condition:
column1 > 1, i.e., only load data where column1 > 1, and filter out other data.
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
PRECEDING FILTER k1 > 1
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
PRECEDING FILTER k1 > 1
FROM KAFKA (...)
Query Results
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 2 | 200 | shanghai | 1.2 |
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
Example 2: Using Intermediate Columns to Filter Invalid Data
This example demonstrates how to handle data import scenarios containing invalid data.
Source data:
1,1
2,abc
3,3
Table Creation
CREATE TABLE example_table
(
k1 INT,
k2 INT NOT NULL
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
For column k2, which is of type INT, abc is invalid dirty data. To filter this data, we can introduce an intermediate column for filtering.
Load Statements
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, tmp, k2 = tmp)
PRECEDING FILTER tmp != "abc"
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, tmp, k2 = tmp),
COLUMNS TERMINATED BY ","
PRECEDING FILTER tmp != "abc"
FROM KAFKA (...);
Load Results
mysql> select * from example_table;
+------+----+
| k1 | k2 |
+------+----+
| 1 | 1 |
| 3 | 3 |
+------+----+
Post-filtering
Post-filtering is the process of filtering the final results after column mapping and transformation.
Filtering Without Column Mapping and Transformation
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to load only the data where the fourth column is greater than 1.2.
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k4 > 1.2;
FROM KAFKA (...)
Query Results
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+
Filtering Transformed Data
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to transform the column values as follows:
column1 -> k1
column2 -> k2
column3 -> k3 (transformed to area id)
column4 -> k4
We want to filter out the data where the transformed k3 value is 3.
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 INT,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, tmp_k3, k4, k3 = case tmp_k3 when 'beijing' then 1 when 'shanghai' then 2 when 'guangzhou' then 3 when 'chongqing' then 4 else null end" \
-H "where: k3 != 3" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, tmp_k3, k4)
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, tmp_k3, k4),
COLUMNS TERMINATED BY ","
SET (
k3 = CASE tmp_k3 WHEN 'beijing' THEN 1 WHEN 'shanghai' THEN 2 WHEN 'guangzhou' THEN 3 WHEN 'chongqing' THEN 4 ELSE NULL END
)
WHERE k3 != 3;
FROM KAFKA (...)
Query Results
mysql> select * from example_table;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 1 | 100 | 1 | 1.1 |
| 2 | 200 | 2 | 1.2 |
| 4 | NULL | 4 | 1.4 |
+------+------+------+------+
Multiple Conditions Filtering
Suppose we have the following source data (column names are for illustration purposes only, and there is no actual header):
column1,column2,column3,column4
1,100,beijing,1.1
2,200,shanghai,1.2
3,300,guangzhou,1.3
4,\N,chongqing,1.4
The target table has four columns: k1, k2, k3, and k4. We want to filter out the data where k1 is NULL and k4 is less than 1.2.
Creating the Target Table
CREATE TABLE example_table
(
k1 INT,
k2 INT,
k3 STRING,
k4 DOUBLE
)
ENGINE = OLAP
DUPLICATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 1;
Loading Data
- Stream Load
curl --location-trusted -u user:passwd \
-H "column_separator:," \
-H "columns: k1, k2, k3, k4" \
-H "where: k1 is not null and k4 > 1.2" \
-T data.csv \
http://host:port/api/example_db/example_table/_stream_load
- Broker Load
LOAD LABEL example_db.label1
(
DATA INFILE("s3://bucket_name/data.csv")
INTO TABLE example_table
COLUMNS TERMINATED BY ","
(k1, k2, k3, k4)
where k1 is not null and k4 > 1.2
)
WITH s3 (...);
- Routine Load
CREATE ROUTINE LOAD example_db.example_routine_load ON example_table
COLUMNS(k1, k2, k3, k4),
COLUMNS TERMINATED BY ","
WHERE k1 is not null and k4 > 1.2
FROM KAFKA (...);
Query Results
mysql> select * from example_table;
+------+------+-----------+------+
| k1 | k2 | k3 | k4 |
+------+------+-----------+------+
| 3 | 300 | guangzhou | 1.3 |
| 4 | NULL | chongqing | 1.4 |
+------+------+-----------+------+