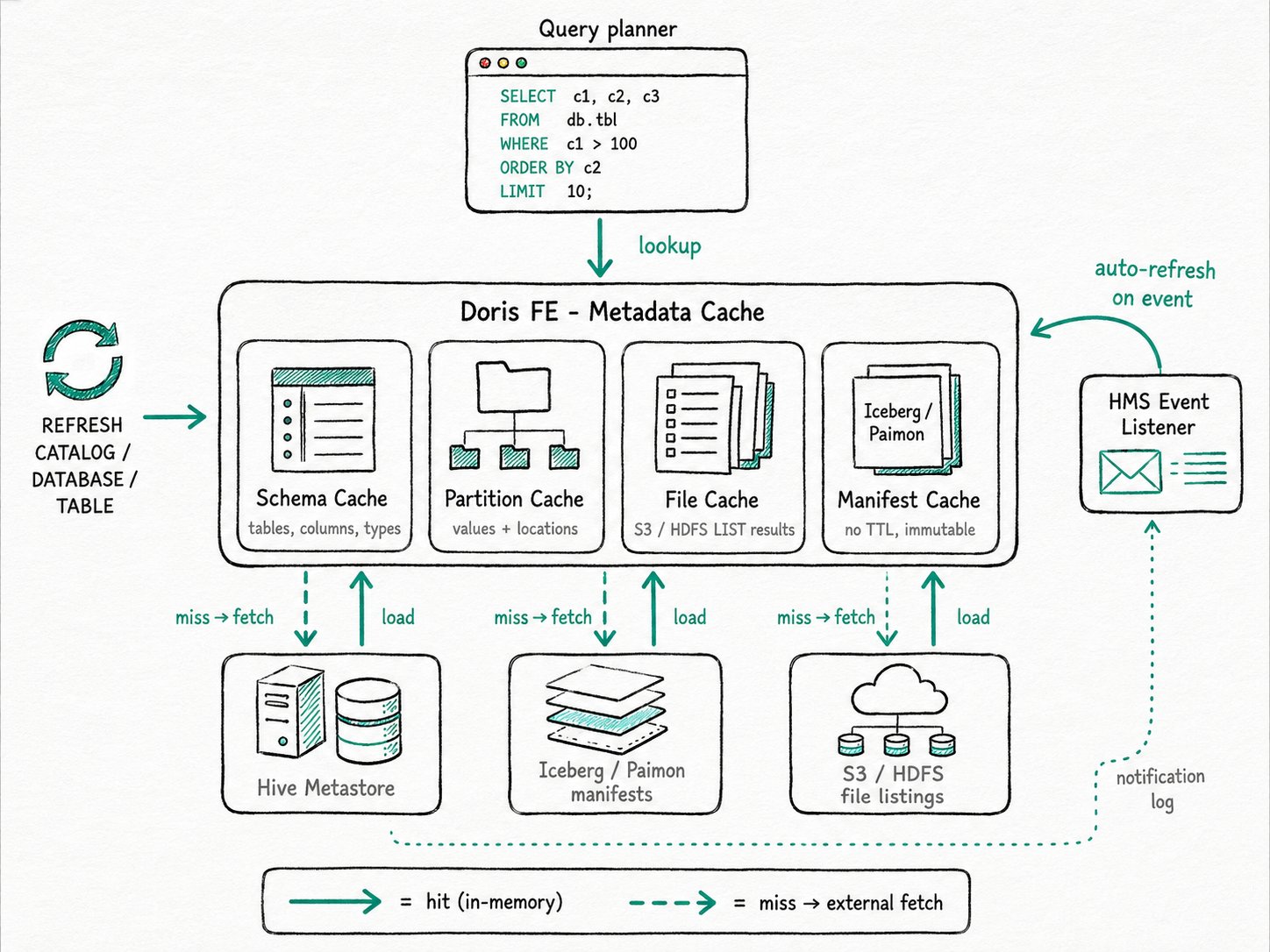
Metadata Cache
TL;DR When Apache Doris queries Hive, Iceberg, Hudi, or Paimon, most of the wall clock can be spent listing partitions, parsing manifests, and asking the Hive Metastore questions. The Apache Doris metadata cache holds all of it: schemas, partition values, file listings, Iceberg manifest entries, Paimon snapshots. Caches are TTL-bounded (defaults: 24 hours for name lists, 8 hours for partitions and files), can refresh from Hive Metastore events for seconds-level lag, and can be invalidated explicitly with
REFRESH CATALOG. Iceberg and Paimon get format-aware invalidation, so immutable manifests stay cached as long as they're still referenced.
Why use the Apache Doris metadata cache?
The Apache Doris metadata cache cuts lakehouse query planning from seconds to milliseconds by absorbing the HMS round-trips, S3/HDFS LISTs, and Iceberg manifest reads that otherwise dominate the wall clock. Lakehouse query planning is dominated by metadata, not by data. A query against a partitioned Hive table needs to:
- Round-trip the Hive Metastore for the database list, table list, column schema, and partition list.
- Issue an S3 or HDFS LIST against each surviving partition path to discover the data files.
- For Iceberg, read
metadata.json, then a manifest list, then N manifest files (one remote read each). - For Hudi, fetch the timeline, build a
FileSystemView, and resolve which file slices are visible at the query timestamp.
A cold catalog with 10K partitions can spend longer in planning than in execution. Common shapes of this:
- A dashboard that filters by date hits the planner with a fresh partition lookup every minute, hammering HMS until it falls over.
- An Iceberg table with 30 manifests pays 30 S3 GETs of manifest metadata per query, on top of the data reads.
- A new FE comes up after a deploy, and the first round of queries spend seconds in
getPartitionsByNames.
Metadata Cache absorbs all of these, with refresh paths that recover correctness whenever the source actually changes.
What is the Apache Doris metadata cache?
The Apache Doris metadata cache is an in-memory cache on the FE for everything an external catalog can tell you, short of the file bytes themselves. Each backend (Hive, Iceberg, Hudi, Paimon, JDBC) has its own implementation of a shared framework, so the user-facing model is consistent: per-cache TTL, per-cache size limit, and a small set of refresh primitives.
Key terms
Schema cache: column lists, types, and table identities. Keyed by table identifier and (for Iceberg/Paimon) schema ID.Partition cache: the partition list of a Hive or Hudi table, including partition values and locations.File cache (FE-side): the file listing and basic file metadata for a partition path, populated by an S3/HDFS LIST. Distinct from the BE-side Data Cache.Manifest cache: parsed Iceberg manifest entries (lists of data and delete files for a manifest). Bounded by entry count, not TTL.HMS event listener: a polling client that consumes Hive Metastore notification events and incrementally invalidates affected entries.
How does the Apache Doris metadata cache work?
Every Apache Doris query traverses the cache before issuing any external RPC: lookup, TTL eviction, size eviction, format-aware invalidation, HMS event polling, and explicit REFRESH together keep the hot metadata in memory and stale entries out.
- Lookup. When the planner asks for a table's schema, partitions, or files, the cache is checked first using a Caffeine-backed loader. A miss triggers a fetch from the underlying catalog (HMS Thrift call, Iceberg metadata read, Hudi timeline scan) and the result is stored.
- TTL eviction. Each cache module has its own TTL. After 3.0.7, the timer resets on every access, so a hot table stays cached as long as it's queried. Defaults are conservative: name lists at 24 hours with a 10-minute refresh, partition and file caches at 8 hours.
- Size eviction. Caches use LRU under a size cap (
max_external_schema_cache_num,max_external_file_cache_num, etc.) so a long tail of cold tables can't displace the hot ones forever. - Format-aware invalidation. Iceberg manifest cache entries are keyed by manifest path and live without a TTL: once a manifest is parsed, it's correct as long as some snapshot still references it. Paimon caches the latest snapshot reference and reloads only when the table moves forward. Hive does not have this luxury, so HMS events fill the gap.
- HMS event-based refresh. When
enable_hms_events_incremental_syncis on, the FE polls the Hive Metastore notification log everyhms_events_polling_interval_msand replays CREATE / ALTER / DROP / INSERT events. Affected entries are invalidated within seconds, without a global flush. - Explicit refresh.
REFRESH CATALOG,REFRESH DATABASE, andREFRESH TABLEprovide the escape hatch for writes that don't go through HMS (direct file uploads, Iceberg commits from outside Apache Doris) and for testing.
The common path serves metadata at memory latency. The recovery path catches up in seconds when the source moves.
Quick start
-- Inspect cache state.
SELECT * FROM information_schema.catalog_meta_cache_statistics
WHERE catalog_name = 'hive_ctl';
-- Refresh just the table whose partition you just added.
REFRESH TABLE hive_ctl.sales.orders;
-- For a fast-changing fact table, disable the file listing cache.
ALTER CATALOG hive_ctl SET PROPERTIES (
"meta.cache.hive.file.ttl-second" = "0"
);
-- For seconds-level auto-refresh on Hive, turn on the HMS event listener
-- (FE config; restart required):
-- enable_hms_events_incremental_sync = true
-- hms_events_polling_interval_ms = 10000
Expected result
+--------------+-------------+-----------+---------+----------+
| catalog_name | cache_name | hit_count | miss_count | size |
+--------------+-------------+-----------+---------+----------+
| hive_ctl | schema | 12480 | 7 | 42 |
| hive_ctl | partition | 9821 | 14 | 28 |
| hive_ctl | file | 9520 | 31 | 612 |
+--------------+-------------+-----------+---------+----------+
After warmup, hit rates are above 99% on the schema and partition caches. Misses correspond to the first access of new tables or to entries that aged out.
When should you use the Apache Doris metadata cache?
The Apache Doris metadata cache is on by default for every external catalog; the practical question is how to tune it for each workload shape, and where to disable it entirely.
Good fit
- Hive tables with stable schemas and a moderate write rate. Pair the default TTLs with the HMS event listener for seconds-level freshness.
- Iceberg, Paimon, and Hudi tables of any size. Snapshot immutability lets the cache hold manifest entries indefinitely; the only thing that needs invalidating is the current snapshot pointer, which Apache Doris does on every query.
- Multi-tenant lakehouse with thousands of catalogs and tables. Schema and partition caches keep planning fast even when the long tail of objects exceeds memory: hot ones stay, cold ones get evicted.
- High-concurrency dashboards. Without a cache, every concurrent query would re-list the same partitions; with one, the listing is computed once and shared.
Not a good fit
- Hive tables that are written outside HMS (
hadoop fs -put, raw S3 uploads). HMS never sees the change, so the event listener won't pick it up. Either route writes through HMS, set the file cache TTL to 0, or callREFRESH TABLEafter each batch. - Tables that change every few seconds and demand strong freshness. A TTL-based cache is the wrong tool. Disable the relevant cache module (
ttl-second = 0) for that table, or accept up-to-N-second staleness from the event listener. - Catalogs that contain millions of tables when memory is tight. Bumping
max_external_schema_cache_numpast your FE heap can cause OOMs. Right-size the limit and keep an eye oncatalog_meta_cache_statistics. - Treating Iceberg like Hive. Aggressively running
REFRESH CATALOGon Iceberg every minute throws away perfectly valid immutable manifest entries. Trust the snapshot model and let the cache do its job.
Further reading
- Metadata Cache reference: module-by-module breakdown of TTLs, size limits, and refresh strategies.
- REFRESH statement: the SQL surface for
REFRESH CATALOG,REFRESH DATABASE, andREFRESH TABLE, plus theinvalid_cacheproperty. - Hive catalog: per-cache
meta.cache.*properties and the HMS event listener configuration (enable_hms_events_incremental_sync). - Iceberg catalog: manifest cache configuration and snapshot-aware invalidation.
- Data Cache & Page Cache: the byte-level storage caches that sit beneath the metadata cache.
- Parquet Reader Optimization: once metadata says which files to read, this is what reads them efficiently.
- Building the next-generation data lakehouse (Apache Doris blog): the architectural overview that introduces the Meta Cache and HMS event listener.
- Iceberg: the catalog whose manifest list and snapshot metadata benefit most from the metadata cache on remote object stores.