
高同時実行性LOADの最適化(グループコミット)
高頻度小バッチ書き込みシナリオでは、従来のロード方式には以下の課題があります:
- 各ロードが独立したトランザクションを作成するため、FEがSQLを解析して実行プランを生成する必要があり、全体的なパフォーマンスに影響する
- 各ロードが新しいバージョンを生成するため、バージョンが急速に増加し、バックグラウンドコンパクションの圧迫が増加する
これらの問題を解決するため、DorisはGroup Commitメカニズムを導入しました。Group Commitは新しいロード方式ではなく、既存のロード方式の最適化拡張であり、主に以下を対象としています:
INSERT INTO tbl VALUES(...)文- Stream Load
バックグラウンドで複数の小バッチロードを1つの大きなトランザクションコミットにマージすることで、高同時実行小バッチ書き込みのパフォーマンスを大幅に向上させます。さらに、PreparedStatementでGroup Commitを使用すると、より高いパフォーマンス向上を実現できます。
Group Commitモード
Group Commitには3つのモードがあります:
-
オフモード(
off_mode)Group Commitが無効です。
-
同期モード(
sync_mode)Dorisはロードとテーブルの
group_commit_intervalプロパティに基づいて複数のロードを1つのトランザクションでコミットし、トランザクションコミット後に戻ります。これは、ロード後に即座にデータの可視性を必要とする高同時実行書き込みシナリオに適しています。 -
非同期モード(
async_mode)DorisはまずデータをWAL(Write Ahead Log)に書き込み、その後即座に戻ります。Dorisはロードとテーブルの
group_commit_intervalプロパティに基づいて非同期でデータをコミットし、コミット後にデータを可視化します。WALがディスク領域を過度に占有することを防ぐため、大きな単一ロードに対しては自動的にsync_modeに切り替わります。これは、書き込み遅延に敏感で高頻度書き込みシナリオに適しています。WAL数は、FE httpインターフェースを通じてこちらに示されているように確認できます、またはBEメトリクスで
walキーワードを検索することで確認できます。
Group Commitの使用方法
テーブル構造を以下と仮定します:
CREATE TABLE `dt` (
`id` int(11) NOT NULL,
`name` varchar(50) NULL,
`score` int(11) NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
JDBCの使用
ユーザーがJDBCのinsert into valuesメソッドを使用して書き込みを行う際、SQLの解析と計画のオーバーヘッドを削減するため、FE側でMySQLプロトコルのPreparedStatement機能をサポートしています。PreparedStatementを使用すると、SQLとその負荷計画がセッションレベルのメモリキャッシュにキャッシュされ、後続の負荷は直接キャッシュされたオブジェクトを使用し、FEのCPU負荷を軽減します。以下は、JDBCでPreparedStatementを使用する例です:
1. JDBC URLを設定し、サーバー側でPrepared Statementを有効にする
url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500
2. group_commitセッション変数を以下の2つの方法のうちいずれかで設定する:
- JDBC URLに
sessionVariables=group_commit=async_modeを追加することによって
url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500&sessionVariables=group_commit=async_mode
- SQL実行を通じて
try (Statement statement = conn.createStatement()) {
statement.execute("SET group_commit = async_mode;");
}
3. PreparedStatementを使用する
private static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
private static final String URL_PATTERN = "jdbc:mysql://%s:%d/%s?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=50$sessionVariables=group_commit=async_mode";
private static final String HOST = "127.0.0.1";
private static final int PORT = 9087;
private static final String DB = "db";
private static final String TBL = "dt";
private static final String USER = "root";
private static final String PASSWD = "";
private static final int INSERT_BATCH_SIZE = 10;
private static void groupCommitInsertBatch() throws Exception {
Class.forName(JDBC_DRIVER);
// add rewriteBatchedStatements=true and cachePrepStmts=true in JDBC url
// set session variables by sessionVariables=group_commit=async_mode in JDBC url
try (Connection conn = DriverManager.getConnection(
String.format(URL_PATTERN, HOST, PORT, DB), USER, PASSWD)) {
String query = "insert into " + TBL + " values(?, ?, ?)";
try (PreparedStatement stmt = conn.prepareStatement(query)) {
for (int j = 0; j < 5; j++) {
// 10 rows per insert
for (int i = 0; i < INSERT_BATCH_SIZE; i++) {
stmt.setInt(1, i);
stmt.setString(2, "name" + i);
stmt.setInt(3, i + 10);
stmt.addBatch();
}
int[] result = stmt.executeBatch();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
注意:高頻度のinsert into文は大量の監査ログを出力し、最終的なパフォーマンスに影響を与えるため、prepared statement監査ログの出力はデフォルトで無効になっています。セッション変数の設定を通じて、prepared statement監査ログを出力するかどうかを制御できます。
# Configure session variable to enable printing prepared statement audit log, default is false
set enable_prepared_stmt_audit_log=true;
JDBC の使用方法の詳細については、Using Insert Method to Synchronize Data を参照してください。
Group Commit での Golang の使用
Golang はプリペアドステートメントのサポートが限定的であるため、手動でクライアント側でのバッチ処理を行うことで Group Commit のパフォーマンスを向上させることができます。以下はサンプルプログラムです:
package main
import (
"database/sql"
"fmt"
"math/rand"
"strings"
"sync"
"sync/atomic"
"time"
_ "github.com/go-sql-driver/mysql"
)
const (
host = "127.0.0.1"
port = 9038
db = "test"
user = "root"
password = ""
table = "async_lineitem"
)
var (
threadCount = 20
batchSize = 100
)
var totalInsertedRows int64
var rowsInsertedLastSecond int64
func main() {
dbDSN := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?parseTime=true", user, password, host, port, db)
db, err := sql.Open("mysql", dbDSN)
if err != nil {
fmt.Printf("Error opening database: %s\n", err)
return
}
defer db.Close()
var wg sync.WaitGroup
for i := 0; i < threadCount; i++ {
wg.Add(1)
go func() {
defer wg.Done()
groupCommitInsertBatch(db)
}()
}
go logInsertStatistics()
wg.Wait()
}
func groupCommitInsertBatch(db *sql.DB) {
for {
valueStrings := make([]string, 0, batchSize)
valueArgs := make([]interface{}, 0, batchSize*16)
for i := 0; i < batchSize; i++ {
valueStrings = append(valueStrings, "(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)")
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, rand.Intn(1000))
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, sql.NullFloat64{Float64: 1.0, Valid: true})
valueArgs = append(valueArgs, "N")
valueArgs = append(valueArgs, "O")
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, time.Now())
valueArgs = append(valueArgs, "DELIVER IN PERSON")
valueArgs = append(valueArgs, "SHIP")
valueArgs = append(valueArgs, "N/A")
}
stmt := fmt.Sprintf("INSERT INTO %s VALUES %s",
table, strings.Join(valueStrings, ","))
_, err := db.Exec(stmt, valueArgs...)
if err != nil {
fmt.Printf("Error executing batch: %s\n", err)
return
}
atomic.AddInt64(&rowsInsertedLastSecond, int64(batchSize))
atomic.AddInt64(&totalInsertedRows, int64(batchSize))
}
}
func logInsertStatistics() {
for {
time.Sleep(1 * time.Second)
fmt.Printf("Total inserted rows: %d\n", totalInsertedRows)
fmt.Printf("Rows inserted in the last second: %d\n", rowsInsertedLastSecond)
rowsInsertedLastSecond = 0
}
}
INSERT INTO VALUES
- 非同期モード
# Configure session variable to enable group commit (default is off_mode), enable asynchronous mode
mysql> set group_commit = async_mode;
# The returned label is prefixed with group_commit, indicating whether group commit is used
mysql> insert into dt values(1, 'Bob', 90), (2, 'Alice', 99);
Query OK, 2 rows affected (0.05 sec)
{'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'}
# The label, txn_id, and previous one are the same, indicating that they are accumulated into the same import task
mysql> insert into dt(id, name) values(3, 'John');
Query OK, 1 row affected (0.01 sec)
{'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'}
# Cannot query immediately
mysql> select * from dt;
Empty set (0.01 sec)
# 10 seconds later, data can be queried, and data visibility delay can be controlled by table attribute group_commit_interval.
mysql> select * from dt;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Bob | 90 |
| 2 | Alice | 99 |
| 3 | John | NULL |
+------+-------+-------+
3 rows in set (0.02 sec)
- 同期モード
# Configure session variable to enable group commit (default is off_mode), enable synchronous mode
mysql> set group_commit = sync_mode;
# The returned label is prefixed with group_commit, indicating whether group commit is used, and import time is at least table attribute group_commit_interval.
mysql> insert into dt values(4, 'Bob', 90), (5, 'Alice', 99);
Query OK, 2 rows affected (10.06 sec)
{'label':'group_commit_d84ab96c09b60587_ec455a33cb0e9e87', 'status':'PREPARE', 'txnId':'3007', 'query_id':'fc6b94085d704a94-a69bfc9a202e66e2'}
# Data can be read immediately
mysql> select * from dt;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Bob | 90 |
| 2 | Alice | 99 |
| 3 | John | NULL |
| 4 | Bob | 90 |
| 5 | Alice | 99 |
+------+-------+-------+
5 rows in set (0.03 sec)
- オフモード
mysql> set group_commit = off_mode;
Stream Load
data.csv に以下が含まれていると仮定します:
6,Amy,60
7,Ross,98
- 非同期モード
# Import with "group_commit:async_mode" configuration in header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:async_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load
{
"TxnId": 7009,
"Label": "group_commit_c84d2099208436ab_96e33fda01eddba8",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 35,
"StreamLoadPutTimeMs": 5,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 26
}
# The returned GroupCommit is true, indicating that the group commit process is entered
# The returned Label is prefixed with group_commit, indicating the label associated with the import that truly consumes data
- 同期モード
# Import with "group_commit:sync_mode" configuration in header
curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:sync_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load
{
"TxnId": 3009,
"Label": "group_commit_d941bf17f6efcc80_ccf4afdde9881293",
"Comment": "",
"GroupCommit": true,
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 19,
"LoadTimeMs": 10044,
"StreamLoadPutTimeMs": 4,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 10038
}
# The returned GroupCommit is true, indicating that the group commit process is entered
# The returned Label is prefixed with group_commit, indicating the label associated with the import that truly consumes data
Stream Loadの使用方法については、Stream Loadを参照してください。
時間間隔(デフォルト10秒)またはデータ量(デフォルト64 MB)のいずれかの条件が満たされると、データは自動的にコミットされます。これらのパラメータは併用し、実際のシナリオに基づいて調整する必要があります。
コミット間隔の変更
デフォルトのコミット間隔は10秒です。ユーザーはテーブル設定を通じて調整できます:
# Modify commit interval to 2 seconds
ALTER TABLE dt SET ("group_commit_interval_ms" = "2000");
パラメータ調整の推奨事項:
-
より短い間隔(例:2秒):
- 利点: データ可視性レイテンシが低く、高いリアルタイム性能が必要なシナリオに適している
- 欠点: コミット数が多く、バージョン増加が速く、バックグラウンドコンパクション圧力が高い
-
より長い間隔(例:30秒):
- 利点: コミットバッチが大きく、バージョン増加が遅く、システムオーバーヘッドが低い
- 欠点: データ可視性レイテンシが高い
データ可視性遅延に対するビジネスの許容度に基づいて設定することを推奨します。システム圧力が高い場合は、間隔を増加することを検討してください。
コミットデータボリュームの変更
Group Commitのデフォルトコミットデータボリュームは64 MBで、ユーザーはテーブル設定を通じて調整できます:
# Modify commit data volume to 128MB
ALTER TABLE dt SET ("group_commit_data_bytes" = "134217728");
パラメータ調整の推奨事項:
-
より小さなしきい値(例:32MB):
- 長所:メモリ使用量が少ない、リソースに制約のある環境に適している
- 短所:コミットバッチが小さい、スループットが制限される可能性がある
-
より大きなしきい値(例:256MB):
- 長所:バッチコミット効率が高い、システムスループットが向上する
- 短所:より多くのメモリを使用する
システムメモリリソースとデータ信頼性要件に基づいてバランスを取ることを推奨します。メモリが十分でより高いスループットが望ましい場合は、128MB以上への増加を検討してください。
BE設定
-
group_commit_wal_path-
説明:group commit WALファイルを保存するディレクトリ
-
デフォルト:設定された各
storage_root_pathの下にwalディレクトリを作成します。設定例:
group_commit_wal_path=/data1/storage/wal;/data2/storage/wal;/data3/storage/wal -
使用制限
-
Group Commit制限
-
INSERT INTO VALUES文は以下の場合でnon-Group Commitモードに降格します:- トランザクション書き込み(
Begin; INSERT INTO VALUES; COMMIT) - ラベル指定(
INSERT INTO dt WITH LABEL {label} VALUES) - 式を含むVALUES(
INSERT INTO dt VALUES (1 + 100)) - カラム更新書き込み
- テーブルが軽量モード変更をサポートしていない
- トランザクション書き込み(
-
Stream Loadは以下の場合でnon-Group Commitモードに降格します:- 2段階コミットの使用
- ラベル指定(
-H "label:my_label") - カラム更新書き込み
- テーブルが軽量モード変更をサポートしていない
-
-
Uniqueモデル
- Group Commitはコミット順序を保証しないため、データの一貫性を確保するためにSequenceカラムの使用を推奨します。
-
WAL制限
async_modeはWALにデータを書き込み、成功後に削除し、失敗時はWALを通じて回復します。- WALファイルは1つのBE上に単一レプリカで保存されるため、ディスク破損やファイルの誤削除によりデータ損失が発生する可能性があります。
- BEノードをオフラインにする際は、データ損失を防ぐため
DECOMMISSIONコマンドを使用してください。 async_modeは以下の場合でsync_modeに切り替わります:- ロードデータボリュームが過大(WAL単一ディレクトリ容量の80%を超える)
- データボリューム不明なチャンク形式ストリームロード
- ディスク容量不足
- 重量級Schema Change中、Group Commitの書き込みは拒否され、クライアントは再試行が必要です。
パフォーマンス
Stream LoadとJDBC(async mode)を使用して、少量データの高同時実行シナリオにおけるgroup commitの書き込みパフォーマンステストを個別に実施しました。
Stream Load
環境
-
1台のFront End(FE)サーバー: 8コアCPU、16GB RAM、100GB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
-
3台のBackend(BE)サーバー: 16コアCPU、64GB RAM、1TB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
-
1台のテストクライアント: 16コアCPU、64GB RAM、100GB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
-
テスト版はDoris-2.1.5です。
データセット
httplogs、31 GB、247249096行(2億4700万行)
テストツール
テスト方法
non group_commitとgroup_commit=async modeモード間で、リクエストあたりの異なるデータサイズと同時実行レベルでテストを実施。
テスト結果
| Load方式 | 単一同時実行データサイズ | 同時実行数 | 実行時間(秒) | 行/秒 | MB/秒 |
|---|---|---|---|---|---|
| group_commit | 10 KB | 10 | 3306 | 74,787 | 9.8 |
| group_commit | 10 KB | 30 | 3264 | 75,750 | 10.0 |
| group_commit | 100 KB | 10 | 424 | 582,447 | 76.7 |
| group_commit | 100 KB | 30 | 366 | 675,543 | 89.0 |
| group_commit | 500 KB | 10 | 187 | 1,318,661 | 173.7 |
| group_commit | 500 KB | 30 | 183 | 1,351,087 | 178.0 |
| group_commit | 1 MB | 10 | 178 | 1,385,148 | 182.5 |
| group_commit | 1 MB | 30 | 178 | 1,385,148 | 182.5 |
| group_commit | 10 MB | 10 | 177 | 1,396,887 | 184.0 |
| non group_commit | 1 MB | 10 | 2824 | 87,536 | 11.5 |
| non group_commit | 10 MB | 10 | 450 | 549,442 | 68.9 |
| non group_commit | 10 MB | 30 | 177 | 1,396,887 | 184.0 |
上記のテストでは、BEのCPU使用率は10-40%の間で変動しています。
group_commitは効果的にロードパフォーマンスを向上させ、バージョン数を削減することでcompactionの負荷を軽減します。
JDBC
環境
1台のFront End(FE)サーバー: 8コアCPU、16GB RAM、100GB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
1台のBackend(BE)サーバー: 16コアCPU、64GB RAM、500GB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
1台のテストクライアント: 16コアCPU、64GB RAM、100GB ESSD PL1 SSD 1台を搭載したAlibaba Cloud。
テスト版はDoris-2.1.5です。
パフォーマンス向上のためprepared statement監査ログの出力を無効化。
データセット
- tpch sf10の
lineitemテーブルのデータ、20ファイル、14 GB、1億2000万行
テスト方法
テスト方法
txtfilereaderを使用してmysqlwriterにデータを書き込み、INSERTSQL毎に異なる同時実行数と行数を設定。
テスト結果
| insert毎の行数 | 同時実行数 | 行/秒 | MB/秒 |
|---|---|---|---|
| 100 | 10 | 107,172 | 11.47 |
| 100 | 20 | 140,317 | 14.79 |
| 100 | 30 | 142,882 | 15.28 |
上記のテストでは、BEのCPU使用率は10-20%の間で変動し、FEは60-70%の間で変動しています。
Insert into Sync Mode小バッチデータ
マシン構成
- 1台のFront-End(FE): Alibaba Cloud、16コアCPU、64GB RAM、500GB ESSD PL1クラウドディスク 1台
- 5台のBack-End(BE)ノード: Alibaba Cloud、16コアCPU、64GB RAM、1TB ESSD PL1クラウドディスク 1台。
- 1台のテストクライアント: Alibaba Cloud、16コアCPU、64GB RAM、100GB ESSD PL1クラウドディスク 1台
- テスト版: Doris-2.1.5
データセット
-
tpch sf10の
lineitemテーブルのデータ。 -
create table文は
CREATE TABLE IF NOT EXISTS lineitem (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 32
PROPERTIES (
"replication_num" = "3"
);
テストツール
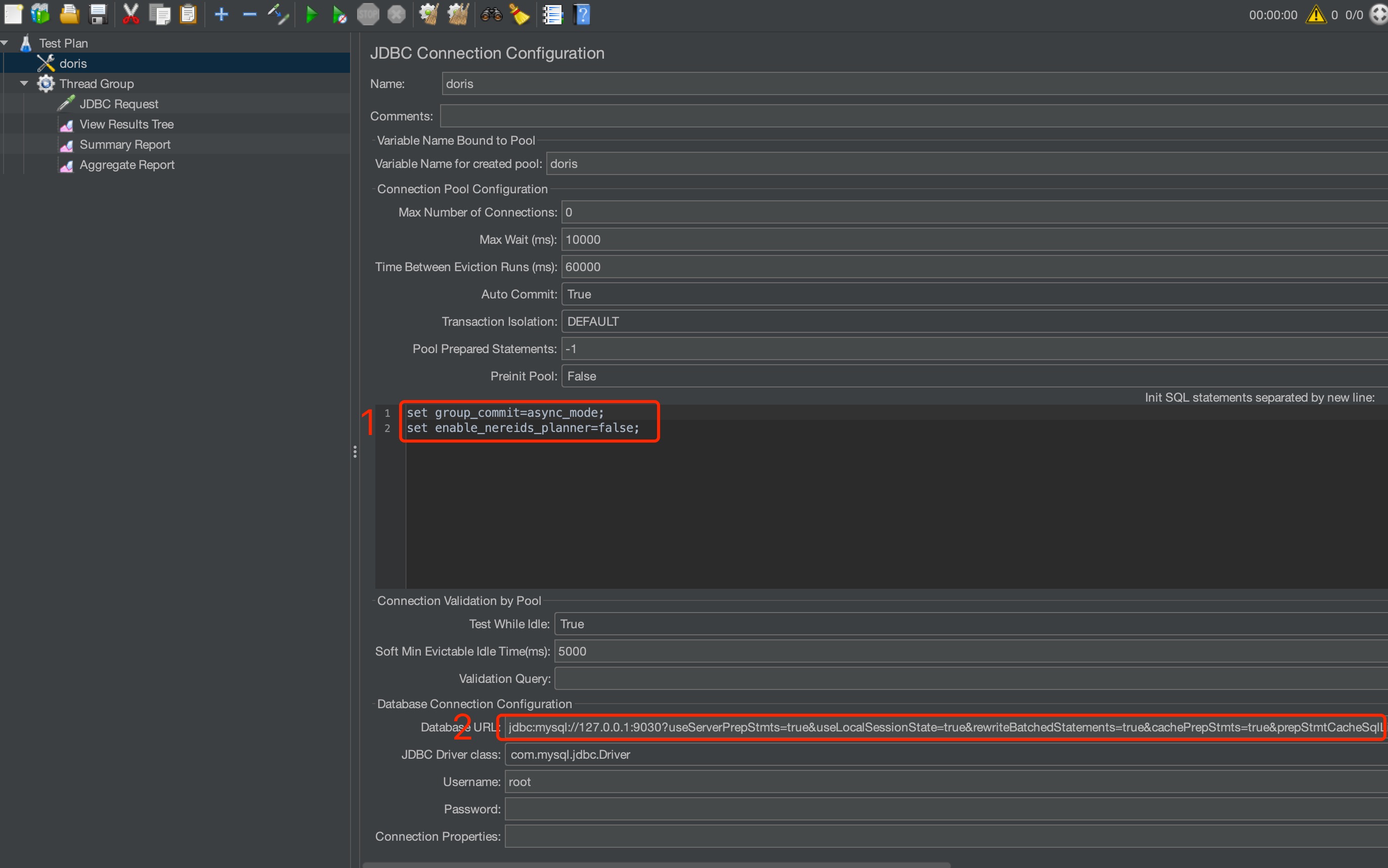
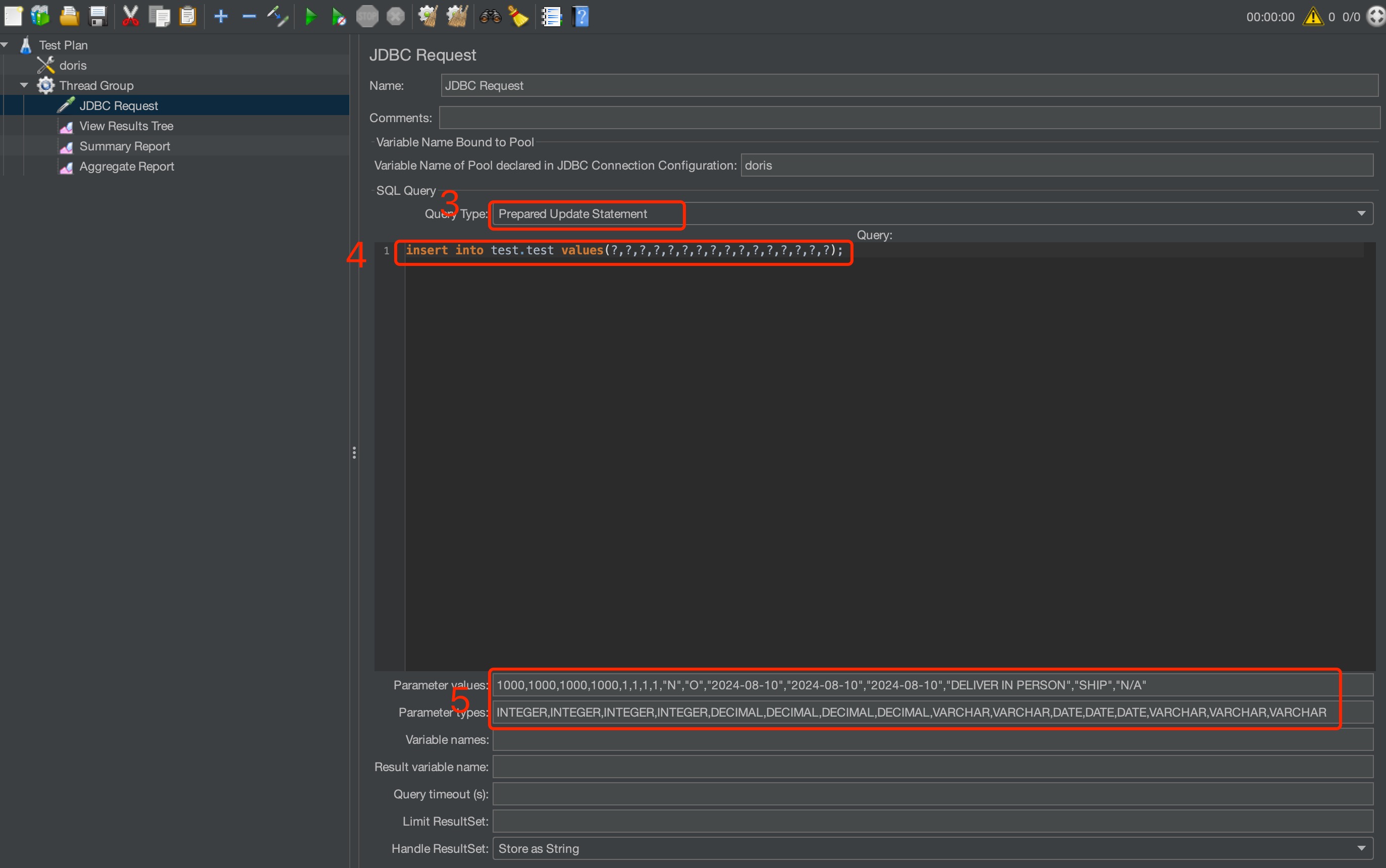
画像に示すJMeterパラメータ設定
-
テスト前のInit Statementを設定: set group_commit=async_mode and set enable_nereids_planner=false.
-
JDBC Prepared Statementを有効化: 完全なURL: jdbc:mysql://127.0.0.1:9030?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=50&sessionVariables=group_commit=async_mode,enable_nereids_planner=false.
-
インポートタイプをPrepared Update Statementに設定。
-
インポート文を設定。
-
インポートする値を設定: インポートする値がデータ型と一対一で一致することを確認。
テスト手法
- JMeterを使用してDorisにデータを書き込み。各スレッドがinsert into文を使用して1回の実行につき1行のデータを書き込み。
テスト結果
-
データ単位:rows per second。
-
以下のテストは30、100、500の並行性に分割。
Sync Mode、5 BE、3レプリカでの30並行ユーザーのパフォーマンステスト
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 321.5 | 307.3 | 285.8 | 224.3 |
Sync Mode、5 BE、3レプリカでの100並行ユーザーのパフォーマンステスト
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 1175.2 | 1108.7 | 1016.3 | 704.5 |
Sync Mode、5 BE、3レプリカでの500並行ユーザーのパフォーマンステスト
| Group Commit Interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 3289.8 | 3686.7 | 3280.7 | 2609.2 |
Insert into Sync Mode大容量バッチデータ
マシン構成
-
1 Front-End (FE):Alibaba Cloud、16コアCPU、64GB RAM、1 x 500GB ESSD PL1クラウドディスク
-
5 Back-End (BE)ノード:Alibaba Cloud、16コアCPU、64GB RAM、1 x 1TB ESSD PL1クラウドディスク。
-
1テストクライアント:Alibaba Cloud、16コアCPU、64GB RAM、1 x 100GB ESSD PL1クラウドディスク
-
テストバージョン:Doris-2.1.5
データセット
- 1000行のInsert into文:
insert into tbl values(1,1)...(1000行省略)
テストツール
テスト手法
- JMeterを使用してDorisにデータを書き込み。各スレッドがinsert into文を使用して1回の実行につき1000行のデータを書き込み。
テスト結果
-
データ単位:rows per second。
-
以下のテストは30、100、500の並行性に分割。
Sync Mode、5 BE、3レプリカでの30並行ユーザーのパフォーマンステスト
| Group commit interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 92.2K | 85.9K | 84K | 83.2K |
Sync Mode、5 BE、3レプリカでの100並行ユーザーのパフォーマンステスト
| Group commit interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 70.4K | 70.5K | 73.2K | 69.4K |
Sync Mode、5 BE、3レプリカでの500並行ユーザーのパフォーマンステスト
| Group commit interval | 10ms | 20ms | 50ms | 100ms |
|---|---|---|---|---|
| 46.3K | 47.7K | 47.4K | 46.5K |