Alternative to ClickHouse
Apache Doris and ClickHouse are both leading real-time analytical databases with columnar storage and fast query capabilities. Apache Doris offers significant advantages over ClickHouse in three critical areas: 10x faster join query performance through its advanced MPP architecture with Cost-Based Optimizer, lower infrastructure costs via compute-storage separation that allows independent scaling of resources, and superior real-time update performance with its Merge-on-Write engine that maintains query speed during high-frequency data modifications.
Featured Migration Cases
“Tencent Music's data platform has migrated from ClickHouse to Apache Doris, improving data timeliness and reducing maintenance costs. Doris' flexible ingestion methods and robust consistency protocol ensure high availability and reliability.”
Highlight:
- Massive boost in multi-table join performance.
- Easy scaling and maintenance.
- Efficient data processing and real-time updates.
“Apache Doris has faster query response times than ClickHouse in the vast majority of scenarios, especially in complex join scenarios, where its performance is significantly superior to that of ClickHouse.”
Highlight:
- Core business queries 2-3x.
- Complex join queries 2-10x.
- Can run all ClickHouse OOM queries.
“By replacing ClickHouse with Doris, Kwai successfully upgraded to a lakehouse architecture, simplifying the data pipeline and eliminating the need for data import, as Doris can directly access data lake data.”
Highlight:
- Directly query of data lake data.
- Improved query performance.
- Flexible data governance with materialized views.
Apache Doris vs. ClickHouse
| Apache Doris | ClickHouse | |
|---|---|---|
| Architecture & SQL |
|
|
| Join Query Performance |
|
|
| Real-time Updates |
|
|
| Transaction Support |
|
|
| Query Concurrency |
|
|
| Data API |
|
|
| Building Open Lakehouse |
|
|
| Operations & Maintenance |
|
|
| Performance |
|
|
| Cost Efficiency (Storage-Compute Separation) |
|
|
| Open Source |
|
|
Performance Comparison
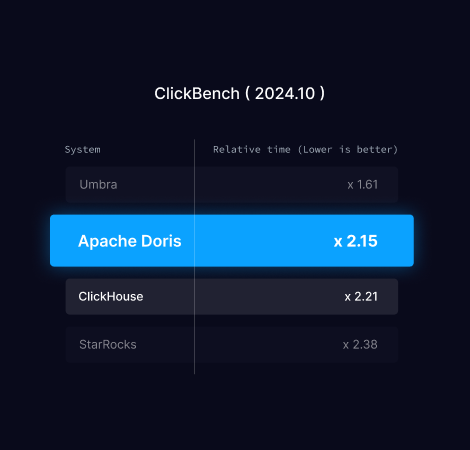
ClickBench Benchmark
ClickBench is a benchmarking tool created and maintained by the ClickHouse team to evaluate the performance of analytical databases.
It focuses on testing the performance of large, flat tables rather than complex multi-table joins. It uses real-world data from a major web analytics platform, covering typical scenarios such as clickstream analysis and structured logs.
The benchmark consists of a set of queries that test aggregation operations and single-table performance, without involving complex joins. This makes it especially useful for evaluating databases optimized for real-time analytics and large-scale data processing.
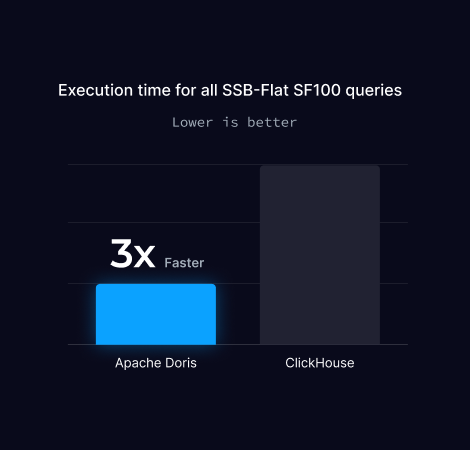
SSB-Flat SF100 Benchmark
SSB-Flat SF100 is a benchmark designed to test the performance of analytical databases in handling large, wide tables.
It is derived from the Star Schema Benchmark (SSB) but flattens the star schema into a single wide table to focus on the performance of single-table queries.
The SF100 indicates that the data scale is 100 times the base size, making it a significant test for evaluating query performance and system scalability.
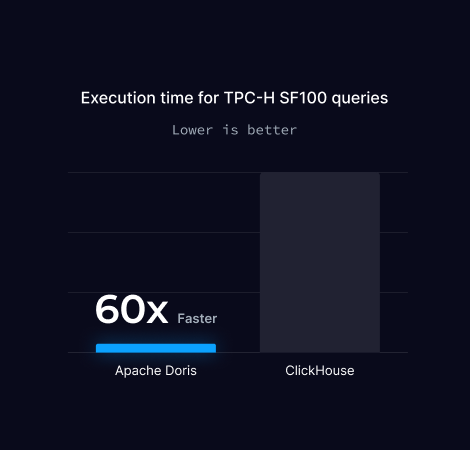
TPC-H SF100 Benchmark
The TPC-H benchmark with a scale factor of 100 (SF100) is a widely used standard for evaluating database performance. It includes a set of complex SQL queries designed to simulate real-world business intelligence workloads.
The SF100 indicates that the data size is 100 times the base size, making it a large-scale test to measure query performance and system scalability.
Note: Since ClickHouse failed to execute 7 queries, the total execution time refers to the time taken by Doris to run all 22 queries, and by ClickHouse to run only 15 queries.
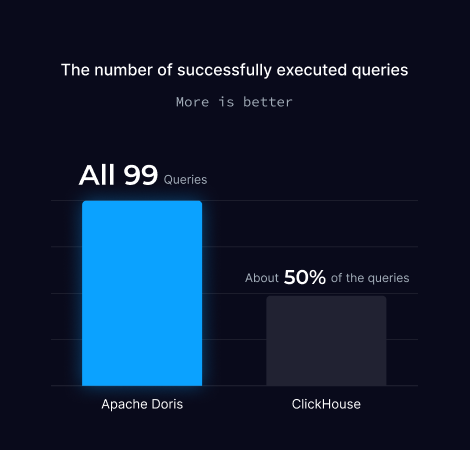
TPC-DS 1TB Benchmark
TPC-DS 1TB is a widely recognized benchmark for evaluating the performance of data warehouses and analytical databases. It involves a dataset of approximately 1TB in size, containing around 6.35 billion records spread across 24 tables.
The benchmark includes 99 complex queries designed to test various aspects of database performance, such as joins, aggregations, and subqueries.
The TPC-DS schema is based on a snowflake schema, representing real-world scenarios like web, catalog, and store sales. The 1TB scale is considered a moderate size for data warehouses but is still challenging due to the complexity of the queries and the large number of records
Note:TPC-DS makes heavy use of correlated subqueries which are at the time of testing (September 2024) not supported by ClickHouse. As a result, about 50% of benchmark queries will fail with errors.