Data Pruning
TL;DR Apache Doris data pruning means a query never really scans a table — it scans whatever survives a stack of pruning layers. Partition keys, distribution keys, ZoneMap min/max statistics, BloomFilter and NGram BloomFilter indexes each peel off another layer of data the engine doesn't have to read. Most of the win is automatic; the operator controls it through DDL choices and verifies it in EXPLAIN output.
Why use data pruning in Apache Doris?
Apache Doris data pruning lets a query skip most of the table before reading it, turning multi-terabyte scans into reads of a few partitions or tablets. The fastest way to make an OLAP query faster is to read less. A wide events table at 50 GB per day stretches into petabytes over a year, and most queries care about a sliver: one day, one user, one product. Without pruning, the planner fans the query out across every partition and every tablet, and the executor walks every page from disk to evaluate WHERE.
This shows up as three concrete pains:
- A
WHERE date BETWEEN '2026-04-01' AND '2026-04-07'query against a 365-partition table touches every partition until the planner is told it can skip them. - Hash-distributed point lookups (
WHERE user_id = 12345) become full-tablet scans when the optimizer can't tie the predicate to the bucket key. - High-cardinality filters on non-key columns (
WHERE phone = '...') read every segment because there's no statistic to rule pages out.
Apache Doris addresses each of these with a different pruning layer, and the layers compose: the planner trims partitions and tablets before the scan starts, then the BE skips segments and pages inside whatever survived.
What is Apache Doris data pruning?
Apache Doris data pruning is the cumulative result of every step in the read path that lets the engine skip data without reading it, spanning partitions, tablets, segments, and column pages. The Frontend planner does the coarse work using table metadata: partitions and tablets. The Backend does the fine work during scan: ZoneMap min/max, BloomFilter, NGram BloomFilter, and the inverted index decide whether a segment, a column page, or even a row range can be skipped.
Key terms
Partition pruning: the planner uses range or list predicates on the partition key to drop irrelevant partitions before any tablet is scheduled.Bucket (tablet) pruning: equality predicates on theDISTRIBUTED BY HASHkey let the planner pick only the buckets that could contain the row.ZoneMap index: per-segment, per-page min/max/null statistics, built automatically on every column. Range predicates use it to skip pages.BloomFilter index: opt-in per-column probabilistic filter, useful for high-cardinality equality andINpredicates.NGram BloomFilter: opt-in index that turns substringLIKE '%abc%'predicates into bloom probes on n-grams.Runtime filter: a join-time filter generated from one side of a join and pushed down to prune the other side.
How does Apache Doris data pruning work?
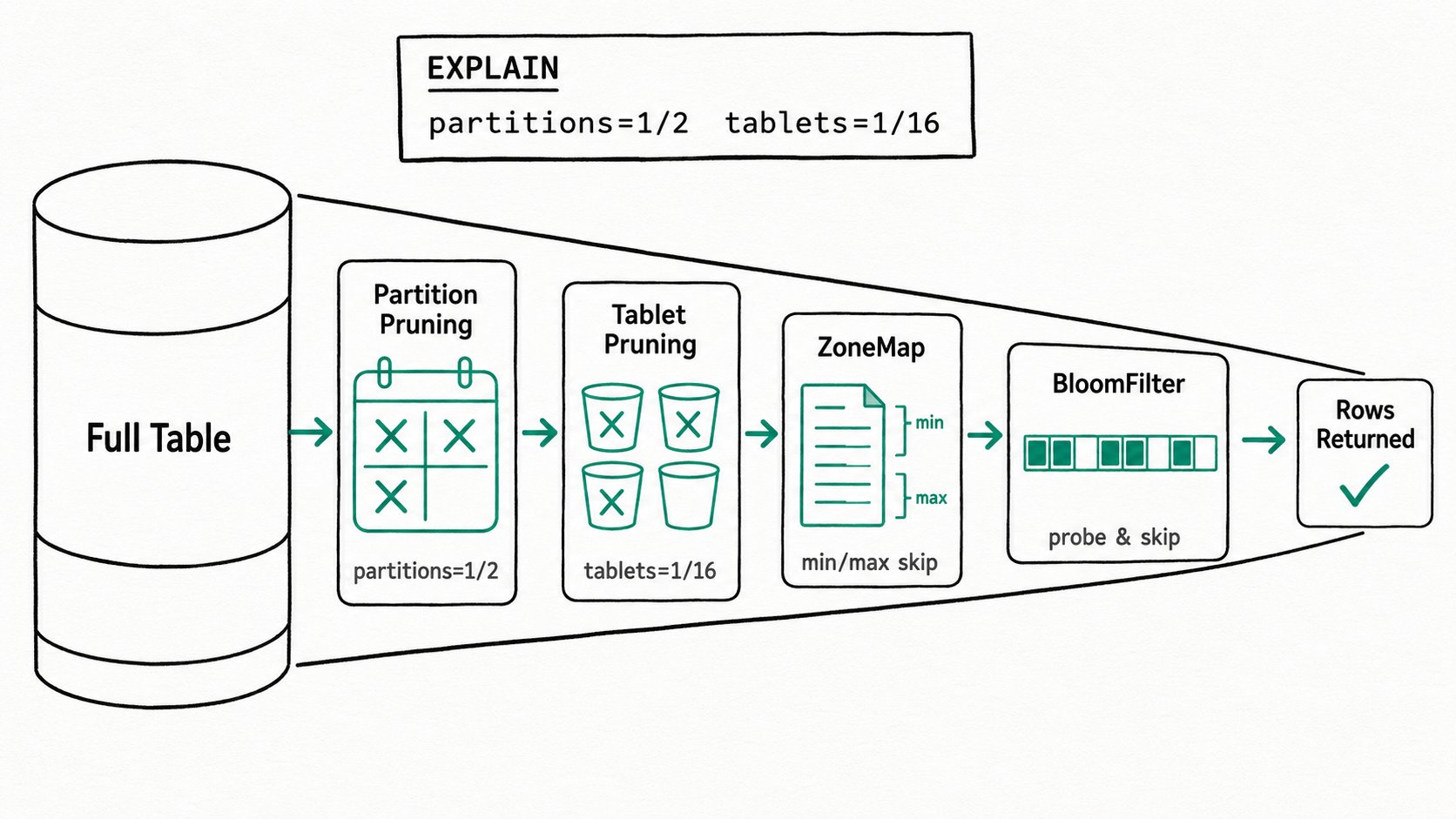
Apache Doris data pruning works in five top-down layers — partition, tablet, segment/page, index probe, and runtime filter — with each layer shrinking the input the next layer has to consider.
- Partition pruning (FE). The Nereids planner runs
PruneOlapScanPartition, matchesWHEREpredicates against the table's range or list partition tree, and produces the surviving set. EXPLAIN shows it aspartitions=2/4 (p2,p3). - Tablet pruning (FE).
PruneOlapScanTabletextracts equality predicates on the bucketing column and asksHashDistributionPrunerwhich buckets they hash to. EXPLAIN showstablets=1/32. - Segment / page pruning (BE). For each surviving tablet, the segment iterator opens column readers and consults the ZoneMap index. If
[min, max]doesn't overlap the predicate, the page is dropped without decompressing. - Index probes (BE). BloomFilter, NGram BloomFilter, and inverted indexes run before row decoding. A miss skips the page; a hit doesn't promise rows match, only that they might.
- Runtime filters (FE/BE). Joins generate filters from the build side (for example,
IN (A.id_set)) and broadcast them so the probe-side scan reuses the same pruning machinery on the fly.
By the time the predicate evaluator runs, most of the table has already been ruled out without being read.
Quick start
CREATE TABLE events (
ts DATETIME, user_id BIGINT, action VARCHAR(64)
)
DUPLICATE KEY(ts, user_id)
PARTITION BY RANGE(ts) (
PARTITION p202604 VALUES LESS THAN ("2026-05-01"),
PARTITION p202605 VALUES LESS THAN ("2026-06-01")
)
DISTRIBUTED BY HASH(user_id) BUCKETS 16
PROPERTIES ("bloom_filter_columns" = "action");
EXPLAIN
SELECT count(*) FROM events
WHERE ts >= '2026-05-08' AND user_id = 42 AND action = 'click';
Expected result (excerpt)
0:VOlapScanNode
TABLE: events
PREDICATES: ts >= '2026-05-08', user_id = 42, action = 'click'
partitions=1/2 (p202605)
tablets=1/16
The planner kept one partition out of two (date range) and one tablet out of sixteen (hash on user_id). At read time, the BE will use ZoneMap on ts plus the BloomFilter on action to skip pages inside that surviving tablet. Four pruning layers handle three predicates without any manual tuning.
When should you use Apache Doris data pruning?
Apache Doris data pruning is always on — the question is which layers your DDL and predicates actually activate. Time-bounded analytical queries, high-concurrency point lookups, substring search on long text columns, and star-schema joins benefit the most; misapplied BloomFilters and catch-all partitions are the common anti-patterns.
Good fit
- Time-bounded analytical queries on partitioned tables. The latency curve flattens once the date predicate makes it into the planner's hands.
- High-concurrency point lookups on hash-distributed tables. Pair the bucket key with the most common equality predicate.
- Substring search on long text columns. Add an NGram BloomFilter and let
LIKE '%...%'become a bloom probe instead of a column scan. - Star-schema joins. Runtime filters propagate the small-side keys to the fact-table scan.
Not a good fit
- BloomFilter on low-cardinality columns (status flags, gender). The filter accepts almost every page anyway and you pay storage for nothing. Use ZoneMap, which is built in, or skip the index entirely.
- BloomFilter on range predicates. Bloom answers "is X in the set?", not "is X less than Y." Range filters fall back to ZoneMap.
- Bucketing on a column you don't filter on. You'll pay for hash distribution at write time and gain no read-side pruning. Pick a bucket key that matches your most selective equality predicate.
- One giant catch-all partition. Nothing for the planner to drop, and tablet/segment pruning has to compensate alone. Partition by the column queries actually filter on, usually time.
- Treating BloomFilter as a substitute for full-text search. For phrase or token search use the inverted index; BloomFilter only handles equality.
Further reading
- Partition pruning optimization
- Index overview: skip indexes
- BloomFilter index
- NGram BloomFilter index
- Partitioning and Bucketing: the DDL choices that decide which partitions and tablets the planner can prune in the first place.
- Inverted Index: the index-probe layer that turns text and high-cardinality equality predicates into posting-list lookups.
- Deep dive: Data Pruning in Apache Doris (blog)
- MPP Architecture: where pruning runs — partition/bucket prune happens in the Nereids planner before fragments ship.