
ルーチンロード
Dorisは、Routine Loadメソッドを通じてKafka Topicからデータを継続的に消費できます。Routine Loadジョブを投稿すると、Dorisはロードジョブを継続的に実行し、リアルタイムロードタスクを生成してKafkaクラスタ内の指定されたTopicからメッセージを常に消費します。
Routine Loadは、Exactly-Onceセマンティクスをサポートするストリーミングロードジョブであり、データが失われることも重複することもないことを保証します。
使用シナリオ
サポートされるデータソース
Routine LoadはKafkaクラスタからのデータ消費をサポートします。
サポートされるデータファイル形式
Routine LoadはCSVおよびJSON形式のデータ消費をサポートします。
CSV形式をロードする際は、null値と空文字列を明確に区別する必要があります:
-
Null値は
\nで表現する必要があります。例えば、a,\n,bは中間列がnull値であることを示します。 -
空文字列は、データフィールドを空にすることで表現できます。例えば、
a,,bは中間列が空文字列であることを示します。
使用制限
Routine Loadを使用してKafkaからデータを消費する際は、以下の制限があります:
-
サポートされるメッセージ形式はCSVおよびJSONテキスト形式です。CSVの各メッセージは個別の行にあり、行は改行文字で終わってはいけません。
-
デフォルトでは、Kafkaバージョン0.10.0.0以上をサポートします。0.10.0.0未満のKafkaバージョン(0.9.0、0.8.2、0.8.1、0.8.0など)を使用する必要がある場合は、
kafka_broker_version_fallbackの値を互換性のある古いバージョンに設定してBE設定を変更するか、Routine Load作成時にproperty.broker.version.fallbackの値を直接設定する必要があります。ただし、古いバージョンを使用することで、時間に基づくKafkaパーティションのオフセット設定などのRoutine Loadの一部の新機能が利用できない場合があります。
基本原理
Routine LoadはKafka Topicsからデータを継続的に消費し、Dorisに書き込みます。
DorisでRoutine Loadジョブが作成されると、複数のインポートタスクから構成される常駐インポートジョブが生成されます:
-
Load Job:Routine Load Jobは、データソースからデータを継続的に消費する常駐インポートジョブです。
-
Load Task:インポートジョブは実際の消費のために複数のインポートタスクに分割され、各タスクは独立したトランザクションです。
Routine Loadの具体的なインポートプロセスを以下の図で示します:
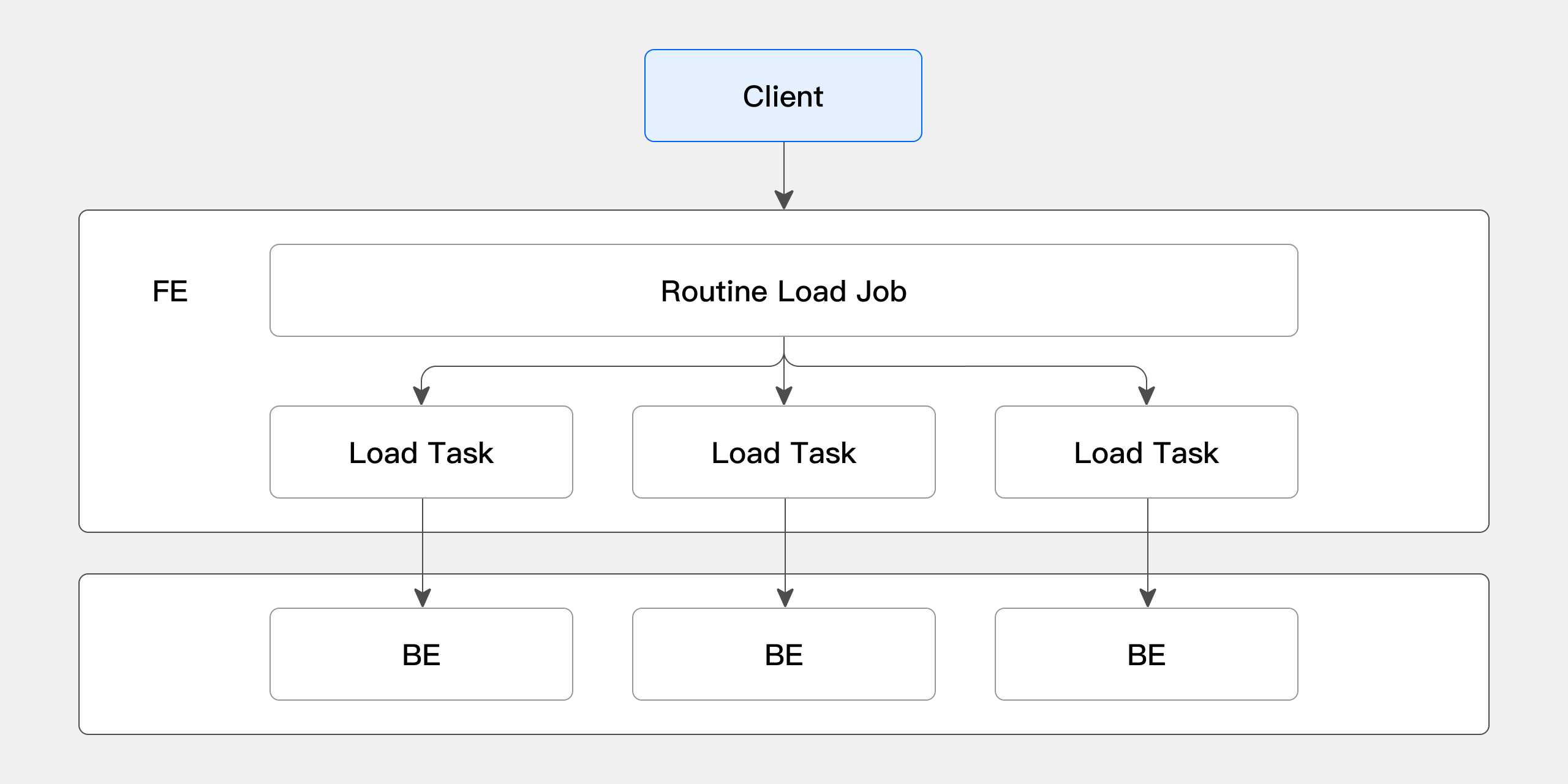
-
ClientがFEにRoutine Loadジョブの作成リクエストを送信し、FEがRoutine Load Managerを通じて常駐インポートジョブ(Routine Load Job)を生成します。
-
FEがJob Schedulerを通じてRoutine Load Jobを複数のRoutine Load Tasksに分割し、Task Schedulerによってスケジューリングされ、BEノードに配布されます。
-
BEでRoutine Load Taskが完了すると、FEにトランザクションを送信し、Jobのメタデータを更新します。
-
Routine Load Taskが送信された後、新しいTasksの生成またはタイムアウトしたTasksの再試行を継続します。
-
新しく生成されたRoutine Load TasksはTask Schedulerによって継続的なサイクルでスケジューリングが続行されます。
Auto Resume
ジョブの高可用性を確保するために、自動再開メカニズムが導入されています。予期しない一時停止の場合、Routine Load Schedulerスレッドがジョブの自動再開を試行します。予期しないKafkaの停止やその他のシステムが機能できないシナリオに対して、自動再開メカニズムによりKafkaが復旧すると、手動介入なしでroutine loadジョブが正常に動作を継続できることが保証されます。
自動再開が発生しない状況:
-
ユーザーが手動でPAUSE ROUTINE LOADコマンドを実行した場合。
-
データ品質に問題がある場合。
-
データベーステーブルが削除されるなど、再開が不可能な状況。
これらの3つの状況以外では、他の一時停止されたジョブは自動的に再開を試行します。
FAQ
自動再開はクラスタの再起動またはアップグレード中に問題が発生する場合があります。バージョン2.1.7以前では、クラスタの再起動またはアップグレードによる一時停止後にタスクが自動的に再開されない確率が高くありました。バージョン2.1.7以降、このようなイベント後にタスクが自動的に再開されない可能性は減少しています。
クイックスタート
ジョブの作成
Dorisでは、CREATE ROUTINE LOADコマンドを使用して永続的なRoutine Loadタスクを作成できます。詳細な構文については、CREATE ROUTINE LOADを参照してください。Routine LoadはCSVおよびJSON形式のデータ消費をサポートします。
CSVデータのロード
-
データサンプルのロード
Kafkaには以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-csv --from-beginning
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64 -
テーブルの作成
Dorisでは、以下の構文を使用してロード用のテーブルを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User Name",
age INT COMMENT "User Age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Routine Loadジョブの作成
Dorisでは、
CREATE ROUTINE LOADコマンドを使用してロードジョブを作成します:CREATE ROUTINE LOAD testdb.example_routine_load_csv ON test_routineload_tbl
COLUMNS TERMINATED BY ",",
COLUMNS(user_id, name, age)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092",
"kafka_topic" = "test-routine-load-csv",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
JSON データの読み込み
-
サンプルデータの読み込み
Kafkaには、以下のサンプルデータがあります:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-routine-load-json --from-beginning -
テーブルの作成
Dorisで、以下の構文を使用してロード用のテーブルを作成します:
CREATE TABLE testdb.test_routineload_tbl(
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User Name",
age INT COMMENT "User Age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -
Routine Loadジョブの作成
Dorisでは、
CREATE ROUTINE LOADコマンドを使用してジョブを作成します:CREATE ROUTINE LOAD testdb.example_routine_load_json ON test_routineload_tbl
COLUMNS(user_id, name, age)
PROPERTIES(
"format"="json",
"jsonpaths"="[\"$.user_id\",\"$.name\",\"$.age\"]"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.62:9092"
);
JSON ファイルのルートノードで JSON オブジェクトをロードする必要がある場合、jsonpaths は $ として指定する必要があります。例:PROPERTIES("jsonpaths"="$.")"
ステータスの確認
Doris では、以下の方法を使用して Routine Load ジョブとタスクのステータスを確認できます:
-
Load Jobs:対象テーブル、サブタスク数、ロード遅延ステータス、ロード設定、ロード結果などのロードタスクに関する情報を表示するために使用されます。
-
Load Tasks:タスク ID、トランザクションステータス、タスクステータス、実行開始時刻、BE(Backend)ノード割り当てなど、個別のロードタスクのステータスを表示するために使用されます。
01 実行中ジョブの確認
SHOW ROUTINE LOAD コマンドを使用してジョブのステータスを確認できます。SHOW ROUTINE LOAD コマンドは、対象テーブル、ロード遅延ステータス、ロード設定、エラーメッセージを含む現在のジョブに関する情報を提供します。
例えば、testdb.example_routine_load_csv ジョブのステータスを確認するには、以下のコマンドを実行できます:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
02 実行中のタスクの表示
SHOW ROUTINE LOAD TASKコマンドを使用して、ロードタスクのステータスを確認できます。SHOW ROUTINE LOAD TASKコマンドは、特定のロードジョブ配下の個別タスクに関する情報を提供します。これには、タスクID、トランザクションステータス、タスクステータス、実行開始時刻、BE IDが含まれます。
例えば、example_routine_load_csvジョブのタスクステータスを表示するには、以下のコマンドを実行します:
mysql> SHOW ROUTINE LOAD TASK WHERE jobname = 'example_routine_load_csv';
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| TaskId | TxnId | TxnStatus | JobId | CreateTime | ExecuteStartTime | Timeout | BeId | DataSourceProperties |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
| 8cf47e6a68ed4da3-8f45b431db50e466 | 195 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 10429 | {"4":1231,"9":2603} |
| f2d4525c54074aa2-b6478cf8daaeb393 | 196 | PREPARE | 12177 | 2024-01-15 12:20:41 | 2024-01-15 12:21:01 | 20 | 12109 | {"1":1225,"6":1216} |
| cb870f1553864250-975279875a25fab6 | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"2":7234,"7":4865} |
| 68771fd8a1824637-90a9dac2a7a0075e | -1 | NULL | 12177 | 2024-01-15 12:20:52 | NULL | 20 | -1 | {"3":1769,"8":2982} |
| 77112dfea5e54b0a-a10eab3d5b19e565 | 197 | PREPARE | 12177 | 2024-01-15 12:21:02 | 2024-01-15 12:21:02 | 20 | 12098 | {"0":3000,"5":2622} |
+-----------------------------------+-------+-----------+-------+---------------------+---------------------+---------+-------+----------------------+
ジョブの一時停止
PAUSE ROUTINE LOADコマンドを使用してロードジョブを一時停止できます。ジョブが一時停止されると、PAUSEDステートに入りますが、ロードジョブは終了せず、RESUME ROUTINE LOADコマンドを使用して再開できます。
testdb.example_routine_load_csvロードジョブを一時停止するには、次のコマンドを使用できます:
PAUSE ROUTINE LOAD FOR testdb.example_routine_load_csv;
ジョブの再開
RESUME ROUTINE LOAD コマンドを使用して、一時停止されたロードジョブを再開できます。
testdb.example_routine_load_csv ジョブを再開するには、以下のコマンドを使用できます:
RESUME ROUTINE LOAD FOR testdb.example_routine_load_csv;
ジョブの変更
作成済みのロードジョブは、ALTER ROUTINE LOAD コマンドを使用して変更できます。ジョブを変更する前に、PAUSE ROUTINE LOAD コマンドを使用してジョブを一時停止し、変更後は RESUME ROUTINE LOAD コマンドを使用して再開できます。
ジョブの desired_concurrent_number パラメータを変更し、Kafkaトピック情報を更新するには、次のコマンドを使用できます:
ALTER ROUTINE LOAD FOR testdb.example_routine_load_csv
PROPERTIES(
"desired_concurrent_number" = "3"
)
FROM KAFKA(
"kafka_broker_list" = "192.168.88.60:9092",
"kafka_topic" = "test-topic"
);
ジョブのキャンセル
STOP ROUTINE LOADコマンドを使用してRoutine Loadジョブを停止および削除できます。削除されると、ロードジョブは復旧できず、SHOW ROUTINE LOADコマンドを使用して表示することもできません。
testdb.example_routine_load_csvロードジョブを停止および削除するには、以下のコマンドを使用できます:
STOP ROUTINE LOAD FOR testdb.example_routine_load_csv;
リファレンスマニュアル
Load コマンド
Routine Load の永続化ロードジョブを作成するための構文は以下の通りです:
CREATE ROUTINE LOAD [<db_name>.]<job_name> [ON <tbl_name>]
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "<comment>"]
ローディングジョブを作成するためのモジュールについて、以下のように説明します:
| モジュール | 説明 |
|---|---|
| db_name | ローディングタスクを作成するデータベースの名前を指定します。 |
| job_name | 作成されるローディングジョブの名前を指定します。ジョブ名は同一データベース内で一意である必要があります。 |
| tbl_name | ロードするテーブルの名前を指定します。このパラメータはオプションです。指定されない場合、動的テーブルモードが使用され、Kafkaデータにテーブル名情報が含まれている必要があります。 |
| merge_type | データマージタイプを指定します。デフォルト値はAPPENDです。可能なmerge_typeオプションは以下の通りです:
|
| load_properties | ロードプロパティを記述します。以下を含みます:
|
| job_properties | Routine Loadの一般的なロードパラメータを指定します。 |
| data_source_properties | Kafkaデータソースのプロパティを記述します。 |
| comment | ローディングジョブの追加コメントを記述します。 |
ロードパラメータの説明
01 FE設定パラメータ
| パラメータ名 | デフォルト値 | 動的設定 | FE Masterのみの設定 | 説明 |
|---|---|---|---|---|
| max_routine_load_task_concurrent_num | 256 | Yes | Yes | Routine Loadジョブの同時サブタスクの最大数を制限します。デフォルト値を維持することを推奨します。高すぎる値を設定すると、過度な同時タスクが発生し、クラスタリソースを消費する可能性があります。 |
| max_routine_load_task_num_per_be | 1024 | Yes | Yes | BE当たりで許可されるRoutine Loadタスクの最大同時実行数。max_routine_load_task_num_per_beはroutine_load_thread_pool_size未満である必要があります。 |
| max_routine_load_job_num | 100 | Yes | Yes | NEED_SCHEDULED、RUNNING、PAUSEを含むRoutine Loadジョブの最大数を制限します。 |
| max_tolerable_backend_down_num | 0 | Yes | Yes | 任意のBEがダウンした場合、Routine Loadは自動復旧できません。特定の条件下で、DorisはPAUSEDタスクをRUNNING状態に再スケジュールできます。値0は、すべてのBEノードが稼働している場合のみ再スケジュールが許可されることを意味します。 |
| period_of_auto_resume_min | 5 (minutes) | Yes | Yes | Routine Loadを自動再開する期間。 |
02 BE設定パラメータ
| パラメータ名 | デフォルト値 | 動的設定 | 説明 |
|---|---|---|---|
| max_consumer_num_per_group | 3 | Yes | サブタスクがデータを消費するために生成できるコンシューマの最大数。Kafkaデータソースの場合、1つのコンシューマが1つまたは複数のKafkaパーティションを消費する可能性があります。タスクが6つのKafkaパーティションを消費する必要がある場合、3つのコンシューマが生成され、それぞれが2つのパーティションを消費します。パーティションが2つしかない場合は、2つのコンシューマのみが生成され、それぞれが1つのパーティションを消費します。 |
ロード設定パラメータ
Routine Loadジョブを作成する際、CREATE ROUTINE LOADコマンドを使用して異なるモジュールのロード設定パラメータを指定できます。
tbl_name句
ロードするテーブルの名前を指定します。このパラメータはオプションです。
指定されない場合、動的テーブルモードが使用され、Kafka内のデータにテーブル名情報が含まれている必要があります。現在、KafkaのValueフィールドからテーブル名を抽出することのみがサポートされています。形式は以下のようにし、JSONを例とします:table_name|{"col1": "val1", "col2": "val2"}。ここでtbl_nameはテーブル名で、|はテーブル名とテーブルデータの間の区切り文字として使用されます。同じ形式がCSVデータにも適用され、例えばtable_name|val1,val2,val3のようになります。ここでのtable_nameはDorisのテーブル名と一致している必要があり、そうでなければロードに失敗します。動的テーブルは後述するcolumn_mapping設定をサポートしないことに注意してください。
merge_type句
merge_typeモジュールはデータマージのタイプを指定します。merge_typeには3つのオプションがあります:
-
APPEND:追加ロードモード。
-
MERGE:マージロードモード。Unique Keyモデルにのみ適用可能です。Delete Flagカラムをマークするために[DELETE ON]モジュールと組み合わせて使用する必要があります。
-
DELETE:ロードされるすべてのデータは削除が必要なデータです。
load_properties句
load_propertiesモジュールは以下の構文を使用してロードされるデータのプロパティを記述します:
[COLUMNS TERMINATED BY <column_separator>,]
[COLUMNS (<column1_name>[, <column2_name>, <column_mapping>, ...]),]
[WHERE <where_expr>,]
[PARTITION(<partition1_name>, [<partition2_name>, <partition3_name>, ...]),]
[DELETE ON <delete_expr>,]
[ORDER BY <order_by_column1>[, <order_by_column2>, <order_by_column3>, ...]]
各モジュールの具体的なパラメータは以下の通りです:
| サブモジュール | パラメータ | 説明 |
|---|---|---|
| COLUMNS TERMINATED BY | <column_separator> | 列区切り文字を指定します。デフォルトは \t です。例えば、区切り文字としてカンマを指定する場合は、COLUMNS TERMINATED BY ","を使用します。空値を扱う際は、以下の点に注意してください:
|
| COLUMNS | <column_name> | 対応する列名を指定します。例えば、ロード列を (k1, k2, k3) として指定する場合は、COLUMNS(k1, k2, k3) を使用します。COLUMNS句は以下の場合に省略できます:
|
<column_mapping> | ロード処理中に、列マッピングを使用して列のフィルタリングと変換を行うことができます。例えば、ターゲット列がデータソースの列に基づいて派生計算を実行する必要がある場合(例:ターゲット列k4がk3列に基づいてk3 + 1として計算される)、COLUMNS(k1, k2, k3, k4 = k3 + 1) を使用できます。詳細については、Data Conversionドキュメントを参照してください。 | |
| WHERE | <where_expr> | ロードするデータソースをフィルタリングする条件を指定します。例えば、age > 30のデータのみをロードする場合は、WHERE age > 30 を使用します。 |
| PARTITION | <partition_name> | ターゲットテーブルのどのパーティションにロードするかを指定します。指定されていない場合は、自動的に対応するパーティションにロードされます。例えば、ターゲットテーブルのパーティションp1とp2にロードする場合は、PARTITION(p1, p2) を使用します。 |
| DELETE ON | <delete_expr> | MERGEロードモードにおいて、delete_exprを使用してどの列を削除する必要があるかをマークします。例えば、MERGE処理中にage > 30の列を削除する場合は、DELETE ON age > 30 を使用します。 |
| ORDER BY | <order_by_column> | Unique Keyモデルでのみ有効です。ロードされたデータのSequence Columnを指定して、データの順序を保証します。例えば、Unique Keyテーブルにロードし、create_timeをSequence Columnとして指定する場合は、ORDER BY create_time を使用します。Unique KeyモデルのSequence Columnsの詳細については、Data Update/Sequence Columnsを参照してください。 |
job_properties句
job_properties句は、Routine Loadジョブを作成する際にジョブのプロパティを指定するために使用されます。構文は以下の通りです:
PROPERTIES ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
job_properties句の利用可能なパラメータは以下の通りです:
| パラメータ | 説明 |
|---|---|
| desired_concurrent_number |
|
| max_batch_interval | 各サブタスクの最大実行時間(秒単位)。0より大きい値である必要があり、デフォルト値は60sです。max_batch_interval/max_batch_rows/max_batch_sizeが一緒になってサブタスクの実行閾値を形成します。これらのパラメータのいずれかが閾値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_batch_rows | 各サブタスクが読み取る最大行数。200,000以上である必要があります。デフォルト値は20,000,000です。max_batch_interval/max_batch_rows/max_batch_sizeが一緒になってサブタスクの実行閾値を形成します。これらのパラメータのいずれかが閾値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_batch_size | 各サブタスクが読み取る最大バイト数。単位はバイトで、範囲は100MBから10GBです。デフォルト値は1Gです。max_batch_interval/max_batch_rows/max_batch_sizeが一緒になってサブタスクの実行閾値を形成します。これらのパラメータのいずれかが閾値に達すると、ロードサブタスクが終了し、新しいものが生成されます。 |
| max_error_number | サンプリングウィンドウ内で許可される最大エラー行数。0以上である必要があります。デフォルト値は0で、エラー行は許可されないことを意味します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウ内のエラー行数がmax_error_numberを超えた場合、定期ジョブは一時停止され、SHOW ROUTINE LOADコマンドとErrorLogUrlsを使用してデータ品質の問題を確認するための手動介入が必要になります。WHERE条件でフィルタリングされた行はエラー行としてカウントされません。 |
| strict_mode | 厳密モードを有効にするかどうか。デフォルト値は無効です。厳密モードは、ロードプロセス中の型変換に対して厳密なフィルタリングを適用します。有効にした場合、型変換後にNULLになる非null元データがフィルタリングされます。厳密モードでのフィルタリングルールは以下の通りです:
|
| timezone | ロードジョブで使用されるタイムゾーンを指定します。デフォルトはセッションのtimezoneパラメータを使用します。このパラメータは、ロードに関わるすべてのタイムゾーン関連関数の結果に影響します。 |
| format | ロードのデータ形式を指定します。デフォルトはCSVで、JSON形式がサポートされています。 |
| jsonpaths | データ形式がJSONの場合、jsonpathsを使用してネストされた構造からデータを抽出するJSONパスを指定できます。これは文字列のJSON配列で、各文字列はJSONパスを表します。 |
| json_root | JSON形式データをインポートする際、json_rootを通じてJSONデータのルートノードを指定できます。Dorisはルートノードから要素を抽出して解析します。デフォルトは空です。例えば、JSONルートノードを指定するには:"json_root" = "$.RECORDS" |
| strip_outer_array | JSON形式データをインポートする際、strip_outer_arrayがtrueの場合、JSONデータが配列として表現され、データ内の各要素が行として扱われることを示します。デフォルト値はfalseです。通常、KafkaのJSONデータは最外層に角括弧[]を持つ配列として表現される場合があります。この場合、"strip_outer_array" = "true"を指定して配列モードでTopicデータを消費できます。例えば、以下のデータは2行に解析されます:[{"user_id":1,"name":"Emily","age":25},{"user_id":2,"name":"Benjamin","age":35}] |
| send_batch_parallelism | バッチデータの送信並列性を設定するために使用されます。並列性の値がBE設定のmax_send_batch_parallelism_per_jobを超えた場合、調整BEはmax_send_batch_parallelism_per_jobの値を使用します。 |
| load_to_single_tablet | タスクごとに対応するパーティション内の1つのタブレットのみにデータをインポートすることをサポートします。デフォルト値はfalseです。このパラメータは、ランダムバケッティングを使用するOLAPテーブルにデータをインポートする場合にのみ設定できます。 |
| partial_columns | 部分列更新機能を有効にするかどうかを指定します。デフォルト値はfalseです。このパラメータは、テーブルモデルがUniqueでMerge on Writeを使用している場合にのみ設定できます。マルチテーブルストリーミングはこのパラメータをサポートしていません。詳細については、Partial Column Updateを参照してください。 |
| max_filter_ratio | サンプリングウィンドウ内で許可される最大フィルタ比率。0から1までの値である必要があります。デフォルト値は1.0で、任意のエラー行を許容できることを示します。サンプリングウィンドウはmax_batch_rows * 10です。サンプリングウィンドウ内のエラー行と総行数の比率がmax_filter_ratioを超えた場合、ルーティンジョブは一時停止され、データ品質の問題を確認するための手動介入が必要になります。WHERE条件でフィルタリングされた行はエラー行としてカウントされません。 |
| enclose | 囲み文字を指定します。CSVデータフィールドに行または列区切り文字が含まれている場合、偶発的な切り捨てを防ぐために単一バイト文字を囲み文字として指定できます。例えば、列区切り文字が","で囲み文字が"'"の場合、データ"a,'b,c'"では"b,c"が1つのフィールドとして解析されます。 |
| escape | エスケープ文字を指定します。囲み文字と同じ文字をフィールド内でエスケープするために使用されます。例えば、データが"a,'b,'c'"で、囲み文字が"'"であり、"b,'c"を1つのフィールドとして解析したい場合、""などの単一バイトエスケープ文字を指定し、データを"a,'b,'c'"に変更する必要があります。 |
これらのパラメータは、特定の要件に応じてRoutine Loadジョブの動作をカスタマイズするために使用できます。
04 data_source_properties句
Routine Loadジョブを作成する際、data_source_properties句を指定してKafkaデータソースのプロパティを指定できます。構文は以下の通りです:
FROM KAFKA ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
data_source_properties句の利用可能なオプションは以下の通りです:
| パラメータ | 説明 |
|---|---|
| kafka_broker_list | Kafkaブローカーの接続情報を指定します。形式は<kafka_broker_ip>:<kafka_port>です。複数のブローカーはカンマで区切られます。例えば、デフォルトポート9092でBroker Listを指定するには、以下のコマンドを使用できます:"kafka_broker_list" = "<broker1_ip>:9092,<broker2_ip>:9092" |
| kafka_topic | 購読するKafkaトピックを指定します。ロードジョブは1つのKafkaトピックのみを消費できます。 |
| kafka_partitions | 購読するKafkaパーティションを指定します。指定されない場合、デフォルトですべてのパーティションが消費されます。 |
| kafka_offsets | Kafkaパーティションの開始消費オフセットを指定します。タイムスタンプが指定された場合、そのタイムスタンプ以上の最も近いオフセットから消費が開始されます。オフセットは0以上の特定のオフセットか、以下の形式を使用できます:
|
| property | カスタムKafkaパラメータを指定します。これはKafka shellの「--property」パラメータと同等です。パラメータの値がファイルの場合、値の前に「FILE:」キーワードを追加する必要があります。ファイルの作成については、CREATE FILEコマンドドキュメントを参照してください。サポートされているその他のカスタムパラメータについては、librdkafkaの公式CONFIGURATIONドキュメントのクライアント側設定オプションを参照してください。例:"property.client.id" = "12345"、"property.group.id" = "group_id_0"、"property.ssl.ca.location" = "FILE:ca.pem" |
data_source_propertiesでKafka propertyパラメータを設定することで、セキュリティアクセスオプションを設定できます。現在、Dorisはplaintext(デフォルト)、SSL、PLAIN、Kerberosなど、さまざまなKafkaセキュリティプロトコルをサポートしています。
ロードステータス
SHOW ROUTINE LOADコマンドを使用してロードジョブのステータスを確認できます。コマンドの構文は以下の通りです:
SHOW [ALL] ROUTINE LOAD [FOR jobName];
例えば、SHOW ROUTINE LOADを実行すると、以下のような結果セットが返されます:
mysql> SHOW ROUTINE LOAD FOR testdb.example_routine_load\G
*************************** 1. row ***************************
Id: 12025
Name: example_routine_load
CreateTime: 2024-01-15 08:12:42
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:testdb
TableName: test_routineload_tbl
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"max_batch_rows":"200000","timezone":"America/New_York","send_batch_parallelism":"1","load_to_single_tablet":"false","column_separator":"','","line_delimiter":"\n","current_concurrent_number":"1","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"10","max_batch_size":"104857600","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"user_id,name,age","whereExpr":"*","desired_concurrent_number":"5","precedingFilter":"*","format":"csv","max_error_number":"0","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"test-topic","currentKafkaPartitions":"0","brokerList":"192.168.88.62:9092"}
CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_routine_load_73daf600-884e-46c0-a02b-4e49fdf3b4dc"}
Statistic: {"receivedBytes":28,"runningTxns":[],"errorRows":0,"committedTaskNum":3,"loadedRows":3,"loadRowsRate":0,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":3,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":30069}
Progress: {"0":"2"}
Lag: {"0":0}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
User: root
Comment:
1 row in set (0.00 sec)
結果セットの列は以下の情報を提供します:
| Column Name | Description |
|---|---|
| Id | Dorisによって自動生成される、ロードジョブのID。 |
| Name | ロードジョブの名前。 |
| CreateTime | ジョブが作成された時刻。 |
| PauseTime | ジョブが最後に一時停止された時刻。 |
| EndTime | ジョブが終了した時刻。 |
| DbName | 関連付けられたデータベースの名前。 |
| TableName | 関連付けられたテーブルの名前。マルチテーブルシナリオでは、"multi-table"として表示されます。 |
| IsMultiTbl | マルチテーブルロードかどうかを示します。 |
| State | ジョブの実行状態で、5つの値を持つことができます:
|
| DataSourceType | この例では、KAFKAであるデータソースのタイプ。 |
| CurrentTaskNum | 現在のサブタスクの数。 |
| JobProperties | ジョブ設定の詳細。 |
| DataSourceProperties | データソース設定の詳細。 |
| CustomProperties | カスタム設定プロパティ。 |
| Statistic | ジョブの実行状況の統計。 |
| Progress | ジョブの進捗。Kafkaデータソースの場合、各パーティションで消費されたオフセットを表示します。例えば、{"0":"2"}はパーティション0が2つのオフセットを消費したことを示します。 |
| Lag | ジョブのラグ。Kafkaデータソースの場合、各パーティションの消費ラグを表示します。例えば、{"0":10}はパーティション0の消費ラグが10であることを示します。 |
| ReasonOfStateChanged | ジョブの状態変更の理由。 |
| ErrorLogUrls | フィルタリングされた低品質データを表示するURL。 |
| OtherMsg | その他のエラーメッセージ。 |
ロード例
最大エラー許容値の設定
-
サンプルデータのロード:
1,Benjamin,18
2,Emily,20
3,Alexander,dirty_data -
テーブルを作成:
CREATE TABLE demo.routine_test01 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job01 ON routine_test01
COLUMNS TERMINATED BY ","
PROPERTIES
(
"max_filter_ratio"="0.5",
"max_error_number" = "100",
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test01;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
+------+------------+------+
2 rows in set (0.01 sec)
指定されたオフセットからのデータ消費
-
サンプルデータをロード:
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
テーブルを作成:
CREATE TABLE demo.routine_test02 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job02 ON routine_test02
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad02",
"kafka_partitions" = "0",
"kafka_offsets" = "3"
); -
結果の読み込み:
mysql> select * from routine_test02;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
Consumer Groupのgroup.idとclient.idの指定
-
サンプルデータを読み込む:
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
テーブルを作成する:
CREATE TABLE demo.routine_test03 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job03 ON routine_test03
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad01",
"property.group.id" = "kafka_job03",
"property.client.id" = "kafka_client_03",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test03;
+------+------------+------+
| id | name | age |
+------+------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+------------+------+
3 rows in set (0.01 sec)
読み込みフィルタリング条件の設定
-
サンプルデータを読み込む:
1,Benjamin,18
2,Emily,20
3,Alexander,22
4,Sophia,24
5,William,26
6,Charlotte,28 -
テーブルを作成する:
CREATE TABLE demo.routine_test04 (
id INT NOT NULL COMMENT "User ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
ロードコマンド:
CREATE ROUTINE LOAD demo.kafka_job04 ON routine_test04
COLUMNS TERMINATED BY ",",
WHERE id >= 3
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad04",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果を読み込み:
mysql> select * from routine_test04;
+------+--------------+------+
| id | name | age |
+------+--------------+------+
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+--------------+------+
3 rows in set (0.01 sec)
指定されたパーティションデータの読み込み
-
サンプルデータを読み込む:
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
テーブルを作成:
CREATE TABLE demo.routine_test05 (
id INT NOT NULL COMMENT "ID",
name VARCHAR(30) NOT NULL COMMENT "Name",
age INT COMMENT "Age",
date DATETIME COMMENT "Date"
)
DUPLICATE KEY(`id`)
PARTITION BY RANGE(`id`)
(PARTITION partition_a VALUES [("0"), ("1")),
PARTITION partition_b VALUES [("1"), ("2")),
PARTITION partition_c VALUES [("2"), ("3")))
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job05 ON routine_test05
COLUMNS TERMINATED BY ",",
PARTITION(partition_b)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad05",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test05;
+------+----------+------+---------------------+
| id | name | age | date |
+------+----------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
+------+----------+------+---------------------+
1 rows in set (0.01 sec)
load の時間帯設定
-
サンプルデータをロードする:
1,Benjamin,18,2024-02-04 10:00:00
2,Emily,20,2024-02-05 11:00:00
3,Alexander,22,2024-02-06 12:00:00 -
テーブルを作成:
CREATE TABLE demo.routine_test06 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
date DATETIME COMMENT "date"
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job06 ON routine_test06
COLUMNS TERMINATED BY ","
PROPERTIES
(
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad06",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
読み込み結果:
mysql> select * from routine_test06;
+------+-------------+------+---------------------+
| id | name | age | date |
+------+-------------+------+---------------------+
| 1 | Benjamin | 18 | 2024-02-04 10:00:00 |
| 2 | Emily | 20 | 2024-02-05 11:00:00 |
| 3 | Alexander | 22 | 2024-02-06 12:00:00 |
+------+-------------+------+---------------------+
3 rows in set (0.00 sec)
merge_typeの設定
delete操作のmerge_typeを指定する
-
サンプルデータを読み込む:
3,Alexander,22
5,William,26
読み込み前のテーブルデータ:
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
2. テーブルを作成:
```sql
CREATE TABLE demo.routine_test07 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. loadコマンド:
```sql
CREATE ROUTINE LOAD demo.kafka_job07 ON routine_test07
WITH DELETE
COLUMNS TERMINATED BY ","
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad07",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 読み込み結果:
```sql
mysql> SELECT * FROM routine_test07;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 4 | Sophia | 24 |
| 6 | Charlotte | 28 |
+------+----------------+------+
```
merge操作のmerge_typeを指定する
-
サンプルデータを読み込む:
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
ロード前のテーブルデータ:
```sql
mysql> SELECT * FROM routine_test08;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. テーブルの作成:
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1;
```
3. Loadコマンド:
```sql
CREATE ROUTINE LOAD demo.kafka_job08 ON routine_test08
WITH MERGE
COLUMNS TERMINATED BY ",",
DELETE ON id = 2
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad08",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 結果の読み込み:
```sql
mysql> SELECT * FROM routine_test08;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
マージする順序列の指定
-
サンプルデータをロードします:
1,xiaoxiaoli,28
2,xiaoxiaowang,30
3,xiaoxiaoliu,32
4,dadali,34
5,dadawang,36
6,dadaliu,38
テーブル内のデータ(読み込み前):
```sql
mysql> SELECT * FROM routine_test09;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
| 4 | Sophia | 24 |
| 5 | William | 26 |
| 6 | Charlotte | 28 |
+------+----------------+------+
6 rows in set (0.01 sec)
```
2. テーブルの作成
```sql
CREATE TABLE demo.routine_test08 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"function_column.sequence_col" = "age"
);
```
3. Load コマンド
```sql
CREATE ROUTINE LOAD demo.kafka_job09 ON routine_test09
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age),
DELETE ON id = 2,
ORDER BY age
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad09",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
```
4. 読み込み結果:
```sql
mysql> SELECT * FROM routine_test09;
+------+-------------+------+
| id | name | age |
+------+-------------+------+
| 1 | xiaoxiaoli | 28 |
| 3 | xiaoxiaoliu | 32 |
| 4 | dadali | 34 |
| 5 | dadawang | 36 |
| 6 | dadaliu | 38 |
+------+-------------+------+
5 rows in set (0.00 sec)
```
カラムマッピングと派生カラム計算による読み込み
-
サンプルデータを読み込む:
1,Benjamin,18
2,Emily,20
3,Alexander,22 -
テーブルを作成:
CREATE TABLE demo.routine_test10 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job10 ON routine_test10
COLUMNS TERMINATED BY ",",
COLUMNS(id, name, age, num=age*10)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad10",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果を読み込み:
mysql> SELECT * FROM routine_test10;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
同梱データでの読み込み
-
サンプルデータを読み込む:
1,"Benjamin",18
2,"Emily",20
3,"Alexander",22 -
テーブルを作成:
CREATE TABLE demo.routine_test11 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "number"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job11 ON routine_test11
COLUMNS TERMINATED BY ","
PROPERTIES
(
"desired_concurrent_number"="1",
"enclose" = "\""
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> SELECT * FROM routine_test11;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.02 sec)
JSON Format Load
シンプルモードでJSON形式データを読み込む
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
テーブルを作成:
CREATE TABLE demo.routine_test12 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job12 ON routine_test12
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad12",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test12;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.02 sec)
match モードで複雑な JSON 形式データを読み込む
-
サンプルデータを読み込む
{ "name" : "Benjamin", "id" : 1, "num":180 , "age":18 }
{ "name" : "Emily", "id" : 2, "num":200 , "age":20 }
{ "name" : "Alexander", "id" : 3, "num":220 , "age":22 } -
テーブルを作成:
CREATE TABLE demo.routine_test13 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job13 ON routine_test13
COLUMNS(name, id, num, age)
PROPERTIES
(
"format" = "json",
"jsonpaths" = "[\"$.name\",\"$.id\",\"$.num\",\"$.age\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad13",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test13;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
指定されたJSONルートノードでデータを読み込む
-
サンプルデータを読み込む
{"id": 1231, "source" :{ "id" : 1, "name" : "Benjamin", "age":18 }}
{"id": 1232, "source" :{ "id" : 2, "name" : "Emily", "age":20 }}
{"id": 1233, "source" :{ "id" : 3, "name" : "Alexander", "age":22 }} -
テーブルを作成:
CREATE TABLE demo.routine_test14 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド
CREATE ROUTINE LOAD demo.kafka_job14 ON routine_test14
PROPERTIES
(
"format" = "json",
"json_root" = "$.source"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad14",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み
mysql> select * from routine_test14;
+------+----------------+------+
| id | name | age |
+------+----------------+------+
| 1 | Benjamin | 18 |
| 2 | Emily | 20 |
| 3 | Alexander | 22 |
+------+----------------+------+
3 rows in set (0.01 sec)
列マッピングと派生列計算を使用したデータの読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18 }
{ "id" : 2, "name" : "Emily", "age":20 }
{ "id" : 3, "name" : "Alexander", "age":22 } -
テーブルを作成:
CREATE TABLE demo.routine_test15 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
num INT COMMENT "num"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job15 ON routine_test15
COLUMNS(id, name, age, num=age*10)
PROPERTIES
(
"format" = "json",
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad15",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果を読み込む:
mysql> select * from routine_test15;
+------+----------------+------+------+
| id | name | age | num |
+------+----------------+------+------+
| 1 | Benjamin | 18 | 180 |
| 2 | Emily | 20 | 200 |
| 3 | Alexander | 22 | 220 |
+------+----------------+------+------+
3 rows in set (0.01 sec)
複雑なデータ型の読み込み
配列データ型の読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18, "array":[1,2,3,4,5]}
{ "id" : 2, "name" : "Emily", "age":20, "array":[6,7,8,9,10]}
{ "id" : 3, "name" : "Alexander", "age":22, "array":[11,12,13,14,15]} -
テーブルを作成する:
CREATE TABLE demo.routine_test16
(
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
array ARRAY<int(11)> NULL COMMENT "test array column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job16 ON routine_test16
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad16",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test16;
+------+----------------+------+----------------------+
| id | name | age | array |
+------+----------------+------+----------------------+
| 1 | Benjamin | 18 | [1, 2, 3, 4, 5] |
| 2 | Emily | 20 | [6, 7, 8, 9, 10] |
| 3 | Alexander | 22 | [11, 12, 13, 14, 15] |
+------+----------------+------+----------------------+
3 rows in set (0.00 sec)
マップデータタイプの読み込み
-
サンプルデータを読み込む:
{ "id" : 1, "name" : "Benjamin", "age":18, "map":{"a": 100, "b": 200}}
{ "id" : 2, "name" : "Emily", "age":20, "map":{"c": 300, "d": 400}}
{ "id" : 3, "name" : "Alexander", "age":22, "map":{"e": 500, "f": 600}} -
テーブルを作成する:
CREATE TABLE demo.routine_test17 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
map Map<STRING, INT> NULL COMMENT "test column"
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job17 ON routine_test17
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad17",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test17;
+------+----------------+------+--------------------+
| id | name | age | map |
+------+----------------+------+--------------------+
| 1 | Benjamin | 18 | {"a":100, "b":200} |
| 2 | Emily | 20 | {"c":300, "d":400} |
| 3 | Alexander | 22 | {"e":500, "f":600} |
+------+----------------+------+--------------------+
3 rows in set (0.01 sec)
Bitmap Data Typeの読み込み
-
サンプルデータを読み込む
{ "id" : 1, "name" : "Benjamin", "age":18, "bitmap_id":243}
{ "id" : 2, "name" : "Emily", "age":20, "bitmap_id":28574}
{ "id" : 3, "name" : "Alexander", "age":22, "bitmap_id":8573} -
テーブルを作成:
CREATE TABLE demo.routine_test18 (
id INT NOT NULL COMMENT "id",
name VARCHAR(30) NOT NULL COMMENT "name",
age INT COMMENT "age",
bitmap_id INT COMMENT "test",
device_id BITMAP BITMAP_UNION COMMENT "test column"
)
AGGREGATE KEY (`id`,`name`,`age`,`bitmap_id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1; -
Loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job18 ON routine_test18
COLUMNS(id, name, age, bitmap_id, device_id=to_bitmap(bitmap_id))
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad18",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select id, BITMAP_UNION_COUNT(pv) over(order by id) uv from(
-> select id, BITMAP_UNION(device_id) as pv
-> from routine_test18
-> group by id
-> ) final;
+------+------+
| id | uv |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
3 rows in set (0.00 sec)
HLL Data Typeの読み込み
-
サンプルデータの読み込み:
2022-05-05,10001,Test01,Beijing,windows
2022-05-05,10002,Test01,Beijing,linux
2022-05-05,10003,Test01,Beijing,macos
2022-05-05,10004,Test01,Hebei,windows
2022-05-06,10001,Test01,Shanghai,windows
2022-05-06,10002,Test01,Shanghai,linux
2022-05-06,10003,Test01,Jiangsu,macos
2022-05-06,10004,Test01,Shaanxi,windows -
テーブルを作成:
create table demo.routine_test19 (
dt DATE,
id INT,
name VARCHAR(10),
province VARCHAR(10),
os VARCHAR(10),
pv hll hll_union
)
Aggregate KEY (dt,id,name,province,os)
distributed by hash(id) buckets 10; -
loadコマンド:
CREATE ROUTINE LOAD demo.kafka_job19 ON routine_test19
COLUMNS TERMINATED BY ",",
COLUMNS(dt, id, name, province, os, pv=hll_hash(id))
FROM KAFKA
(
"kafka_broker_list" = "10.16.10.6:9092",
"kafka_topic" = "routineLoad19",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
); -
結果の読み込み:
mysql> select * from routine_test19;
+------------+-------+----------+----------+---------+------+
| dt | id | name | province | os | pv |
+------------+-------+----------+----------+---------+------+
| 2022-05-05 | 10001 | Test01 | Beijing | windows | NULL |
| 2022-05-06 | 10001 | Test01 | Shanghai | windows | NULL |
| 2022-05-05 | 10002 | Test01 | Beijing | linux | NULL |
| 2022-05-06 | 10002 | Test01 | Shanghai | linux | NULL |
| 2022-05-05 | 10004 | Test01 | Hebei | windows | NULL |
| 2022-05-06 | 10004 | Test01 | Shaanxi | windows | NULL |
| 2022-05-05 | 10003 | Test01 | Beijing | macos | NULL |
| 2022-05-06 | 10003 | Test01 | Jiangsu | macos | NULL |
+------------+-------+----------+----------+---------+------+
8 rows in set (0.01 sec)
mysql> SELECT HLL_UNION_AGG(pv) FROM routine_test19;
+-------------------+
| hll_union_agg(pv) |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.01 sec)
Kafka Security Authentication
SSL認証を使用したKafkaデータの読み込み
読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job20 ON routine_test20
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "ssl_passwd"
);
パラメータの説明:
| Parameter | Description |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル、この例ではSSL |
| property.ssl.ca.location | CA(認証局)証明書の場所 |
| property.ssl.certificate.location | クライアントの公開鍵の場所(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
| property.ssl.key.location | クライアントの秘密鍵の場所(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
| property.ssl.key.password | クライアントの秘密鍵のパスワード(Kafkaサーバーでクライアント認証が有効になっている場合に必要) |
Kerberos認証を使用したKafkaデータの読み込み
読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job21 ON routine_test21
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad21",
"property.security.protocol" = "SASL_PLAINTEXT",
"property.sasl.kerberos.service.name" = "kafka",
"property.sasl.kerberos.keytab"="/opt/third/kafka/kerberos/kafka_client.keytab",
"property.sasl.kerberos.principal" = "clients/stream.dt.local@EXAMPLE.COM"
);
パラメータの説明:
| パラメータ | 説明 |
|---|---|
| property.security.protocol | 使用するセキュリティプロトコル、この例ではSASL_PLAINTEXT |
| property.sasl.kerberos.service.name | ブローカーサービス名を指定、デフォルトはKafka |
| property.sasl.kerberos.keytab | keytabファイルの場所 |
| property.sasl.kerberos.principal | Kerberosプリンシパルを指定 |
PLAIN認証を使用したKafkaクラスタの読み込み
- 読み込みコマンドの例:
CREATE ROUTINE LOAD demo.kafka_job22 ON routine_test22
PROPERTIES
(
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.100.129:9092",
"kafka_topic" = "routineLoad22",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="admin",
"property.sasl.password"="admin"
);
パラメータの説明:
| Parameter | Description |
|---|---|
| property.security.protocol | 使用されるセキュリティプロトコル、この例ではSASL_PLAINTEXTです |
| property.sasl.mechanism | SASL認証メカニズムをPLAINとして指定します |
| property.sasl.username | SASLのユーザー名 |
| property.sasl.password | SASLのパスワード |
単一タスクによる複数テーブルへのロード
"example_db"に対して"test1"という名前のKafkaルーチン動的テーブルロードタスクを作成します。カラム区切り文字、group.id、およびclient.idを指定します。すべてのパーティションを自動的に消費し、利用可能なデータポジション(OFFSET_BEGINNING)から購読を開始します。
Kafkaから"example_db"のテーブル"tbl1"と"tbl2"にデータをロードする必要があると仮定し、"test1"という名前のRoutine Loadタスクを作成します。このタスクはKafkaのトピックmy_topicから"tbl1"と"tbl2"の両方に同時にデータをロードします。この方法により、単一のroutine loadタスクを使用してKafkaから2つのテーブルにデータをロードできます。
CREATE ROUTINE LOAD example_db.test1
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
現在、KafkaのValueフィールドからテーブル名を抽出することのみがサポートされています。形式は以下のようにする必要があり、JSONを例として:table_name|{"col1": "val1", "col2": "val2"}、ここでtbl_nameはテーブル名で、|はテーブル名とテーブルデータ間の区切り文字として使用されます。同じ形式がCSVデータにも適用され、例えばtable_name|val1,val2,val3のようになります。ここでのtable_nameはDoris内のテーブル名と一致している必要があり、そうでなければロードは失敗します。動的テーブルは後述のcolumn_mapping設定をサポートしないことに注意してください。
厳密モードロード
"example_db"と"example_tbl"に対して"test1"という名前のKafka routine loadタスクを作成します。ロードタスクは厳密モードに設定されます。
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
PRECEDING FILTER k1 = 1,
WHERE k1 < 100 and k2 like "%doris%"
PROPERTIES
(
"strict_mode" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic"
);
SASL Kafka サービスに接続する
ここでは、StreamNative メッセージサービスへのアクセスを例に説明します:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(user_id, name, age)
FROM KAFKA (
"kafka_broker_list" = "pc-xxxx.aws-mec1-test-xwiqv.aws.snio.cloud:9093",
"kafka_topic" = "my_topic",
"property.security.protocol" = "SASL_SSL",
"property.sasl.mechanism" = "PLAIN",
"property.sasl.username" = "user",
"property.sasl.password" = "token:eyJhbxxx",
"property.group.id" = "my_group_id_1",
"property.client.id" = "my_client_id_1",
"property.enable.ssl.certificate.verification" = "false"
);
BE側で信頼されるCA証明書パスが設定されていない場合は、サーバー証明書が信頼できるかどうかを検証しないよう"property.enable.ssl.certificate.verification" = "false"を設定する必要があることに注意してください。
そうでない場合は、信頼されるCA証明書パスを設定する必要があります:"property.ssl.ca.location" = "/path/to/ca-cert.pem"。
詳細情報
Routine LoadのSQLマニュアルを参照してください。また、クライアントのコマンドラインでHELP ROUTINE LOADを入力すると、より詳しいヘルプを確認できます。