Large-Scale Performance Benchmarks
This document presents real-world load and query performance benchmarks for the Doris ANN Index on medium-large and hundred-million-scale datasets. It helps you evaluate query performance at different data scales and understand how to scale smoothly from a single-node deployment to a distributed deployment.
Quick Navigation
After reading this document, you can answer the following questions:
- For tens of millions of vectors, can a single BE node handle online retrieval? What QPS and latency can you expect?
- For hundreds of millions of vectors, when a single node runs out of memory, how can you continue to serve vector queries through a multi-BE deployment?
- How does performance differ across vector dimensions (768/1536) and distance metrics (
inner_product/l2_distance)? - How can you reproduce these test results?
Test Environment and Datasets
Deployment Topology
| Deployment Mode | BE Nodes | Per-Node Spec | Suitable Data Scale |
|---|---|---|---|
| Single node | 1 | 16C64GB | Tens of millions |
| Distributed | 3 | 16C64GB | Hundreds of millions |
FE and BE are deployed separately. All tests use the VectorDBBench tool.
Dataset Overview
| Dataset | Data Volume | Vector Dimension | Distance Metric | Deployment Topology |
|---|---|---|---|---|
| Performance768D10M | 10M | 768 | inner_product | Single node |
| Performance1536D5M | 5M | 1536 | inner_product | Single node |
| Performance768D100M | 100M | 768 | l2_distance | Distributed |
Single-Node Benchmark (16C64GB)
The single-node results provide a baseline for ANN query performance on medium-large datasets.
Load Performance
The load metrics for the two datasets are as follows:
| Item | Performance768D10M | Performance1536D5M |
|---|---|---|
| Vector dimension | 768 | 1536 |
metric_type | inner_product | inner_product |
| Data volume | 10M rows | 5M rows |
| Load batch params | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 | NUM_PER_BATCH=250000--stream-load-rows-per-batch 250000 |
| Load duration | 76m41s | 41m |
show data all | 56.498 GB (25.354 GB + 31.145 GB) | 55.223 GB (25.346 GB + 29.878 GB) |
CPU usage:
-
During the Performance768D10M load, CPU utilization was relatively stable overall.
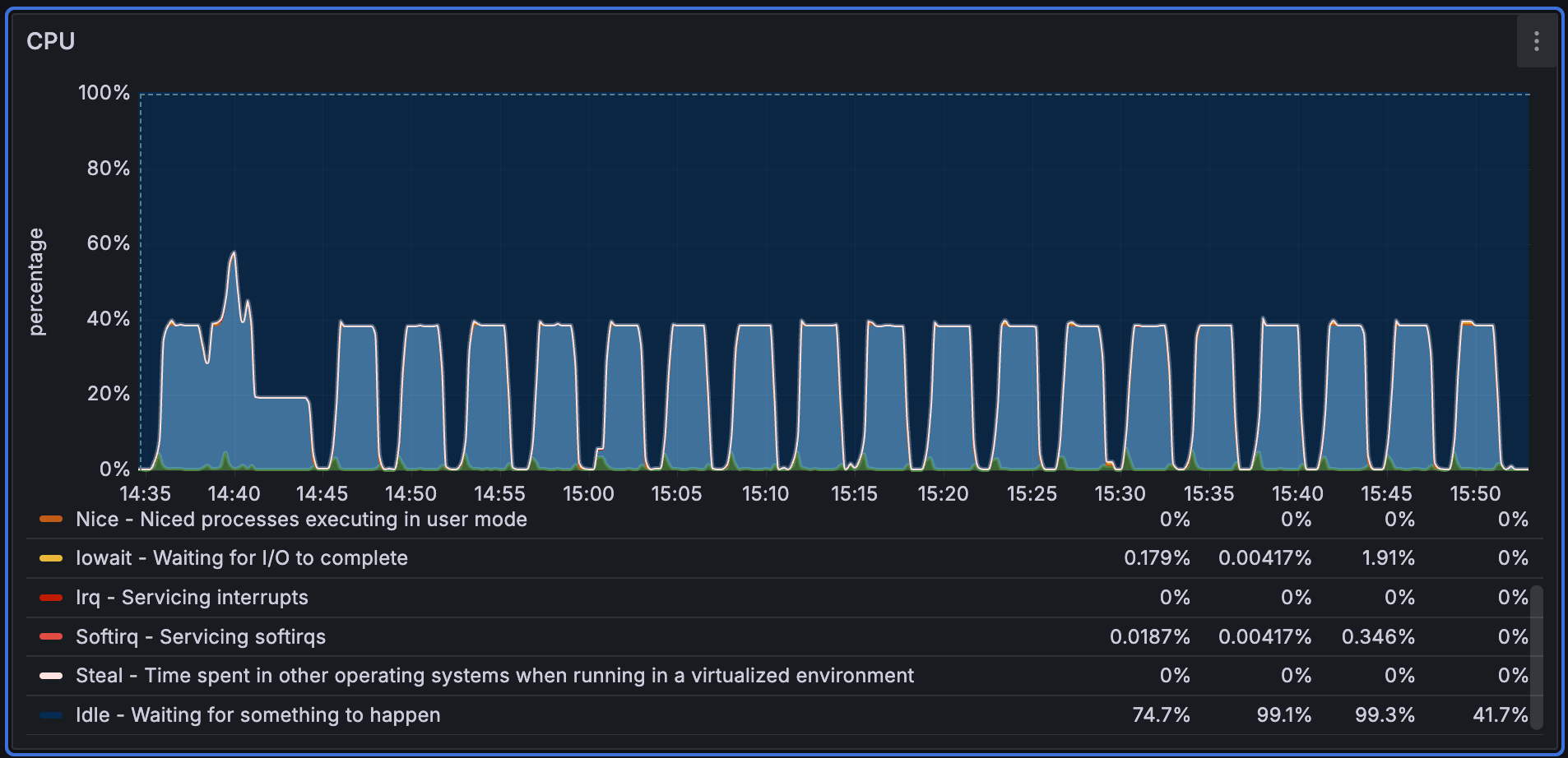
-
Performance1536D5M has a smaller data volume and a smaller batch size, so CPU utilization fluctuates more frequently during the load phase.
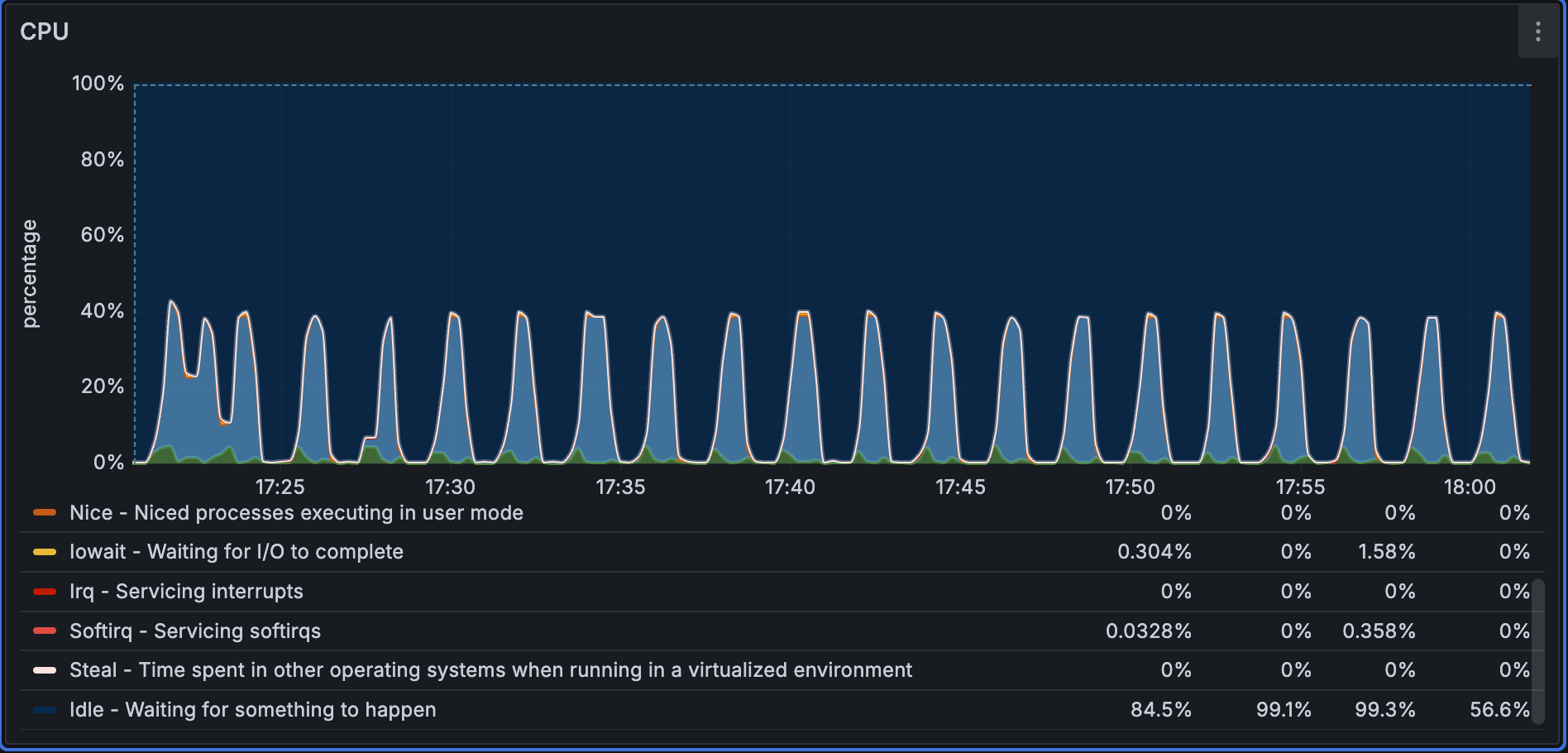
Query Performance
While maintaining a high recall rate, the single-node deployment can reach hundreds of QPS and keep query latency low.
Summary Metrics
| Dataset | BestQPS | Recall@100 |
|---|---|---|
| Performance768D10M | 481.9356 | 0.9207 |
| Performance1536D5M | 414.7342 | 0.9677 |
Performance768D10M Details (inner_product, 10M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Average Latency |
|---|---|---|---|---|
| 10 | 116.2000 | 0.0932 | 0.0933 | 0.0861 |
| 40 | 455.9485 | 0.1102 | 0.1225 | 0.0877 |
| 80 | 481.9356 | 0.2331 | 0.2674 | 0.1658 |
Performance1536D5M Details (inner_product, 5M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Average Latency |
|---|---|---|---|---|
| 10 | 144.3221 | 0.0764 | 0.0800 | 0.0693 |
| 40 | 401.9732 | 0.1271 | 0.1404 | 0.0994 |
| 80 | 414.7342 | 0.2772 | 0.3222 | 0.1925 |
CPU Monitoring
During the cold query phase, the index needs to be loaded into memory, so CPU utilization is relatively low and the system mainly waits on IO. After entering the hot query phase, CPU utilization rises significantly and approaches 100%.
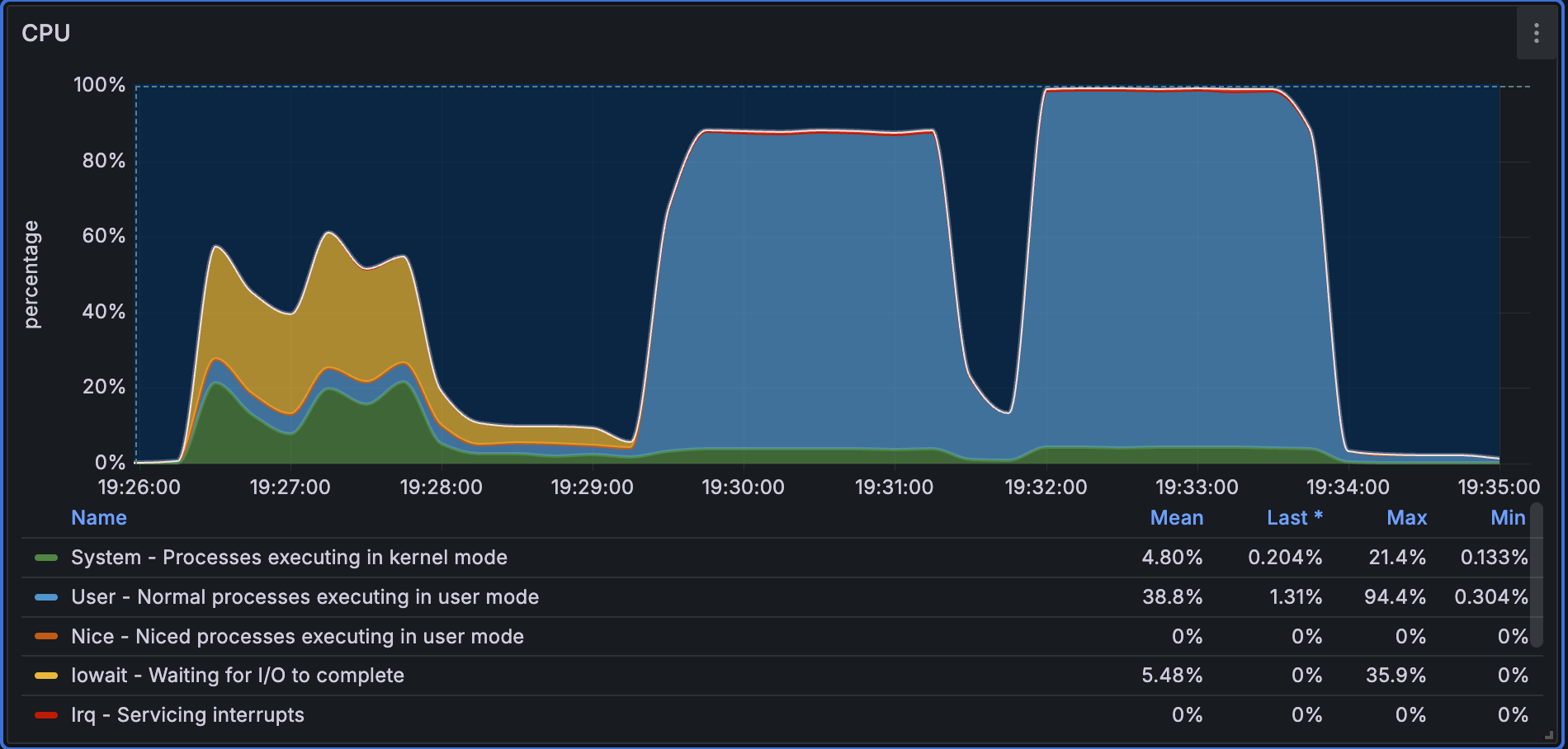
Distributed Benchmark (3 x 16C64GB)
When the data scale exceeds the reasonable memory capacity of a single 16C64GB node, you can scale out horizontally with a multi-BE deployment. This section uses the Performance768D100M dataset (100M rows, 768 dimensions) to show that Doris can still provide online vector query capability at the 100M scale.
This test does not constitute a one-to-one absolute numerical comparison with the small-scale single-node tests. It is more suitable for observing how performance scales with data size.
Load and Index Build
Because the per-node memory cap is 64GB, this test uses vector quantization compression to reduce memory overhead.
| Item | Value |
|---|---|
| Dataset | Performance768D100M |
| Data volume | 100M rows |
| Vector dimension | 768 |
| Batch params | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 |
| Index params | "dim"="768", "index_type"="hnsw", "metric_type"="l2_distance", "pq_m"="384", "pq_nbits"="8", "quantizer"="pq" |
| Build index time | 4h5min |
show data all | 198.809 GB (137.259 GB + 61.550 GB) |
Data distribution after index build:
- 3 buckets in total
- Each bucket contains 34 rowsets, each rowset is about 1.99 GB
- Each rowset contains 6 segments
CPU usage: During the index build, CPU utilization stayed stable at around 50% overall. The CPU was not maxed out for an extended period, leaving some resource headroom.
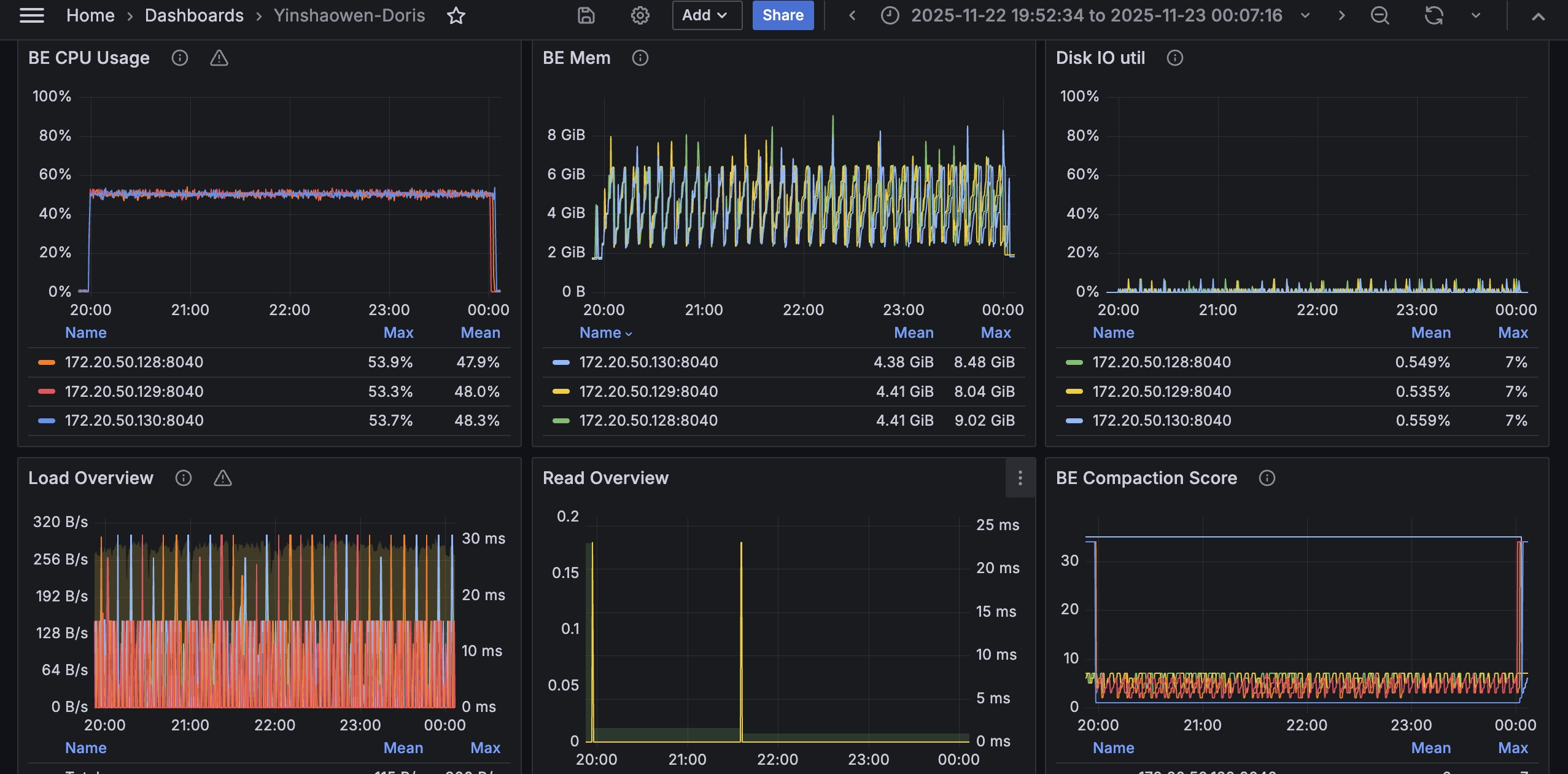
Query Performance
Summary Metrics
| Metric | Value |
|---|---|
| BestQPS | 77.6247 |
| Recall@100 | 0.9294 |
Details (l2_distance, 100M rows)
| Concurrency | QPS | P95 Latency | P99 Latency | Average Latency |
|---|---|---|---|---|
| 10 | 46.5836 | 0.2628 | 0.2791 | 0.2145 |
| 20 | 75.3579 | 0.3251 | 0.3541 | 0.2651 |
| 30 | 77.6247 | 0.5222 | 0.5766 | 0.3860 |
| 40 | 76.6313 | 0.7089 | 0.7854 | 0.5212 |
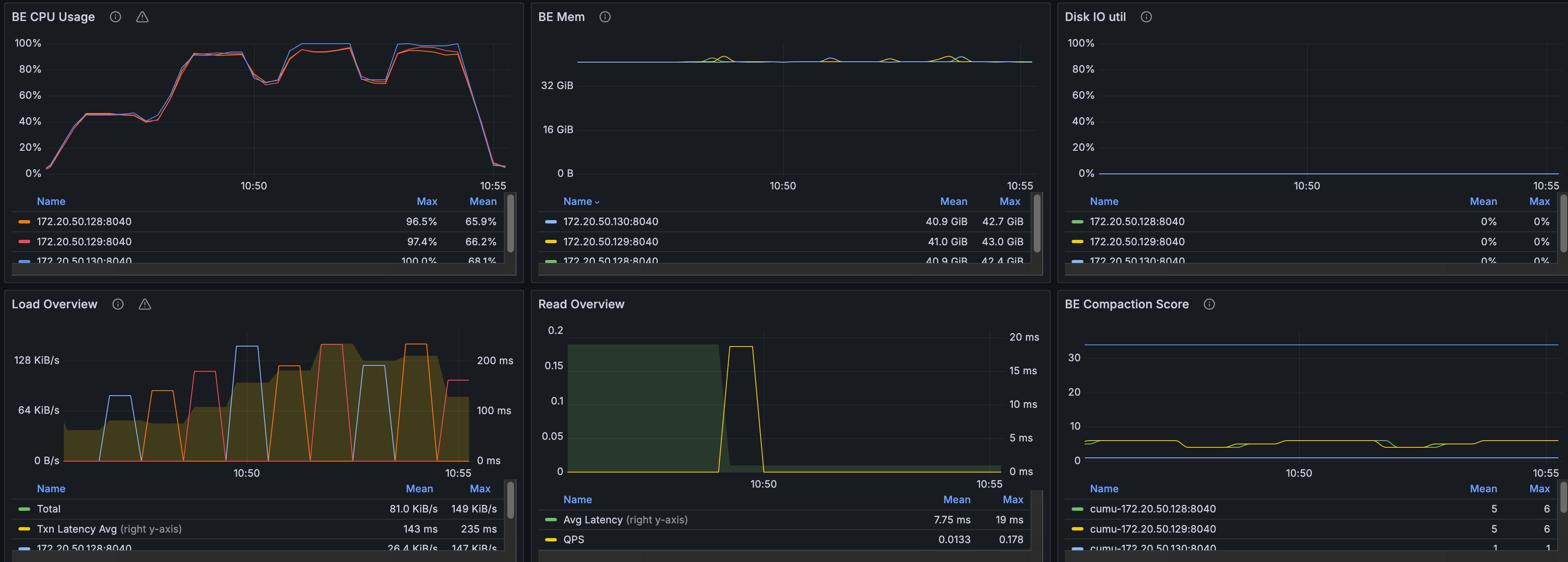
CPU Monitoring
During the query phase, CPU utilization on each node stays at a high level, indicating that the query workload makes good use of the distributed compute resources.
Key Conclusions
- Tens of millions on a single node: At the tens-of-millions vector data scale, a Doris single-node deployment can deliver hundreds of QPS for ANN queries while maintaining a high recall rate (>=0.92).
- Hundreds of millions, distributed: On the 100M vector dataset, a multi-BE deployment combined with vector quantization compression can continue to provide online vector query capability (BestQPS approximately 77, Recall@100 approximately 0.93).
- Horizontal scalability: When the data scale exceeds the memory capacity of a single node, distributed deployment is a viable path to sustain online retrieval capability.
Test Notes
When reading these results, keep the following in mind:
- Different distance metrics: The single-node tests use
inner_product, while the distributed test usesl2_distance. Direct side-by-side comparison of absolute numbers is not recommended. - Different data scales and index parameters: The data scales and index parameters (such as whether quantization is enabled) differ across test groups. The results are more suitable for observing how performance scales with data size.
- Cold-query correction: For the single-node
Performance768D10Mtest, the result at concurrency 10 has been corrected after removing the impact of cold queries.
How to Reproduce
The tests are run with the VectorDBBench tool.
Single-Node Reproduction
# Performance768D10M
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D10M --stream-load-rows-per-batch 500000
# Performance1536D5M
export NUM_PER_BATCH=250000
vectordbbench doris ... --case-type Performance1536D5M --stream-load-rows-per-batch 250000
Distributed 3BE Reproduction
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D100M --stream-load-rows-per-batch 500000
FAQ
Q1: How many vectors can a single 16C64GB node hold at most?
This depends on the vector dimension, whether quantization is enabled, and the index parameters. In this document, 768-dimensional 10M rows (about 56 GB) runs stably on a single 16C64GB node. If the data scale grows further or the dimension is higher, enable vector quantization or use a multi-BE distributed deployment.
Q2: Why is the QPS of the distributed test lower than that of the single-node tests?
The two groups of tests differ in distance metric, data scale, and index parameters (the distributed test enables PQ quantization), so absolute numbers cannot be compared directly. The goal of the distributed test is to validate scalability at large data sizes, not to maximize QPS.
Q3: Why is quantization required on the 100M dataset?
The per-node memory cap is 64GB, and the raw size of 100M 768-dimensional vectors already exceeds this capacity. PQ quantization (pq_m=384, pq_nbits=8) significantly reduces memory consumption, making large-scale online retrieval feasible.
Q4: Does the load duration include index build time?
In the single-node tests, "load duration" is the overall write time. The index is built either during writing or in the background compaction phase. In the distributed test, build index time is listed separately so that the index build cost can be evaluated for large-scale scenarios.