Data Compaction
TL;DR Every load into Apache Doris produces a new immutable rowset. Apache Doris compaction merges those rowsets in the background so queries don't have to walk through hundreds of versions. Two policies (
size_basedandtime_series), plus vertical and segment compaction, let you tune the write-amplification vs. read-amplification trade-off per table.
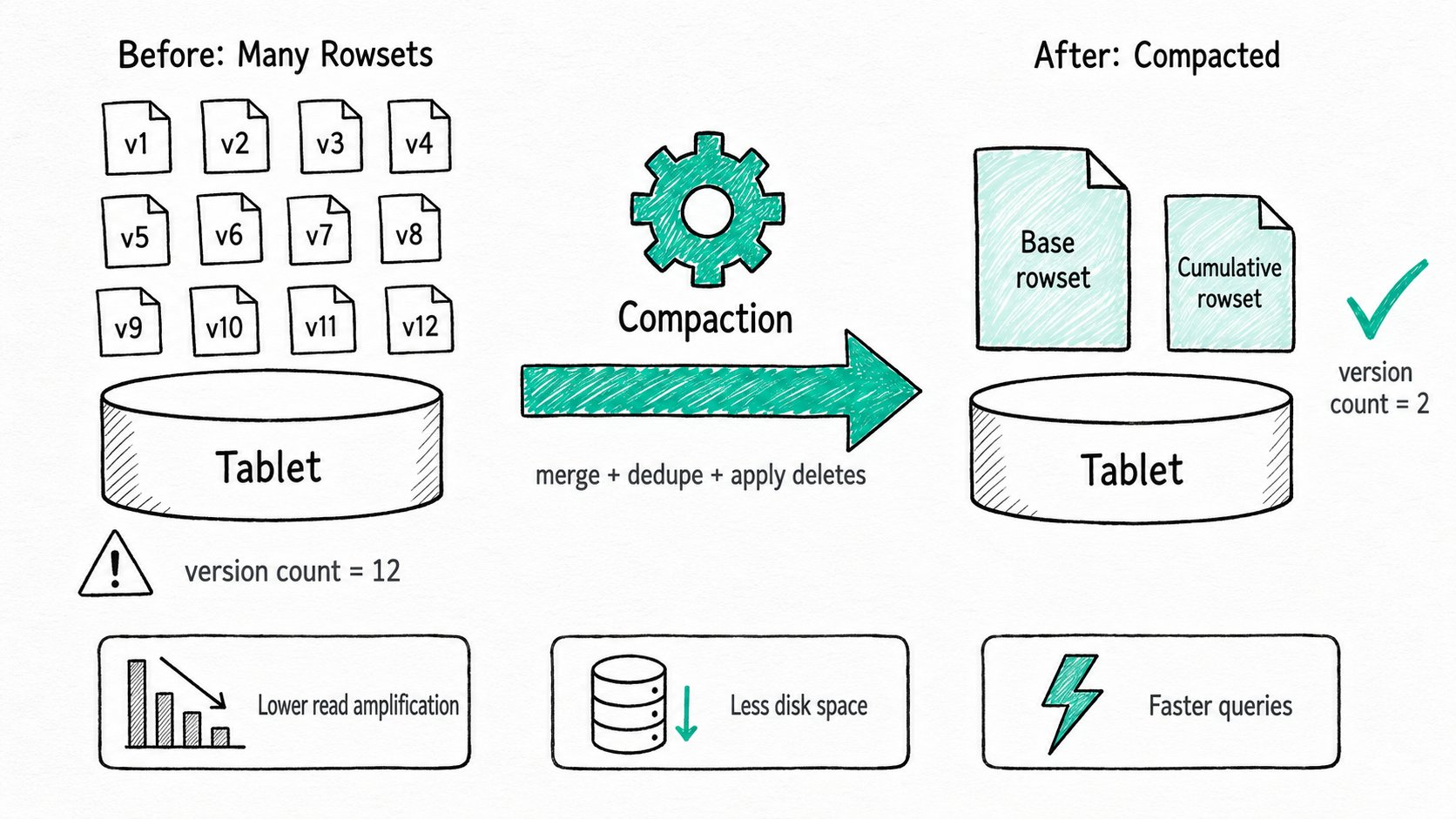
Why use Apache Doris compaction?
Apache Doris compaction keeps queries fast under high-frequency loads by merging the immutable rowsets each write produces, before the version pile-up turns into the dreaded -235 ingest failure. Apache Doris stores data the way an LSM tree does: a write never updates a file in place. It lands as a brand-new rowset, and the rowset count on a tablet keeps climbing until something cleans up. High-frequency ingest paths like Stream Load and Group Commit make that climb especially fast. Without compaction:
- Once a tablet's version count exceeds
max_tablet_version_num(default 500), loads fail with error -235. This is one of the most common production incidents on the Doris user list. - Every query has to merge all of a tablet's rowsets on the fly. Going from 5 rowsets to 50 turns a one-box lookup into a fifty-box one.
- Deleted rows linger as tombstones, and small files cost more in metadata than the data they hold.
Apache Doris compaction is the background process that handles all three. The shipped policies exist because doing it well also means not burning so much CPU that ingestion slows down.
What is Apache Doris compaction?
Apache Doris compaction is a tablet-local procedure that picks a window of rowsets, merges their rows, applies deletes, and writes a single replacement rowset. The Backend (BE) runs it on a thread pool, scoring tablets by how messy they are and grabbing the worst offenders first.
Key terms
Rowset: the immutable file group produced by one load. Rowsets are versioned; queries merge across them at read time.Cumulative compaction: the fast, frequent kind. Merges small recent rowsets above the cumulative point.Base compaction: the slow, occasional kind. Merges everything below the cumulative point into the single base rowset.Compaction score: roughly the number of merge paths a query would walk on this tablet. Higher score, higher priority.Compaction policy: per-table choice ofsize_based(default) ortime_series. Picks which rowsets to merge and when.Vertical compaction: column-group merging for wide tables. Cuts memory use by ~10x compared with row-wise merging.
How does Apache Doris compaction work?
Apache Doris compaction scores every tablet by version pressure, picks rowsets per the active policy, and merges them on a BE thread pool while the original files stay readable for in-flight queries.
- Score every tablet. The BE keeps a running compaction score for each tablet based on how many rowsets sit above the cumulative point. Tablets with higher scores get scheduled first.
- Pick the rowsets. The active policy decides the window.
size_basedgroups by power-of-two sizes;time_serieswaits until rowsets in a partition cross a goal size, file count, or age threshold, then takes them in one bite. - Merge and write. The task reads rows from the inputs, drops duplicates, applies pending deletes, and writes the result to a new rowset. Wide tables go through vertical compaction, which handles columns in groups so memory stays bounded.
- Promote to base. When a cumulative output grows past
compaction_promotion_size_mbytes(1 GB by default), it's eligible for base compaction the next round. - Replace and clean up. The output rowset replaces its inputs in tablet metadata. Old files stick around for a grace window in case a query is still reading them, then get deleted.
Quick start
CREATE TABLE access_log (
ts DATETIME, user_id BIGINT, url VARCHAR(512)
)
DUPLICATE KEY(ts, user_id)
PARTITION BY RANGE(ts) (
PARTITION p202605 VALUES LESS THAN ("2026-06-01")
)
DISTRIBUTED BY HASH(user_id) BUCKETS 4
PROPERTIES (
"compaction_policy" = "time_series",
"time_series_compaction_goal_size_mbytes" = "1024",
"time_series_compaction_file_count_threshold" = "2000",
"time_series_compaction_time_threshold_seconds" = "3600"
);
ADMIN COMPACT TABLE access_log PARTITION (p202605) WHERE TYPE = "cumulative";
Expected result
Query OK, 0 rows affected
You've created a partitioned log table that uses the time-series policy: small rowsets get merged once they cross 1 GB total, hit 2000 files, or sit for an hour. The ADMIN COMPACT line forces a manual cumulative pass on the active partition, which is useful for benchmarks and post-load cleanup. Watch progress with SELECT * FROM information_schema.doris_be_compaction_tasks WHERE TABLE_ID = ....
When should you use Apache Doris compaction?
Apache Doris compaction runs on every table by default; the real choice is which policy to set and when to override the defaults.
Good fit
- Any table that takes frequent loads. The defaults already work; the question is just whether to switch policies.
- Append-only logs and metrics.
time_seriesreduces write amplification because each rowset participates in compaction once, not repeatedly across size tiers. - Wide tables (dozens of columns or more). Keep
enable_vertical_compaction = trueso big merges don't blow up memory.
Not a good fit
- High-frequency single-row inserts as a way to "stress test compaction". You'll just create the version-pileup pain you're trying to study. Use Group Commit on the load side instead.
- Disabling auto-compaction in production to "save CPU". Tablets accumulate versions silently and then loads start failing with -235. Tune the thread counts (
max_cumu_compaction_threads,max_base_compaction_threads) instead. - Mixing the
time_seriespolicy with workloads that update or delete rows by primary key. The policy assumes append-only behavior; for Unique Key tables with frequent updates, stick withsize_based. - Treating compaction as a fix for bad bucketing. If a single tablet is hot enough to constantly trail in version count, the answer is more buckets, not more compaction threads.
Performance / numbers
- Vertical compaction: ~1/10 the memory of row-wise compaction, and roughly 15% faster on wide tables. Source: Doris compaction tuning docs.
- Compaction throughput: around 300,000 rows/second per task with the default settings, holding cumulative score near 50 under continuous load. Source: Understanding Data Compaction in 3 Minutes.
Further reading
- Vertical Compaction: column-group merging that cuts compaction memory by about 10x and speeds up wide-table merges by roughly 15%.
- Compaction principles, types, and scheduling
- Compaction tuning: vertical, segment, single-replica, time-series
ADMIN COMPACT TABLEsyntax reference- Understanding Data Compaction in 3 Minutes (blog)
- Unique Key: the table model where compaction reclaims rows marked in the per-rowset delete bitmap.