Vectorized Execution
TL;DR Every Apache Doris query runs on the vectorized engine. Operators move data in
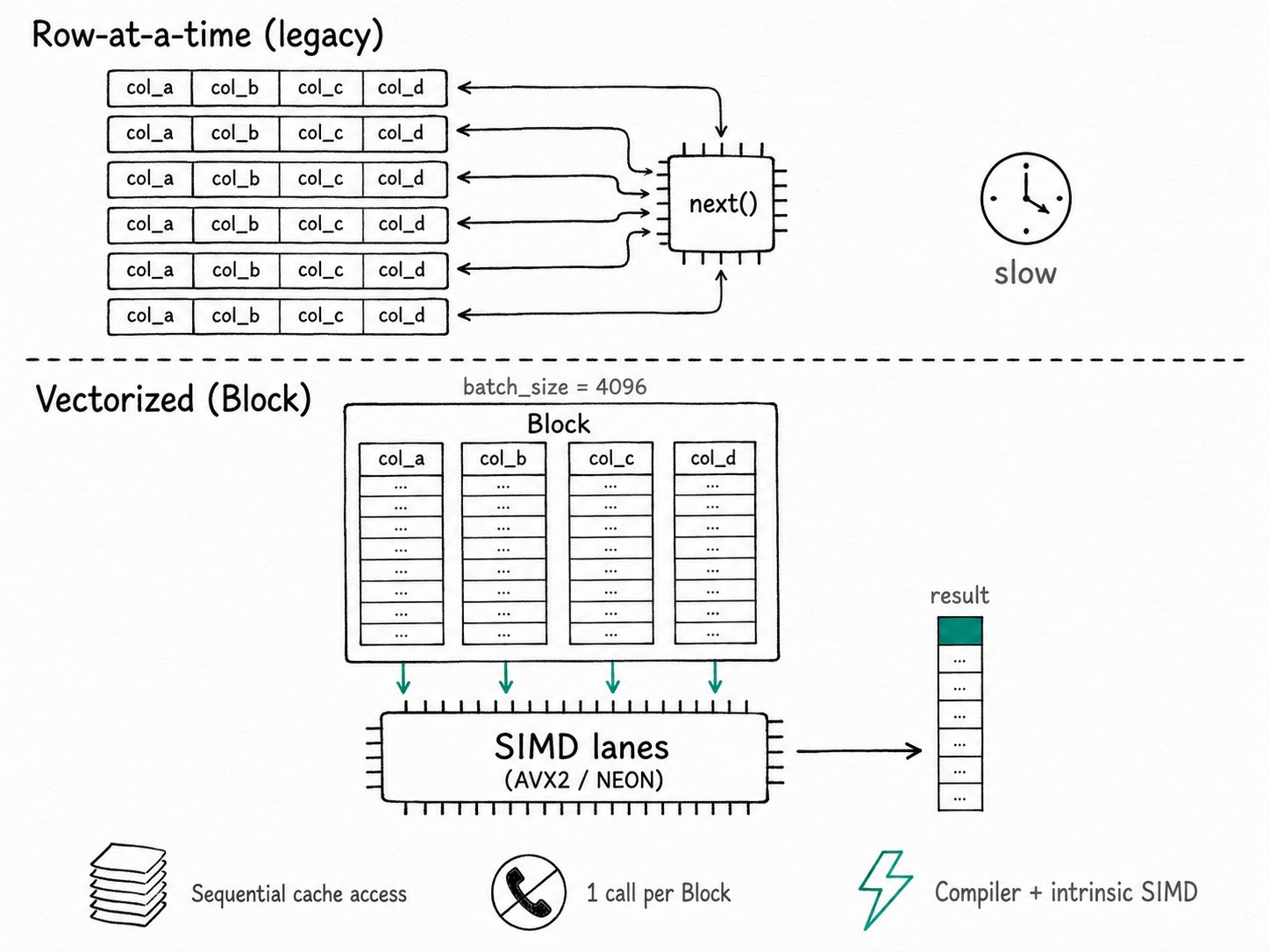
Blocks of up to 4,096 column-oriented rows, and the inner loops are tight enough for the compiler and hand-written intrinsics to use SIMD. The row-based engine was deleted entirely in v2.0, so there is nothing to enable; the only knob most users will ever touch isbatch_size.
Why use vectorized execution in Apache Doris?
Apache Doris vectorized execution replaces per-row virtual dispatch with column-batch inner loops so the CPU spends its time on arithmetic instead of indirection. A classic Volcano-style executor calls next() once per row, walking through a tree of virtual function dispatches to produce a single tuple. On a modern CPU, the actual arithmetic is a rounding error on top of the dispatch, branch mispredictions, and cache misses. Aggregating a billion rows row-by-row turns a fast machine into a slow one.
- One virtual call per row, per operator, multiplies into millions of indirect jumps the branch predictor cannot help with.
- Random row layout in memory keeps the CPU's L1/L2 caches mostly empty of useful data.
- Tight numeric loops cannot be auto-vectorized when the data is interleaved across rows.
Vectorized execution flips the inner loop. An operator receives a batch of column values, runs a straight loop over that batch, and the hot path ends up looking like the kind of code AVX2 was built for.
What is Apache Doris vectorized execution?
Apache Doris vectorized execution is a column-batch query engine: every operator's get_block() consumes one Block and produces another, where a Block is a small set of columnar arrays describing 1 to batch_size rows. SIMD intrinsics accelerate the parts that benefit most: filter selection, decimal arithmetic, string comparison, JSON parsing. The model traces back to MonetDB/X100 and Vectorwise. ClickHouse, StarRocks, and DuckDB use the same design.
Key terms
Block: the unit of data passed between operators. Holds typed columnar arrays plus column metadata. Implemented inbe/src/vec/core/block.h.Column: one typed array inside a Block. Specializations includeColumnVector,ColumnString,ColumnDecimal,ColumnNullable, andColumnDictionary, each tuned for its data shape.batch_size: maximum rows in a Block. Default 4,096, configurable per session. Larger batches amortize per-call overhead; smaller ones reduce memory footprint and tail latency.- SIMD path: hand-written code in
be/src/util/simd/plus compiler-auto-vectorized loops, dispatched at runtime to AVX2 on x86 or NEON on ARM.
How does Apache Doris vectorized execution work?
Apache Doris vectorized execution chains operators that pass columnar Blocks of up to 4,096 rows, runs straight column-at-a-time loops with SIMD where it pays off, and lets the Pipeline scheduler interleave those batches across cores.
- Plan to operator chain. The optimizer produces a plan, the FE rewrites it as a pipeline of operators, and each operator implements
get_block(state, block, eos). - Pull a batch. A scan operator reads up to
batch_sizerows from a tablet's columnar storage, fills a Block in place, and returns it. Rows never get materialized into structs. - Run column-at-a-time. Filter, project, aggregate, and join operators iterate over each column with a straight loop. Where it pays off, the loop calls into SIMD primitives, like
bytes32_mask_to_bits32_maskfor filter compression or vectorized decimal compare. - Hand off downstream. The Block moves through the pipeline as a value, with the Pipeline scheduler interleaving CPU-bound and IO-bound stages across cores. Multiple pipeline tasks process different Blocks in parallel.
- Return to the client. The final operator serializes the last Blocks into the MySQL wire protocol and the query is done.
The Pipeline engine introduced in v2.0 is built on top of this. Vectorization decides what an operator does to a batch; Pipeline decides how those batches get scheduled across cores. The two are different layers, often confused.
Quick start
You don't need to enable vectorized execution: it's the only execution mode. The one knob worth knowing is batch_size.
-- Default; safe to leave alone for most workloads
SHOW VARIABLES LIKE 'batch_size';
-- Larger batches: better throughput on big aggregations, more memory per fragment
SET batch_size = 8192;
SELECT user_id, COUNT(*) AS events, SUM(bytes) AS total_bytes
FROM access_log
WHERE ts BETWEEN '2026-05-01' AND '2026-05-08'
GROUP BY user_id
ORDER BY total_bytes DESC
LIMIT 10;
Expected result
+---------+--------+-------------+
| user_id | events | total_bytes |
+---------+--------+-------------+
| 42718 | 18374 | 924518127 |
| ... |
+---------+--------+-------------+
The aggregation runs column-at-a-time over 8,192-row Blocks. On a wide-table scan with millions of matching rows, the larger batch trades a bit more BE memory for fewer scheduling round-trips, which usually wins on long scans and loses on tiny point queries.
When should you use Apache Doris vectorized execution?
Apache Doris vectorized execution is the only execution mode since v2.0, so the real question is when to tune batch_size or rely on a different query path entirely.
Good fit
- Any workload Doris already runs. Scan-heavy aggregations, GROUP BY, hash joins, and sorts all live on this engine. There is no "non-vectorized" option to compare against.
- Wide-table analytics and dashboard queries. Column-at-a-time loops and SIMD filters do their best work here.
- Workloads on machines with AVX2 or NEON. Doris recommends AVX2-capable x86 CPUs in the install checklist; NEON is the default ARM path. Older CPUs still work, but SIMD-accelerated paths fall back to scalar code.
Not a good fit
- Single-row primary-key lookups served at thousands of QPS. Per-Block setup cost works against you when the Block holds one row. Use the High-Concurrency Point Query path instead.
- Tuning
batch_sizefor ad-hoc queries. The default of 4,096 was chosen for a reason, and changing it usually does nothing or makes things slightly worse. Reach for it only when profiling tells you the per-batch overhead is dominating, or when fragments are running out of memory. - Reading old advice that mentions
enable_vectorized_engine. That session variable was demoted to a no-op in v1.2.1 and the underlying row-based code was deleted in v2.0. If a doc or blog post tells you to flip it, the doc is stale. - Confusing this feature with vector search. "Vectorized execution" is a query engine model. ANN-style vector search lives in a separate index family under
docs/ai/vector-search/.
Performance
- 3 to 5x faster than the prior version when v1.1 made vectorized execution the default for all queries. Source: Apache Doris 1.1.0 release notes.
- 5 to 10x improvement on wide-table aggregations, attributed to the columnar memory layout combined with SIMD acceleration. Source: Doris product concepts.
Further reading
- Product concepts: Vectorized Execution Engine
- Pipeline execution engine
- System architecture overview
- Columnar Storage: the on-disk format whose pages and encodings feed directly into the vectorized columns.
- Parquet Reader Optimization: how external Parquet decoding lands straight in the vectorized engine without an Arrow round trip.
- Apache Doris 2.0 release notes (row-based engine removed)
- MPP Architecture: the layer that schedules vectorized operators across BEs, not just within one.