
リソースグループ
Resource Groupは、compute-storage統合アーキテクチャの下で、異なるワークロード間での物理的な分離を実現するメカニズムです。その基本原理は以下の図に示されています:
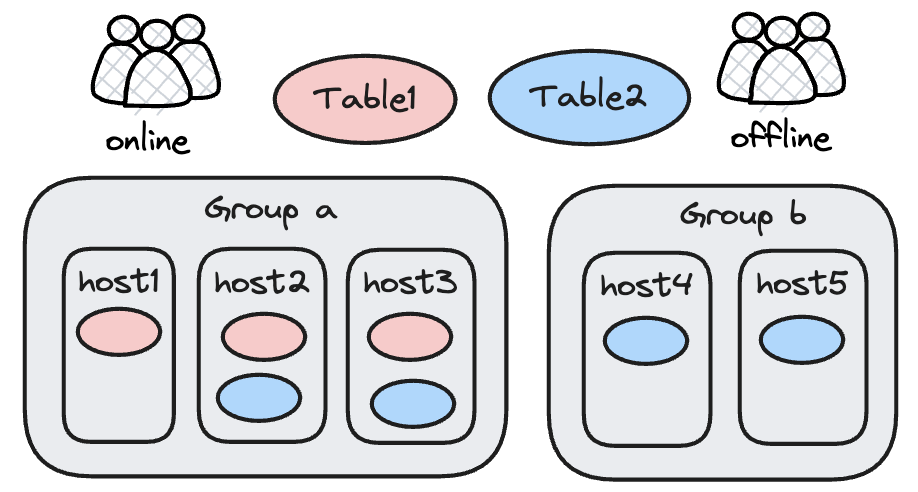
-
タグを使用することで、BEは異なるグループに分割され、各グループはタグの名前で識別されます。例えば、上図では、host1、host2、host3はすべてgroup aに設定され、host4とhost5はgroup bに設定されています。
-
テーブルの異なるレプリカは異なるグループに配置されます。例えば、上図では、table1は3個のレプリカを持ち、すべてgroup aに配置されています。一方、table2は4個のレプリカを持ち、2個がgroup a、2個がgroup bに配置されています。
-
クエリ実行時は、ユーザーに基づいて異なるResource Groupが使用されます。例えば、オンラインユーザーはhost1、host2、host3上のデータのみにアクセスできるため、table1とtable2の両方にアクセスできます。しかし、オフラインユーザーはhost4とhost5のみにアクセスできるため、table2のデータのみにアクセスできます。table1はgroup bに対応するレプリカを持たないため、アクセスするとエラーになります。
本質的に、Resource Groupはテーブルレプリカの配置戦略であるため、以下の利点と制限があります:
-
異なるResource Groupは異なるBEを使用するため、完全に分離されています。グループ内のBEが障害を起こしても、他のグループのクエリには影響しません。データロードには複数のレプリカの成功が必要なため、残りのレプリカ数がquorumを満たさない場合、データロードは依然として失敗します。
-
各Resource Groupは、各テーブルの少なくとも1つのレプリカを持つ必要があります。例えば、5つのResource Groupを確立し、各グループがすべてのテーブルにアクセスできるようにする場合、各テーブルには5つのレプリカが必要となり、大幅なストレージコストが発生する可能性があります。
典型的な使用例
-
読み書き分離:クラスターを2つのResource Groupに分割し、ETLジョブを実行するためのOffline Resource Groupと、オンラインクエリを処理するためのOnline Resource Groupを設けることができます。データは3つのレプリカで保存され、Online Resource Groupに2つ、Offline Resource Groupに1つのレプリカが配置されます。Online Resource Groupは主に高同時実行、低遅延のオンラインデータサービスに使用され、大規模なクエリやオフラインETL操作はOffline Resource Groupのノードを使用して実行できます。これにより、統合されたクラスター内でオンラインとオフラインの両方のサービスを提供できます。
-
異なる事業間の分離:複数の事業間でデータが共有されない場合、各事業にResource Groupを割り当てることで、事業間での干渉を防げます。これにより、複数の物理クラスターを効果的に1つの大きなクラスターに統合して管理できます。
-
異なるユーザー間の分離:例えば、クラスター内に3つのユーザー全員で共有する必要があるビジネステーブルがあるが、ユーザー間のリソース競合を最小限に抑えたい場合、テーブルの3つのレプリカを作成し、3つの異なるResource Groupに保存し、各ユーザーを特定のResource Groupに関連付けることができます。
Resource Groupの設定
BEへのタグ設定
現在のDorisクラスターがhost[1-6]という名前の6つのBEノードを持つと仮定します。初期状態では、すべてのBEノードはデフォルトのresource group(Default)に属しています。
以下のコマンドを使用して、これらの6つのノードを3つのresource group:group_a、group_b、group_cに分割できます。
alter system modify backend "host1:9050" set ("tag.location" = "group_a");
alter system modify backend "host2:9050" set ("tag.location" = "group_a");
alter system modify backend "host3:9050" set ("tag.location" = "group_b");
alter system modify backend "host4:9050" set ("tag.location" = "group_b");
alter system modify backend "host5:9050" set ("tag.location" = "group_c");
alter system modify backend "host6:9050" set ("tag.location" = "group_c");
ここでは、host[1-2]でResource Group group_a、host[3-4]でResource Group group_b、host[5-6]でResource Group group_cを形成します。
注意: BEは1つのResource Groupにのみ所属できます。
Resource Groupによるデータ再配布
Resource Groupを分割した後、異なるResource Group間でユーザーデータの異なるレプリカを配布することができます。UserTableという名前のユーザーテーブルがあり、3つのResource Groupそれぞれに1つのレプリカを保存したいと仮定します。これは以下のテーブル作成文により実現できます:
create table UserTable
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"
)
このようにして、UserTableのデータは3つのレプリカに保存され、それぞれgroup_a、group_b、group_cのリソースグループ内のノードに配置されます。
以下の図は、現在のノードの分割とデータ分散を示しています:
┌────────────────────────────────────────────────────┐
│ │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ host1 │ │ host2 │ │
│ │ ┌─────────────┐ │ │ │ │
│ group_a │ │ replica1 │ │ │ │ │
│ │ └─────────────┘ │ │ │ │
│ │ │ │ │ │
│ └──────────────────┘ └──────────────────┘ │
│ │
├────────────────────────────────────────────────────┤
├────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ host3 │ │ host4 │ │
│ │ │ │ ┌─────────────┐ │ │
│ group_b │ │ │ │ replica2 │ │ │
│ │ │ │ └─────────────┘ │ │
│ │ │ │ │ │
│ └──────────────────┘ └──────────────────┘ │
│ │
├────────────────────────────────────────────────────┤
├────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ host5 │ │ host6 │ │
│ │ │ │ ┌─────────────┐ │ │
│ group_c │ │ │ │ replica3 │ │ │
│ │ │ │ └─────────────┘ │ │
│ │ │ │ │ │
│ └──────────────────┘ └──────────────────┘ │
│ │
└────────────────────────────────────────────────────┘
データベースに非常に多数のテーブルが含まれている場合、各テーブルの分散戦略を変更するのは面倒な作業になることがあります。そのため、Dorisはデータベースレベルで統一されたデータ分散戦略を設定することもサポートしていますが、個別のテーブルの設定はデータベースレベルの設定よりも高い優先度を持ちます。例として、4つのテーブルを持つデータベースdb1を考えてみます:table1はgroup_a:1,group_b:2のレプリカ分散戦略を必要とし、table2、table3、table4はgroup_c:1,group_b:2の戦略を必要とします。
デフォルトの分散戦略でdb1を作成するには、以下のステートメントを使用できます:
CREATE DATABASE db1 PROPERTIES (
"replication_allocation" = "tag.location.group_c:1, tag.location.group_b:2"
)
特定の分散戦略でtable1を作成する:
CREATE TABLE table1
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:1, tag.location.group_b:2"
)
table2、table3、table4については、作成文でreplication_allocationを指定する必要はありません。これらのテーブルはデータベースレベルのデフォルト戦略を継承するためです。
データベースレベルでレプリカ配布戦略を変更しても、既存のテーブルには影響しません。
ユーザーのResource Groupの設定
以下の文を使用して、ユーザーの特定のresource groupへのアクセスを制限できます。例えば、user1はgroup_a resource group内のノードのみを使用でき、user2はgroup_bのみを使用でき、user3は3つすべてのresource groupを使用できます:
set property for 'user1' 'resource_tags.location' = 'group_a';
set property for 'user2' 'resource_tags.location' = 'group_b';
set property for 'user3' 'resource_tags.location' = 'group_a, group_b, group_c';
設定後、user1がUserTableにクエリを実行すると、group_aリソースグループ内のノードのデータレプリカにのみアクセスし、このグループのコンピューティングリソースを使用します。User3のクエリは、任意のリソースグループのレプリカとコンピューティングリソースを使用できます。
注意: デフォルトでは、ユーザーのresource_tags.locationプロパティは空です。バージョン2.0.2より前では、ユーザーはタグによる制限を受けず、任意のリソースグループを使用できます。バージョン2.0.3以降では、一般ユーザーはデフォルトでデフォルトリソースグループのみ使用できます。Rootユーザーとadminユーザーは任意のリソースグループを使用できます。
resource_tags.locationプロパティを変更した後、変更を有効にするためにユーザーは接続を再確立する必要があります。
データロードジョブのリソースグループ割り当て
データロードジョブ(insert、broker load、routine load、stream loadなどを含む)のリソース使用量は、2つの部分に分けることができます:
-
コンピューティング部分:データソースの読み取り、データ変換、および配布を担当します。
-
書き込み部分:データのエンコーディング、圧縮、およびディスクへの書き込みを担当します。
書き込みリソースはデータレプリカが配置されているノード上に存在する必要があり、コンピューティングリソースは任意のノードから割り当てることができるため、Resource Groupsはデータロードシナリオにおいてコンピューティング部分で使用されるリソースのみを制限できます。