Condition Cache
TL;DR Apache Doris Condition Cache stores the result of a
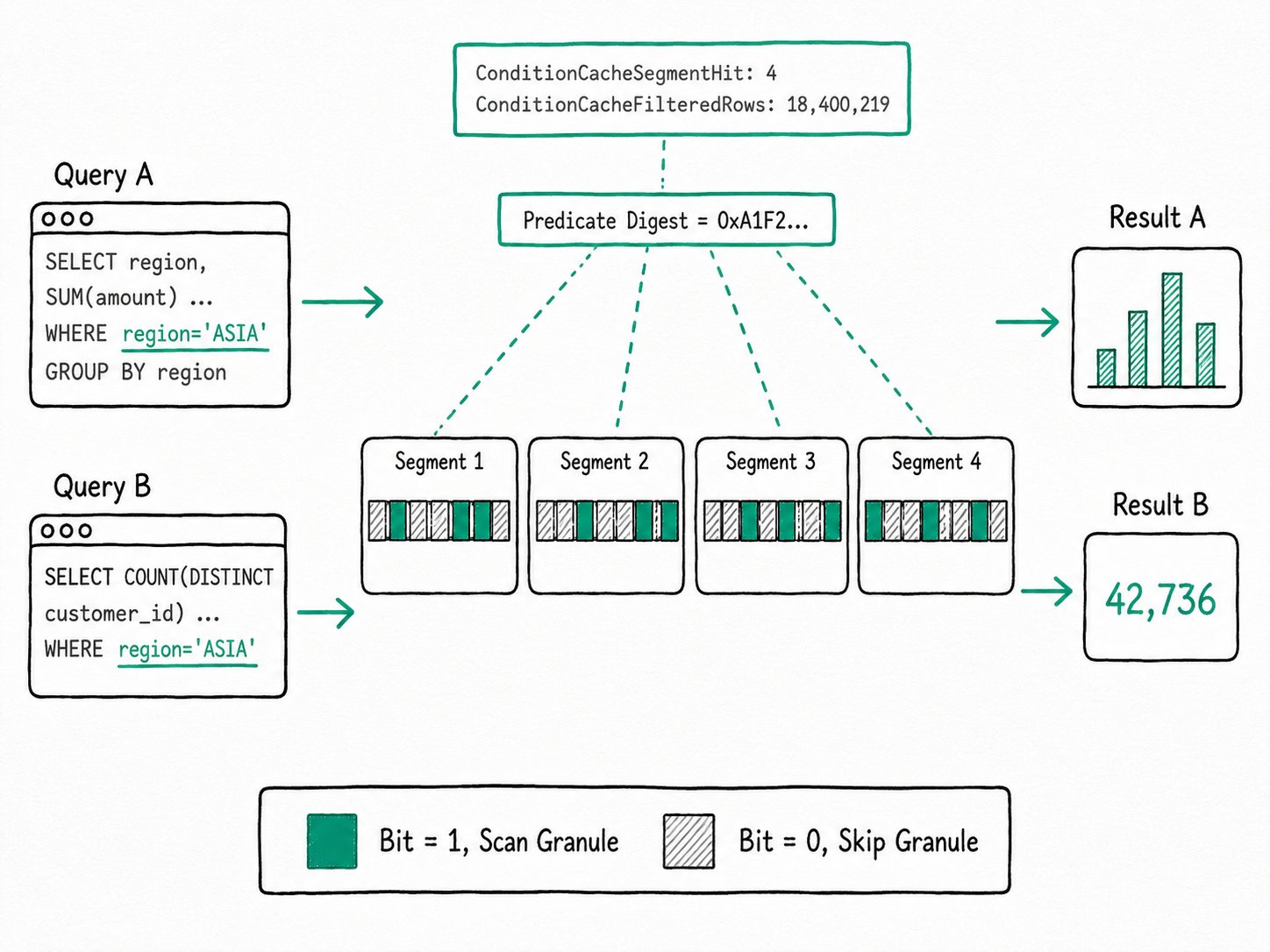
WHEREclause on each segment as a compressed bit vector keyed by(predicate digest, key range). The next query that uses the same filter on the same segment skips the granules the bit vector already says cannot match, even when the SELECT list, GROUP BY, or aggregation is different. Five dashboard panels that all shareWHERE region = 'ASIA' AND order_date >= '2023-01-01'evaluate that filter once per segment and reuse it across every panel.
Why use the Apache Doris Condition Cache?
The Apache Doris Condition Cache reuses predicate evaluation across queries that share a WHERE clause but differ in everything else, plugging the gap between SQL Cache and Query Cache. Most analytical workloads filter a lot more than they aggregate. A dashboard built on a single orders table will have ten panels that all share WHERE region = ? AND order_date >= ? and differ only in the SELECT list. An application backend reissues the same predicate every few seconds with a new aggregation. A T+1 report runs different aggregations against partitions that have not changed since last night.
The cluster pays the predicate evaluation cost on every one of those queries: read the column, decode it, run the comparison, build the row mask, then carry on with the rest of the plan.
SQL Cache helps when the SQL text is byte-identical and gives up the moment the SELECT list shifts. Query Cache helps for aggregation queries that share whole tablets. Neither helps the case where the WHERE is shared but the SELECT list is not.
The Apache Doris Condition Cache fits between them, caching the predicate evaluation step at the segment level, separate from whatever the surrounding query does with the rows.
What is the Apache Doris Condition Cache?
The Apache Doris Condition Cache is a BE-side cache of predicate evaluation results, stored per segment as a granule-level bit vector. When a scan starts on a segment, the BE computes a 64-bit digest from the predicate expression and the segment's key range, then probes the cache. On a hit, it skips every granule whose bit is 0 and only scans the granules whose bit is 1. On a miss, it runs the predicate as usual and writes the resulting bit vector back to the cache.
The cache is independent of projections, aggregations, joins, and sort. Two queries with identical WHERE clauses share entries even when one runs SELECT * and the other runs SELECT COUNT(DISTINCT customer_id).
Key terms
enable_condition_cache: session variable. On by default; set tofalseto opt out for one query or one session.- Segment: a sealed file inside a tablet. Once written, a segment never mutates; compaction produces new segments instead. This immutability is what makes the cache safe.
- Granule: a 2048-row block inside a segment. Bit vectors store one bit per granule, not one bit per row.
- Predicate digest: a 64-bit hash of the conjunctive predicate plus the segment's key range. Semantically equivalent predicates produce the same digest.
condition_cache_limit: per-BE memory cap for the cache, in MB. Defaults to1024. Lives inbe.conf.
How does the Apache Doris Condition Cache work?
The Apache Doris Condition Cache hashes each conjunctive predicate plus the segment's key range into a 64-bit digest, looks the digest up in a per-BE LRU, and skips every granule whose stored bit is 0.
- Compile the digest (BE). When a scan operator starts on a segment, it normalizes its conjunctive predicates and the segment's key range into a 64-bit digest. Different SELECT lists, GROUP BYs, and aggregations all produce the same digest because none of those affect the predicate.
- Probe per segment. The BE looks up
(digest, segment_id)in a sharded LRU cache. If the segment carries a delete marker, or if a TopN runtime filter built the predicate at execution time, the BE skips the lookup and falls back to a normal scan. - On hit. The scan reads the bit vector, skips every granule whose bit is
0, and only decodes the columns for the granules whose bit is1. A row-level filter pass on those granules confirms the matches. - On miss. The scan evaluates the predicate normally, builds the bit vector as it goes, and writes the result back keyed on
(digest, segment_id). Subsequent queries with the same digest land on a hit. - Invalidation by immutability. Segments do not mutate. A new INSERT or compaction produces a new segment with a new ID, and the old cache entry ages out of the LRU on its own. Apache Doris does not need an explicit invalidation step.
Quick start
SET enable_condition_cache = true;
-- Run 1: misses every segment, builds bit vectors, writes them back
SELECT region, country, SUM(amount)
FROM orders
WHERE region = 'ASIA' AND order_date >= '2023-01-01'
GROUP BY region, country;
-- Run 2: different SELECT, same WHERE; hits the cache on every segment
SELECT COUNT(DISTINCT customer_id)
FROM orders
WHERE region = 'ASIA' AND order_date >= '2023-01-01';
Expected result (excerpt from EXPLAIN PROFILE on Run 2)
ConditionCacheSegmentHit: 42
ConditionCacheFilteredRows: 18,400,219
The first run scans every segment, evaluates the predicate, and writes one bit vector per segment. The second run shares the WHERE so the digest matches; every segment hits the cache, and the BE skips the granules already known to be empty for region = 'ASIA' AND order_date >= '2023-01-01'.
When should you use the Apache Doris Condition Cache?
Turn the Apache Doris Condition Cache on for read-heavy workloads where many queries reuse the same WHERE clause and the table is not under continuous write pressure.
Good fit
- Dashboards where many panels share the same
WHEREand differ only in the SELECT list or aggregation. - Application traffic that reissues the same predicate at high frequency against tables that take writes infrequently.
- T+1 reports that run different aggregations over yesterday's already-loaded partitions.
- High-selectivity filters where most granules turn into
0bits and the cache lets the scan skip large chunks of each segment.
Not a good fit
- Tables under heavy continuous write pressure. New segments mean new digests, and old cache entries age out of the LRU before they get reused. If you want shape-stable result reuse on aggregations, use Query Cache instead.
- Queries that hit segments with delete markers. The BE skips the cache to keep delete semantics correct, so workloads with frequent
DELETEtraffic rarely fire it. - Queries whose predicate is built by a TopN runtime filter at execution time. Not yet supported.
- Low-selectivity filters that match most rows. You still pay for scanning the matched granules; the cache only saves work on granules already known to be empty.
- Ad-hoc queries with one-off WHERE clauses that no other query reuses. The cache fills with entries that get one read and then evict each other. Leaving it on does no harm, but expect the hit rate to stay low.
- Lookups by primary key. Use High-Concurrency Point Query instead.
Further reading
- Condition Cache user guide
- Query Cache: pipeline-level partial aggregation cache
- SQL Cache: result-level cache for byte-identical SQL
- Caching in Doris: choosing the right strategy
- Data Cache & Page Cache: the storage-tier caches that sit below Condition Cache for the bytes and decoded pages themselves.
- Metadata Cache: the external-catalog metadata cache that complements the data-side caches.
- MPP Architecture: the execution model whose plan the condition cache hooks into to skip already-evaluated predicates.