BM25 Relevance Scoring
TL;DR Apache Doris ranks full-text search hits with BM25, the same scoring algorithm Lucene and Elasticsearch use. Add
score()to a SELECT, keep aMATCH_*predicate in the WHERE clause, andORDER BYthe score with aLIMIT. The Apache Doris planner pushes the top-K computation into the inverted index and returns the most relevant rows first.
Why use BM25 scoring in Apache Doris?
Apache Doris BM25 scoring turns full-text matches into a ranked top-K result inside SQL, so a million-row corpus can return the best ten hits without a separate search engine. Equality filters tell you which rows match. They don't tell you which rows are good matches. A query like WHERE content MATCH_ANY 'apache doris real-time analytics' over a million-row log table can easily return 50,000 hits, and the user only wants the best ten. Without a relevance score, the database has no good way to pick those ten:
- Sort by date and you bury the perfect match from last year.
- Sort by an arbitrary column and you ship random results.
- Compute relevance in the application and you've now built half a search engine on top of your warehouse.
BM25 closes that gap inside SQL. Apache Doris gives each matching row a score based on how often the query terms appear in it, how rare those terms are across the table, and how long the row's text is. Sort by that score and you get search-engine-style ranking from a SELECT.
What is Apache Doris BM25 scoring?
Apache Doris BM25 scoring is the SQL-exposed implementation of the BM25 (Best Matching 25) relevance ranking function from the TF-IDF family. The function takes a query term and a document and returns a positive number: higher means more relevant. Three things drive the score. Rows that contain the term more often score higher. Rare terms count for more than common ones. And longer rows are normalized down so a 200-word row doesn't automatically beat a 20-word row that says the same thing.
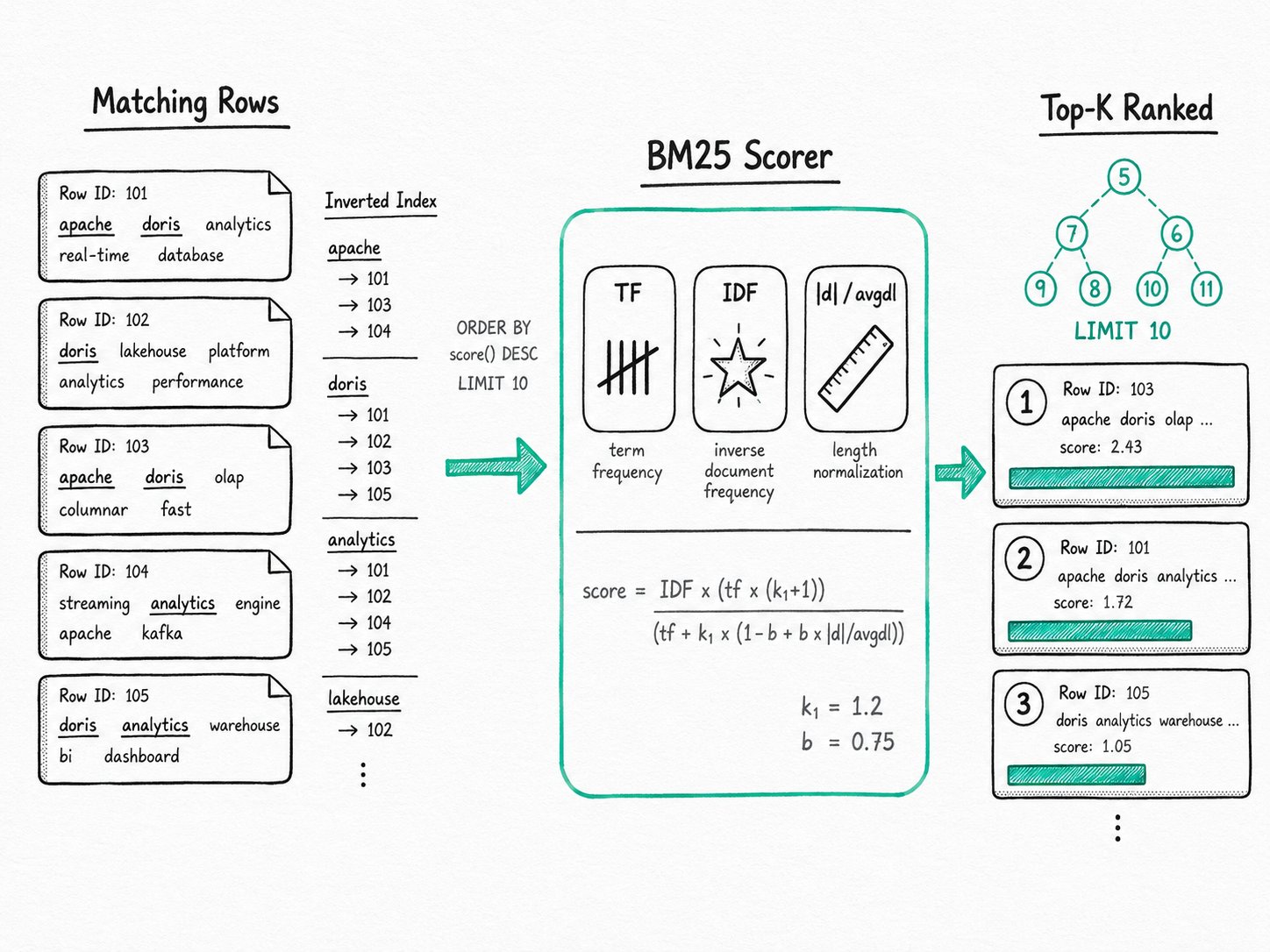
Apache Doris exposes BM25 through the score() SQL function. The inverted index already stores the term frequencies, document frequencies, and field lengths the formula needs, so once the index exists you don't pay an extra scan to score.
Key terms
score(): an Apache Doris scalar function that returns the BM25 relevance score of the current row against the query'sMATCH_*predicates. ReturnsFLOAT.- TF (term frequency): how many times the query term appears in the row.
- IDF (inverse document frequency): a measure of how rare the term is across the table. Common words score low, rare words score high.
k1andb: BM25's tuning constants. Apache Doris ships withk1 = 1.2andb = 0.75, the Lucene defaults. They are not currently exposed as session variables.
How does Apache Doris BM25 scoring work?
Apache Doris evaluates BM25 inside the inverted-index reader: the planner recognizes the score() + MATCH_* + ORDER BY + LIMIT shape, the BE scores rows while it scans postings, and a bounded min-heap of size LIMIT keeps only the top-K.
- The inverted index records the statistics. When data is loaded into a column with a tokenized inverted index (parsers like
english,standard, orchinese), Apache Doris stores the term dictionary, per-row term frequencies, and field lengths. The same statistics that powerMATCH_*filtering also feed BM25. - The planner recognizes the scoring shape. When a query has
score()in the SELECT, aMATCH_*predicate in the WHERE, and anORDER BY score()with aLIMIT, Nereids rewrites the plan to push top-K scoring into the storage layer. If you usescore()outside that exact shape, Apache Doris fails the query withscore() function requires WHERE clause with MATCH function, ORDER BY and LIMIT for optimization. That constraint exists to keep you from accidentally scoring every row in a billion-row table. - The BE scores while it scans. The inverted-index reader walks the postings for each query term. For every candidate row, it computes
IDF * (tf * (k1 + 1)) / (tf + k1 * (1 - b + b * |d| / avgdl)), where|d|is the row's tokenized length andavgdlis the table's average. For multi-term queries, the per-term scores are added. - A heap keeps the top-K. The BE keeps a bounded min-heap of size
LIMIT, so it never has to hold the full match set in memory. That's the difference between scoring 50,000 rows and then sorting versus stream-scoring and keeping only the best ten. - Apache Doris returns the ranked rows. The FE merges the already-sorted top-K from each tablet and returns the result.
Quick start
CREATE TABLE articles (
id BIGINT,
content TEXT,
INDEX idx_content(content) USING INVERTED PROPERTIES("parser" = "english")
) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 1;
INSERT INTO articles VALUES
(1, 'apache doris is a real-time analytics database'),
(2, 'real-time analytics on streaming data'),
(3, 'a guide to apache kafka');
SELECT id, content, score() AS relevance
FROM articles
WHERE content MATCH_ANY 'apache doris analytics'
ORDER BY relevance DESC
LIMIT 3;
Expected result
+----+----------------------------------------------------+-----------+
| id | content | relevance |
+----+----------------------------------------------------+-----------+
| 1 | apache doris is a real-time analytics database | 1.871290 |
| 2 | real-time analytics on streaming data | 0.575364 |
| 3 | a guide to apache kafka | 0.287682 |
+----+----------------------------------------------------+-----------+
Row 1 wins because it matches all three query terms. Row 2 matches one rare term (analytics). Row 3 only matches apache, the most common term in this corpus, so it scores lowest. The absolute numbers don't mean anything on their own. What matters is the ordering inside this one result set.
When should you use Apache Doris BM25 scoring?
Apache Doris BM25 scoring fits top-K full-text ranking and the text leg of hybrid search; it is not the right tool for exact-equality lookups, aggregations on relevance, or comparing scores across different queries.
Good fit
- Top-K full-text search over logs, documents, articles, product descriptions, or any text column with a tokenized inverted index.
- The text-relevance leg of a hybrid search query, fused with vector similarity through SQL
ORDER BYor RRF. - Retiring a separate Elasticsearch cluster whose only job is ranking matches over data you already store in Doris.
- Multi-term queries where users care about the best match, not just any match.
Not a good fit
- Exact-equality lookups. A non-tokenized inverted index does not compute scores. Use
=orINand skipscore()entirely. - Aggregations over scored results. Apache Doris rejects
score()insideGROUP BY, inside aggregate functions, and in any plan withoutORDER BY score() LIMIT. If you need analytics on relevance, materialize the top-K first and aggregate over that result set. - Comparing scores across queries. BM25 is corpus- and query-dependent. A score of 3.0 from one query and 3.0 from another mean different things. Use a rank-based fusion such as RRF instead. See Reciprocal Rank Fusion.
- Tuning
k1andbper query. Apache Doris uses Lucene's defaults and does not currently expose these as runtime parameters. If your workload really needs custom tuning, file an issue rather than working around it with hand-rolled scoring. - Pure vector ranking. If the query is "find the 10 nearest embeddings, no keyword constraint at all", use an ANN distance function and skip BM25.
Further reading
- Inverted index: how Apache Doris stores the data BM25 reads from
- Full-text search: tokenizers, MATCH operators, and the SEARCH function
- Hybrid search: combining BM25 with vector similarity in one query
- Reciprocal Rank Fusion: a query-independent way to fuse BM25 and vector rankings
- Relevance scoring reference: full BM25 formula, parameters, and FAQ
- Inverted index overview: index types, parsers, and supported queries