Binlog / Table Stream
TL;DR Apache Doris Table Stream is the upcoming public API for reading row-level changes (insert, update, delete) out of a Doris table, the way you read a MySQL binlog. The plumbing is already in the codebase: a row-format binlog, a
STREAMobject that pins offsets per partition, and consumption metadata. The feature is not GA yet, and the defaultbinlog.ttl_secondsis 86,400 seconds (one day). Today the same binlog powers Cross-Cluster Replication; for general CDC out of Doris, use the Flink Doris Connector. Status: Coming Soon (Preview).
The STREAM object, binlog.format = ROW, and the consumption metadata views described here are present in the Doris source tree but not yet released as a stable, user-facing API. Syntax and semantics may change before GA. Production CDC pipelines today should use Kafka and CDC Integration or CCR.
Why use binlog and table stream in Apache Doris?
Apache Doris binlog and table stream give downstream consumers a row-level change feed, so a Flink job, audit trail, or search index can react to every insert, update, and delete without re-reading the table. Apache Doris is good at ingesting change data. Getting change data back out is harder. If a downstream system (a Flink job, an audit trail, another Doris cluster, a search index) needs to react to every insert, update, and delete, the options today are awkward:
- Re-read the table on a timer and diff. Cheap to write, expensive to run, never real-time.
- Have producers double-write to Kafka and Doris. Two sinks, two failure modes.
- Stand up CCR. It works, but it is a Doris-to-Doris replicator, not a generic change feed.
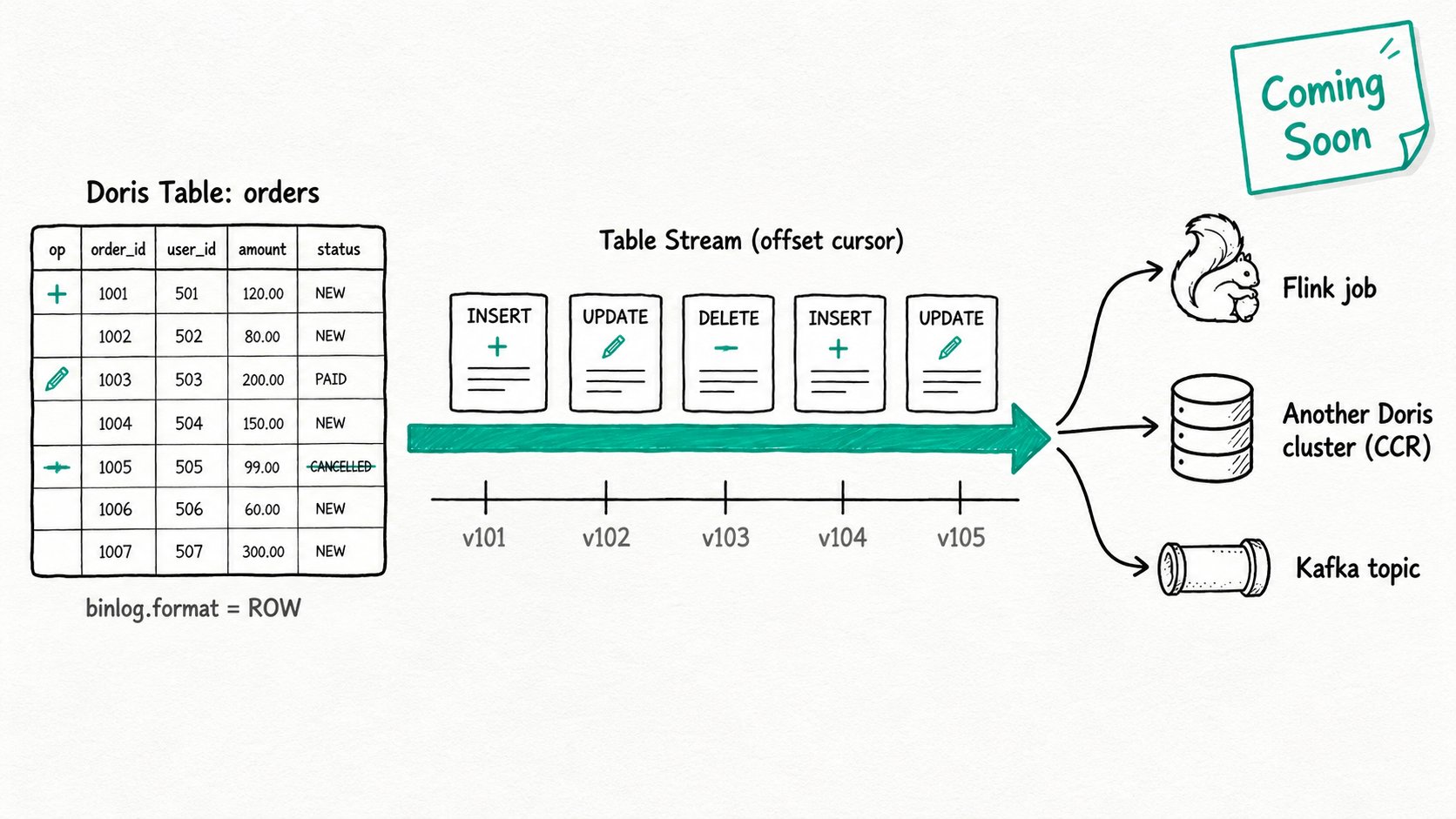
Binlog and Table Stream close that gap. The binlog records every committed change at the row level. The Table Stream is a named cursor over that log: a consumer attaches to a stream, reads the changes since its last offset, and acknowledges. Same idea as MySQL binlog, Snowflake Streams, or a Postgres logical replication slot, expressed as a first-class Doris object.
What is the Apache Doris binlog and table stream?
Apache Doris binlog is the per-table change log Doris already maintains for replication, and Apache Doris table stream is the consumer-facing object that exposes it as row-level CDC. The binlog comes in two formats. STATEMENT_AND_SNAPSHOT is what CCR has shipped on for years: it records DDL plus snapshots, and the CCR Syncer applies them downstream. The new ROW format records every committed row delta, which is what a generic CDC consumer needs.
A table stream is the consumer-facing object on top of the row-format binlog. A stream is created with CREATE STREAM <name> ON <base_table>, owns its own offsets per partition, and exposes a SQL surface: SHOW CREATE STREAM and an information_schema view of consumption progress.
Key terms
binlog.enable: per-table property.trueturns on the binlog for that table.binlog.format: per-table property.STATEMENT_AND_SNAPSHOT(today, used by CCR) orROW(the row-delta format Table Stream consumes).binlog.ttl_seconds/binlog.max_bytes/binlog.max_history_nums: retention knobs. Default TTL is one day; the byte and history caps default to effectively unlimited.STREAM: a Doris catalog object that wraps a base table and tracks per-partition offsets for one consumer.- Stream consume type:
default,append_only, ormin_delta. Controls whether the stream emits full row deltas, inserts only, or the minimal change set. - Stream lag: visible version of the partition minus the stream's recorded offset. Surfaced as the
LAGcolumn.
How does the Apache Doris binlog and table stream work?
The Apache Doris binlog records row-level deltas at the BE, and a table stream wraps that log with per-partition offsets so a downstream consumer can read changes incrementally and acknowledge them.
- Turn the binlog on.
ALTER TABLE t SET ("binlog.enable" = "true", "binlog.format" = "ROW"). The BE starts retaining row-level deltas alongside tablet data, governed bybinlog.ttl_secondsand the size and history caps. CCR users may already havebinlog.enable = truewith the olderSTATEMENT_AND_SNAPSHOTformat; Table Stream needsROW. - Create a stream over the table.
CREATE STREAM s ON t PROPERTIES ("type" = "default"). The FE materializes aSTREAMobject, snaps the current visible version of every partition as the starting offset, and registers it under the database.show_initial_rows = trueflips that so the first read returns the historical state. - Consume. A downstream reader (an external CDC connector today, native consumer endpoints over time) reads from the stream. Each batch advances the per-partition offset and stamps a consumption timestamp.
- Trim. Once every active stream has moved past a binlog entry, and the entry is older than
binlog.ttl_seconds, the BE garbage-collects it. A stream that falls behind retention is markedIS_STALE = truewith a reason, the same way CCR reports a broken syncer. - Observe.
information_schema.table_streamslists every stream and its base table.table_stream_consumptionreportsUNIT(the partition),CONSUMPTION_STATUS,LAG, andLAST_CONSUMPTION_TIMEper partition. That is the lag dashboard.
Quick start
-- 1. Enable row-format binlog on the source table
ALTER TABLE orders SET (
"binlog.enable" = "true",
"binlog.format" = "ROW",
"binlog.ttl_seconds" = "86400"
);
-- 2. Create a Table Stream over it (planned syntax, subject to change)
CREATE STREAM orders_cdc ON orders
PROPERTIES ("type" = "default", "show_initial_rows" = "false");
-- 3. Inspect the stream and its lag
SHOW CREATE STREAM orders_cdc;
SELECT * FROM information_schema.table_stream_consumption
WHERE STREAM_NAME = 'orders_cdc';
Expected result
+---------+------------+-----------+--------------------+-----+----------------------+
| DB_NAME | STREAM_NAME| STREAM_ID | UNIT (partition) | LAG | LAST_CONSUMPTION_TIME|
+---------+------------+-----------+--------------------+-----+----------------------+
| sales | orders_cdc | 10042 | p_2026_05 | 0 | 2026-05-09 10:14:33 |
+---------+------------+-----------+--------------------+-----+----------------------+
LAG = 0 means the consumer is caught up to the partition's visible version. As writes commit upstream, LAG grows; as the consumer reads, it shrinks. A non-N/A STALE_REASON means retention rolled past the offset and a re-snapshot is needed.
When should you use the Apache Doris binlog and table stream?
Once GA, use the Apache Doris binlog and table stream when a downstream system needs row-level change events from a Doris table without re-reading the whole table.
Good fit (once GA)
- Driving a downstream Flink or Spark job from Doris-side change events without re-reading the table.
- Maintaining an external search index, cache, or audit trail that needs every insert and delete.
- Doris-to-Doris replication that wants explicit consumer offsets rather than CCR's syncer model.
- Triggering recomputation of an external materialized view when a partition's
LAGchanges.
Not a good fit (especially today)
- Production CDC pipelines, right now. The
STREAMobject is in the source tree but not announced as GA. Use Kafka and CDC Integration instead. - Doris-to-Doris cross-cluster sync. CCR ships today, handles DDL replay, and is the supported path. CCR uses
STATEMENT_AND_SNAPSHOTbinlog; Table Stream usesROW. - Long-paused consumers on short binlog retention. If
LAGoutruns whatbinlog.ttl_secondskeeps, the stream goes stale and the consumer has to reseed. - Storage-compute decoupled clusters. CCR explicitly does not support it yet; Table Stream's support model there is still in flight.
- Reading external catalog tables (Hive, Iceberg). Table Stream is scoped to internal OLAP tables only.
Further reading
- Kafka and CDC Integration: the supported way to move change data into and around Doris today.
- Cross-Cluster Replication overview: the existing binlog consumer, with the Syncer architecture and applicable scenarios.
- CCR feature matrix: which DDL and DML operations the binlog already captures and replays, a preview of what a row-format stream will surface.
- CCR quickstart: how
binlog.enableandenable_feature_binlogget configured today. - Data Update and Delete: how Unique Key Merge-on-Write tables represent the deletes and out-of-order updates a row stream will carry.
- Iceberg: an external destination for replicated tables — land CDC into Iceberg via SQL without leaving Doris.
- Unique Key: the upstream table model that captures one-row-per-key state cleanly for downstream binlog consumers.