
結合
JOINとは
リレーショナルデータベースでは、データは複数のテーブルに分散して格納されており、これらのテーブルは特定の関係を通じて相互に接続されています。SQL JOIN操作により、ユーザーはこれらの関係に基づいて異なるテーブルをより完全な結果セットに結合することができます。
DorisでサポートされているJOINタイプ
-
INNER JOIN: JOIN条件に基づいて左テーブルの各行を右テーブルのすべての行と比較し、両方のテーブルから一致する行を返します。詳細については、SELECTのJOINクエリの構文定義を参照してください。
-
LEFT JOIN: INNER JOINの結果セットをベースとし、左テーブルの行が右テーブルで一致しない場合、左テーブルのすべての行が返され、右テーブルの対応する列はNULLとして表示されます。
-
RIGHT JOIN: LEFT JOINの反対です。右テーブルの行が左テーブルで一致しない場合、右テーブルのすべての行が返され、左テーブルの対応する列はNULLとして表示されます。
-
FULL JOIN: INNER JOINの結果セットをベースとし、両方のテーブルからすべての行を返し、一致しない箇所にはNULLを埋めます。
-
CROSS JOIN: JOIN条件を持たず、2つのテーブルのデカルト積を返します。左テーブルの各行が右テーブルの各行と結合されます。
-
LEFT SEMI JOIN: JOIN条件に基づいて左テーブルの各行を右テーブルのすべての行と比較します。一致が存在する場合、左テーブルから対応する行が返されます。
-
RIGHT SEMI JOIN: LEFT SEMI JOINの反対です。右テーブルの各行を左テーブルのすべての行と比較し、一致が存在する場合に右テーブルから対応する行を返します。
-
LEFT ANTI JOIN: JOIN条件に基づいて左テーブルの各行を右テーブルのすべての行と比較します。一致しない場合、左テーブルから対応する行が返されます。
-
RIGHT ANTI JOIN: LEFT ANTI JOINの反対です。右テーブルの各行を左テーブルのすべての行と比較し、一致しない右テーブルの行を返します。
-
NULL AWARE LEFT ANTI JOIN: LEFT ANTI JOINと似ていますが、一致する列がNULLである左テーブルの行を無視します。
DorisにおけるJOINの実装
Dorisでは、JOINの実装方法としてHash JoinとNested Loop Joinの2つをサポートしています。
- Hash Join: 等価JOIN列に基づいて右テーブルでハッシュテーブルを構築し、左テーブルのデータをこのハッシュテーブルを通じてストリーミングしてJOIN計算を行います。この方法は等価JOIN条件が適用可能な場合に限定されます。
- Nested Loop Join: この方法では2つのネストしたループを使用し、左テーブルによって駆動され、左テーブルの各行を反復処理し、JOIN条件に基づいて右テーブルのすべての行と比較します。これは、Hash Joinが処理できないケース(GREATER THANやLESS THANの比較を含むクエリやデカルト積を必要とするケース)を含む、すべてのJOINシナリオに適用できます。ただし、Hash Joinと比較して、Nested Loop Joinはパフォーマンスが劣る場合があります。
DorisにおけるHash Joinの実装
分散MPPデータベースとして、Apache DorisではJOIN結果の正確性を確保するため、Hash Joinプロセス中にデータシャッフルが必要です。以下にいくつかのデータシャッフル方法を示します:
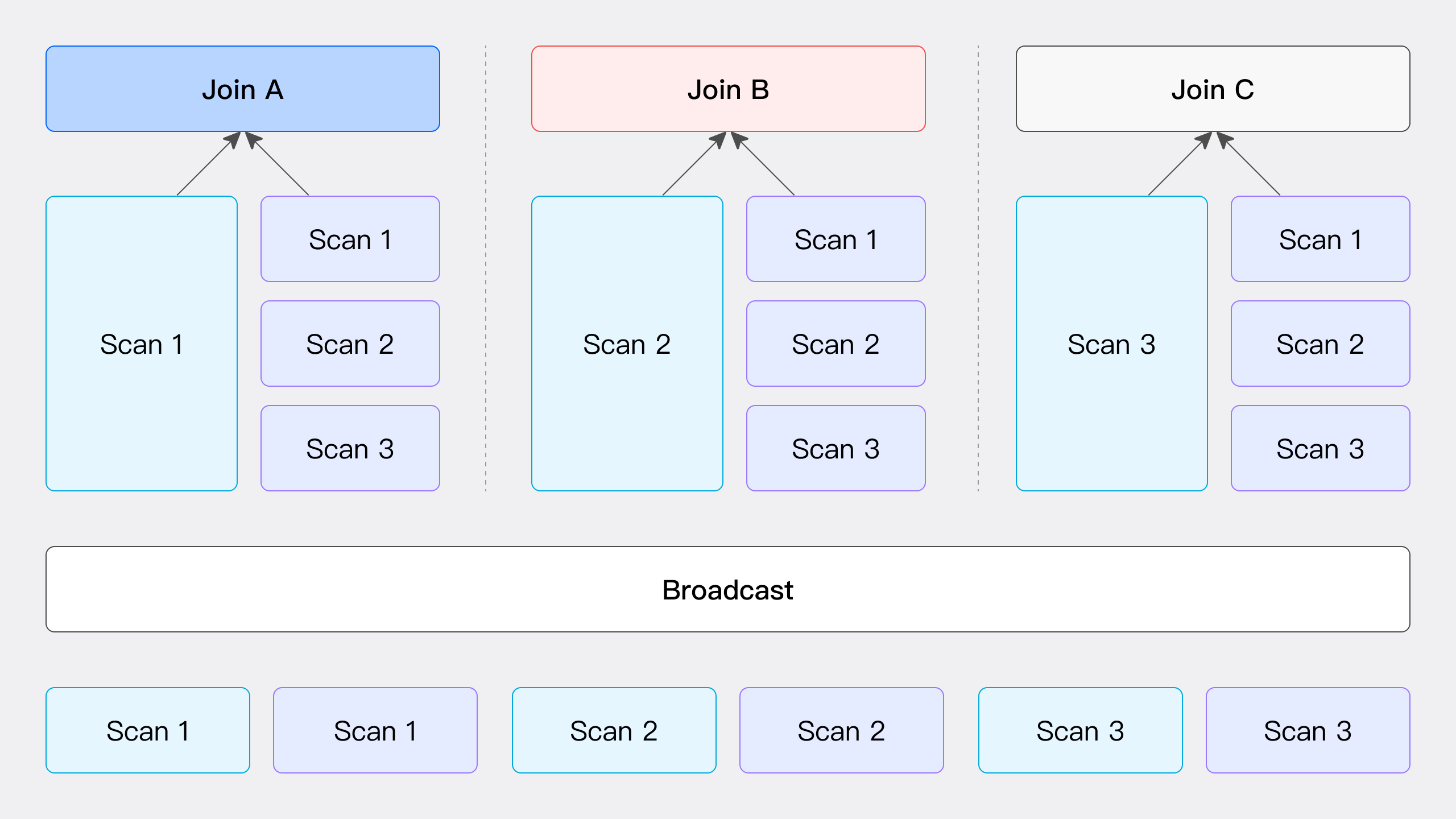
Broadcast Join 図で示されているように、Broadcast Joinプロセスでは、右テーブルのすべてのデータを、左テーブルのデータをスキャンするノードを含む、JOIN計算に参加するすべてのノードに送信し、左テーブルのデータは移動しません。このプロセスでは、各ノードが右テーブルのデータの完全なコピー(総量T(R))を受信し、すべてのノードがJOIN操作を実行するために必要なデータを持つことを保証します。
この方法は様々なシナリオに適用できますが、RIGHT OUTER、RIGHT ANTI、およびRIGHT SEMIタイプのHash Joinには適用できません。ネットワークオーバーヘッドは、JOINノード数Nに右テーブルのデータ量T(R)を掛けた値として計算されます。
パーティション Shuffle Join
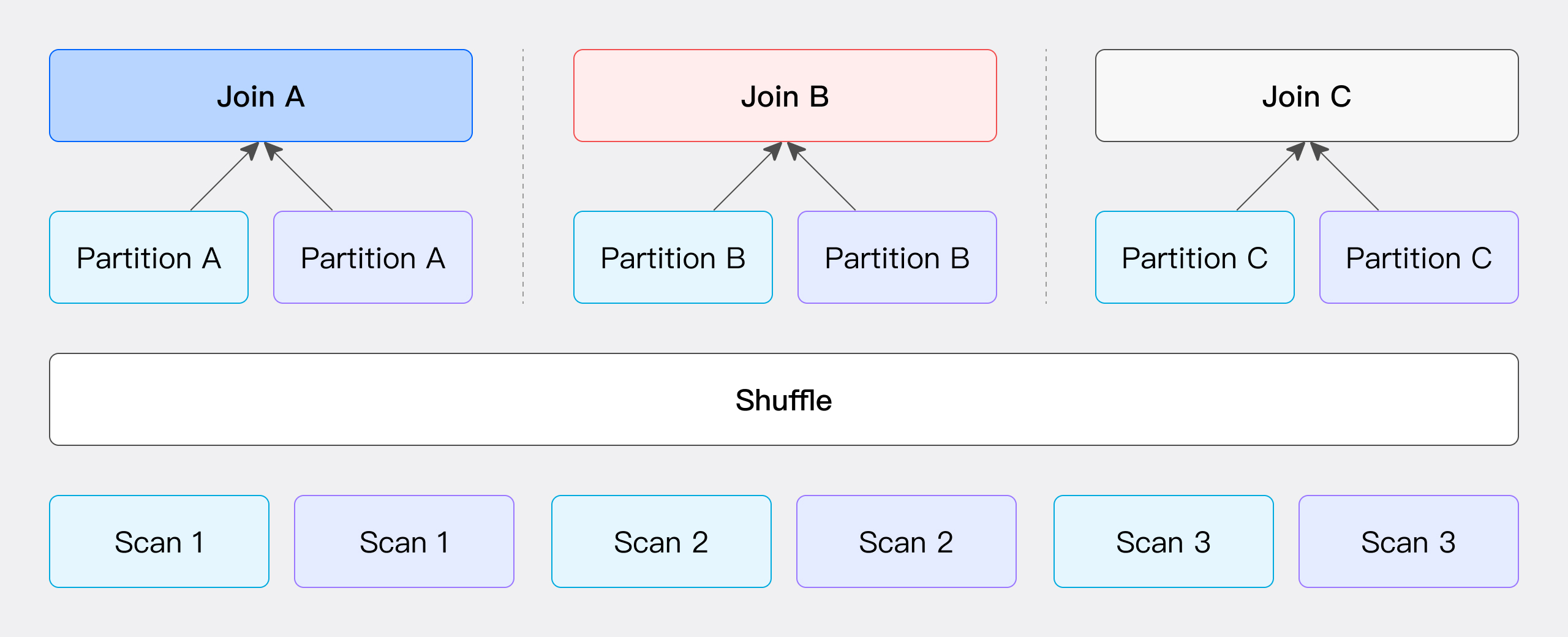
この方法では、JOIN条件に基づいてハッシュ値を計算し、バケット化を実行します。具体的には、左テーブルと右テーブルの両方のデータがJOIN条件から計算されたハッシュ値に従ってパーティション化され、これらのパーティション化されたデータセットが対応するパーティションノードに送信されます(図で示されている通り)。
この方法のネットワークオーバーヘッドは主に2つの部分から構成されます:左テーブルのデータT(S)の転送コストと右テーブルのデータT(R)の転送コストです。この方法は、JOIN条件を使用してデータのバケット化を実行することに依存するため、Hash JOIN操作のみをサポートします。
バケット Shuffle Join
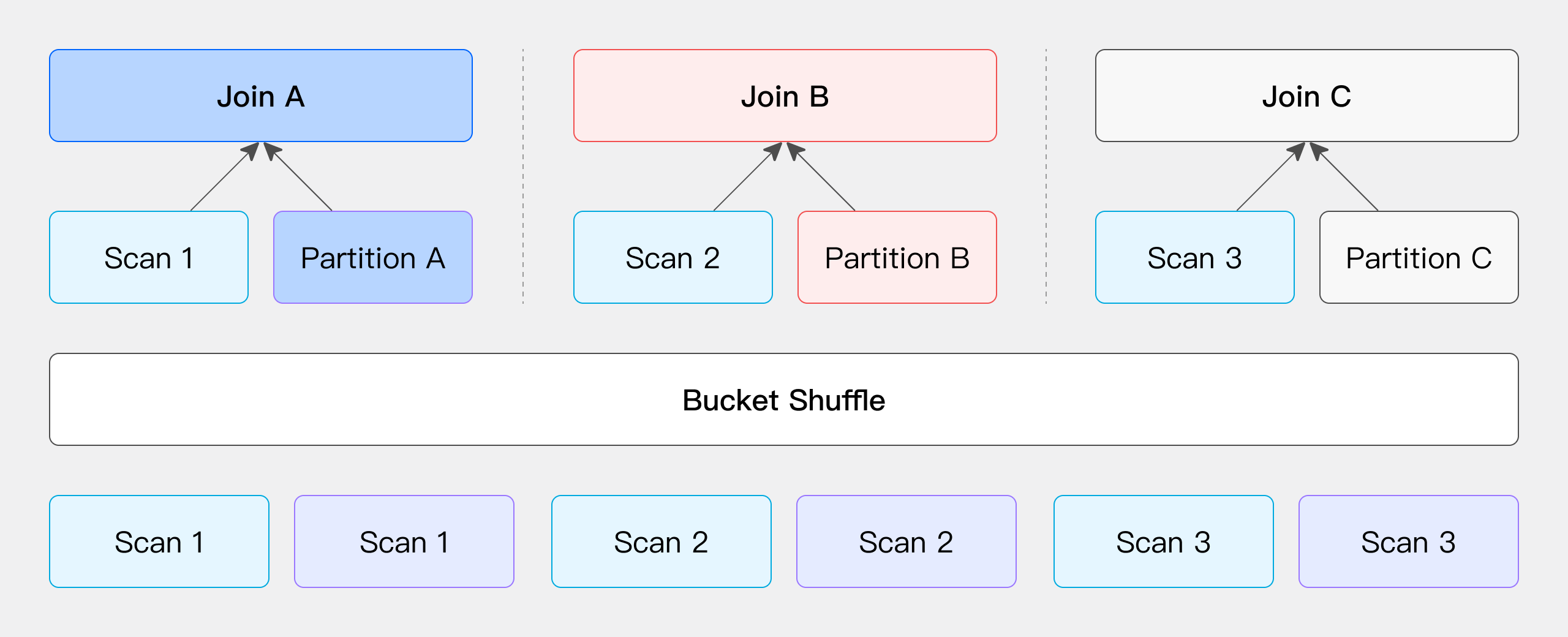
JOIN条件が左テーブルのバケット列を含む場合、左テーブルのデータ位置は変更されず、右テーブルのデータが左テーブルのノードに分散してJOINが実行され、ネットワークオーバーヘッドが削減されます。
JOIN操作に関与するテーブルの一方のデータが既にJOIN条件列に従ってハッシュ分散されている場合、ユーザーはこちら側のデータ位置を変更せずに保持し、同じJOIN条件列とハッシュ分散に基づいて他方のデータを分散することを選択できます。(ここでの「テーブル」は物理的に格納されたテーブルだけでなく、SQLクエリ内の任意の演算子の出力結果も指します。ユーザーは柔軟に左テーブルまたは右テーブルのデータ位置を変更せずに保持し、他方のテーブルのみを移動・分散することを選択できます。)
例えば、Dorisの物理テーブルの場合、テーブルデータはハッシュ計算によってバケット化された方法で格納されているため、ユーザーはこの機能を直接活用してJOIN操作のデータシャッフルプロセスを最適化できます。JOINする必要がある2つのテーブルがあり、JOIN列が左テーブルのバケット列である場合を想定してください。この場合、左テーブルのデータを移動する必要はなく、左テーブルのバケット情報に基づいて右テーブルのデータを適切な場所に分散するだけでJOIN計算を完了できます。
このプロセスの主要なネットワークオーバーヘッドは、右テーブルのデータの移動から生じ、T(R)として表されます。
Colocate Join
バケット Shuffle Joinと同様に、Joinに関与する両方のテーブルが既にJoin条件列に従ってHashで分散されている場合、Shuffleプロセスをスキップして、ローカルデータで直接Join計算を実行できます。これは物理テーブルで説明できます:
DorisでDISTRIBUTED BY HASHの指定でテーブルを作成する場合、システムはデータインポート中にHash分散キーに基づいてデータを分散します。両方のテーブルのHash分散キーがたまたまJoin条件列と一致する場合、これらの2つのテーブルのデータは既にJoin要件に従って事前分散されていると言え、追加のShuffle操作を不要にします。したがって、実際のクエリ中に、これら2つのテーブルでJoin計算を直接実行できます。
データを直接スキャンした後にJoinが実行されるシナリオでは、テーブル作成時に特定の条件を満たす必要があります。2つの物理テーブル間のColocate Joinに関する後続の制限を参照してください。
バケット Shuffle Join VS Colocate Join
前述したように、バケット Shuffle JoinとColocate Joinの両方について、参加するテーブルの分散が特定の条件を満たす限り、join操作を実行できます(ここでの「テーブル」は、SQLクエリ演算子からの任意の出力を指します)。
次に、2つのテーブル、t1とt2、および関連するSQLの例を使用して、一般化されたバケット Shuffle JoinとColocate Joinについてより詳細な説明を提供します。まず、両方のテーブルのテーブル作成文は以下の通りです:
create table t1
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
create table t2
(
c1 bigint,
c2 bigint
)
DISTRIBUTED BY HASH(c1) BUCKETS 3
PROPERTIES ("replication_num" = "1");
Bucket Shuffle Join の例
次の例では、テーブル t1 と t2 の両方が GROUP BY 演算子によって処理され、新しいテーブルが作成されています(この時点で、tx テーブルは c1 によってハッシュ分散され、ty テーブルは c2 によってハッシュ分散されています)。後続の JOIN 条件は tx.c1 = ty.c2 であり、これは Bucket Shuffle Join の条件を完全に満たしています。
explain select *
from
(
-- The t1 table is hash-distributed by c1, and after the GROUP BY operator, it still maintains the hash distribution by c1.
select c1 as c1, sum(c2) as c2
from t1
group by c1
) tx
join
(
-- The t2 table is hash-distributed by c1, but after the GROUP BY operator, the data is redistributed to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c1 = ty.c2;
以下のExplain execution planから、Hash Joinノード7の左の子ノードが集約ノード6であり、右の子ノードがExchangeノード4であることが観察できます。これは、左の子ノードからのデータが集約後に同じ場所に残る一方で、右の子ノードからのデータがBucket Shuffleメソッドを使用して左の子ノードが存在するノードに分散され、後続のHash Join操作を実行するためであることを示しています。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c1[#18] |
| c2[#19] |
| c2[#20] |
| c1[#21] |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 7:VHASH JOIN(364) |
| | join op: INNER JOIN(BUCKET_SHUFFLE)[] |
| | equal join conjunct: (c1[#12] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 8 |
| | output tuple id: 8 |
| | vIntermediate tuple ids: 7 |
| | hash output slot ids: 6 7 12 13 |
| | final projections: c1[#14], c2[#15], c2[#16], c1[#17] |
| | final project output tuple id: 8 |
| | distribute expr lists: c1[#12] |
| | distribute expr lists: c2[#6] |
| | |
| |----4:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: c2[#6] |
| | |
| 6:VAGGREGATE (update finalize)(342) |
| | output: sum(c2[#9])[#11] |
| | group by: c1[#8] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c1[#10], c2[#11] |
| | final project output tuple id: 6 |
| | distribute expr lists: c1[#8] |
| | |
| 5:VOlapScanNode(339) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c2[#2] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| BUCKET_SHFFULE_HASH_PARTITIONED: c2[#6] |
| |
| 3:VAGGREGATE (merge finalize)(355) |
| | output: sum(partial_sum(c1)[#3])[#5] |
| | group by: c2[#2] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | final projections: c2[#4], c1[#5] |
| | final project output tuple id: 3 |
| | distribute expr lists: c2[#2] |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(349) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(346) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
97 rows in set (0.01 sec)
Colocate Joinの例
以下の例では、テーブルt1とt2の両方がGROUP BY演算子で処理され、新しいテーブルが生成されています(この時点で、txとtyの両方がc2によってハッシュ分散されています)。その後のJOIN条件はtx.c2 = ty.c2であり、これはColocate Joinの条件を完全に満たしています。
explain select *
from
(
-- The t1 table is initially hash-distributed by c1, but after the GROUP BY operator, the data distribution changes to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t1
group by c2
) tx
join
(
-- The t2 table is initially hash-distributed by c1, but after the GROUP BY operator, the data distribution changes to be hash-distributed by c2.
select c2 as c2, sum(c1) as c1
from t2
group by c2
) ty
on tx.c2 = ty.c2;
以下のExplain実行計画の結果から、Hash Joinノード8の左の子ノードが集約ノード7であり、右の子ノードが集約ノード3であり、Exchangeノードが存在しないことがわかります。これは、左右の子ノードからの集約データが元の場所に残っており、データ移動の必要がなく、後続のHash Join操作を直接ローカルで実行できることを示しています。
+------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| c2[#20] |
| c1[#21] |
| c2[#22] |
| c1[#23] |
| PARTITION: HASH_PARTITIONED: c2[#10] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 8:VHASH JOIN(373) |
| | join op: INNER JOIN(PARTITIONED)[] |
| | equal join conjunct: (c2[#14] = c2[#6]) |
| | cardinality=10 |
| | vec output tuple id: 9 |
| | output tuple id: 9 |
| | vIntermediate tuple ids: 8 |
| | hash output slot ids: 6 7 14 15 |
| | final projections: c2[#16], c1[#17], c2[#18], c1[#19] |
| | final project output tuple id: 9 |
| | distribute expr lists: c2[#14] |
| | distribute expr lists: c2[#6] |
| | |
| |----3:VAGGREGATE (merge finalize)(367) |
| | | output: sum(partial_sum(c1)[#3])[#5] |
| | | group by: c2[#2] |
| | | sortByGroupKey:false |
| | | cardinality=5 |
| | | final projections: c2[#4], c1[#5] |
| | | final project output tuple id: 3 |
| | | distribute expr lists: c2[#2] |
| | | |
| | 2:VEXCHANGE |
| | offset: 0 |
| | distribute expr lists: |
| | |
| 7:VAGGREGATE (merge finalize)(354) |
| | output: sum(partial_sum(c1)[#11])[#13] |
| | group by: c2[#10] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | final projections: c2[#12], c1[#13] |
| | final project output tuple id: 7 |
| | distribute expr lists: c2[#10] |
| | |
| 6:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: c1[#8] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 06 |
| HASH_PARTITIONED: c2[#10] |
| |
| 5:VAGGREGATE (update serialize)(348) |
| | STREAMING |
| | output: partial_sum(c1[#8])[#11] |
| | group by: c2[#9] |
| | sortByGroupKey:false |
| | cardinality=10 |
| | distribute expr lists: c1[#8] |
| | |
| 4:VOlapScanNode(345) |
| TABLE: tt.t1(t1), PREAGGREGATION: ON |
| partitions=1/1 (t1) |
| tablets=1/1, tabletList=491188 |
| cardinality=21, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: c1[#0] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: c2[#2] |
| |
| 1:VAGGREGATE (update serialize)(361) |
| | STREAMING |
| | output: partial_sum(c1[#0])[#3] |
| | group by: c2[#1] |
| | sortByGroupKey:false |
| | cardinality=5 |
| | distribute expr lists: c1[#0] |
| | |
| 0:VOlapScanNode(358) |
| TABLE: tt.t2(t2), PREAGGREGATION: ON |
| partitions=1/1 (t2) |
| tablets=1/1, tabletList=491198 |
| cardinality=10, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| Statistics |
| planed with unknown column statistics |
+------------------------------------------------------------+
105 rows in set (0.06 sec)
4つのshuffleメソッドの比較
| Shuffle Methods | Network Overhead | Physical Operator | Applicable Scenarios |
|---|---|---|---|
| Broadcast | N * T(R) | Hash Join /Nest Loop Join | 一般的 |
| Shuffle | T(S) + T(R) | Hash Join | 一般的 |
| Bucket Shuffle | T(R) | Hash Join | JOIN条件に左テーブルのbucketed columnが含まれ、左テーブルが単一パーティションである場合。 |
| Colocate | 0 | Hash Join | JOIN条件に左テーブルのbucketed columnが含まれ、両テーブルが同じColocate Groupに属している場合。 |
N: Join計算に参加するインスタンス数
T(Relation): リレーション内のタプル数
4つのShuffleメソッドの柔軟性は順番に低下し、データ分散への要件はますます厳しくなります。ほとんどの場合、データ分散への要件が高くなるにつれて、Join計算のパフォーマンスは徐々に向上する傾向があります。重要な点として、テーブル内のbucket数が少ない場合、Bucket ShuffleやColocate Joinは並列性の低下によりパフォーマンスが低下し、Shuffle Joinよりも遅くなる可能性があることに注意が必要です。これは、Shuffle操作がデータ分散をより効果的にバランスさせることで、後続の処理でより高い並列性を提供できるためです。
FAQ
Bucket Shuffle JoinとColocate Joinは、適用時にデータ分散とJOIN条件に関して特定の制限があります。以下では、これらのJOINメソッドのそれぞれの具体的な制限について詳しく説明します。
Bucket Shuffle Joinの制限
2つの物理テーブルを直接スキャンしてBucket Shuffle Joinを実行する場合、以下の条件を満たす必要があります:
-
等価JOIN条件: Bucket Shuffle Joinは、hash計算によってデータ分散を決定するため、JOIN条件が等価に基づくシナリオにのみ適用されます。
-
等価条件でのbucketed columnの包含: 等価JOIN条件には、両テーブルのbucketed columnが含まれている必要があります。左テーブルのbucketed columnが等価JOIN条件として使用される場合、Bucket Shuffle Joinとして計画される可能性が高くなります。
-
テーブルタイプの制限: Bucket Shuffle JoinはDorisのネイティブOLAPテーブルにのみ適用されます。ODBC、MySQL、ESなどの外部テーブルが左テーブルとして使用される場合、Bucket Shuffle Joinは有効になりません。
-
単一パーティション要件: パーティション化されたテーブルでは、パーティション間でデータ分散が異なる可能性があるため、Bucket Shuffle Joinは左テーブルが単一パーティションの場合にのみ有効性が保証されます。したがって、SQLを実行する際は、可能な限り
WHERE条件を使用してパーティションpruning戦略を有効にすることが推奨されます。
Colocate Joinの制限
2つの物理テーブルを直接スキャンする場合、Colocate JoinはBucket Shuffle Joinと比較してより厳しい制限があります。Bucket Shuffle Joinのすべての条件を満たすことに加えて、以下の要件も満たす必要があります:
-
bucket columnのタイプと数が同じ: bucketed columnのタイプが一致するだけでなく、bucket数も同じである必要があり、データ分散の一貫性を確保する必要があります。
-
Colocation Groupの明示的な指定: Colocation Groupを明示的に指定する必要があります;同じColocation Group内のテーブルのみがColocate Joinに参加できます。
-
レプリカ修復またはバランシング中の不安定状態: レプリカ修復やバランシングなどの操作中、Colocation Groupは不安定状態になる可能性があります。この場合、Colocate Joinは通常のJoin操作に降格されます。