
Lakehouse Overview
The lakehouse is a modern big data solution that combines the advantages of data lakes and data warehouses. It integrates the low cost and high scalability of data lakes with the high performance and strong data governance capabilities of data warehouses, enabling efficient, secure, and quality-controlled storage and processing analysis of various data in the big data era. Through standardized open data formats and metadata management, it unifies real-time and historical data, batch processing, and stream processing, gradually becoming the new standard for enterprise big data solutions.
Doris Lakehouse Solution
Doris provides an excellent lakehouse solution for users through an extensible connector framework, a compute-storage decoupled architecture, a high-performance data processing engine, and data ecosystem openness.
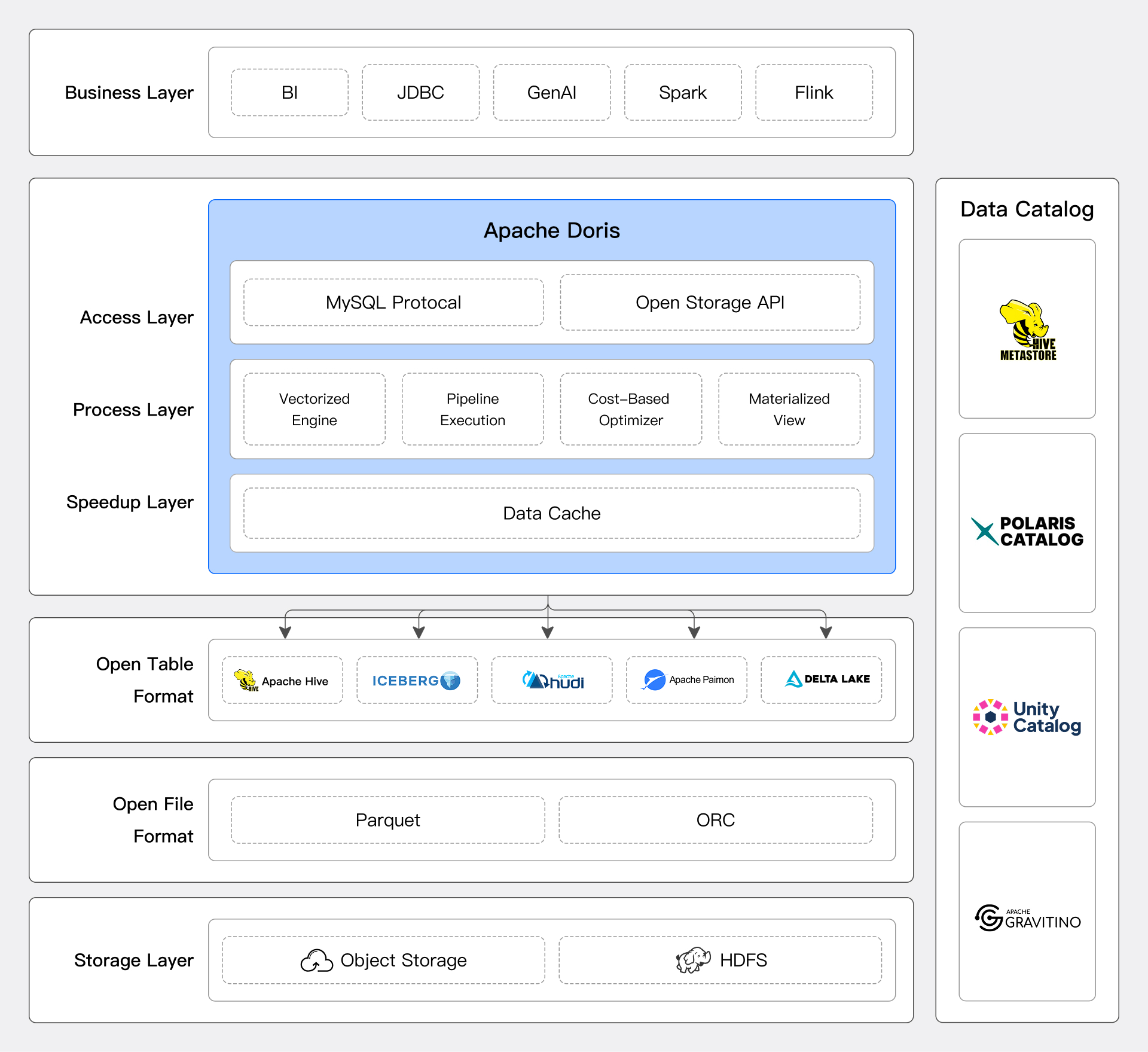
Flexible Data Access
Doris supports mainstream data systems and data format access through an extensible connector framework and provides unified data analysis capabilities based on SQL, allowing users to easily perform cross-platform data queries and analysis without moving existing data. For details, refer to Catalog Overview
Data Source Connectors
Whether it's Hive, Iceberg, Hudi, Paimon, or database systems supporting the JDBC protocol, Doris can easily connect and efficiently access data.
For lakehouse systems, Doris can obtain the structure and distribution information of data tables from metadata services such as Hive Metastore, AWS Glue, and Unity Catalog, perform reasonable query planning, and utilize the MPP architecture for distributed computing.
For details, refer to each catalog document, such as Iceberg Catalog
Extensible Connector Framework
Doris provides a good extensibility framework to help developers quickly connect to unique data sources within enterprises, achieving fast data interoperability.
Doris defines three levels of standard Catalog, Database, and Table, allowing developers to easily map to the required data source levels. Doris also provides standard interfaces for metadata service and storage service accessing, and developers only need to implement the corresponding interface to complete the data source connection.
Doris is compatible with the Trino Connector plugin, allowing the Trino plugin package to be directly deployed to the Doris cluster, and with minimal configuration, the corresponding data source can be accessed. Doris has already completed connections to data sources such as Kudu, BigQuery, and Delta Lake. You can also adapt new plugins yourself.
Convenient Cross-Source Data Processing
Doris supports creating multiple data catalogs at runtime and using SQL to perform federated queries on these data sources. For example, users can associate query fact table data in Hive with dimension table data in MySQL:
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
Combined with Doris's built-in job scheduling capabilities, you can also create scheduled tasks to further simplify system complexity. For example, users can set the result of the above query as a routine task executed every hour and write each result into an Iceberg table:
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 HOUR DO
INSERT INTO iceberg.db.ice_table
SELECT h.id, m.name
FROM hive.db.hive_table h JOIN mysql.db.mysql_table m
ON h.id = m.id;
High-Performance Data Processing
As an analytical data warehouse, Doris has made numerous optimizations in lakehouse data processing and computation and provides rich query acceleration features:
-
Execution Engine
The Doris execution engine is based on the MPP execution framework and Pipeline data processing model, capable of quickly processing massive data in a multi-machine, multi-core distributed environment. Thanks to fully vectorized execution operators, Doris leads in computing performance in standard benchmark datasets like TPC-DS.
-
Query Optimizer
Doris can automatically optimize and process complex SQL requests through the query optimizer. The query optimizer deeply optimizes various complex SQL operators such as multi-table joins, aggregation, sorting, and pagination, fully utilizing cost models and relational algebra transformations to automatically obtain better or optimal logical and physical execution plans, greatly reducing the difficulty of writing SQL and improving usability and performance.
-
Data Cache and IO Optimization
Access to external data sources is usually network access, which can have high latency and poor stability. Apache Doris provides rich caching mechanisms and has made numerous optimizations in cache types, timeliness, and strategies, fully utilizing memory and local high-speed disks to enhance the analysis performance of hot data. Additionally, Doris has made targeted optimizations for network IO characteristics such as high throughput, low IOPS, and high latency, providing external data source access performance comparable to local data.
-
Materialized Views and Transparent Acceleration
Doris provides rich materialized view update strategies, supporting full and partition-level incremental refresh to reduce construction costs and improve timeliness. In addition to manual refresh, Doris also supports scheduled refresh and data-driven refresh, further reducing maintenance costs and improving data consistency. Materialized views also have transparent acceleration capabilities, allowing the query optimizer to automatically route to appropriate materialized views for seamless query acceleration. Additionally, Doris's materialized views use high-performance storage formats, providing efficient data access capabilities through column storage, compression, and intelligent indexing technologies, serving as an alternative to data caching and improving query efficiency.
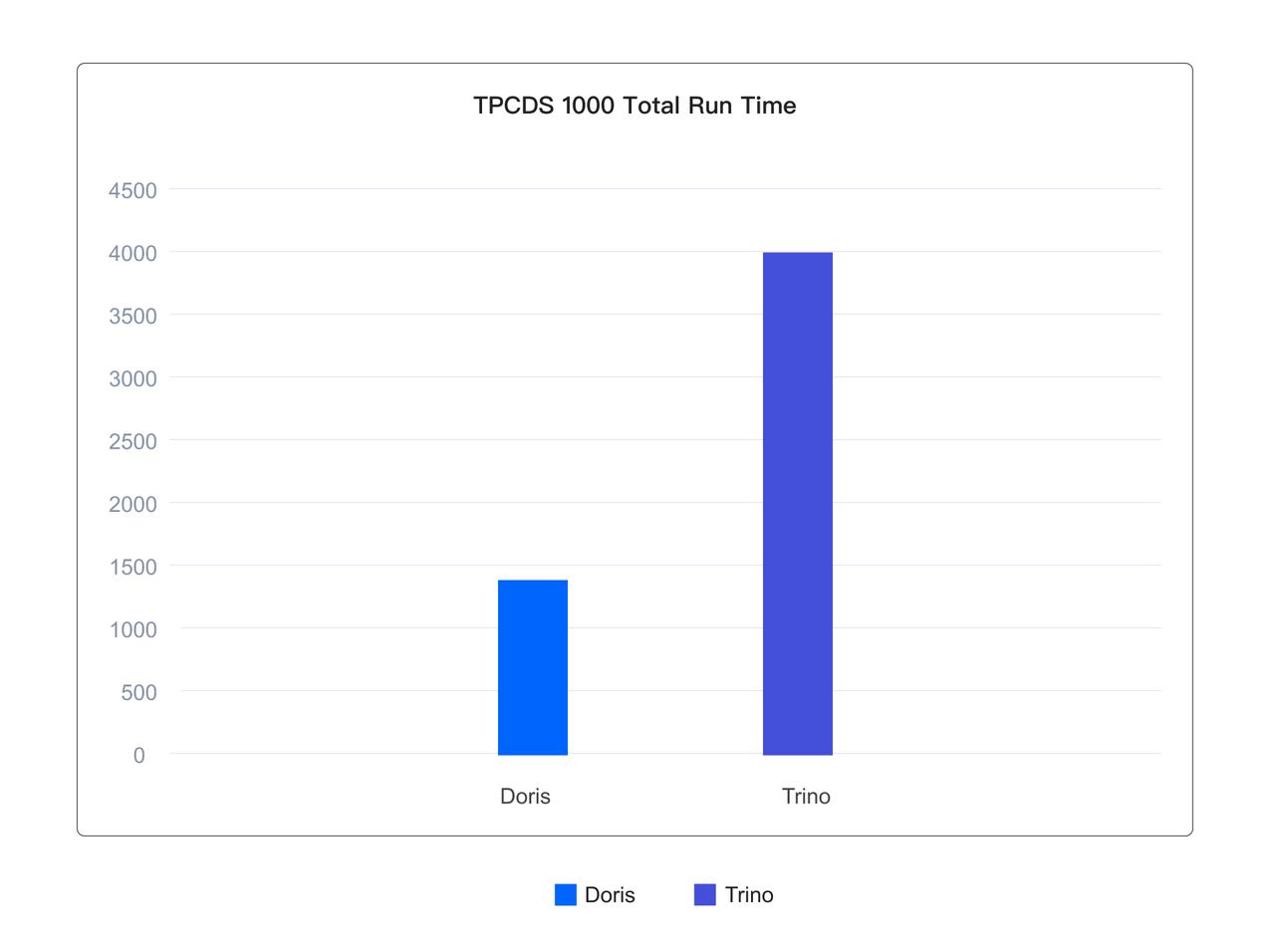
As shown below, on a 1TB TPCDS standard test set based on the Iceberg table format, Doris's overall execution of 99 queries is only 1/3 of Trino's.
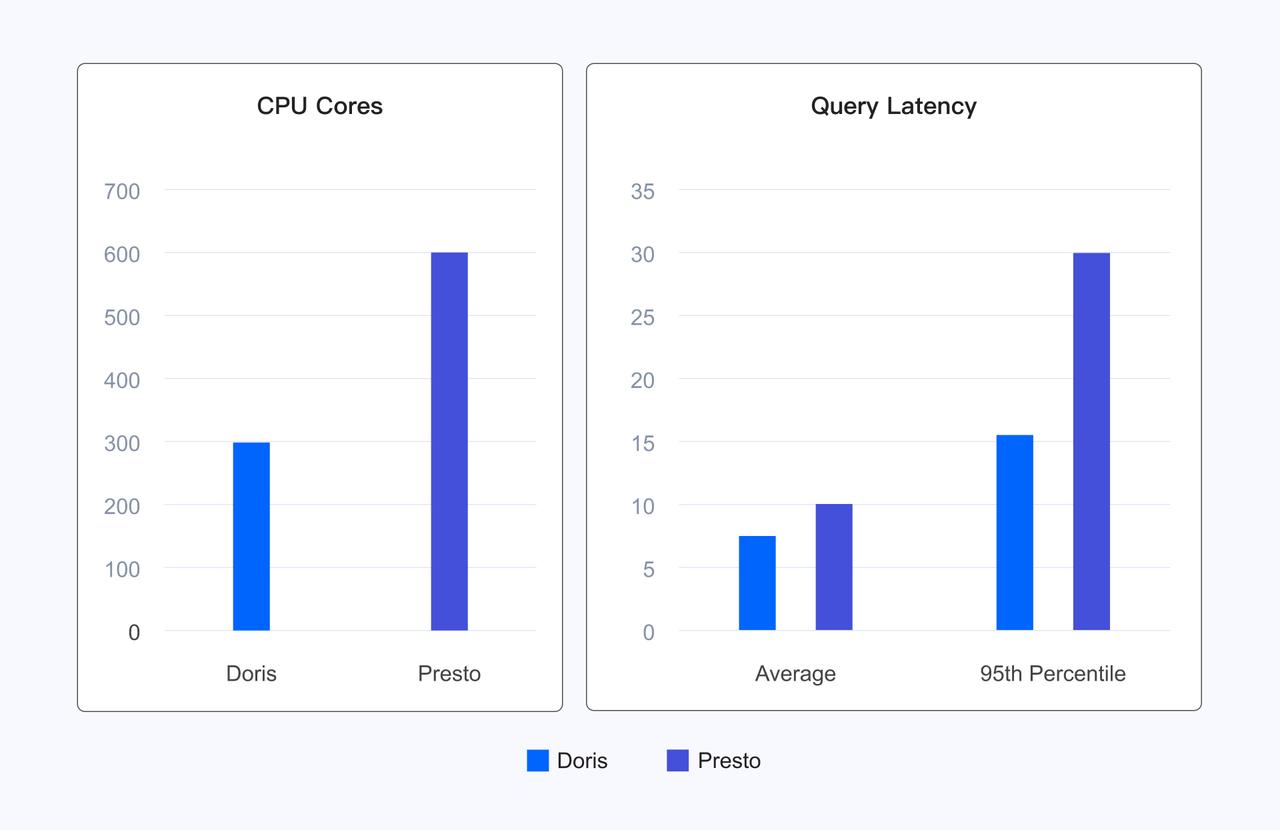
In actual user scenarios, Doris reduces average query latency by 20% and 95th percentile latency by 50% compared to Presto while using half the resources, significantly reducing resource costs while enhancing user experience.
Convenient Service Migration
In the process of integrating multiple data sources and achieving lakehouse transformation, migrating SQL queries to Doris is a challenge due to differences in SQL dialects across systems in terms of syntax and function support. Without a suitable migration plan, the business side may need significant modifications to adapt to the new system's SQL syntax.
Modern Deployment Architecture
Since version 3.0, Doris supports a cloud-native compute-storage separation architecture. This architecture, with its low cost and high elasticity, effectively improves resource utilization and enables independent scaling of compute and storage.
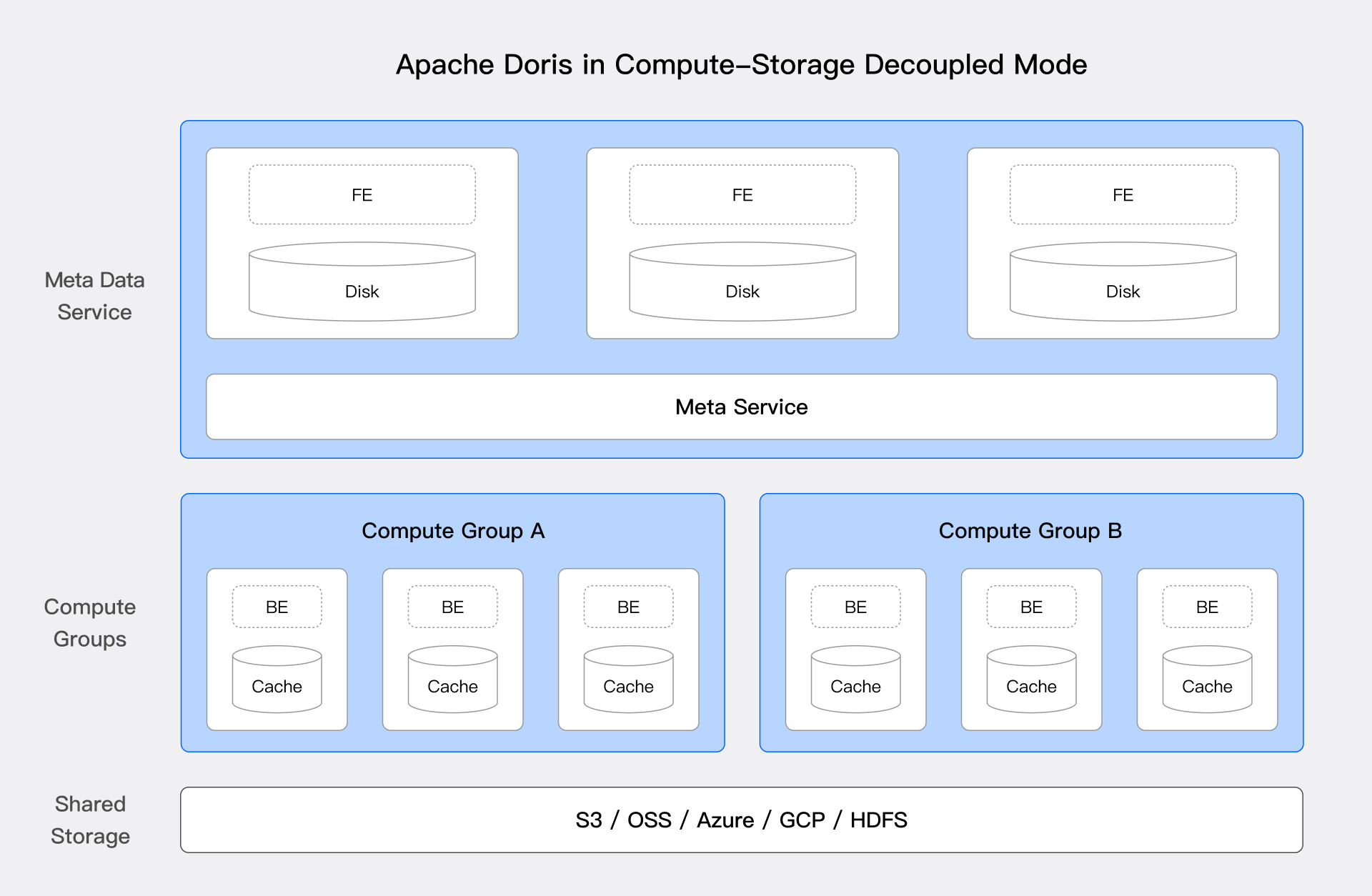
The above diagram shows the system architecture of Doris's compute-storage separation, decoupling compute and storage. Compute nodes no longer store primary data, and the underlying shared storage layer (HDFS and object storage) serves as the unified primary data storage space, supporting independent scaling of compute and storage resources. The compute-storage separation architecture brings significant advantages to the lakehouse solution:
-
Low-Cost Storage: Storage and compute resources can be independently scaled, allowing enterprises to increase storage capacity without increasing compute resources. Additionally, by using cloud object storage, enterprises can enjoy lower storage costs and higher availability, while still using local high-speed disks for caching relatively low-proportion hot data.
-
Single Source of Truth: All data is stored in a unified storage layer, allowing the same data to be accessed and processed by different compute clusters, ensuring data consistency and integrity, and reducing the complexity of data synchronization and duplicate storage.
-
Workload Diversity: Users can dynamically allocate compute resources based on different workload needs, supporting various application scenarios such as batch processing, real-time analysis, and machine learning. By separating storage and compute, enterprises can more flexibly optimize resource usage, ensuring efficient operation under different loads.
In addition, under the storage-computing coupled architecture, elastic computing nodes can still be used to provide elastic computing capabilities in lake warehouse data query scenarios.
Openness
Doris not only supports access to open lake table formats but also has good openness for its own stored data. Doris provides an open storage API and implements a high-speed data link based on the Arrow Flight SQL protocol, offering the speed advantages of Arrow Flight and the ease of use of JDBC/ODBC. Based on this interface, users can access data stored in Doris using Python/Java/Spark/Flink's ABDC clients.
Compared to open file formats, the open storage API abstracts the specific implementation of the underlying file format, allowing Doris to accelerate data access through advanced features in its storage format, such as rich indexing mechanisms. Additionally, upper-layer compute engines do not need to adapt to changes or new features in the underlying storage format, allowing all supported compute engines to simultaneously benefit from new features.
Lakehouse Best Practices
In the lakehouse solution, Doris is mainly used for lakehouse query acceleration, multi-source federated analysis, and lakehouse data processing.
Lakehouse Query Acceleration
In this scenario, Doris acts as a compute engine, accelerating query analysis on lakehouse data.
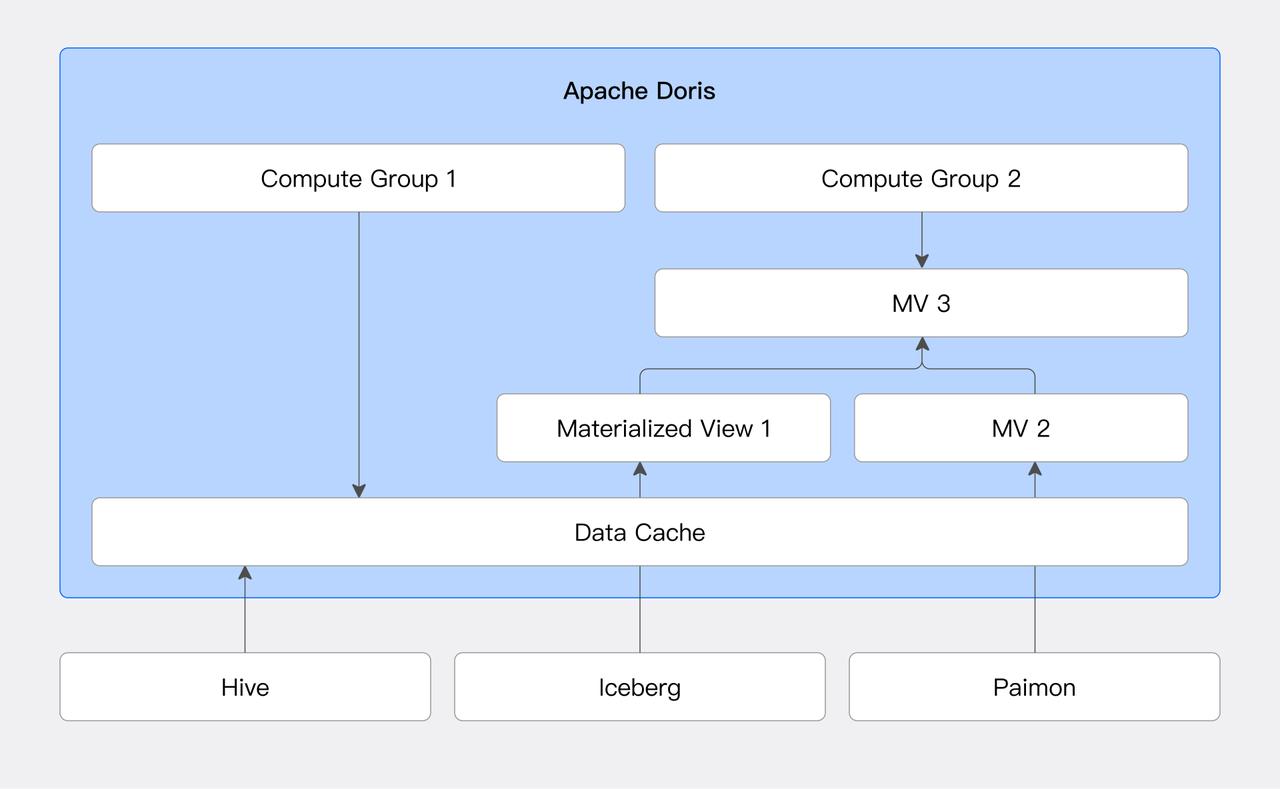
Cache Acceleration
For lakehouse systems like Hive and Iceberg, users can configure local disk caching. Local disk caching automatically stores query-designed data files in local cache directories and manages cache eviction using the LRU strategy. For details, refer to the Data Cache document.
Materialized Views and Transparent Rewrite
Doris supports creating materialized views for external data sources. Materialized views store pre-computed results as Doris internal table formats based on SQL definition statements. Additionally, Doris's query optimizer supports a transparent rewrite algorithm based on the SPJG (SELECT-PROJECT-JOIN-GROUP-BY) pattern. This algorithm can analyze the structure information of SQL, automatically find suitable materialized views for transparent rewrite, and select the optimal materialized view to respond to query SQL.
This feature can significantly improve query performance by reducing runtime computation. It also allows access to data in materialized views through transparent rewrite without business awareness. For details, refer to the Materialized Views document.
Multi-Source Federated Analysis
Doris can act as a unified SQL query engine, connecting different data sources for federated analysis, solving data silos.
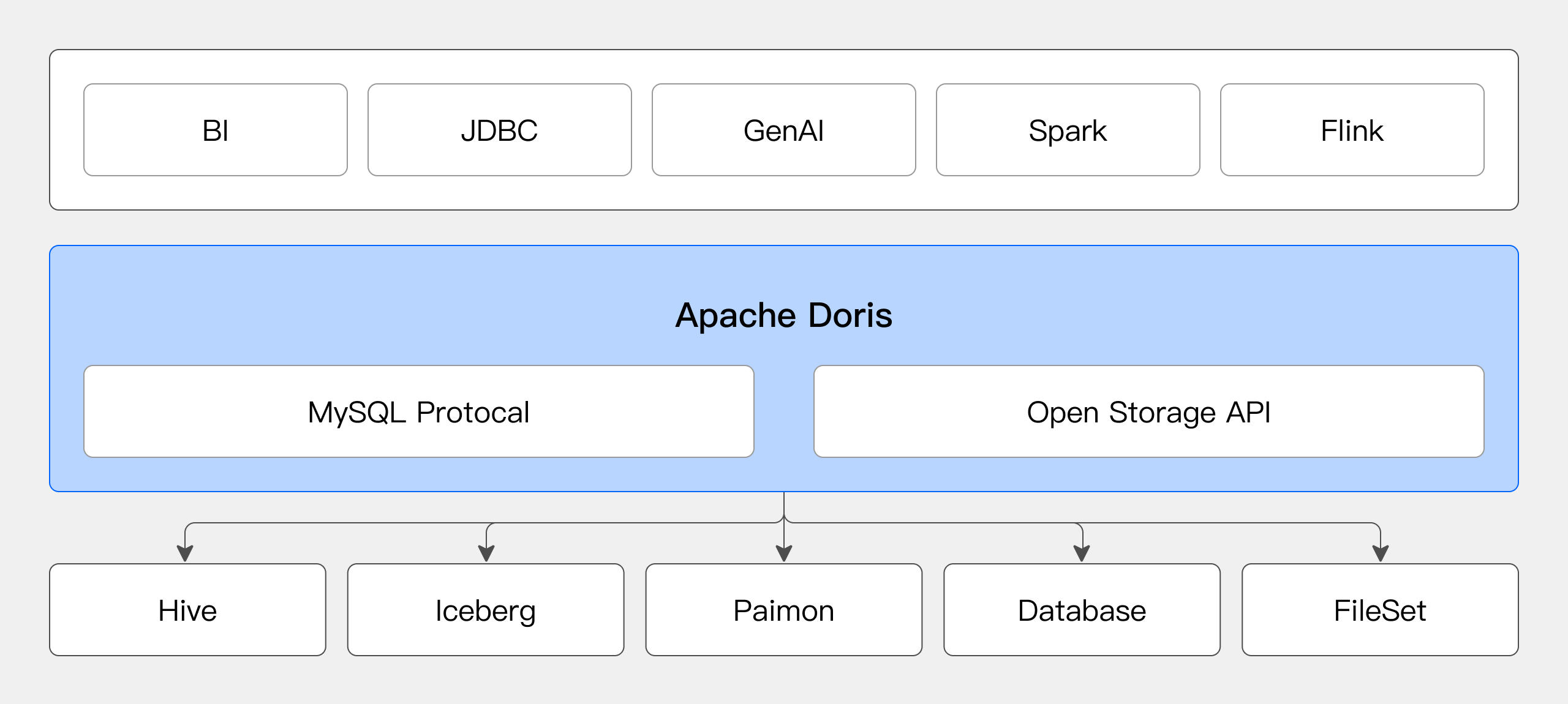
Users can dynamically create multiple catalogs in Doris to connect different data sources. They can use SQL statements to perform arbitrary join queries on data from different data sources. For details, refer to the Catalog Overview.
Lakehouse Data Processing
In this scenario, Doris acts as a data processing engine, processing lakehouse data.
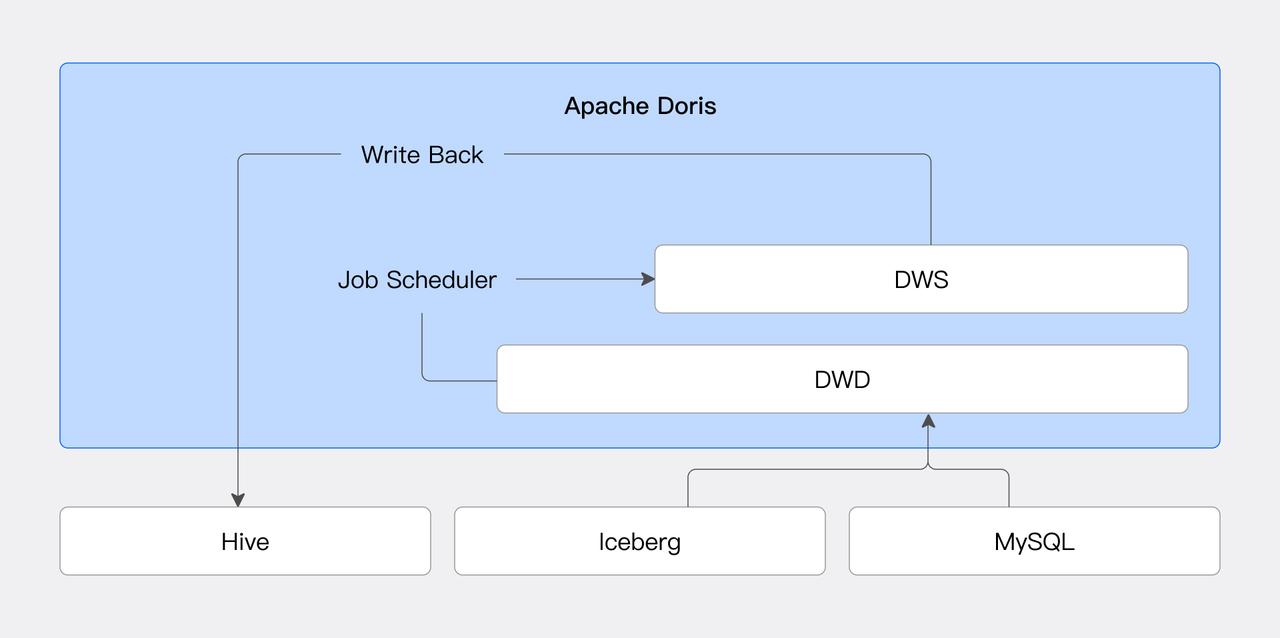
Task Scheduling
Doris introduces the Job Scheduler feature, enabling efficient and flexible task scheduling, reducing dependency on external systems. Combined with data source connectors, users can achieve periodic processing and storage of external data. For details, refer to the Job Scheduler.
Data Modeling
User typically use data lakes to store raw data and perform layered data processing on this basis, making different layers of data available to different business needs. Doris's materialized view feature supports creating materialized views for external data sources and supports further processing based on materialized views, reducing system complexity and improving data processing efficiency.
Data Write-Back
The data write-back feature forms a closed loop of Doris's lakehouse data processing capabilities. Users can directly create databases and tables in external data sources through Doris and write data. Currently, JDBC, Hive, and Iceberg data sources are supported, with more data sources to be added in the future. For details, refer to the documentation of the corresponding data source.