Performance Testing and Analysis
This document presents the query and ingestion performance benchmark results of the Apache Doris vector index (ANN Index). All tests are performed with VectorDBBench, and the results help you:
- Evaluate whether Doris vector retrieval meets your business requirements.
- Understand the trade-offs among recall, query performance, and ingestion speed.
- Reproduce the test results locally and verify production-environment behavior.
For benchmark results on larger datasets (10M / 100M scale) under single-node and distributed deployments, see Large-Scale Performance Benchmarks.
Test Environment
| Item | Configuration |
|---|---|
| Machine spec | 16C 64GB |
| CPU model | Intel(R) Xeon(R) Platinum 8369B CPU @ 2.70GHz |
| Deployment | FE and BE co-located on the same machine |
| Doris version | Apache Doris 4.0.2 |
| Test dataset | VectorDBBench Performance768D1M (768-dimensional vectors, 1 million rows) |
Co-locating FE and BE is not the recommended production deployment. In production, deploy FE and BE on separate machines.
Test Results
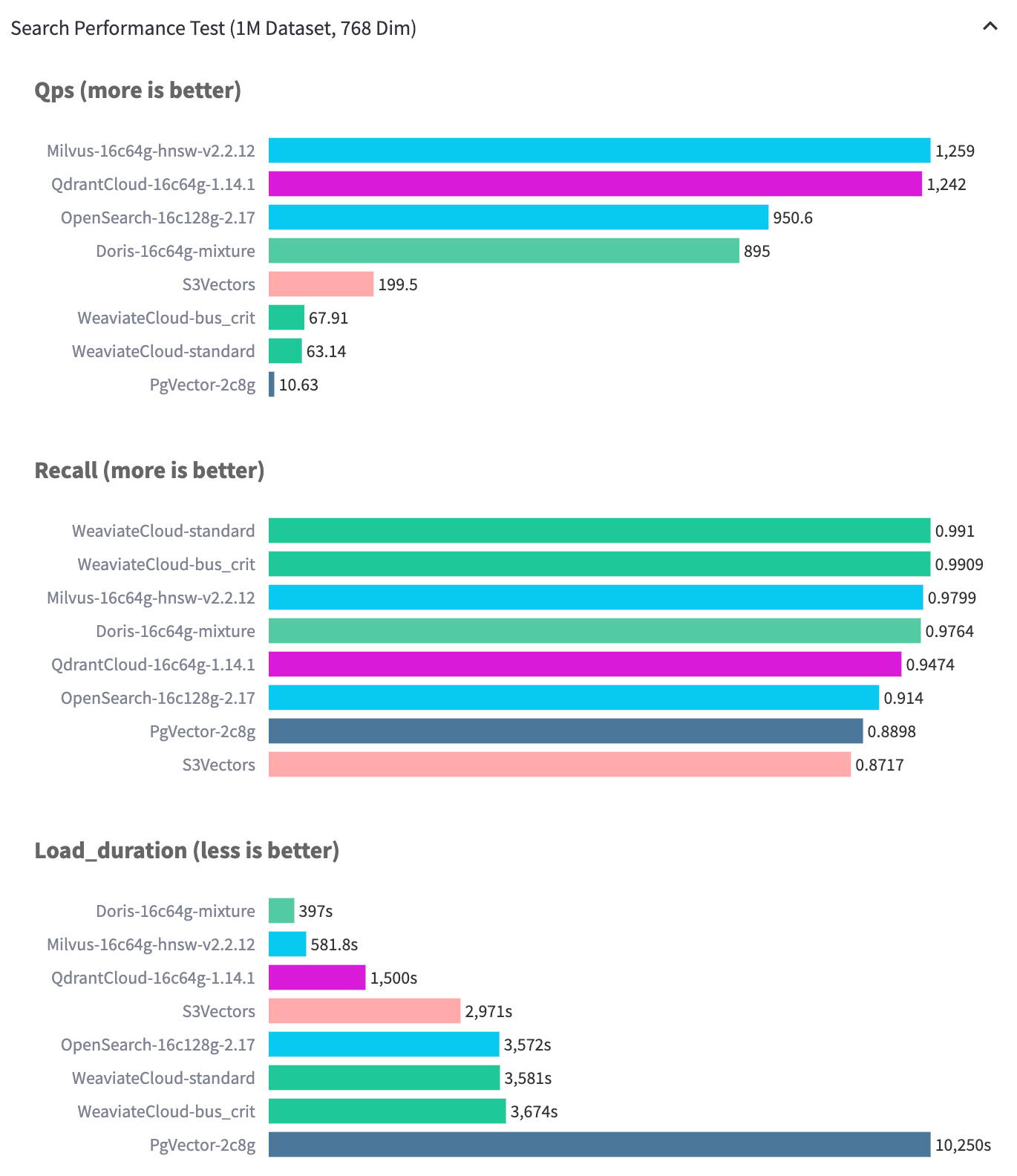
On the Performance768D1M dataset, Apache Doris reaches 989.1 QPS while maintaining above 97% recall, and its ingestion performance is significantly better than that of comparable systems.
Result Analysis
The "Performance Triangle" of Vector Databases
In vector search scenarios, a mature vector database that runs reliably in production typically has to trade off among the following three dimensions:
┌──────────────────────┐
│ Recall │
│ (Higher is Better) │
└──────────▲───────────┘
/ \
/ \
/ \
/ \
/ \
/ \
┌───────────┘ └───────────┐
│ │
│ │
▼ ▼
┌──────────────────────┐ ┌────────────────────────┐
│ Query QPS │ │ Indexing │
│ (Latency / QPS) │ │ Throughput │
│ (Lower Latency Better)│ │ (Higher is Better) │
└──────────────────────┘ └────────────────────────┘
| Dimension | Metric | Desired direction |
|---|---|---|
| Recall | Top-K hit ratio | Higher is better |
| Query QPS / Latency | Queries per second / per-query latency | Higher QPS, lower latency |
| Indexing Throughput | Index build throughput | Higher is better |
These three are typically hard to maximize at the same time, so vector database design has to balance them.
Key HNSW Parameters and Trade-offs
Take HNSW (Hierarchical Navigable Small World), the most widely used vector index in the industry, as an example. It relies on a graph structure for search optimization and has three main tunable hyperparameters:
| Parameter | Role | Impact |
|---|---|---|
max_degree | Maximum out-degree of each node in the graph | Determines graph density and overall connectivity |
ef_construction | Candidate set size during index construction | A larger value produces a higher-quality graph |
hnsw_ef_search | Exploration window size during querying | Directly affects recall and query latency |
Typical tuning trade-offs:
- Increasing
max_degreeandef_constructionsignificantly improves graph connectivity and navigation efficiency, which leads to higher recall. - A higher-quality graph allows
hnsw_ef_searchto be set smaller during queries, which reduces search cost and improves query performance. - The cost is that index construction consumes more compute and memory, which lowers ingestion performance.
This is the typical "trilemma" that vector database design must face.
Apache Doris Optimization Approach
When designing vector search capabilities, Apache Doris aims to build a more balanced performance triangle by:
- Optimizing the underlying execution engine.
- Improving the storage format.
- Engineering-level parallel acceleration of the HNSW build pipeline.
The result is that Doris significantly improves overall index ingestion speed without sacrificing index quality or high recall.
The benchmark results on the Performance768D1M dataset confirm this design goal:
- With consistent index quality, Doris ingestion performance is significantly better than that of comparable systems.
- Graph quality is not reduced in exchange for higher ingestion speed.
- QPS reaches 989.1, recall stays above 97%, and the result is balanced across all three dimensions.
Reproduction Steps
Use the following command to reproduce the test locally:
NUM_PER_BATCH=500000 vectordbbench doris \
--host 127.0.0.1 \
--port 9030 \
--http-port 8030 \
--case-type Performance768D1M \
--db-name vdb \
--num-concurrency 80 \
--stream-load-rows-per-batch 500000 \
--index-prop max_degree=128,ef_construction=256 \
--session-var hnsw_ef_search=100
Key parameters:
| Parameter | Meaning |
|---|---|
--case-type | Selects the test case (here, the 768D1M dataset) |
--num-concurrency | Query concurrency |
--stream-load-rows-per-batch | Rows per batch for Stream Load |
--index-prop | Index build parameters (max_degree, ef_construction) |
--session-var | Session variables at query time (hnsw_ef_search) |
Related Documents
- Large-Scale Performance Benchmarks: Test results on 10M / 100M scale datasets under single-node and distributed deployments.
- HNSW Index Internals
- Vector Index Overview
- Vector Index Practical Guide