Pipeline Execution Engine
The Pipeline Execution Engine is an experimental feature in Apache Doris 2.0, which was later optimized and upgraded in version 2.1 (i.e., PipelineX). In versions 3.0 and later, PipelineX is used as the only execution engine in Doris and renamed to Pipeline Execution Engine.
The goal of pipeline execution engine is to replace the current execution engine of Doris's volcano model, fully release the computing power of multi-core CPUs, and limit the number of Doris's query threads to solve the problem of Doris's execution thread bloat.
Its specific design, implementation and effects can be found in [DSIP-027](DSIP-027: Support Pipeline Exec Engine - DORIS - Apache Software Foundation) and [DSIP-035](DSIP-035: PipelineX Execution Engine - DORIS - Apache Software Foundation).
Principle
The current Doris SQL execution engine is designed based on the traditional volcano model, which has the following problems in a single multi-core scenario:
-
Inability to take full advantage of multi-core computing power to improve query performance,most scenarios require manual setting of parallelism for performance tuning, which is almost difficult to set in production environments.
-
Each instance of a standalone query corresponds to one thread of the thread pool, which introduces two additional problems.
-
Once the thread pool is hit full. Doris' query engine will enter a pseudo-deadlock and will not respond to subsequent queries. At the same time there is a certain probability of entering a logical deadlock situation: for example, all threads are executing an instance's probe task.
-
Blocking arithmetic will take up thread resources,blocking thread resources can not be yielded to instances that can be scheduled, the overall resource utilization does not go up.
-
-
Blocking arithmetic relies on the OS thread scheduling mechanism, thread switching overhead (especially in the scenario of system mixing))
The resulting set of problems drove Doris to implement an execution engine adapted to the architecture of modern multi-core CPUs.
And as shown in the figure below (quoted from[Push versus pull-based loop fusion in query engines](jfp_1800010a (cambridge.org))),The resulting set of problems drove Doris to implement an execution engine adapted to the architecture of modern multi-core CPUs.:
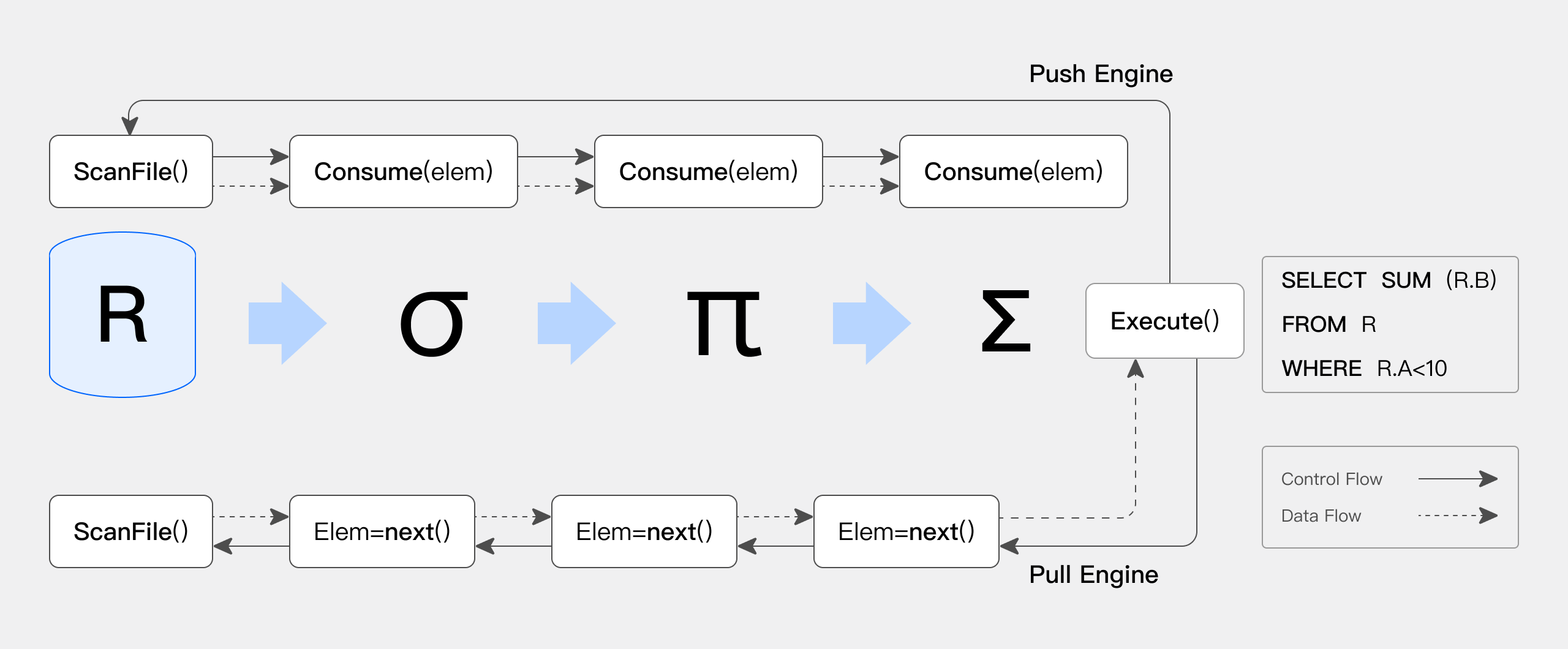
-
Transformation of the traditional pull pull logic-driven execution process into a data-driven execution engine for the push model
-
Blocking operations are asynchronous, reducing the execution overhead caused by thread switching and thread blocking and making more efficient use of the CPU
-
Controls the number of threads to be executed and reduces the resource congestion of large queries on small queries in mixed load scenarios by controlling time slice switching
-
In terms of execution concurrency, pipelineX introduces local exchange optimization to fully utilize CPU resources, and distribute data evenly across different tasks to minimize data skewing. In addition, pipelineX will no longer be constrained by the number of tablets.
-
Logically, multiple pipeline tasks share all shared states of the same pipeline and eliminate additional initialization overhead, such as expressions and some const variables.
-
In terms of scheduling logic, the blocking conditions of all pipeline tasks are encapsulated using Dependency, and the execution logic of the tasks is triggered by external events (such as rpc completion) to enter the runnable queue, thereby eliminating the overhead of blocking polling threads.
-
Profile: Provide users with simple and easy to understand metrics.
This improves the efficiency of CPU execution on mixed-load SQL and enhances the performance of SQL queries.
Usage
Query
- enable_pipeline_engine
Setting the session variable enable_pipeline_engine to true will make BE to use the Pipeline execution engine when performing query execution.
set enable_pipeline_engine = true;
- parallel_pipeline_task_num
The parallel_pipeline_task_num represents the number of Pipeline Tasks for a SQL query to be queried concurrently.The default configuration of Doris is 0, in which case the number of Pipeline Tasks will be automatically set to half of the minimum number of CPUs in the current cluster machine. You can also adjust it according to your own situation.
set parallel_pipeline_task_num = 0;
You can limit the automatically configured concurrency by setting max_instance_num(The default value is 64)
- enable_local_shuffle
Set enable_local_shuffle to true will enable local shuffle optimization. Local shuffle will try to evenly distribute data among different pipeline tasks to avoid data skewing as much as possible.
set enable_local_shuffle = true;
- ignore_storage_data_distribution
Settings ignore_storage_data_distribution is true, it means ignoring the data distribution of the storage layer. When used in conjunction with local shuffle, the concurrency capability of the pipelineX engine will no longer be constrained by the number of storage layer tables, thus fully utilizing machine resources.
set ignore_storage_data_distribution = true;
Load
The engine selected for import are detailed in the Load documentation.
