Query Cache
TL;DR The Apache Doris Query Cache is a pipeline-engine cache for aggregation queries on internal OLAP tables. The Query Cache stores partial aggregation results at tablet granularity, keyed by a digest of the plan plus the tablet ID and version. Two queries that share a tablet share the cache for that tablet, even when their date ranges only partly overlap — so a dashboard that polls the same
GROUP BYevery 15 seconds stops re-scanning the same tablets every refresh.
Why use the Apache Doris Query Cache?
The Apache Doris Query Cache eliminates the redundant tablet-level work that BI dashboards generate when the same aggregation runs against overlapping partitions every few seconds. Most BI traffic is repetitive aggregation. A dashboard tile re-runs the same SUM/COUNT/AVG every refresh. A T+1 report aggregates last night's partition once, then re-aggregates it every time someone opens the page today. A trader's panel polls the same GROUP BY symbol every five seconds against an order book that only changes a few tablets per minute.
The same tablet contributes the same partial aggregate again and again, and the cluster pays the full scan and aggregation cost every time.
SQL Cache helps when the SQL text is byte-identical, but it gives up as soon as a single filter shifts or one tablet gets a new version. A materialized view fixes the shape, but it commits you to maintaining the view and its refresh schedule.
Query Cache works at a smaller grain than either of those: the contribution of one tablet to one aggregation. That is the level at which dashboard refreshes actually overlap, where filter ranges slide a day forward and only one or two partitions are new per refresh.
What is the Apache Doris Query Cache?
The Apache Doris Query Cache is a pipeline-engine optimization that activates when a fragment matches the shape AggregationNode -> OlapScanNode, or AggregationNode -> AggregationNode -> OlapScanNode for two-stage aggregation. Filter and project nodes are allowed in between. Joins, sorts, unions, window functions, and exchange nodes are not. When a fragment qualifies, the BE checks the cache before scanning. On a hit, the scan range is skipped and the cached blocks are emitted directly. On a miss, the result is computed normally and written back, one entry per tablet.
Key terms
enable_query_cache: session variable. Off by default; turn it on per session, or set globally for dashboard accounts.CacheSourceOperator: pipeline operator inserted between the aggregation and the scan. Its profile section reportsHitCache,InsertCache, andCacheTabletIdper tablet.SQL digest: a SHA-256 over the normalized aggregation plan (functions, group keys, non-partition predicates, projected columns, and result-affecting session variables). Semantically equivalent SQL produces the same digest.Tablet range: derived from partition predicates. Included in the cache key so two queries can reuse the cache for partitions they have in common.LRU-K (K=2): admission policy. A new entry has to be touched at least twice before it earns a slot, so a one-off ad-hoc query cannot evict the entries that the dashboards depend on.
How does the Apache Doris Query Cache work?
The Apache Doris Query Cache works by detecting the agg-over-scan pattern in the FE, building a per-tablet cache key from the plan digest plus the tablet ID and version, and probing the cache before each BE scans. The five-step flow below covers plan check, key construction, probe, hit, and miss.
- Plan check (FE). Nereids walks each fragment looking for the agg-over-scan pattern. Joins, sorts, runtime-filter targets, external table scans, and non-deterministic expressions disqualify the fragment.
- Build the cache key (FE). For single-column RANGE partitioned tables, the planner extracts partition predicates and computes the intersection of the predicate range with each scanned partition. The plan digest covers the rest of the query. The per-tablet key is
(digest, tablet_id, tablet_range). - Probe per tablet (BE). For each assigned tablet,
QueryCache::lookup(key, version)checks both the cache key and the tablet's version. AnyINSERT,DELETE,UPDATE, or compaction since the entry was written counts as a miss. - On hit. The scan operator skips the range, the agg operator produces nothing, and
CacheSourceOperatoremits the cached blocks. If the projection order differs from the cached entry (SELECT a, bvsSELECT b, awith the same digest), columns are reordered automatically. - On miss. The fragment computes its partial aggregate, sends rows downstream as usual, and buffers a copy. After the fragment finishes, results within
query_cache_entry_max_bytes(5 MB) andquery_cache_entry_max_rows(500,000) are written to the cache.
Quick start
SET enable_query_cache = true;
-- Run 1: warms the cache for partitions 2024-01-01 .. 2024-01-07
SELECT region, SUM(revenue), COUNT(*)
FROM orders
WHERE dt >= '2024-01-01' AND dt < '2024-01-08'
GROUP BY region;
-- Run 2: overlapping window, three shared days
SELECT region, SUM(revenue), COUNT(*)
FROM orders
WHERE dt >= '2024-01-05' AND dt < '2024-01-12'
GROUP BY region;
Expected result (excerpt from EXPLAIN PROFILE)
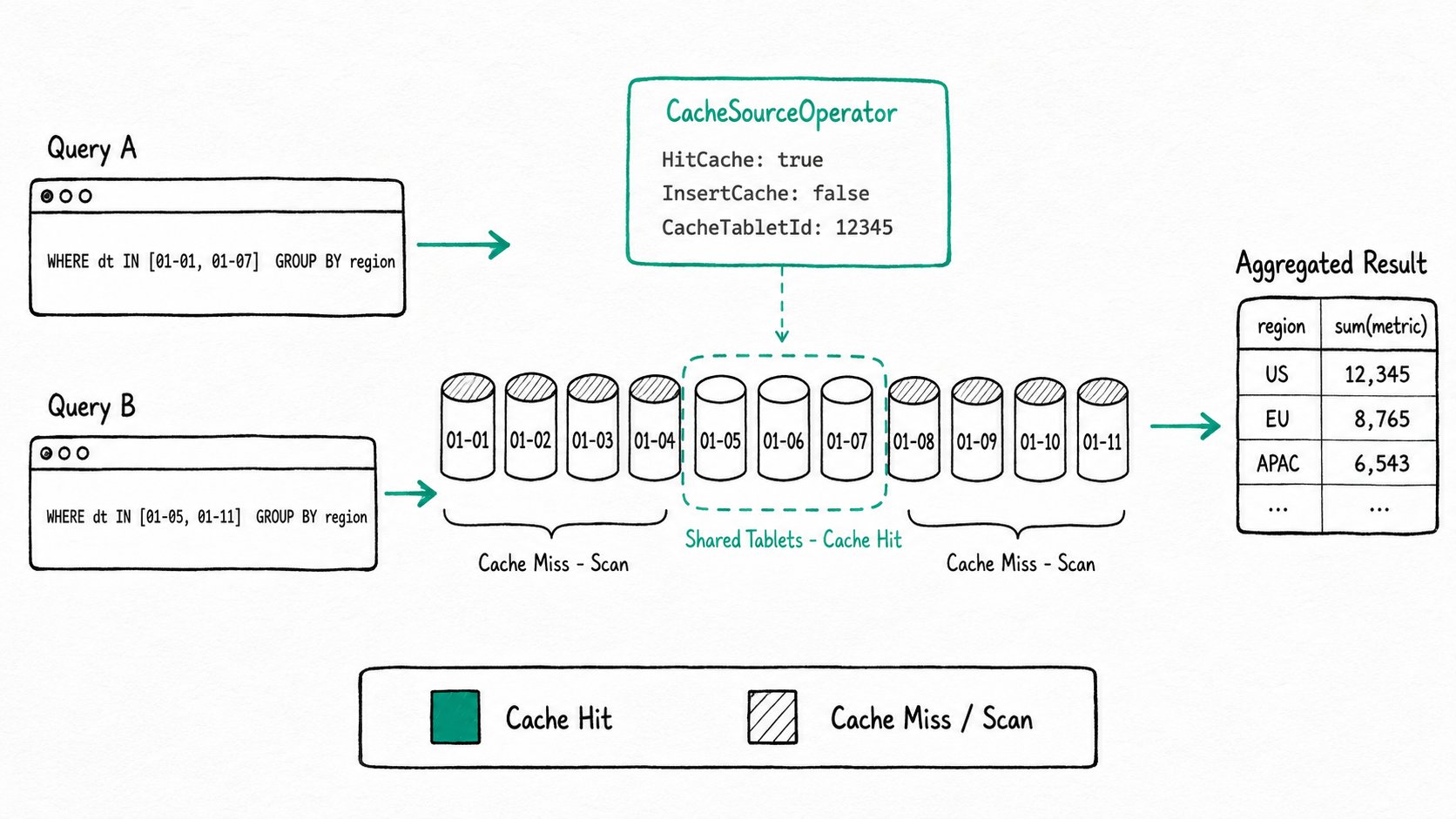
CacheSourceOperator
HitCache: true
InsertCache: false
CacheTabletId: 12345
The first run misses every tablet and writes per-tablet partial aggregates. The second run hits the cache for the three overlapping days (2024-01-05 through 2024-01-07) and only scans the new days (2024-01-08 through 2024-01-11). To confirm a hit, look at CacheSourceOperator in the profile: a per-tablet HitCache: true means that tablet was served from memory.
When should you use the Apache Doris Query Cache?
Use the Apache Doris Query Cache for BI dashboards, T+1 reports, and rolling-window aggregations on internal single-column RANGE partitioned tables. Avoid it for JOIN/ORDER/UNION/window queries, external lakehouse tables (use SQL Cache instead), high-write hot tables, and primary-key lookups.
Good fit
- BI dashboards and tile widgets that repeat the same aggregation many times per minute.
- T+1 reports. Once the day's load finishes, repeat reads serve from the cache until tomorrow's load invalidates the new partition.
- Aggregation queries with rolling date windows where only the most recent partition changes between refreshes.
- Single-column
RANGEpartitioned tables. These are the shape that earns tablet-level reuse across different filter ranges.
Not a good fit
- Queries with
JOIN,ORDER BY,UNION, or window functions in the cached subtree. Aggregate first and then join, or build an async materialized view for the join shape. - External tables (Hive, Iceberg, Hudi, Paimon, JDBC). The cache keys on tablet ID and version, which external tables do not have. Use SQL Cache instead.
- Hot tables that take writes every few seconds. Each version bump invalidates the relevant tablet entry, so the hit rate stays low. If filter reuse is what you actually need, look at Condition Cache.
- Queries with
now(),rand(),uuid(), or non-deterministic UDFs. The plan is treated as non-deterministic and the cache is disabled. Replace with day-bucketed expressions likeWHERE dt = date(now()). - Multi-column
RANGEorLISTpartitioned tables with shifting filter ranges. The partition predicate is included in the digest verbatim, so different ranges produce different keys. Tablet-level reuse only kicks in for single-columnRANGE. - Lookups by primary key. Query Cache is for aggregation. For
WHERE pk = ?patterns, use High-Concurrency Point Query instead.
Configuration knobs
| Knob | Where | Default | When to change |
|---|---|---|---|
enable_query_cache | session | false | Always: set per session, or globally for dashboard accounts. |
query_cache_entry_max_bytes | session | 5 MB | Raise for very wide group-bys; results above this are silently uncached. |
query_cache_entry_max_rows | session | 500,000 | Raise for high-cardinality GROUP BY. |
query_cache_size | be.conf | 512 MB | Per-BE memory cap. Raise for cache-bound dashboards. |
query_cache_force_refresh | session | false | Set to true for one query when you suspect a stale cached result, then reset. |
Further reading
- Query Cache user guide
- SQL Cache: result-level caching for any query
- Condition Cache: caches filter results on segments
- Async materialized views: pre-aggregate complex pipelines
- Caching in Doris: choosing the right strategy
- Data Cache & Page Cache: the storage-tier caches that sit below Query Cache for repeated scans.
- Metadata Cache: the external-catalog metadata cache for federated lakehouse queries.
- MPP Architecture: the execution model whose fragment DAG the query cache short-circuits when result is reusable.