Apache Doris vs Trino / Presto
Apache Doris and Trino/Presto are both popular data lakehouse query engines, but Doris outperforms Trino/Presto in terms of performance. While Trino/Presto are primarily query engines, Doris can also function as a standalone data warehouse. This enables enterprises to unify their data warehouse and Lakehouse query engine into one with Doris, simplifying their data architecture
-
Unified: Doris unifies data warehouse and Lakehouse query engine, simplifying the tech stack
-
10x Query Performance: Doris native table boosts query performance by up to 10x compared to Presto/Trino
-
2-3x Faster: Doris as a Lakehouse engine is 2-3x faster than Presto/Trino
Featured Migration Cases
“As the world-renowed internet giant, our early data platform used Trino, Pinot, Iceberg, and Kyuubi, but faced complexity, redundancy, and poor performance. By replacing them with Apache Doris, we unified its data lakehouse and query engine, boosting performance and reducing costs by 30%.”
“After switching from Presto to Doris, query performance significantly improved, reducing query time from 20-40 seconds to 1-2 seconds. By designing 2-3 materialized views based on common data dimensions, Doris can automatically match the optimal view for queries, further enhancing performance.”
“Using Trino and SparkSQL, query latency was at the minute level, and performance was low. After switching to Doris, performance improved 2 times. Doris also unified the tech stack, simplifying the management of real-time and interactive analytics tools.”
Apache Doris vs. Trino / Presto
| Apache Doris | Trino / Presto | |
|---|---|---|
| Architecture |
|
|
| Execution Engine |
|
|
| Query Optimizer |
|
|
| Caching Mechanisms |
|
|
| Materialized Views |
|
|
| Use Cases |
|
|
Performance Comparison
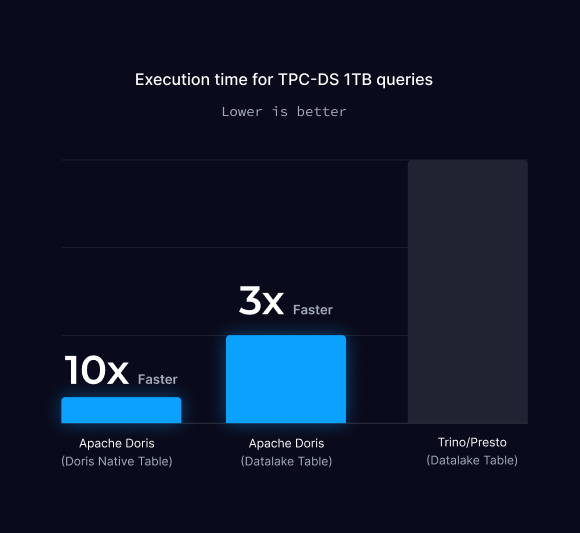
TPC-DS 1TB Benchmark
The TPC-DS 1TB Benchmark evaluates data warehouse performance using a 1TB dataset with 6.35 billion records across 24 tables. It includes 99 complex queries to test joins, aggregations, and subqueries. Based on a snowflake schema, it simulates real-world sales scenarios. The 1TB scale is challenging due to query complexity.
The test environment consists of:
- 1 FE/Coordinator node and 5 BE/Worker nodes.
- Each node has 64 cores, 1.5TB of memory, and SSD storage.
- HDFS is co-located on these nodes, and Hive tables are created.
In this test, using the same dataset and equal computing service, the results shows that:
- When data is imported into Doris' internal tables and queried using Doris, it achieves the shortest execution time.
- When Doris and Trino are used separately to query data directly from Hive tables, Doris demonstrates superior query acceleration performance in the data lake.