Stream Load
TL;DR Apache Doris Stream Load lets a client
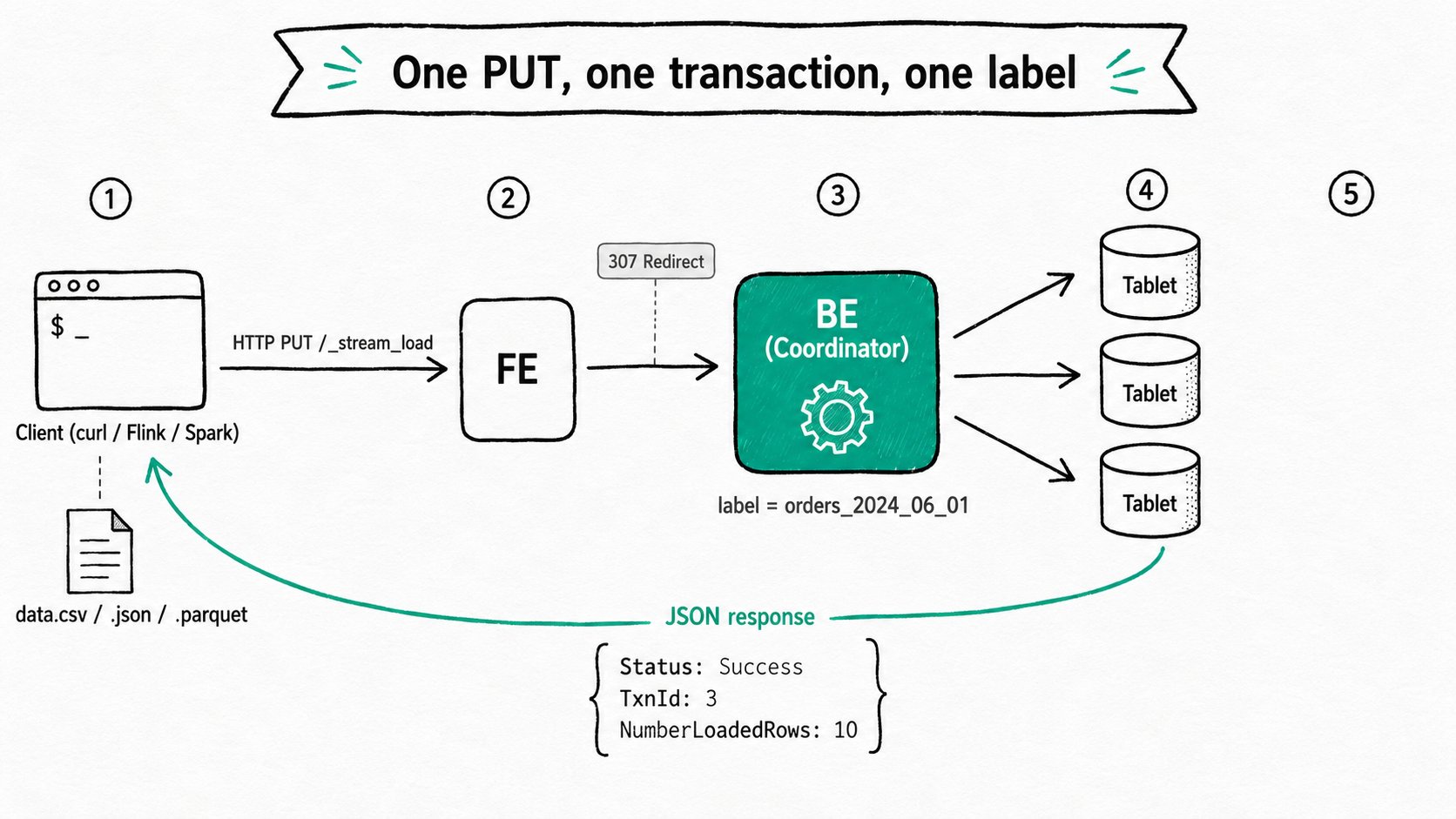
curl(or any HTTP library) push a file or a stream of bytes into a table over a single HTTP PUT request. The FE redirects the request to a BE, the chosen BE acts as the coordinator, parses CSV/JSON/Parquet/ORC, writes to the target tablets, and returns a JSON body that tells the caller whether the whole batch committed. One label dedupes retries, one transaction makes the batch atomic, and the JSON response carries the row counts and per-phase timings.
Why use Apache Doris Stream Load?
Apache Doris Stream Load is the path for clients that already speak HTTP and want a synchronous answer per batch, with a label-keyed retry guarantee and no extra transaction manager. A lot of real-time writes into a warehouse start out as a script that pushes a file. The script lives inside a Flink sink, a Kafka consumer, an rsync cron, or a microservice that just produced a few thousand events. Whoever wrote the script wants to send the bytes, get an answer on the same connection, and know that a retry is safe.
- A Flink job needs to flush its current checkpoint to Apache Doris and learn whether the commit succeeded before it advances offsets.
- An ETL script has a 200 MB CSV from yesterday's export and wants the rows visible before the morning report runs.
- A side service emits a JSON batch every few seconds and needs at-most-once semantics without bringing in a transaction manager.
Apache Doris Stream Load covers that shape of write directly. One HTTP PUT, one label, one transaction, one synchronous response on the same socket.
What is Apache Doris Stream Load?
Apache Doris Stream Load is a synchronous HTTP load endpoint exposed by every node in the cluster. The client sends an HTTP PUT to either an FE or a BE; the FE redirects to a BE in round-robin order, and the chosen BE becomes the coordinator for that load. The coordinator parses the request body, distributes rows to the BEs that own each tablet, opens one transaction with the FE, commits when every BE acks, and returns a JSON body on the same socket. Apache Doris has supported CSV since the beginning and now also accepts JSON, Parquet, ORC, and CSV-with-header variants.
Key terms
- Coordinator BE: the backend that receives the HTTP body, parses it, and orchestrates the load. Either chosen by the FE redirect or addressed directly by the client.
label: the request-supplied (or server-generated) string that names the transaction. Reusing a successful label rejects the duplicate; reusing a failed label is allowed./api/{db}/{table}/_stream_load: the canonical endpoint. The 2PC variant is_stream_load_2pc.Expect: 100-continue: required header. The client posts the headers first, lets the server check auth and start a transaction, then sends the body.max_filter_ratio: the per-load tolerance for malformed rows. Defaults to 0, so one bad row fails the batch.
How does Apache Doris Stream Load work?
Apache Doris Stream Load runs the entire load as one HTTP request: the FE redirects to a coordinator BE, the BE parses the body, opens a transaction, distributes rows to tablet owners, and answers on the same socket.
- Client sends PUT to FE (or BE). The headers carry the label, format, column mapping, filters, and timeouts. The body is the file or stream.
Expect: 100-continuelets the server reject the request before the body is uploaded. - FE picks a coordinator BE and redirects. The FE returns an HTTP 307 to a BE chosen in round-robin order. A client that already knows a healthy BE can skip this hop and PUT to the BE directly.
- Coordinator BE opens a transaction and parses. It calls back to the FE to begin the transaction with the supplied label, then streams the body through the format-specific reader (CSV, JSON, Parquet, ORC). Rows that fail parsing or schema checks are counted against
max_filter_ratio. - Distribute, write, commit. The coordinator routes each row to the BEs that hold the right tablets, those BEs flush memtables to segments, the coordinator asks the FE to commit, and the FE issues a
PublishVersionto every replica. - Return JSON. The coordinator answers the original PUT with a JSON body:
Status,Label,TxnId,NumberLoadedRows,NumberFilteredRows, anErrorURLif anything failed quality checks, and per-phase timings. The connection closes.
The whole sequence is one HTTP request from the client's point of view. If the client retries with the same label after a successful commit, the FE rejects the retry with Label Already Exists; that is the at-most-once guarantee.
Quick start
# Push a CSV directly to Doris over HTTP PUT.
curl --location-trusted -u root: \
-H "Expect:100-continue" \
-H "label:orders_2024_06_01" \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T streamload_example.csv \
-XPUT http://fe_host:8030/api/testdb/test_streamload/_stream_load
Expected result
{
"TxnId": 3,
"Label": "orders_2024_06_01",
"Status": "Success",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173
}
Status: Success means the batch committed and the rows are queryable. Resending the same curl returns Status: Label Already Exists and writes nothing, so a client that retries on a network blip will not double-load.
When should you use Apache Doris Stream Load?
Use Apache Doris Stream Load when one HTTP PUT per batch, with a label-keyed retry guarantee and a synchronous JSON response, is exactly the contract the client wants.
Good fit
- Flink, Spark, or other streaming sinks that already speak HTTP and want a synchronous answer per checkpoint. Combine with
two_phase_commit:truefor exactly-once across checkpoints. - ETL scripts that push a single CSV, JSON, Parquet, or ORC file (typically up to about 10 GB) and want one atomic commit.
- Bash one-liners and language-native HTTP clients that produce data programmatically and pipe it through
curl -T -. - Loads that need a label-keyed retry guarantee without a transaction manager.
Not a good fit
- Tens of thousands of tiny PUTs per second from many clients. Each load opens its own transaction and produces its own rowset, which overwhelms the FE planner and triggers
-235 Too many segmentson the BE. Use Group Commit so the BE merges small writes into one transaction, or move to Routine Load for Kafka. - Single files much larger than 10 GB. Apache Doris Stream Load runs as one synchronous request; if the connection drops you start over. Split the file or use Batch Load, which runs server-side and survives the client.
- Continuous tailing of a Kafka topic. Stream Load knows nothing about offsets. Use Routine Load, which manages offsets, restart, and pause for you.
- Stream Load 2PC against Merge-on-Write Unique Key tables in cloud / storage-compute-separated deployments. The BE rejects this combination with
Status::NotSupported. On-prem (shared-nothing) clusters allow it, and the regression suite covers it. - Loads that need server-side recording out of the box. By default, Apache Doris does not log Stream Load history; turn on
enable_stream_load_recordinbe.confifSHOW STREAM LOADshould return anything.
Further reading
- Stream Load HTTP reference: every header, the redirect rules, and the full response body
- Group Commit: server-side merge for high-frequency Stream Loads that hit
-235 - Batch Load: asynchronous bulk ingest for large files from S3 and HDFS
- Load transactions and Stream Load 2PC: when checkpoints need exactly-once across two systems
- Routine Load: managed Kafka consumer with offset and pause control
- Doris Streamloader: a multi-concurrency client wrapper around the Stream Load API
- Unique Key: the primary destination for partial-column upserts (
partial_columns: true) from CDC pipelines.