Partitioning and Bucketing
TL;DR Every Apache Doris table is split twice: a
PARTITION BYclause carves rows by a column value (usually a date), and aDISTRIBUTED BYclause shards each partition into N tablets. Partitions give the planner something coarse to drop and the operator something to archive; buckets give the cluster something parallel to scan and write. Pick the date column queries filter on for the partition key, pick a high-cardinality equality column for the bucket key, and letBUCKETS AUTOsize the rest.
Why use partitioning and bucketing in Apache Doris?
Apache Doris partitioning and bucketing solve the three problems that show up once a table outgrows one machine: queries that scan everything, single-tablet tables that pin one BE, and deletions that drag on for hours.
- A
WHERE date BETWEEN '2026-04-01' AND '2026-04-07'query on a 365-day events table reads every row of every day until the planner is told it can skip the other 358. - A 4 TB table loaded into one tablet pins one BE to 100% CPU and leaves the other nine idle. The cluster has parallelism; the table does not expose it.
- Dropping last quarter's data turns into a multi-hour
DELETEjob instead of a metadata change.
Partitioning solves the first and third. Bucketing solves the second. Between them, they decide where each row lives and which BEs touch it at query time.
What are Apache Doris partitioning and bucketing?
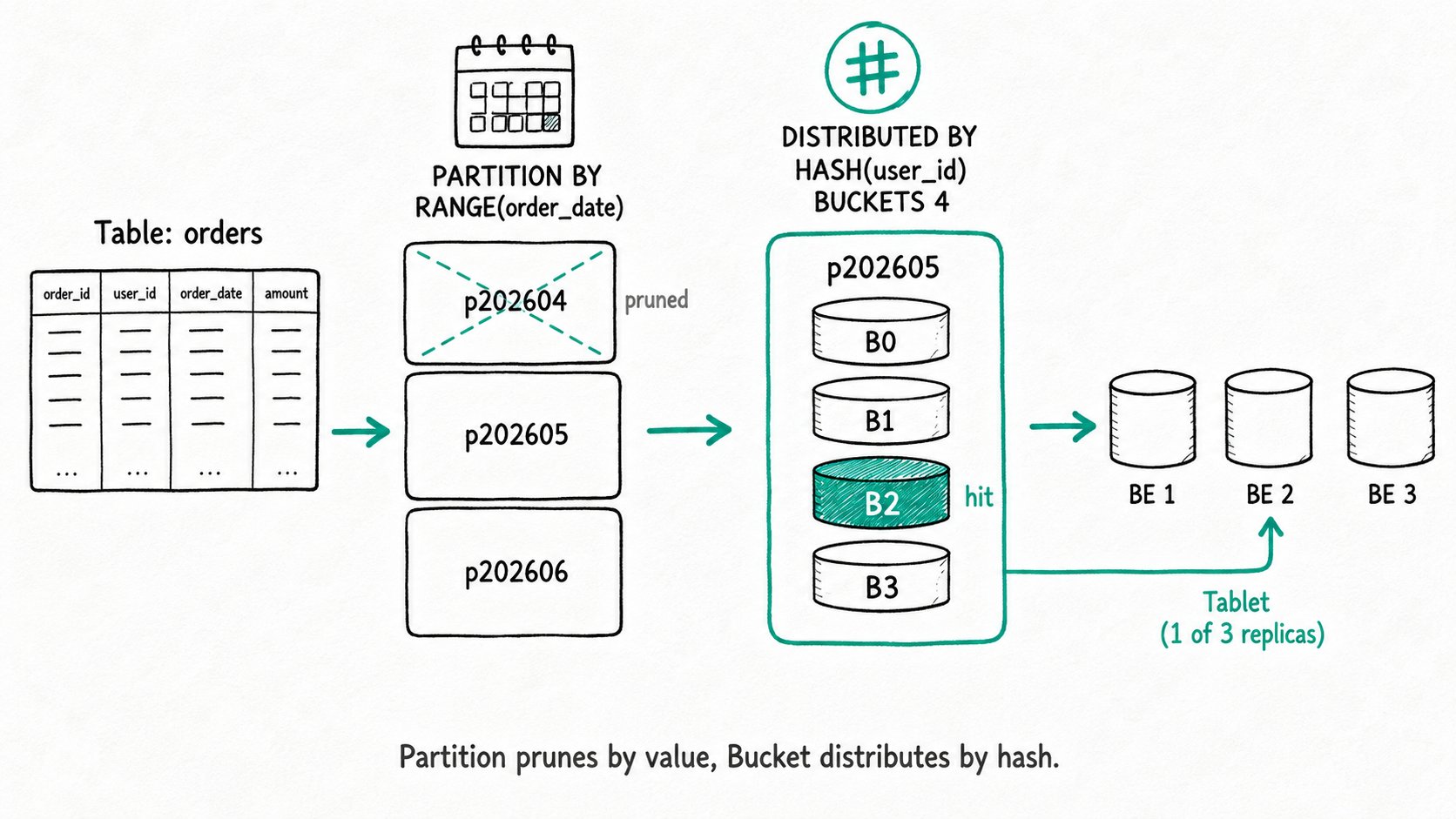
Apache Doris partitioning and bucketing are the two-level physical layout for every table. The PARTITION BY clause divides the table into disjoint subsets by a column value (Range or List), and DISTRIBUTED BY further shards each partition into a fixed number of tablets, the unit of replication and parallelism. A row first finds its partition by value, then its tablet by hash (or random assignment).
Key terms
Partition: a subset of rows defined by a Range or List on one or more KEY columns. The unit of pruning, archival, and TTL.Bucket: a hash- or randomly-assigned slice of a partition. Each bucket maps to one tablet per replica.Tablet: the physical data shard. The unit of replication, scheduling, and parallelism inside a BE.PARTITION BY RANGE / LIST: explicit partitioning declared in DDL. Range fits time and numeric ranges; List fits enumerated dimensions like region or tenant.AUTO PARTITION: partitions created on demand at write time, bydate_trunc(col, 'month')for ranges or by enumerated value for lists. Replaces the static partition list.DISTRIBUTED BY HASH(col) BUCKETS N: hash-distributed shards.crc32(col) % Npicks the bucket; equality predicates oncolenable bucket pruning.DISTRIBUTED BY RANDOM BUCKETS N: rows scattered across buckets without a key. Avoids skew, but no bucket pruning. Duplicate-Key tables only.BUCKETS AUTO: the FE picks the bucket count fromestimate_partition_size, BE count, and disk count. Set per partition.
How do Apache Doris partitioning and bucketing work?
Apache Doris partitioning and bucketing together route a row's path from INSERT to disk through two layers, partition selection and tablet selection.
- Map the row to a partition. The planner evaluates the partition expression. Range partitions binary-search a sorted interval list; List partitions look up the value in a hash map. Auto Partition creates the partition on the fly if none matches.
- Map the row to a bucket. Hash distribution computes
crc32(bucket_cols) % bucket_num; random distribution picks a tablet round-robin (or sticks the whole batch on one tablet whenload_to_single_tablet = true). - Write to that tablet's replicas. Each tablet has N replicas (default 3) on different BEs. The Coordinator streams the row to all of them.
- Prune at query time (FE).
PruneOlapScanPartitionmatchesWHEREpredicates against the partition tree;PruneOlapScanTabletextracts equality predicates on the bucket key and asksHashDistributionPrunerwhich buckets they hash to. EXPLAIN shows the survivors aspartitions=1/365andtablets=1/32. - Scan the survivors in parallel (BE). Each surviving tablet is a parallel scan unit. The pipeline engine fans them out across BE cores, so a query that touches 16 tablets on 4 BEs runs 16-way parallel without any session tuning.
The hierarchy on disk reads Table → Partition → Tablet → Rowset → Segment. Compaction and replication operate at the tablet level, so the partition and bucket numbers govern both query parallelism and operational cost. See Data Pruning for the layered pruning chain that runs after the planner picks the surviving partitions and tablets.
Quick start
CREATE TABLE orders (
order_id BIGINT,
user_id BIGINT,
order_date DATE NOT NULL,
amount DECIMAL(10,2)
)
DUPLICATE KEY(order_id, user_id)
AUTO PARTITION BY RANGE (date_trunc(order_date, 'month')) ()
DISTRIBUTED BY HASH(user_id) BUCKETS 16;
INSERT INTO orders VALUES
(1, 100, '2026-04-15', 99.00),
(2, 200, '2026-05-02', 50.00);
EXPLAIN SELECT SUM(amount) FROM orders
WHERE order_date >= '2026-05-01' AND user_id = 200;
Expected result (excerpt)
0:VOlapScanNode
TABLE: orders
PREDICATES: order_date >= '2026-05-01', user_id = 200
partitions=1/2 (p20260501000000)
tablets=1/16
Two months of data produced two partitions automatically. The planner kept one of those partitions on the date predicate, and one tablet out of sixteen on the user_id equality, so the query reads 1/32 of the table. Writes spread across all sixteen tablets, so a single load uses sixteen BE workers in parallel.
When should you use Apache Doris partitioning and bucketing?
Apache Doris partitioning fits time-series and enumerated-dimension tables that need pruning or archival; bucketing fits any table large enough that one tablet cannot keep up with scans or writes.
Good fit
- Time-series fact tables (events, orders, logs). Range or Auto Range on the timestamp lets the planner skip almost every partition for a typical dashboard query, and dropping a month is a metadata change.
- High-concurrency point queries on
user_id,device_id, or any other high-cardinality equality column. Hash bucket on that column and a single query touches one tablet. - Multi-tenant or per-region tables with a stable enumerated dimension. List partition by tenant, then offboard a tenant by dropping its partition.
- Tables loaded incrementally where you cannot predict the value range.
AUTO PARTITION BY RANGE(date_trunc(...))creates partitions on first write, so you skip the partition-management DDL entirely. - Wide-fanout joins between two large tables on the same key. Match the bucket key on both tables and enable Colocate Join to skip the shuffle.
Not a good fit
- Partitioning by a low-cardinality column queries don't filter on (a status flag, a country with 5 values). The planner has nothing to drop and you pay metadata for partitions you never skip.
- Bucketing on a column you don't filter on. You pay the hash cost at write time and gain no pruning. Pick the most selective equality predicate, or use
RANDOMif there isn't one. - Bucketing on a low-cardinality column (say,
gender). Two values cannot fan out to 16 buckets; you get hot tablets and cold ones. Pick a high-cardinality column, or combine columns into the bucket key. - Hundreds of buckets per partition. The doc cap is 128 per partition; beyond that, write throughput drops and the FE memory bill climbs (rule of thumb: 100 GB FE memory per 10 million tablets). Partition first, then bucket.
- Tiny tablets in the megabytes. Each tablet costs FE metadata and a compaction loop. Aim for 1 GB to 10 GB compressed per tablet (Unique-Key tables stay under 10 GB).
- Random bucketing on Unique or Aggregate tables. Random distribution breaks merge correctness; only Duplicate tables accept it.
Further reading
- Basic Concepts: Partition + Bucket walkthrough with diagrams
- Manual Partitioning: Range, List, and the four Range forms
- Auto Partitioning: on-demand partition creation at write time
- Data Bucketing: choosing the method, the key, and the bucket count
- Data Pruning: the layered pruning chain that runs after partition and tablet selection
ALTER TABLE PARTITIONreference- MPP Architecture: Bucket Shuffle and Colocate Join read the bucket layout you choose here to avoid network shuffles.
- Unique Key: the table model where partition columns must be a subset of the unique key — otherwise dedup breaks.