Vector Index
TL;DR Apache Doris 4.0 added a native ANN index on
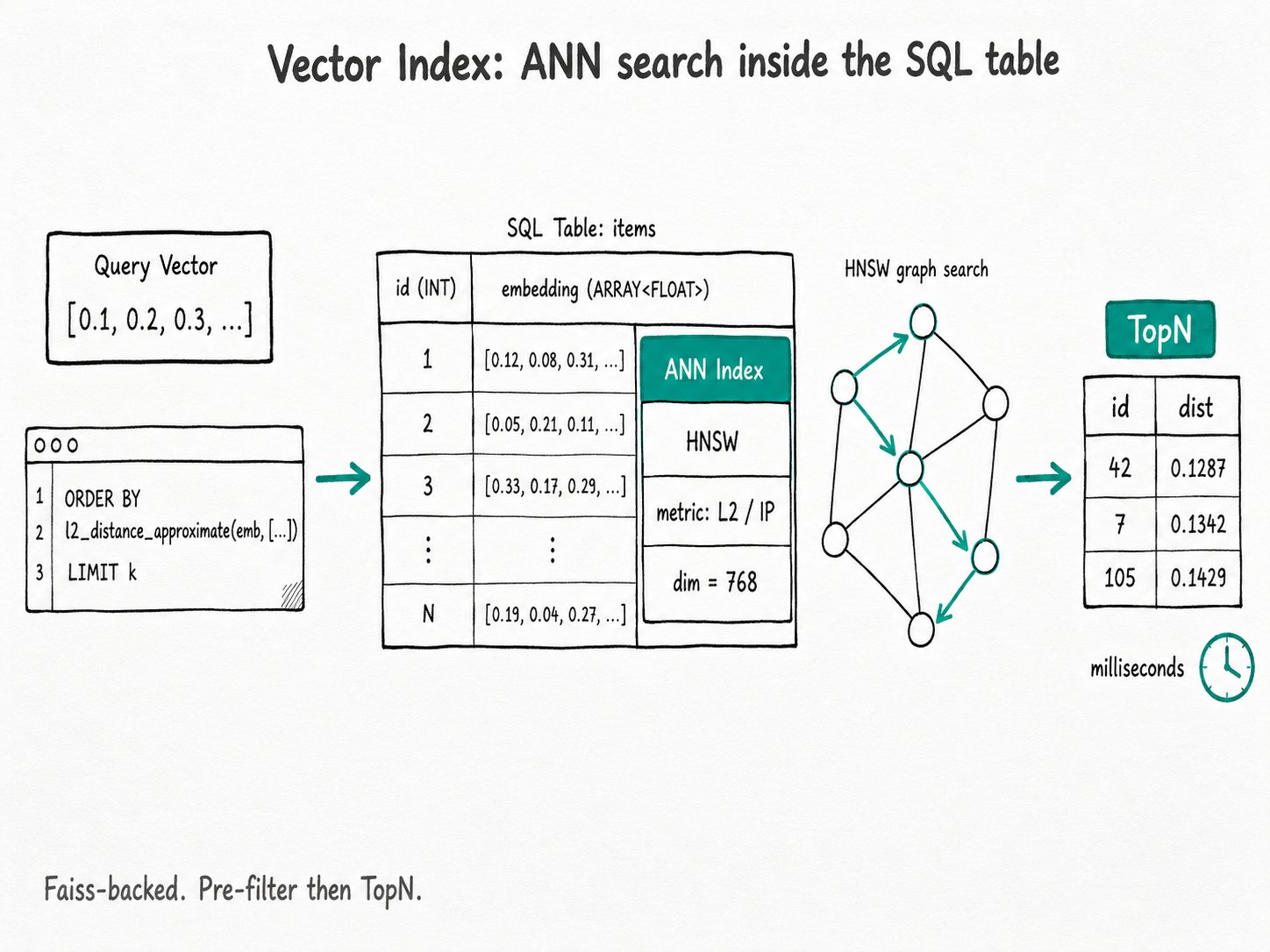
ARRAY<FLOAT>columns. The index is declared inline inCREATE TABLE(or withCREATE INDEX ... USING ANN); pick HNSW or IVF, pick L2 or inner product, and then calll2_distance_approximateorinner_product_approximateinORDER BY ... LIMIT k. Built on Faiss, the vector index pre-filters before the TopN, soWHEREpredicates stay correct.
Why use the vector index in Apache Doris?
The Apache Doris vector index removes the need for a separate vector database alongside your analytics warehouse. The default move when you need vector search is to bolt on a second cluster. That works, but you pay for it twice. Once in dollars, and once in the operational tax of running two systems where the keyword filters live on one side and the embeddings live on the other.
- A separate cluster to size, monitor, and pay for, just to answer "find the closest 10 vectors."
- Drift between the analytics table and the vector store, when a row gets updated in one and not the other.
- Glue code in the application that fans out the query and merges the results, because the SQL engine cannot see the vectors.
Apache Doris pulls the vector index into the same table as the rest of your data. One pipeline in, one SQL query out.
What is the Apache Doris vector index?
The Apache Doris vector index is an ANN (Approximate Nearest Neighbor) secondary index on a vector-typed column. There is no new column type: vectors are stored as ARRAY<FLOAT> of fixed dimension. The index sits next to the data, builds at segment granularity, and gets used whenever the planner sees an approximate distance function in ORDER BY.
Key terms
ARRAY<FLOAT>: how Apache Doris stores a vector. The column must beNOT NULL, and every row must have the same length as the indexdim.USING ANN: the index clause. Properties pick the algorithm (hnsw,ivf,ivf_on_disk), the metric (l2_distanceorinner_product), and the dimension.- HNSW: the default graph-based algorithm. Fast, high recall, must stay in memory.
- IVF / IVF on-disk: inverted-file algorithms for larger sets where memory is tight.
l2_distance_approximate/inner_product_approximate: the SQL functions that trigger the index. The non-_approximateversions exist too, but they fall through to a brute-force scan.
How does the Apache Doris vector index work?
The Apache Doris vector index runs through a five-step lifecycle: build at load time, recognize the query pattern, pre-filter, merge per-segment TopN, and let session knobs tune recall.
- Build at load time. When a segment is written, Apache Doris hands the column to Faiss and builds the index file alongside the data. One index per segment, no separate build job.
- Plan recognizes the pattern. A query that reads
ORDER BY l2_distance_approximate(col, [...]) LIMIT kis rewritten into anAnnTopNoperator on the storage side. The literal vector is pushed down with the LIMIT. - Pre-filter, then TopN. If there is a
WHEREclause, Apache Doris evaluates the predicate first, then runs ANN TopN on what survives. This keeps recall honest under selective filters. The predicate columns must have their own secondary index (such as inverted), or the engine falls back to brute force on those rows to keep results correct. - Per-segment local TopN, then merge. Each segment returns its own k closest. The TopN operator merges across segments and tablets to produce the global k.
- Tuneable at query time. Session variables like
hnsw_ef_searchwiden the candidate queue for higher recall, at the cost of latency. The defaults are conservative; nudge them when you have a recall target.
Quick start
CREATE TABLE docs (
id INT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES(
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "3"
)
) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 1;
INSERT INTO docs VALUES
(1, [1.0, 2.0, 3.0]),
(2, [0.5, 2.1, 2.9]),
(3, [10.0, 10.0, 10.0]);
SELECT id, l2_distance_approximate(embedding, [1.0, 2.0, 3.0]) AS dist
FROM docs ORDER BY dist LIMIT 3;
Expected result
+----+--------------------+
| id | dist |
+----+--------------------+
| 1 | 0.0 |
| 2 | 0.5196152329444885 |
| 3 | 13.928388595581055 |
+----+--------------------+
The query against id=1 is exact (distance 0). The ANN index ranks the two close neighbors first and the outlier last. The same query shape against the SIFT-1M dataset (1 million 128-dim vectors) runs in about 20 ms with the index, versus about 290 ms without; both numbers are from the Vector Search overview.
When should you use the Apache Doris vector index?
The Apache Doris vector index fits any workload where the embeddings live in the same table as the structured columns you already filter and aggregate on.
Good fit
- RAG retrieval where the same table also holds tenant id, document type, time, and other filter columns. You want the filter and the vector lookup in one query.
- Recommendation recall and "find similar" features where embeddings live next to product or content metadata that already drives the rest of your dashboards.
- Anomaly detection or "look for everything within distance X" workloads, served by approximate range search (
WHERE l2_distance_approximate(...) > 300). - Hybrid search that mixes
MATCH_*text predicates with vector ranking. The inverted index pre-filters; the ANN index ranks. See Hybrid Search.
Not a good fit
- Pure billion-vector ANN with no filters and no SQL analytics. A dedicated vector database can be cheaper to operate and may use less memory per QPS.
AGGREGATE KEYtables, orUNIQUE KEYwithout merge-on-write. ANN indexes today requireDUPLICATE KEYor MoWUNIQUE KEY.- Nullable vector columns or rows with mismatched length. The column must be
NOT NULL ARRAY<FLOAT>, and every row must match the declareddimexactly. Loads with the wrong shape fail. score()plus a distance function in the sameORDER BY. The TopN push-down accepts one ordering expression; if you need both BM25 and ANN scores fused, do the fusion above the SQL layer.- Cosine similarity called as
cosine_distance. Apache Doris has no cosine metric; normalize the vectors before insert and useinner_product. On unit-length vectors, cosine equals inner product.
Performance / numbers
The numbers below come from the project's published benchmark on Cohere-MEDIUM-1M (768-dim, 1M vectors, FE 32C 64GB + BE 32C 64GB).
| Concurrency | Scheme | QPS | Avg latency | P99 latency | Recall |
|---|---|---|---|---|---|
| 240 | HNSW (FLAT) | 3,340 | 71 ms | 163 ms | 91.0% |
| 240 | HNSW + SQ INT8 | 3,189 | 75 ms | 160 ms | 88.3% |
| 240 | Brute force (no index) | 3.7 | 25.6 s | 29.4 s | 100% |
Source: Vector index performance. Treat these as a reference point, not as a guarantee for your workload. The same page reports that SQ8 quantization shrinks the index to about a third of FLAT, with the small recall hit you can see above.
Further reading
- Hybrid Search: how to combine the ANN index with the inverted index in one SQL statement.
- Vector Search overview: full reference for index properties, query patterns, and limits.
- HNSW deep dive: how
max_degree,ef_construction, andef_searchtrade recall against latency. - IVF on-disk: the option to use when the vector set no longer fits in BE memory.
- Practical guide: end-to-end walkthrough including data prep, loading, and tuning.
- Embedding: the
EMBED()SQL function that turns text and media into theARRAY<FLOAT>vectors this index reads from. - AI overview: how vector search fits with the rest of Doris's AI features.