
Broker Load
Broker LoadはMySQL APIから開始されます。DorisはLOAD文の情報に基づいて、ソースからデータを能動的に取得します。Broker Loadは非同期のインポート方法です。Broker Loadタスクの進行状況と結果は、SHOW LOAD文で確認できます。
Broker Loadは、ソースデータがHDFSなどのリモートストレージシステムに保存されており、データ量が比較的大きいシナリオに適しています。
HDFSやS3からの直接読み取りは、[レイクハウス/TVF](../../../data-operate/import/file-format/csv#TVF Load)のHDFS TVFやS3 TVFを通じてインポートすることもできます。現在のTVFベースの「Insert Into」は同期インポートですが、Broker Loadは非同期インポート方法です。
Dorisの初期バージョンでは、S3 LoadとHDFS Loadの両方がWITH BROKERを使用して特定のBrokerプロセスに接続することで実装されていました。
新しいバージョンでは、S3 LoadとHDFS Loadは最も一般的に使用されるインポート方法として最適化されており、追加のBrokerプロセスに依存しなくなりましたが、Broker Loadと似た構文を引き続き使用しています。
歴史的な理由と構文の類似性により、S3 Load、HDFS Load、およびBroker Loadは総称してBroker Loadと呼ばれています。
制限事項
サポートされているデータソース:
- S3プロトコル
- HDFSプロトコル
- カスタムプロトコル(brokerプロセスが必要)
サポートされているデータタイプ:
- CSV
- JSON
- PARQUET
- ORC
サポートされている圧縮タイプ:
- PLAIN
- GZ
- LZO
- BZ2
- LZ4FRAME
- DEFLATE
- LZOP
- LZ4BLOCK
- SNAPPYBLOCK
- ZLIB
- ZSTD
基本原理
ユーザーがインポートタスクを送信すると、Frontend(FE)が対応するプランを生成します。現在のBackend(BE)ノード数とファイルサイズに基づいて、プランは複数のBEノードに配布され実行されます。各BEノードはインポートデータの一部を処理します。
実行中、BEノードはBrokerからデータを取得し、必要な変換を実行してから、データをシステムにインポートします。すべてのBEノードがインポートを完了すると、FEがインポートが成功したかどうかの最終判定を行います。
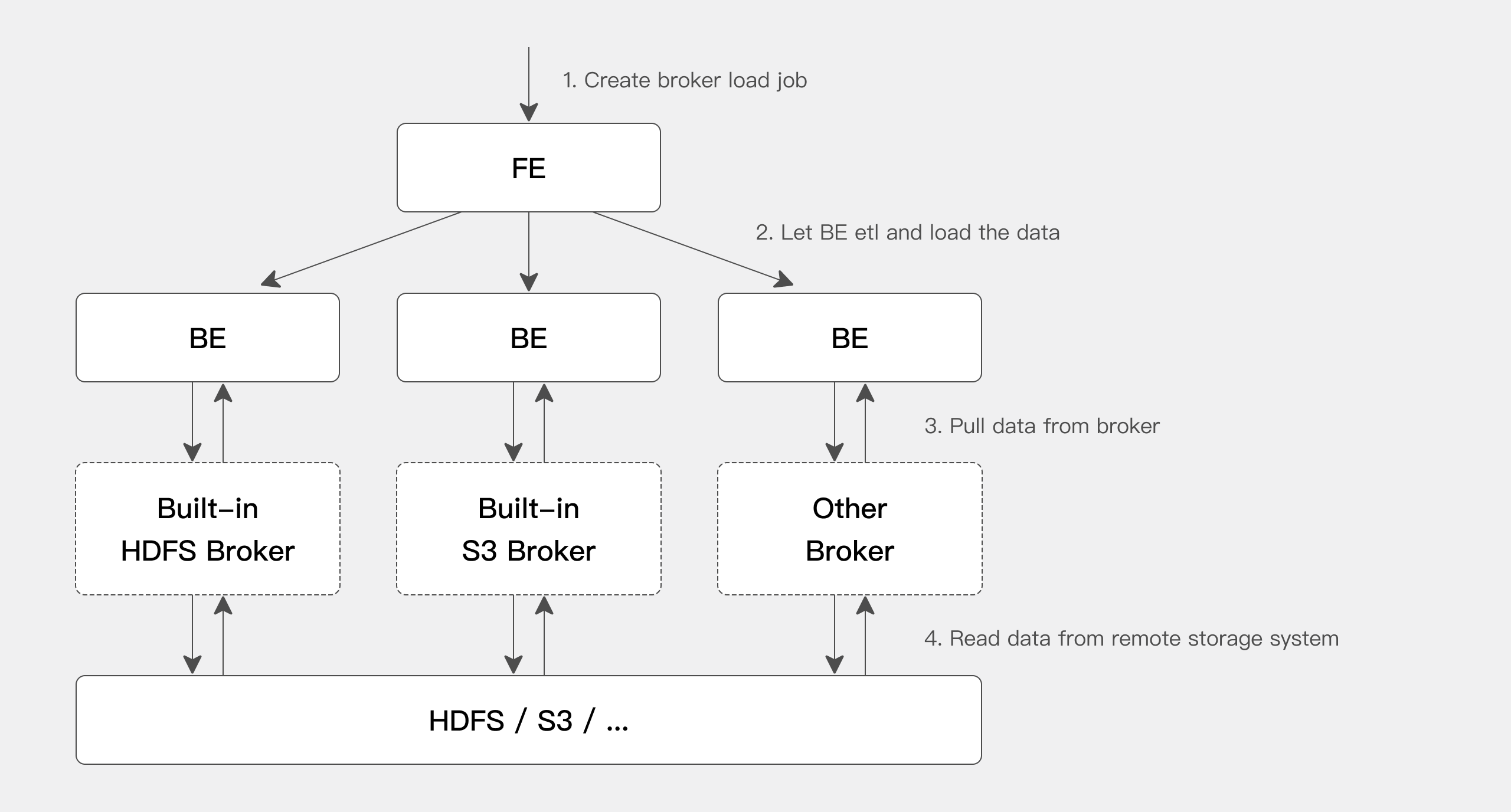
図に示されているように、BEノードは対応するリモートストレージシステムからデータを読み取るためにBrokerプロセスに依存しています。Brokerプロセスの導入は、主に異なるリモートストレージシステムに対応することを目的としています。ユーザーは確立された標準に従って独自のBrokerプロセスを開発できます。Javaを使用して開発できるこれらのBrokerプロセスは、ビッグデータエコシステムの様々なストレージシステムとのより良い互換性を提供します。BrokerプロセスをBEノードから分離することで、両者間のエラー分離が保証され、BEの安定性が向上します。
現在、BEノードにはHDFSおよびS3 Brokerのサポートが組み込まれています。したがって、HDFSやS3からデータをインポートする際は、追加でBrokerプロセスを起動する必要はありません。ただし、カスタマイズされたBroker実装が必要な場合は、対応するBrokerプロセスをデプロイする必要があります。
クイックスタート
このセクションでは、S3 Loadのデモを示します。 使用方法の具体的な構文については、SQLマニュアルのBROKER LOADを参照してください。
前提条件の確認
- テーブルでの権限付与
Broker Loadは対象テーブルでのINSERT権限が必要です。INSERT権限がない場合は、GRANTコマンドを通じてユーザーに権限を付与できます。
- S3認証および接続情報
ここでは、主にAWS S3に保存されたデータをインポートする方法を紹介します。S3プロトコルをサポートする他のオブジェクトストレージシステムからのデータインポートについては、AWS S3の手順を参照できます。
-
AKとSK:まず、AWS
Access Keysを見つけるか再生成する必要があります。AWSコンソールのMy Security Credentialsで生成方法の手順を確認できます。 -
REGIONとENDPOINT:REGIONはバケット作成時に選択するか、バケットリストで確認できます。各REGIONのS3 ENDPOINTはAWS documentationで確認できます。
ロードジョブの作成
- CSVファイルbrokerload_example.csvを作成します。このファイルはS3に保存され、その内容は以下の通りです:
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64
- ロード用のDorisテーブルを作成する
Dorisでインポート用テーブルを作成します。SQLステートメントは以下の通りです:
CREATE TABLE testdb.test_brokerload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
- Broker Loadを使用してS3からデータをインポートします。バケット名とS3認証情報は実際の状況に応じて入力してください:
LOAD LABEL broker_load_2022_04_01
(
DATA INFILE("s3://your_bucket_name/brokerload_example.csv")
INTO TABLE test_brokerload
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
(user_id, name, age)
)
WITH S3
(
"provider" = "S3",
"AWS_ENDPOINT" = "s3.us-west-2.amazonaws.com",
"AWS_ACCESS_KEY" = "<your-ak>",
"AWS_SECRET_KEY"="<your-sk>",
"AWS_REGION" = "us-west-2",
"compress_type" = "PLAIN"
)
PROPERTIES
(
"timeout" = "3600"
);
providerはS3サービスのベンダーを指定します。
サポートされているS3プロバイダー一覧:
- "S3" (AWS, Amazon Web Services)
- "AZURE" (Microsoft Azure)
- "GCP" (GCP, Google Cloud Platform)
- "OSS" (Alibaba Cloud)
- "COS" (Tencent Cloud)
- "OBS" (Huawei Cloud)
- "BOS" (Baidu Cloud)
お使いのサービスがリストにない場合(MinIOなど)、"S3"(AWS互換モード)を使用してみてください。
インポートステータスの確認
Broker Loadは非同期インポート方式であり、具体的なインポート結果はSHOW LOADコマンドで確認できます。
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************
JobId: 41326624
Label: broker_load_2022_04_01
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: BROKER
EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=27
TaskInfo: cluster:N/A; timeout(s):1200; max_filter_ratio:0.1
ErrorMsg: NULL
CreateTime: 2022-04-01 18:59:06
EtlStartTime: 2022-04-01 18:59:11
EtlFinishTime: 2022-04-01 18:59:11
LoadStartTime: 2022-04-01 18:59:11
LoadFinishTime: 2022-04-01 18:59:11
URL: NULL
JobDetails: {"Unfinished backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[]},"ScannedRows":27,"TaskNumber":1,"All backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[36728051]},"FileNumber":1,"FileSize":5540}
1 row in set (0.01 sec)
インポートのキャンセル
Broker Loadジョブのステータスが CANCELLED または FINISHED でない場合、ユーザーが手動でキャンセルすることができます。キャンセルするには、キャンセルするインポートタスクのラベルを指定する必要があります。cancel importコマンドの構文は、CANCEL LOADを実行して確認できます。
例:DEMOデータベースでラベル"broker_load_2022_04_01"のインポートジョブをキャンセルする場合。
CANCEL LOAD FROM demo WHERE LABEL = "broker_load_2022_04_01";
リファレンスマニュアル
broker loadのSQL構文
LOAD LABEL load_label
(
data_desc1[, data_desc2, ...]
[format_properties]
)
WITH [S3|HDFS|BROKER broker_name]
[broker_properties]
[load_properties]
[COMMENT "comments"];
WITH句はストレージシステムへのアクセス方法を指定し、broker_propertiesはアクセス方法の設定パラメータです
S3: S3プロトコルを使用するストレージシステムHDFS: HDFSプロトコルを使用するストレージシステムBROKER broker_name: その他のプロトコルを使用するストレージシステム。SHOW BROKERを通じて現在利用可能なbroker_nameリストを確認できます。詳細については、よくある問題セクションの「その他のBrokerインポート」を参照してください。
関連設定
ロードプロパティ
| プロパティ名 | タイプ | デフォルト値 | 説明 |
|---|---|---|---|
| "timeout" | Long | 14400 | インポートのタイムアウトを秒単位で指定するために使用します。設定可能な範囲は1秒から259200秒です。 |
| "max_filter_ratio" | Float | 0.0 | フィルタリング可能な(不正またはその他の問題のある)データの最大許容比率を指定するために使用します。デフォルトはゼロトレランスです。値の範囲は0から1です。インポートされたデータのエラー率がこの値を超えると、インポートは失敗します。不正データには、where条件によってフィルタリングされた行は含まれません。 |
| "strict_mode" | Boolean | false | このインポートに対してストリクトモードを有効にするかどうかを指定するために使用します。 |
| "partial_columns" | Boolean | false | 部分列更新を有効にするかどうかを指定するために使用します。デフォルト値はfalseで、このパラメータはUnique Key + Merge on Writeテーブルでのみ利用可能です。 |
| "timezone" | String | "Asia/Shanghai" | このインポートで使用するタイムゾーンを指定するために使用します。このパラメータは、インポートに関わるすべてのタイムゾーン関連関数の結果に影響します。 |
| "load_parallelism" | Integer | 8 | 各バックエンドでの最大並列インスタンス数を制限します。 |
| "send_batch_parallelism" | Integer | 1 | memtable_on_sink_nodeが無効化されている場合の、sinkノードがデータを送信する際の並列度。 |
| "load_to_single_tablet" | Boolean | "false" | パーティションに対応する単一のタブレットにのみデータをロードするかどうかを指定するために使用します。このパラメータは、ランダムバケッティングを使用するOLAPテーブルにロードする場合にのみ利用可能です。 |
| "priority" | oneof "HIGH", "NORMAL", "LOW" | "NORMAL" | タスクの優先度。 |
フォーマットプロパティ
| プロパティ名 | タイプ | デフォルト値 | 説明 |
|---|---|---|---|
skip_lines | Integer | 0 | CSVファイルの開始時にスキップする行数。csv_with_namesまたはcsv_with_names_and_typesを使用している場合は無視されます。 |
trim_double_quotes | Boolean | false | trueの場合、各フィールドから最も外側のダブルクォートを削除します。 |
enclose | String | "" | 区切り文字や改行文字を含むフィールドの囲み文字。例えば、区切り文字が,で囲み文字が'の場合、'b,c'は一つのフィールドとして解析されます。 |
escape | String | "" | フィールド内容に囲み文字を含めるためのエスケープ文字。例えば、'が囲み文字で\がエスケープ文字の場合、'b,\'c'は'b,'c'を一つのフィールドとして保持します。 |
注意:フォーマットプロパティは、ソースファイルの解析方法(区切り文字、クォート処理など)を定義し、LOAD句内で設定する必要があります。ロードプロパティは実行動作(タイムアウト、リトライなど)を制御し、外部のPROPERTIESブロックで設定する必要があります。
LOAD LABEL s3_load_example (
DATA INFILE("s3://bucket/path/file.csv")
INTO TABLE users
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
(user_id, name, age)
PROPERTIES (
"trim_double_quotes" = "true" -- format property
)
)
WITH S3 (
...
)
PROPERTIES (
"timeout" = "3600" -- load property
);
fe.conf
以下の設定は、すべてのBrokerロードインポートタスクに影響するBrokerロードのシステムレベル設定です。これらの設定はfe.confファイルを変更することで調整できます。
| Session Variable | Type | Default Value | Description |
|---|---|---|---|
| min_bytes_per_broker_scanner | Long | 67108864 (64 MB) | Broker Loadジョブで単一のBEが処理するデータの最小量(バイト単位)。 |
| max_bytes_per_broker_scanner | Long | 536870912000 (500 GB) | Broker Loadジョブで単一のBEが処理するデータの最大量(バイト単位)。通常、インポートジョブがサポートするデータの最大量はmax_bytes_per_broker_scanner * BEノード数です。より大きなデータ量をインポートする必要がある場合は、max_bytes_per_broker_scannerパラメータのサイズを適切に調整する必要があります。 |
| max_broker_concurrency | Integer | 10 | ジョブの同時インポート最大数を制限します。 |
| default_load_parallelism | Integer | 8 | BEノードあたりの同時実行インスタンスの最大数 |
| broker_load_default_timeout_second | 14400 | Broker Loadインポートのデフォルトタイムアウト(秒単位)。 |
注意:min_bytes_per_broker_scanner、max_broker_concurrency、ソースファイルのサイズ、現在のクラスタ内のBE数が、このロードの同時実行インスタンス数を共同で決定します。
Import Concurrency = Math.min(Source File Size / min_bytes_per_broker_scanner, max_broker_concurrency, Current Number of BE Nodes * load_parallelism)
Processing Volume per BE for this Import = Source File Size / Import Concurrency
session variables
| Session Variable | Type | Default | Description |
|---|---|---|---|
| time_zone | String | "Asia/Shanghai" | デフォルトのタイムゾーン。インポート時のタイムゾーン関連関数の結果に影響します。 |
| send_batch_parallelism | Integer | 1 | sinkノードがデータを送信する際の同時実行数。enable_memtable_on_sink_nodeがfalseに設定されている場合のみ有効です。 |
よくある問題
よくあるエラー
1. インポートエラー: Scan bytes per broker scanner exceed limit:xxx
ドキュメントのベストプラクティスセクションを参照し、FE設定項目のmax_bytes_per_broker_scannerとmax_broker_concurrencyを変更してください。
2. インポートエラー: failed to send batchまたはTabletWriter add batch with unknown id
query_timeoutとstreaming_load_rpc_max_alive_time_secの設定を適切に調整してください。
3. インポートエラー: LOAD_RUN_FAIL; msg:Invalid Column Name:xxx
PARQUETまたはORC形式のデータの場合、ファイルヘッダー内の列名はDorisテーブルの列名と一致する必要があります。例:
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)
これはparquetまたはorcファイル内の(tmp_c1, tmp_c2)という名前の列を取得し、Dorisテーブルの(id, name)列にマッピングすることを表しています。setが指定されていない場合は、ファイルヘッダー内の列がマッピングに使用されます。
特定のHiveバージョンを使用してORCファイルが直接生成される場合、ORCファイル内の列ヘッダーがHiveメタデータではなく、(_col0, _col1, _col2, ...)になる可能性があり、これによりInvalid Column Nameエラーが発生する場合があります。この場合、SETを使用したマッピングが必要です。
5. インポートエラー: Failed to get S3 FileSystem for bucket is null/empty
bucketの情報が不正であるか存在しません。またはbucketの形式がサポートされていません。GCSを使用してアンダースコアを含むbucket名を作成する場合(s3://gs_bucket/load_tblなど)、S3 ClientがGCSにアクセスする際にエラーを報告する可能性があります。bucketを作成する際はアンダースコアを使用しないことを推奨します。
6. インポートタイムアウト
インポートのデフォルトタイムアウトは4時間です。タイムアウトが発生した場合、問題を解決するために最大インポートタイムアウトを直接増加させることは推奨されません。単一のインポート時間がデフォルトのインポートタイムアウトである4時間を超える場合は、インポートするファイルを分割して複数回のインポートを実行して問題を解決することが最適です。過度に長いタイムアウト時間を設定すると、失敗したインポートの再試行で高いコストが発生する可能性があります。
以下の式を使用してDorisクラスターの予想最大インポートファイルデータボリュームを計算できます:
予想最大インポートファイルデータボリューム = 14400s * 10M/s * BEの数
例えば、クラスターに10個のBEがある場合:
予想最大インポートファイルデータボリューム = 14400s * 10M/s * 10 = 1440000M ≈ 1440G
一般的に、ユーザー環境では10M/sの速度に達しない可能性があるため、500Gを超えるファイルはインポート前に分割することを推奨します。
S3 Load URLスタイル
-
S3 SDKはデフォルトでvirtual-hosted styleメソッドを使用してオブジェクトにアクセスします。しかし、一部のオブジェクトストレージシステムではvirtual-hosted styleアクセスが有効化またはサポートされていない可能性があります。このような場合、
use_path_styleパラメータを追加してpath styleメソッドの使用を強制できます:WITH S3
(
"AWS_ENDPOINT" = "AWS_ENDPOINT",
"AWS_ACCESS_KEY" = "AWS_ACCESS_KEY",
"AWS_SECRET_KEY"="AWS_SECRET_KEY",
"AWS_REGION" = "AWS_REGION",
"use_path_style" = "true"
)
S3 Load一時認証情報
-
一時認証情報(TOKEN)を使用してS3プロトコルをサポートするすべてのオブジェクトストレージシステムにアクセスするためのサポートが利用可能です。使用方法は以下の通りです:
WITH S3
(
"AWS_ENDPOINT" = "AWS_ENDPOINT",
"AWS_ACCESS_KEY" = "AWS_TEMP_ACCESS_KEY",
"AWS_SECRET_KEY" = "AWS_TEMP_SECRET_KEY",
"AWS_TOKEN" = "AWS_TEMP_TOKEN",
"AWS_REGION" = "AWS_REGION"
)
HDFS Simple認証
Simple認証とは、hadoop.security.authenticationが"simple"に設定されているHadoopの構成を指します。
(
"username" = "user",
"password" = ""
);
usernameはアクセスするユーザーとして設定する必要があり、passwordは空白のままにしておくことができます。
HDFS Kerberos Authentication
この認証方法には以下の情報が必要です:
-
hadoop.security.authentication: 認証方法をKerberosとして指定します。
-
hadoop.kerberos.principal: Kerberosプリンシパルを指定します。
-
hadoop.kerberos.keytab: Kerberosキータブのファイルパスを指定します。ファイルはBrokerプロセスが配置されているサーバー上の絶対パスである必要があり、Brokerプロセスからアクセス可能である必要があります。
-
kerberos_keytab_content: base64でエンコードされたKerberosキータブファイルの内容を指定します。これはkerberos_keytab設定の代替として使用できます。
設定例:
(
"hadoop.security.authentication" = "kerberos",
"hadoop.kerberos.principal" = "doris@YOUR.COM",
"hadoop.kerberos.keytab" = "/home/doris/my.keytab"
)
(
"hadoop.security.authentication" = "kerberos",
"hadoop.kerberos.principal" = "doris@YOUR.COM",
"kerberos_keytab_content" = "ASDOWHDLAWIDJHWLDKSALDJSDIWALD"
)
Kerberos認証を使用するには、krb5.conf (opens new window)ファイルが必要です。krb5.confファイルにはKerberos設定情報が含まれています。通常、krb5.confファイルは/etcディレクトリにインストールする必要があります。KRB5_CONFIG環境変数を設定することで、デフォルトの場所を上書きできます。krb5.confファイルの内容の例は以下の通りです:
[libdefaults]
default_realm = DORIS.HADOOP
default_tkt_enctypes = des3-hmac-sha1 des-cbc-crc
default_tgs_enctypes = des3-hmac-sha1 des-cbc-crc
dns_lookup_kdc = true
dns_lookup_realm = false
[realms]
DORIS.HADOOP = {
kdc = kerberos-doris.hadoop.service:7005
}
HDFS HAモード
この設定は、HA(High Availability)モードでデプロイされたHDFSクラスタにアクセスするために使用されます。
-
dfs.nameservices: HDFSサービスの名前を指定します。これはカスタマイズ可能です。例:"dfs.nameservices" = "my_ha"
-
dfs.ha.namenodes.xxx: namenodeの名前をカスタマイズします。複数の名前はカンマで区切ります。ここで、xxxはdfs.nameservicesで指定されたカスタム名を表します。例:"dfs.ha.namenodes.my_ha" = "my_nn"
-
dfs.namenode.rpc-address.xxx.nn: namenodeのRPCアドレス情報を指定します。この文脈において、nnはdfs.ha.namenodes.xxxで設定されたnamenode名を表します。例:"dfs.namenode.rpc-address.my_ha.my_nn" = "host:port"
-
dfs.client.failover.proxy.provider.[nameservice ID]: namenodeへのクライアント接続のプロバイダを指定します。デフォルトはorg.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProviderです。
設定例は以下の通りです:
(
"fs.defaultFS" = "hdfs://my_ha",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
HAモードは、クラスターアクセスのために前述の2つの認証方法と組み合わせることができます。例えば、シンプル認証を通じてHA HDFSにアクセスする場合:
(
"username"="user",
"password"="passwd",
"fs.defaultFS" = "hdfs://my_ha",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
他のbrokerでのロード
他のリモートストレージシステム用のBrokerは、Dorisクラスタにおけるオプションのプロセスであり、主にDorisがリモートストレージ上のファイルやディレクトリの読み書きを行うためのサポートに使用されます。
現在、Dorisは様々なリモートストレージシステムに対応したBroker実装を提供しています。
以前のバージョンでは、異なるオブジェクトストレージBrokerも利用可能でしたが、現在はオブジェクトストレージからデータをインポートする際にはWITH S3メソッドの使用が推奨されており、WITH BROKERメソッドは推奨されません。
- Tencent Cloud CHDFS
- Tencent Cloud GFS
- JuiceFS
BrokerはRPCサービスポートを通じてサービスを提供し、ステートレスなJavaプロセスとして動作します。その主な役割は、open、pread、pwrite等、リモートストレージに対するPOSIXライクなファイル操作をカプセル化することです。さらに、Brokerは他の情報を追跡することはありません。これは、リモートストレージに関連するすべての接続詳細、ファイル情報、権限詳細は、RPC呼び出し時にパラメータを通じてBrokerプロセスに渡される必要があることを意味します。これにより、Brokerがファイルを正しく読み書きできることが保証されます。
Brokerは純粋にデータ経路として機能し、計算タスクには関与しないため、必要なメモリ使用量は最小限です。通常、Dorisシステムでは1つまたは複数のBrokerプロセスをデプロイします。さらに、同じタイプのBrokerはグループ化され、一意の名前(Broker name)が割り当てられます。
このセクションでは主に、Brokerが異なるリモートストレージシステムにアクセスする際に必要なパラメータ(接続情報や認証詳細など)に焦点を当てます。これらのパラメータを理解し、正しく設定することは、Dorisとリモートストレージシステム間での成功かつ安全なデータ交換にとって重要です。
Broker情報
Brokerの情報は2つの部分で構成されます:名前(Broker name)と認証情報です。通常の構文形式は以下のとおりです:
WITH BROKER "broker_name"
(
"username" = "xxx",
"password" = "yyy",
"other_prop" = "prop_value",
...
);
Broker Name
通常、ユーザーは操作コマンドで WITH BROKER "broker_name" 句を通じて既存のBroker Nameを指定する必要があります。Broker Nameは、ALTER SYSTEM ADD BROKER コマンドを通じてBrokerプロセスを追加する際にユーザーが指定する名前です。1つの名前は通常、1つ以上のBrokerプロセスに対応します。Dorisは名前に基づいて利用可能なBrokerプロセスを選択します。ユーザーは SHOW BROKER コマンドを通じて、現在クラスター内に存在するBrokerを確認できます。
Broker Nameは単にユーザー定義の名前であり、Brokerのタイプを表すものではありません。
認証情報
異なるBrokerタイプとアクセス方法には、異なる認証情報が必要です。認証情報は通常、WITH BROKER "broker_name" の後にKey-Value形式でProperty Mapで提供されます。
Broker Load例
HDFSからのTXTファイルのインポート
LOAD LABEL demo.label_20220402
(
DATA INFILE("hdfs://host:port/tmp/test_hdfs.txt")
INTO TABLE `load_hdfs_file_test`
COLUMNS TERMINATED BY "\t"
(id,age,name)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
HDFSはNameNode HA(High Availability)の設定が必要です
LOAD LABEL demo.label_20220402
(
DATA INFILE("hdfs://hafs/tmp/test_hdfs.txt")
INTO TABLE `load_hdfs_file_test`
COLUMNS TERMINATED BY "\t"
(id,age,name)
)
with HDFS
(
"hadoop.username" = "user",
"fs.defaultFS"="hdfs://hafs",
"dfs.nameservices" = "hafs",
"dfs.ha.namenodes.hafs" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.hafs.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.hafs.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider.hafs" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
ワイルドカードを使用してHDFSから2つのファイルバッチにマッチするデータをインポートし、それらを2つの別々のテーブルにインポートする
LOAD LABEL example_db.label2
(
DATA INFILE("hdfs://host:port/input/file-10*")
INTO TABLE `my_table1`
PARTITION (p1)
COLUMNS TERMINATED BY ","
(k1, tmp_k2, tmp_k3)
SET (
k2 = tmp_k2 + 1,
k3 = tmp_k3 + 1
),
DATA INFILE("hdfs://host:port/input/file-20*")
INTO TABLE `my_table2`
COLUMNS TERMINATED BY ","
(k1, k2, k3)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
HDFSからワイルドカードfile-10*とfile-20*にマッチする2つのファイルバッチをインポートし、それらを2つの別々のテーブルmy_table1とmy_table2にロードするには。この場合、my_table1はデータをパーティションp1にインポートするよう指定し、ソースファイルの2列目と3列目の値をインポート前に1ずつ増加させます。
ワイルドカードを使用してHDFSからデータのバッチをインポートする
LOAD LABEL example_db.label3
(
DATA INFILE("hdfs://host:port/user/doris/data/*/*")
INTO TABLE `my_table`
COLUMNS TERMINATED BY "\\x01"
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
Hiveでよく使用されるデフォルトの区切り文字である\x01を区切り文字として指定し、ワイルドカード文字*を使用してデータディレクトリ下のすべてのディレクトリ内のすべてのファイルを参照します。
Parquet形式のデータをインポートし、FORMATをparquetとして指定
LOAD LABEL example_db.label4
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
FORMAT AS "parquet"
(k1, k2, k3)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
デフォルトの方法は、ファイル拡張子によって決定することです。
データをインポートし、ファイルパスからパーティションフィールドを抽出する
LOAD LABEL example_db.label5
(
DATA INFILE("hdfs://host:port/input/city=beijing/*/*")
INTO TABLE `my_table`
FORMAT AS "csv"
(k1, k2, k3)
COLUMNS FROM PATH AS (city, utc_date)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
my_tableの列はk1、k2、k3、city、およびutc_dateです。
ディレクトリhdfs://hdfs_host:hdfs_port/user/doris/data/input/dir/city=beijingには以下のファイルが含まれています:
hdfs://hdfs_host:hdfs_port/input/city=beijing/utc_date=2020-10-01/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=beijing/utc_date=2020-10-02/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=tianji/utc_date=2020-10-03/0000.csv
hdfs://hdfs_host:hdfs_port/input/city=tianji/utc_date=2020-10-04/0000.csv
ファイルにはk1、k2、k3の3つのデータ列のみが含まれています。その他の2つの列であるcityとutc_dateは、ファイルパスから抽出されます。
インポートしたデータをフィルタする
LOAD LABEL example_db.label6
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
(k1, k2, k3)
SET (
k2 = k2 + 1
)
PRECEDING FILTER k1 = 1
WHERE k1 > k2
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
元のデータでk1 = 1であり、変換後にk1 > k2となる行のみがインポートされます。
ファイルパスから時間パーティションフィールドをインポートして抽出する。
LOAD LABEL example_db.label7
(
DATA INFILE("hdfs://host:port/user/data/*/test.txt")
INTO TABLE `tbl12`
COLUMNS TERMINATED BY ","
(k2,k3)
COLUMNS FROM PATH AS (data_time)
SET (
data_time=str_to_date(data_time, '%Y-%m-%d %H%%3A%i%%3A%s')
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username" = "user"
);
時刻には"%3A"が含まれています。HDFSパスではコロン":"は許可されていないため、すべてのコロンが"%3A"に置き換えられます。
パス配下には以下のファイルがあります:
/user/data/data_time=2020-02-17 00%3A00%3A00/test.txt
/user/data/data_time=2020-02-18 00%3A00%3A00/test.txt
テーブル構造は以下の通りです:
CREATE TABLE IF NOT EXISTS tbl12 (
data_time DATETIME,
k2 INT,
k3 INT
) DISTRIBUTED BY HASH(data_time) BUCKETS 10
PROPERTIES (
"replication_num" = "3"
);
インポートにMergeモードを使用する
LOAD LABEL example_db.label8
(
MERGE DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
(k1, k2, k3, v2, v1)
DELETE ON v2 > 100
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
)
PROPERTIES
(
"timeout" = "3600",
"max_filter_ratio" = "0.1"
);
インポートでMergeモードを使用するには、"my_table"はUnique Keyテーブルである必要があります。インポートされるデータの"v2"列の値が100より大きい場合、その行は削除行と見なされます。インポートタスクのタイムアウトは3600秒で、最大10%のエラー率が許可されます。
インポート時に"source_sequence"列を指定して、置換の順序を保証します。
LOAD LABEL example_db.label9
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
COLUMNS TERMINATED BY ","
(k1,k2,source_sequence,v1,v2)
ORDER BY source_sequence
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
The "my_table" must be a Unique Key model table and have a specified Sequence column. The data will maintain its order based on the values in the "source_sequence" column in the source data.
指定されたファイル形式をjsonとしてインポートし、それに応じてjson_rootとjsonpathsを指定します。
LOAD LABEL example_db.label10
(
DATA INFILE("hdfs://host:port/input/file.json")
INTO TABLE `my_table`
FORMAT AS "json"
PROPERTIES(
"json_root" = "$.item",
"jsonpaths" = "[\"$.id\", \"$.city\", \"$.code\"]"
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
jsonpathsは、列リストとSET (column_mapping)と組み合わせて使用することもできます:
LOAD LABEL example_db.label10
(
DATA INFILE("hdfs://host:port/input/file.json")
INTO TABLE `my_table`
FORMAT AS "json"
(id, code, city)
SET (id = id * 10)
PROPERTIES(
"json_root" = "$.item",
"jsonpaths" = "[\"$.id\", \"$.city\", \"$.code\"]"
)
)
with HDFS
(
"fs.defaultFS"="hdfs://host:port",
"hadoop.username"="user"
);
JSONファイルのルートノードでJSONオブジェクトを読み込む必要がある場合、jsonpathsは$.として指定する必要があります。例:PROPERTIES("jsonpaths"="$.")"
他のブローカーから読み込む
-
Alibaba Cloud OSS
(
"fs.oss.accessKeyId" = "",
"fs.oss.accessKeySecret" = "",
"fs.oss.endpoint" = ""
) -
JuiceFS
(
"fs.defaultFS" = "jfs://xxx/",
"fs.jfs.impl" = "io.juicefs.JuiceFileSystem",
"fs.AbstractFileSystem.jfs.impl" = "io.juicefs.JuiceFS",
"juicefs.meta" = "xxx",
"juicefs.access-log" = "xxx"
) -
GCS
Brokerを使用してGCSにアクセスする場合、Project IDが必要ですが、その他のパラメータはオプションです。すべてのパラメータ設定については、GCS Configを参照してください。
(
"fs.gs.project.id" = "Your Project ID",
"fs.AbstractFileSystem.gs.impl" = "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS",
"fs.gs.impl" = "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem",
)
より詳しいヘルプ
Broker Loadの使用に関するより詳細な構文とベストプラクティスについては、Broker Loadコマンドマニュアルを参照してください。また、MySQLクライアントのコマンドラインでHELP BROKER LOADと入力することで、より多くのヘルプ情報を取得できます。