
リリース 3.0.0
Apache Doris 3.0のリリースをお知らせできることを嬉しく思います!
バージョン3.0以降、Apache Dorisはクラスターデプロイメント時にコンピュートとストレージが結合されたモードに加えて、コンピュートとストレージが分離されたモードをサポートします。コンピュートとストレージレイヤーを分離するクラウドネイティブアーキテクチャにより、ユーザーは複数のコンピュートクラスター間でクエリロードの物理的分離、および読み取りと書き込みロード間の分離を実現できます。さらに、ユーザーはオブジェクトストレージやHDFSなどの低コストな共有ストレージシステムを活用して、ストレージコストを大幅に削減できます。
バージョン3.0は、Apache Dorisが統合されたデータレイクとデータウェアハウスアーキテクチャに向けて進化する上でのマイルストーンです。このバージョンでは、データレイクへのデータの書き戻し機能を導入し、ユーザーがApache Doris内で複数のデータソースにわたってデータ分析、共有、処理、ストレージ操作を実行できるようになりました。非同期マテリアライズドビューなどの機能により、Apache Dorisは企業向けの統合データ処理エンジンとしての役割を果たし、ユーザーがレイク、ウェアハウス、データベース間でデータをより適切に管理できるよう支援します。また、Apache Doris 3.0ではTrino Connectorを導入しています。これにより、ユーザーはより多くのデータソースに迅速に接続または適応でき、Dorisのハイパフォーマンスコンピュートエンジンを活用してTrinoよりも高速なクエリ結果を提供できます。
バージョン3.0では、ETLバッチ処理シナリオのサポートも強化され、insert into select、delete、updateなどの操作に対する明示的なトランザクションサポートが追加されました。クエリ実行の可観測性も改善されました。
パフォーマンスの面では、バージョン3.0でクエリオプティマイザーのフレームワーク機能、インフラストラクチャ、ルールを改善しました。これにより、より複雑で多様なビジネスシナリオでのブラインドテストで実証された最適化されたパフォーマンスを提供します。
適応的なRuntime Filter計算方式により、実行時にデータサイズに基づいてフィルターを正確に推定し、大量データと高負荷下でより良いパフォーマンスを提供します。さらに、非同期マテリアライズドビューは、クエリ高速化とデータモデリングにおいてより安定性があり、ユーザーフレンドリーになりました。
バージョン3.0の開発期間中、200人を超えるコントリビューターがApache Dorisに対してほぼ5,000の最適化と修正を提出しました。VeloDB、Baidu、Meituan、ByteDance、Tencent、Alibaba、Kwai、Huawei、Tianyi Cloudなどの企業のコントリビューターがコミュニティと積極的に協力し、実世界のユースケースからのテストケースを提供してApache Dorisの改善を支援しました。このリリースの開発、テスト、フィードバックプロセスに関わったすべてのコントリビューターに心からの感謝を表します。
1. コンピュート・ストレージ分離モード
V3.0以降、Apache Dorisはコンピュート・ストレージ分離モードをサポートします。ユーザーはクラスターデプロイメント時にこのモードとコンピュート・ストレージ結合モードから選択できます。
コンピュート・ストレージ分離モードでは、BEノードはもはやデータを保存せず、代わりに共有ストレージレイヤー(HDFSおよびオブジェクトストレージ)が共有データストレージレイヤーとして導入されます。コンピューティングリソースとストレージリソースは独立してスケールでき、ユーザーに複数のメリットをもたらします:
-
ワークロード分離: 複数のコンピュートクラスターが同じデータを共有でき、ユーザーは別々のコンピュートクラスターを使用して異なるビジネスワークロードやオフラインロードを分離できます。
-
ストレージコストの削減: 全データセットはよりコスト効率的で高い信頼性を持つ共有ストレージに保存され、ホットデータのみがローカルにキャッシュされます。3つのデータレプリカを持つコンピュート・ストレージ結合モードと比較して、ストレージコストを最大90%削減できます。
-
弾力的なコンピューティングリソース: BEノードにデータが保存されないため、コンピューティングリソースは負荷要件に基づいて柔軟にスケールできます。ユーザーは個別のコンピュートクラスターをスケールインまたはスケールアウトしたり、コンピュートクラスターの数を増減できます。これもコスト削減につながります。
-
システム堅牢性の向上: データを共有ストレージに保存することで、Dorisはマルチレプリカ整合性の複雑なロジックを処理する必要がなくなり、分散ストレージの複雑さが簡素化され、システム全体の堅牢性が向上します。
-
柔軟なデータ共有とクローニング: コンピュート・ストレージ分離モードの柔軟性は、単一のDorisクラスターを超えて拡張されます。1つのDorisクラスターのテーブルを別のDorisクラスターに簡単にクローンでき、メタデータのレプリケーションのみで済みます。
1-1. 結合から分離へ
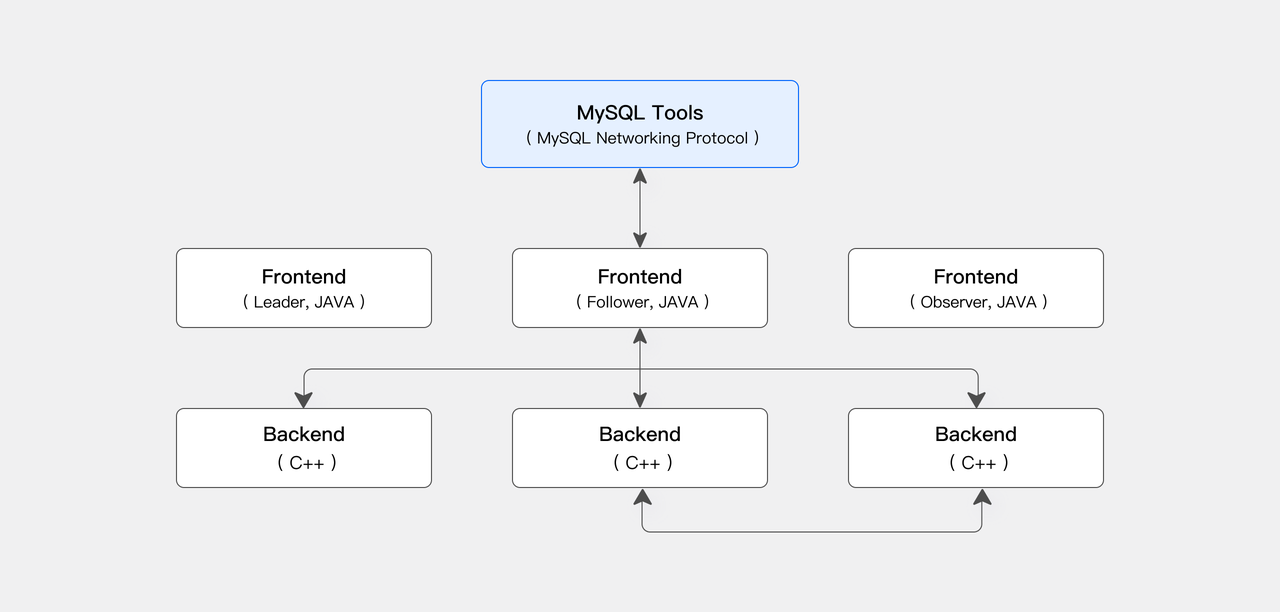
コンピュート・ストレージ結合モードでは、Apache Dorisアーキテクチャは2つの主要なプロセスタイプで構成されます:Frontend(FE)とBackend(BE)です。FEは主にユーザーリクエストアクセス、クエリ解析と計画、メタデータ管理、ノード管理を担当します。BEはデータストレージとクエリ計画の実行を担当します。
BEノードはMPP(Massively Parallel Processing)分散コンピューティングアーキテクチャを採用し、マルチレプリカ整合性プロトコルを活用して高いサービス可用性と高いデータ信頼性を確保します。
パブリッククラウド、プライベートクラウド、Kubernetesベースのコンテナプラットフォームを含む新興クラウドコンピューティングインフラストラクチャの成熟により、クラウドネイティブ機能の必要性が高まっています。ますます多くのユーザーが、より多くの弾力性を提供するために、Apache Dorisとクラウドコンピューティングインフラストラクチャの深い統合を求めています。
このニーズに対応するため、VeloDBチームはコンピューティングとストレージを分離するApache Dorisのクラウドネイティブバージョンを設計・実装し、VeloDB Cloudとして知られています。長期間にわたる数百の企業での広範囲な本番テストと改良を経て、このクラウドネイティブソリューションはApache Dorisコミュニティに貢献され、コンピュート・ストレージ分離モードのApache Doris 3.0として現れています。
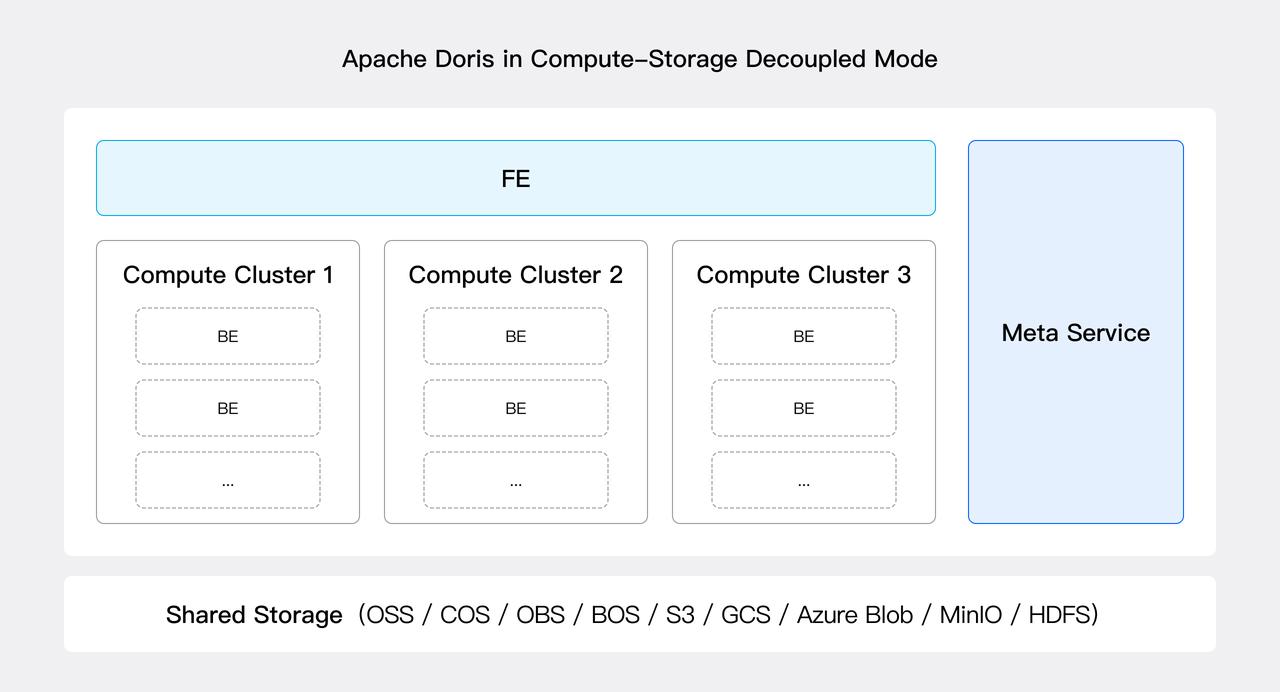
コンピュート・ストレージ分離モードでは、Apache Dorisアーキテクチャは3つのレイヤーで構成されます:
- メタデータレイヤー: 新しいMeta Serviceモジュールが導入され、データベースとテーブル情報、スキーマ、rowsetメタデータ、トランザクションなどのメタデータサービスを提供します。Meta Serviceはステートレスで水平スケール可能です。V3.0では、BEのすべてのメタデータとFEのメタデータの一部がMeta Serviceに移行されました。残りの移行は将来のバージョンで完了予定です。
- コンピュテーションレイヤー: ステートレスなBEノードがクエリプランを実行し、クエリパフォーマンス向上のためにデータとtabletメタデータの一部をローカルにキャッシュします。複数のステートレスBEノードをコンピューティングリソースプール(すなわち、コンピュートクラスター)に組織でき、複数のコンピュートクラスターが同じデータとメタデータサービスを共有できます。コンピュートクラスターは必要に応じてノードを追加または削除することで弾力的にスケールできます。
- 共有ストレージレイヤー: データは共有ストレージレイヤーに永続化され、現在HDFSおよびS3プロトコルと互換性のある様々なクラウドベースオブジェクトストレージシステム(S3、OSS、GCS、Azure Blob、COS、BOS、MinIOなど)をサポートします。
1-2 設計ハイライト
Apache Dorisのコンピュート・ストレージ分離モードの設計は、FEのインメモリメタデータモデルを共有メタデータサービスに変換することをハイライトしています。このアプローチは、グローバル一貫性状態ビューを提供し、任意のノードが公開のためにFEを経由することなく直接書き込みを送信できるようにします。書き込み操作中、データは共有ストレージに保存され、メタデータはメタデータサービスによって管理されます。これにより、共有ストレージ内の小ファイル数を効果的に制御できます。同時に、個々のテーブルの実時間書き込みパフォーマンスは、コンピュート・ストレージ結合モードとほぼ同等です。システムの全体的な書き込み容量は、もはや単一のFEノードの処理能力によって制限されません。
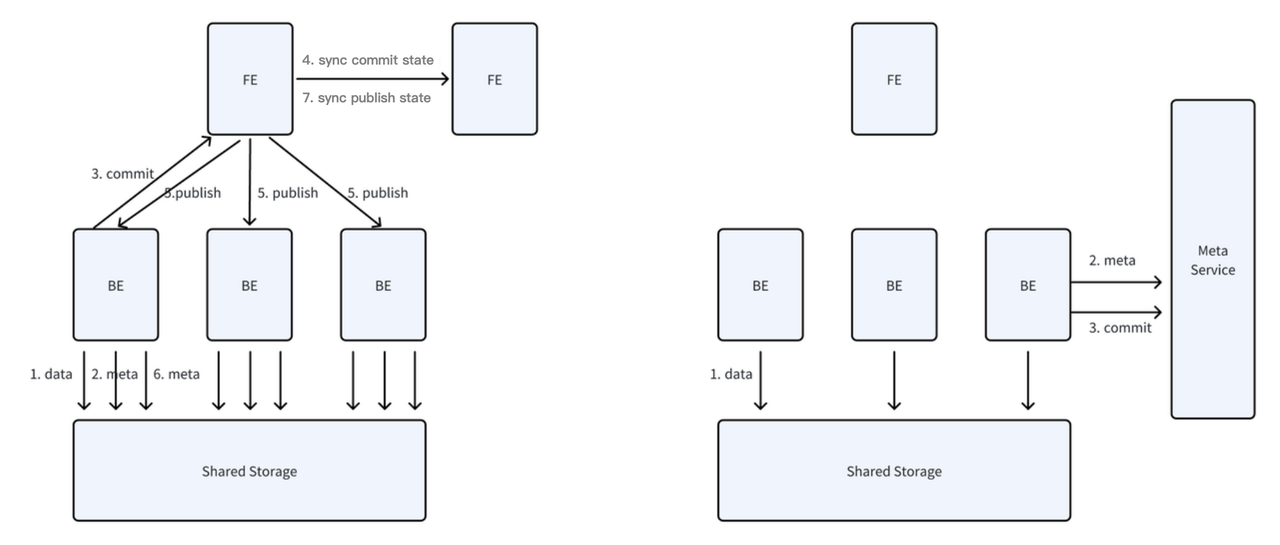
グローバル一貫性状態ビューに基づいて、データガベージコレクションについては、より正確性を証明しやすく、より効率的なデータ削除の設計アプローチを採用しました。
具体的には、共有ストレージ内のデータは、共有メタデータサービスが提供するグローバル一貫性ビューに組み込まれます。データが生成されるたびに、それを別個の独立したトランザクションにバインドします。同様に、メタデータ削除操作についても、それを別個の独立したトランザクションにバインドします。このアプローチの目的は、削除と書き込み操作が一緒に成功できないことを保証することです。ビューは削除が必要なデータを記録し、非同期削除プロセスは、逆ガベージコレクションを必要とせずに、トランザクション記録に基づいてデータの前方削除を簡単に実行できます。
FE内のtablet関連メタデータが徐々に共有メタデータサービスに移行されるにつれて、Dorisクラスターのスケーラビリティは、もはや単一のFEノードのメモリ容量によって制約されることはありません。共有メタデータサービスと前方データ削除技術に基づいて、データ共有と軽量クローニングなどの機能を便利に拡張できます。
1-3 代替ソリューションとの比較
業界におけるコンピューティングとストレージの分離の別の設計は、データとBEノードメタデータを共有オブジェクトストレージまたはHDFSに保存することです。しかし、このアプローチは以下の問題をもたらします:
-
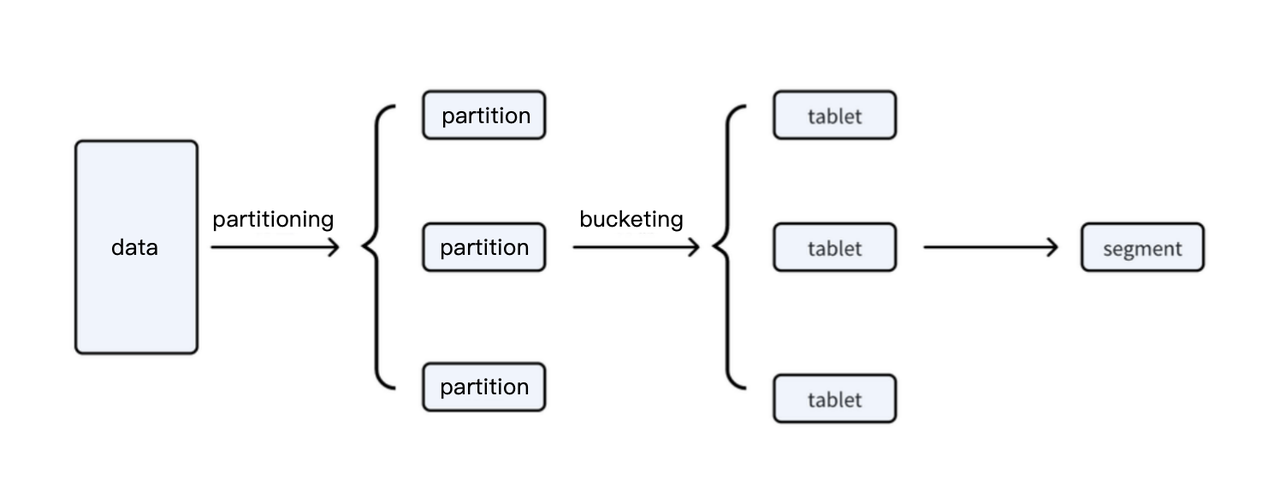
実時間書き込みをサポートできない: データ書き込み中、データはパーティショニングとバケティングルールに基づいてtabletにマップされ、segmentファイルとrowsetメタデータを生成します。書き込みプロセス中に、FEを通じて2フェーズコミット(Publish)が実行されます。BEノードがPublishリクエストを受信すると、rowsetを可視に設定します。Publish操作は失敗してはいけません。rowsetメタデータが共有ストレージに保存されている場合、実時間書き込みプロセス中の小ファイルデータの総量は実際のデータファイルのサイズの3倍になります - データファイルの1つのレプリカ、rowsetメタデータの1つ、Publish中のrowsetメタデータ変更のもう1つ。Publish操作は単一のFEノードによって駆動されるため、単一テーブルまたはシステム全体の書き込み容量はFEノードの能力によって制限されます。
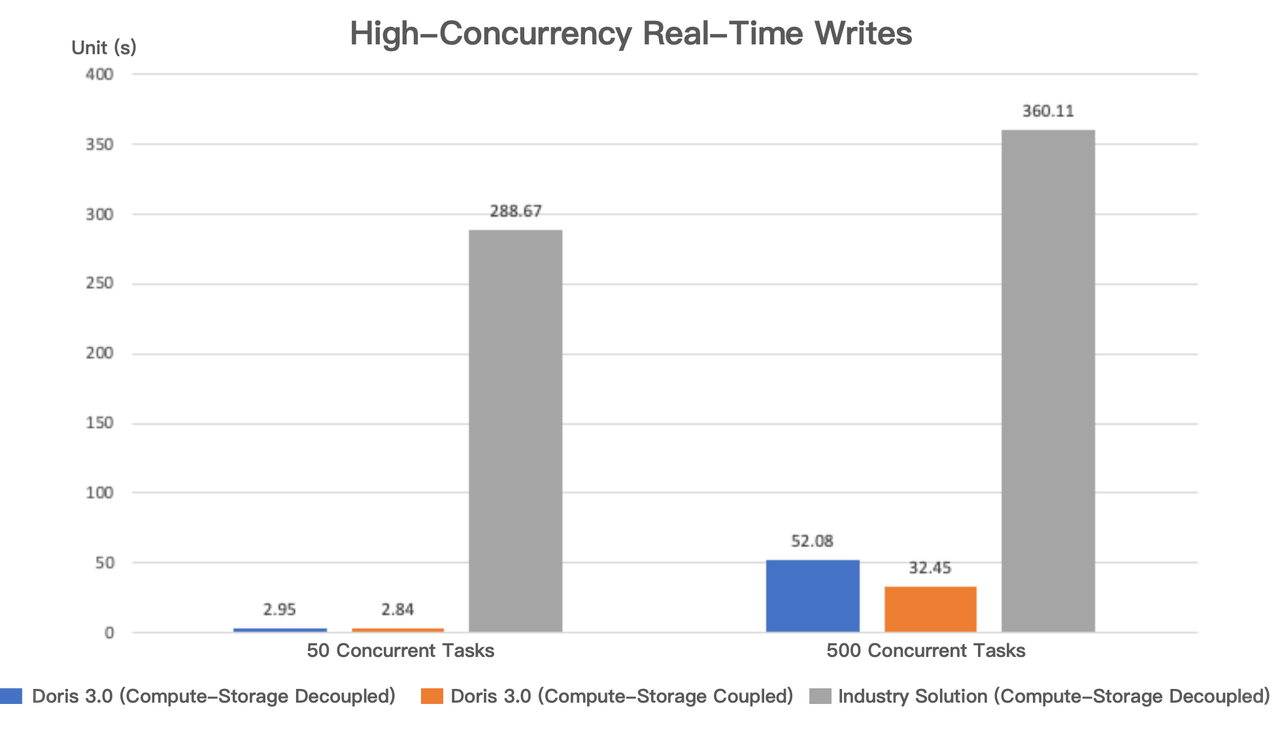
私たちはApache Doris 3.0の実時間データ書き込みパフォーマンスを上記のソリューションと比較しました。同じコンピューティングリソースを使用して、500行ずつの10,000データファイルを書き込む500の同時タスクと、20,000行ずつの250データファイルを書き込む50の同時タスクをシミュレートしました。
結果は、50同時タスクにおいて、Apache Dorisのコンピュート・ストレージ結合モードと分離モード両方のマイクロバッチ書き込みパフォーマンスがほぼ同じであった一方、業界ソリューションはApache Dorisに100倍遅れていることを示しました。
500同時タスクでは、Apache Dorisのコンピュート・ストレージ分離モードのパフォーマンスはわずかな劣化を示しましたが、業界ソリューションに対して11倍の優位性を維持しました。公平なテストを確保するため、Apache DorisはGroup Commit機能を有効にしませんでした(業界ソリューションには欠如)。Group Commitを有効にすることで、実時間書き込みパフォーマンスはさらに向上します。
さらに、業界ソリューションは実時間データ取り込みの観点から安定性とコストの問題にも直面します:
-
安定性の懸念: 大量の小ファイルは共有ストレージ、特にHDFSに圧力をかけ、安定性リスクを導入する可能性があります。
-
高いオブジェクトストレージリクエストコスト: 一部のパブリッククラウドオブジェクトストレージサービスは、Get操作と比較してPutとDelete操作に10倍高い料金を請求します。大量の小ファイルは、オブジェクトストレージリクエストコストの大幅な増加につながり、ストレージコストを上回る可能性があります。
-
-
限定的なスケーラビリティ: コンピュート・ストレージ分離モデルのユースケースは、Frontend(FE)メタデータが完全にインメモリであるため、しばしばより大きなデータストレージサイズを扱います。tabletの数が特定の高レベル(例:数千万)に達すると、FEのメモリ圧力がシステムの全体的な書き込みスループットを制限するボトルネックになる可能性があります。
-
潜在的なデータ削除ロジックの問題: コンピュート・ストレージ分離アーキテクチャでは、データは単一レプリカで保存されます。したがって、データ削除ロジックはシステムの信頼性にとって重要です。差分を比較することによるクロスシステムデータ削除の従来のアプローチは困難な場合があります。書き込みプロセス中に、削除と書き込みが一緒に成功することを完全に回避する方法はなく、これがデータ損失につながる可能性があります。さらに、ストレージシステムに異常が発生した場合、差分計算に使用される入力が間違っている可能性があり、意図しないデータ削除につながる可能性があります。
-
データ共有と軽量クローニング: 分離ストレージ・コンピュートアーキテクチャの柔軟性により、将来のデータ共有と軽量データクローニングが可能になり、企業データ管理の負担を軽減できます。しかし、各クラスターが別々のFEを持つ場合、クラスター間でデータをクローニングした後、どのデータがもはや参照されずに安全に削除できるかを正確に判断することが困難になります。クラスター間参照の計算は簡単に意図しないデータ削除につながる可能性があるためです。
FEの完全なインメモリメタデータモデルを共有メタデータサービスに進化させることで、Apache Doris 3.0は前述のすべての問題を回避します。
1-4 クエリパフォーマンス比較
コンピュート・ストレージ分離モードでは、データはリモート共有ストレージシステムから読み取る必要があり、主なボトルネックはコンピュート・ストレージ結合モードのディスクI/Oではなく、ネットワーク帯域幅になりました。
データアクセスを高速化するため、Apache Dorisはローカルディスクに基づく高速キャッシュメカニズムを実装し、LRU(Least Recently Used)とTTL(Time-To-Live)の2つのキャッシュ管理ポリシーを提供します。新たに取り込まれたデータは、最新データへの初回アクセスを高速化するため、非同期でキャッシュに書き込まれます。クエリに必要なデータがキャッシュにない場合、システムはリモートストレージからメモリにデータを読み込み、後続のクエリのためにキャッシュに同期的に書き込みます。
複数のコンピュートクラスターを含むユースケースでは、Apache Dorisはキャッシュプリヒート機能を提供します。新しいコンピュートクラスターが確立された場合、ユーザーは特定のデータ(テーブルやパーティションなど)をプリヒートしてクエリ効率をさらに向上させることができます。
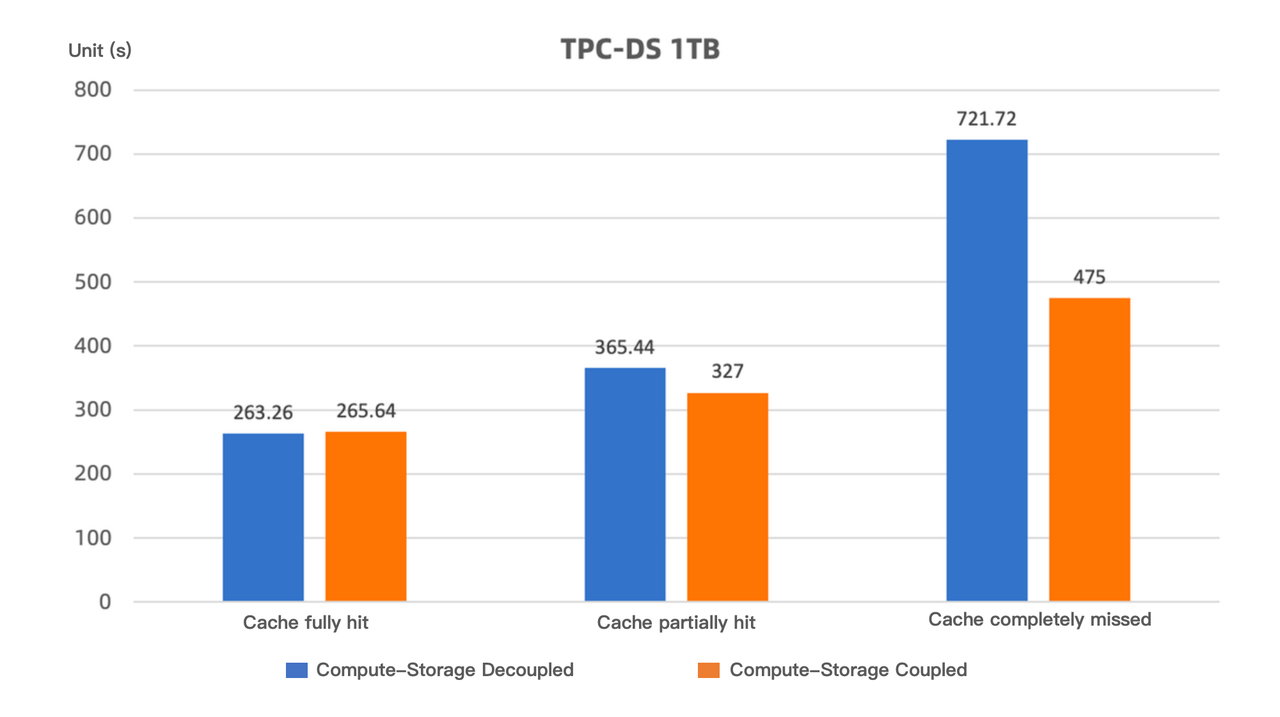
この文脈で、TPC-DS 1TBテストデータセットを使用して、コンピュート・ストレージ結合モードと分離モードの両方で異なるキャッシュ戦略でパフォーマンステストを実施しました。結果は以下のとおりです:
-
キャッシュが完全にヒットした場合(すなわち、クエリに必要なすべてのデータがキャッシュにロードされている場合)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードと同等です。
-
キャッシュが部分的にヒットした場合(すなわち、テスト前にキャッシュがクリアされ、テスト中にデータが段階的にキャッシュにロードされ、パフォーマンスが継続的に向上する場合)、コンピュート・ストレージ分離モードのクエリパフォーマンスはコンピュート・ストレージ結合モードより約10%低くなります。このテストシナリオは実際のユースケースに最も近いものです。
-
キャッシュが完全に失敗した場合(すなわち、すべてのSQL実行前にキャッシュがクリアされ、極端なケースをシミュレート)、パフォーマンス損失は約35%です。それでも、コンピュート・ストレージ分離モードのApache Dorisは、代替ソリューションよりもはるかに高いパフォーマンスを提供します。
1-5 書き込み速度比較
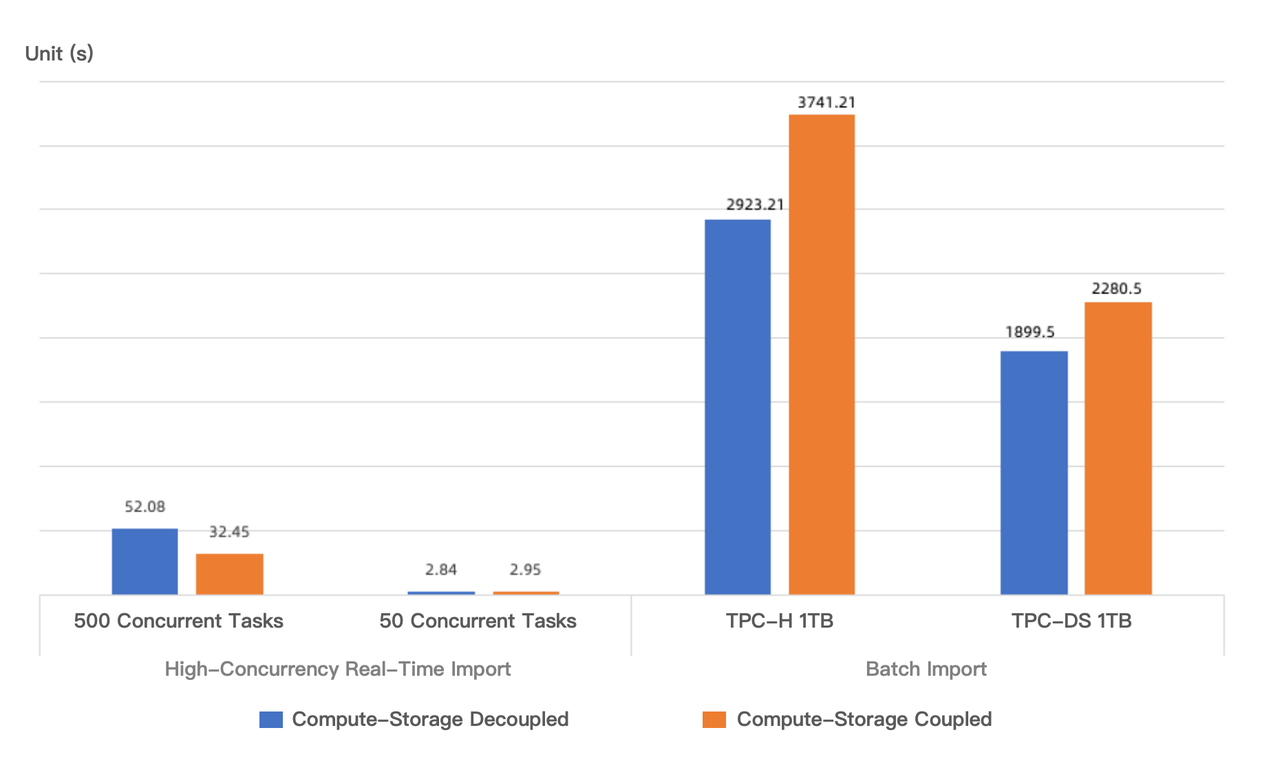
書き込みパフォーマンスについては、同じコンピューティングリソースの下で2つのテストケースをシミュレートしました:バッチインポートと高同時実時間インポートです。コンピュート・ストレージ結合モードと分離モードの書き込みパフォーマンス比較は以下のとおりです:
-
バッチインポート: 1TB TPC-Hと1TB TPC-DSテストデータセットをインポートする場合、コンピュート・ストレージ分離モードの書き込みパフォーマンスは、単一レプリカ設定下でコンピュート・ストレージ結合モードよりもそれぞれ20.05%と27.98%高くなります。バッチインポート中、segmentファイルサイズは一般的に数十から数百MBの範囲にあります。コンピュート・ストレージ分離モードでは、segmentファイルはより小さなファイルに分割され、オブジェクトストレージに同時にアップロードされ、ローカルディスクへの書き込みと比較してより高いスループットを実現できます。実際のデプロイメントでは、コンピュート・ストレージ結合モードは通常3つのレプリカを使用するため、コンピュート・ストレージ分離モードの書き込み速度の優位性はさらに顕著になります。
-
高同時実時間インポート: 「代替ソリューションとの比較」セクションで説明したとおりです。
1-6 本番環境のヒント
-
パフォーマンス: 実時間データ分析について、ユーザーはキャッシュにTTL(Time-To-Live)を指定し、新たに取り込まれたデータをキャッシュに書き込むことで、コンピュート・ストレージ結合モードに匹敵するクエリパフォーマンスを実現できます。クエリジッターを防ぐため、ユーザーはデータの使用頻度に基づいて、compactionやスキーマ変更などのバックグラウンドタスクによって生成されたデータをキャッシュできます。
-
ワークロード分離: ユーザーは複数のコンピュートクラスターを使用して異なるビジネスの物理リソース分離を実現できます。単一のコンピュートクラスター内でのワークロード分離については、ユーザーはWorkload Groupメカニズムを利用して異なるクエリのリソースを制限し分離できます。
1-7 注意事項
-
Apache Doris 3.0は、コンピュート・ストレージ結合モードとコンピュート・ストレージ分離モードの共存をサポートしていません。ユーザーはクラスターデプロイメント時にそのいずれかを指定する必要があります。
-
ユーザーがコンピュート・ストレージ結合モードが必要な場合は、デプロイメントとアップグレードについてdocumentationに従ってください。迅速なデプロイメントとクラスターアップグレードにはDoris Managerの使用を推奨します。しかし、コンピュート・ストレージ分離モードはまだDoris Managerデプロイメントとアップグレードをサポートしていません。将来のバージョンでより良いサポートのために継続的に反復していきます。
-
現在、Apache DorisはV2.1からV3.0のコンピュート・ストレージ分離モードへのインプレースアップグレードをサポートしていません。この目的のために、ユーザーはコンピュート・ストレージ分離クラスターをデプロイした後、ツールを使用してデータ移行を実行する必要があります。将来は、CCR(Change Data Capture)機能を通じてサービス中断なしの移行をサポートする予定です。
2. データレイクハウス
Apache Dorisは実時間データウェアハウスとして位置づけられていますが、それ以上の存在です。以前のバージョンでは、従来のデータウェアハウス機能の境界を一貫して押し広げ、統合データレイクハウスに向けて前進してきました。バージョン3.0は、レイクハウスアーキテクチャの機能が完全に成熟したこの旅程におけるマイルストーンです。私たちは、統合レイクハウスは境界なきデータとレイクハウス融合によって識別されると考えています:
境界なきデータ: Apache Dorisは統合クエリ処理エンジンとして機能し、異なるシステム間のデータ障壁を打破します。データウェアハウス、データレイク、データストリーム、ローカルデータファイルを含むすべてのデータソースで一貫した超高速分析エクスペリエンスを提供します。
-
レイクハウスクエリ高速化: データをApache Dorisに移行することなく、ユーザーはDorisの効率的なクエリエンジンを活用して、Iceberg、Hudi、Paimon、Hiveなどのオフラインデータウェアハウスなどのデータレイクに保存されたデータを直接クエリし、クエリ分析を高速化できます。
-
フェデレーテッド分析: catalogとストレージプラグインを拡張することで、Apache Dorisはフェデレーテッド分析機能を強化し、データを単一のストレージシステムに物理的に集中化することなく、複数の異種データソース間で統合分析を実行できるようにします。これにより、外部テーブルクエリと内部・外部テーブル間のフェデレーテッド結合が可能になり、データサイロを打破し、グローバル一貫
BEGIN;
DELETE FROM table WHERE date >= "2024-07-01" AND date <= "2024-07-31";
INSERT INTO table SELECT * FROM stage_table;
COMMIT; -
失敗したタスクの処理を簡素化: たとえば、単一のトランザクション内で2つの
insert into select操作が実行される場合、いずれかの操作が失敗しても、直接再試行できます。BEGIN WITH LABEL label_etl_1;
INTO table1 SELECT * FROM stage_table1;
INSERT INTO table SELECT * FROM stage_table;
COMMIT;
doc参照: https://doris.apache.org/docs/3.0/data-operate/transaction/ 現在、Cross-Cluster Replication(CCR)では明示的なトランザクション同期はサポートされていません。
4-2. 可観測性の向上
-
リアルタイムprofile取得: 以前のバージョンでは、実行プランやデータの問題により、複雑なクエリの一部は高い計算要件を持つ可能性があり、開発者はクエリの完了後にのみパフォーマンス分析用のクエリprofileにアクセスできました。これにより、本番環境の安定性を保証するためのクエリ実行での問題の迅速な特定が困難でした。現在、リアルタイムprofile取得機能により、V3.0ではユーザーがクエリ実行中にクエリ実行を監視できます。また、各ETLジョブの進行状況をより適切に監視できます。
-
backend_active_tasksシステムテーブル:backend_active_tasksシステムテーブルは、各BEノード上の各クエリのリアルタイムリソース消費情報を提供します。ユーザーはSQLを使用してこのシステムテーブルを分析し、各クエリのリソース使用量を取得できるため、大きなクエリや異常なワークロードの特定に役立ちます。
5. 非同期マテリアライズドビュー
V3.0では、非同期マテリアライズドビューはより高速で安定しています。また、クエリアクセラレーションやデータモデリングシナリオでよりユーザーフレンドリーです。透過的リライトのロジックを再構築し、その機能を拡張することで、2倍高速になりました。
5-1 更新
-
パーティション単位でのマテリアライズドビューの増分更新と、異なる粒度での更新を可能にするマテリアライズドビューでのパーティションロールアップのサポート。
-
データモデリングシナリオで有用な、ネストされたマテリアライズドビューのサポート。
-
非同期マテリアライズドビューでのインデックス作成とソートキー指定のサポート。これにより、マテリアライズドビューがヒットした後のクエリパフォーマンスが向上します。
-
マテリアライズドビューの原子的置換をサポートするマテリアライズドビューDDLの使いやすさの向上により、マテリアライズドビューを利用可能な状態に保ちながらマテリアライズドビュー定義SQLの変更が可能。
-
日常的なマテリアライズドビュー作成により適したマテリアライズドビューでの非決定論的関数のサポート。
-
ネストされたマテリアライズドビューを使用したデータモデリングでのデータ整合性を保証するトリガーベースのマテリアライズドビュー更新のサポート。
-
パーティション化マテリアライズドビュー構築のためのより幅広いSQLパターンのサポートにより、増分更新機能をより多くのユースケースで利用可能。
5-2 更新の安定性
- V3.0では、マテリアライズドビュー構築のためのWorkload Groupの指定をサポート。これは、マテリアライズドビュー構築プロセスで使用されるリソースを制限し、進行中のクエリに対して十分なリソースを確実に利用可能にするためです。
5-3 透過的リライト
-
派生Joinを含む、より多くのJoinタイプの透過的リライトのサポート。クエリとマテリアライズドビューの間でJoinタイプが一致しない場合でも、マテリアライズドビューがクエリに必要なすべてのデータを提供できる限り、追加の述語で補完することで透過的リライトを実行できます。
-
ロールアップ用のより多くの集約関数とGROUPING SETS、ROLLUP、CUBEなどの多次元集約のリライトのサポート;マテリアライズドビューが集約を含まない場合の集約を持つクエリのリライトをサポートし、Join操作と式計算を簡素化。
-
ネストされたマテリアライズドビューの透過的リライトのサポートにより、複雑なクエリのより高いパフォーマンスを実現。
-
部分的に無効なパーティション化マテリアライズドビューに対して、V3.0はデータ補完のためのベーステーブルの
Union Allをサポートし、パーティション化マテリアライズドビューの適用可能性を拡張。
5-4 透過的リライトのパフォーマンス
- 透過的リライトのパフォーマンスを向上させるための継続的な最適化が行われ、バージョン2.1.0と比較して2倍の速度を実現。
6. パフォーマンス向上
6-1 よりスマートなオプティマイザー
V3.0では、クエリオプティマイザーがフレームワーク機能、分散プランサポート、オプティマイザーインフラストラクチャ、ルール拡張の面で強化されました。より複雑で多様なビジネスシナリオに対してより良い最適化機能を提供し、複雑なSQLに対してより高いブラインドテストパフォーマンスを実現:
-
プラン列挙機能の向上: プラン列挙の主要構造であるMemoが再構築され正規化されました。これにより、プラン列挙でのCascadesフレームワークの効率性と、より良いプランを生成する可能性が向上しました。さらに、以前のバージョンでJoin Reorderプロセス中の不完全な列プルーニングを修正し、これがJoin演算子の不要なオーバーヘッドを引き起こしていたため、関連シナリオでの実行パフォーマンスが向上しました。
-
分散プランサポートの向上: 分散クエリプランが強化され、集約、結合、ウィンドウ関数操作が中間計算結果のデータ特性をより知的に識別し、非効率的なデータ再配布操作を回避できるようになりました。同時に、マルチレプリカ連続実行モードでの実行を最適化し、データキャッシュにより適したものにしました。
-
オプティマイザーインフラストラクチャの向上: V3では、コストモデルと統計情報推定でのいくつかの問題を修正しました。コストモデルの修正により、実行エンジンの進化により適応性があり、以前のバージョンと比較してより安定した実行プランを実現しました。
-
Runtime Filterプランサポートの強化: Join Runtime Filterをベースに、V3.0はTopN Runtime Filterの機能を拡張し、TopN演算子を含むユースケースでより良いパフォーマンスを実現しました。
-
最適化ルールライブラリの拡充: ユーザーフィードバックと内部テスト結果に基づき、Intersect Reorderなどの最適化ルールを導入し、オプティマイザーのルールセットを拡充しました。
6-2 自己適応Runtime Filter
以前のバージョンでは、Runtime Filterの生成は統計情報に基づくユーザーの手動設定に依存していました。しかし、特定のケースでの不正確な設定はパフォーマンスの不安定性を引き起こす可能性がありました。
V3.0では、Dorisは自己適応Runtime Filter計算アプローチを実装しています。データサイズに基づいて高い精度でランタイム時にRuntime Filterを推定でき、大きなデータボリュームと高いワークロードを持つユースケースでより良いパフォーマンスを実現します。
6-3 関数パフォーマンス最適化
- V3.0では数十の関数のベクトル化実装を改善し、一般的に使用される一部の関数で50%を超えるパフォーマンス向上を実現しました。
- V3.0ではnullableデータ型の集約に対しても大幅な最適化を行い、30%のパフォーマンス向上を実現しました。
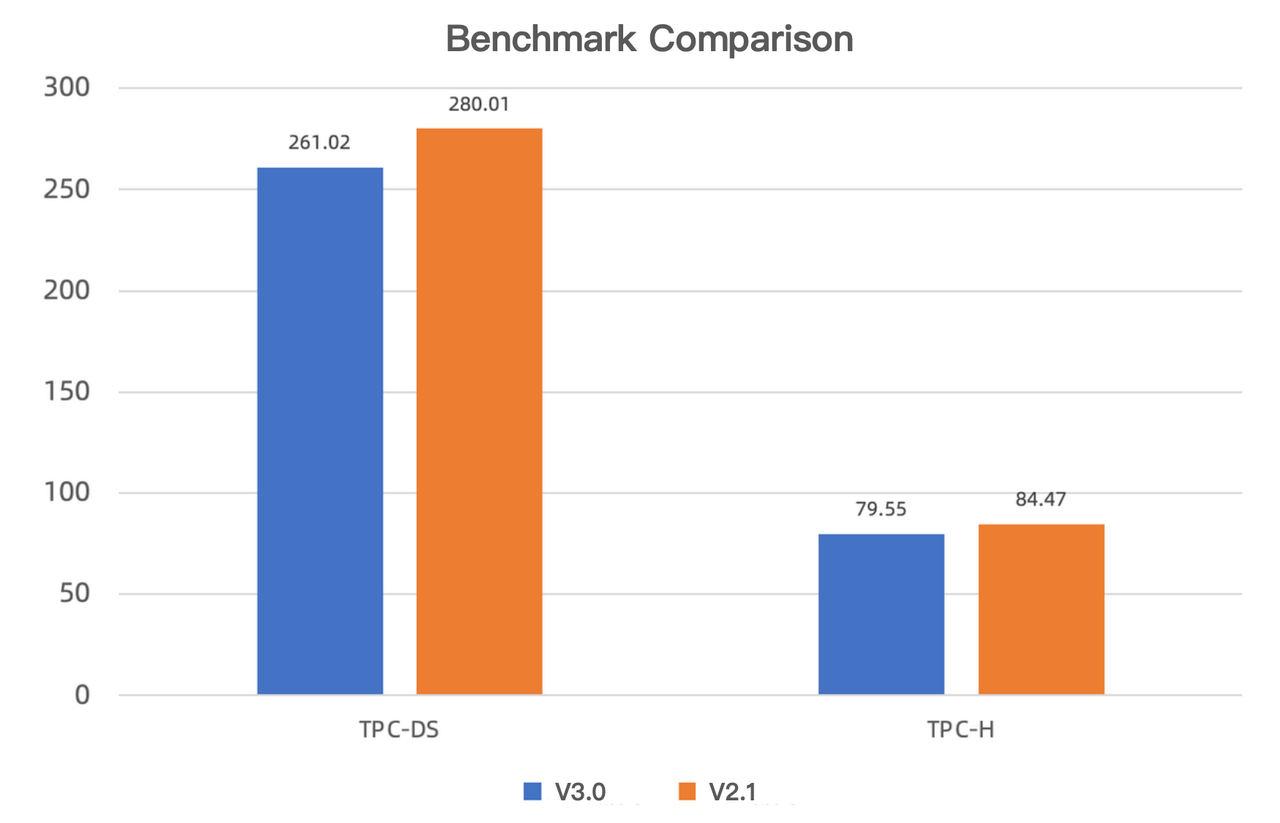
6-4 ブラインドテストパフォーマンス向上
V3.0とV2.1のブラインドテストでは、新しいバージョンがTPC-DSとTPC-Hベンチマークテストでそれぞれ7.3%と6.2%高速であることが示されました。
7. 新機能
7-1 Java UDTF
バージョン3.0ではJava UDTFのサポートが追加されました。主要な操作は以下の通りです:
-
UDTFの実装: UDFと同様に、UDTFではユーザーが
evaluateメソッドを実装する必要があります。UDTF関数の戻り値はArrayデータ型である必要があることに注意してください。public class UDTFStringTest {
public ArrayList<String> evaluate(String value, String separator) {
if (value == null || separator == null) {
return null;
} else {
return new ArrayList<>(Arrays.asList(value.split(separator)));
}
}
} -
UDTFの作成: デフォルトでは、対応する2つの関数が作成されます -
java-utdfとjava-utdf_outerです。_outerサフィックスは、テーブル関数が0行の出力を生成する際に、NULLデータの単一行を追加します。CREATE TABLES FUNCTION java-utdf(string, string) RETURNS array<string> PROPERTIES (
"file"="file:///pathTo/java-udaf.jar",
"symbol"="org.apache.doris.udf.demo.UDTFStringTest",
"always_nullable"="true",
"type"="JAVA_UDF"
);
7-2 Generated column
Generated columnは、ユーザーが直接挿入または更新するのではなく、他の列の値から計算される特別な列です。式の結果を事前に計算してデータベースに保存することをサポートしており、頻繁なクエリや複雑な計算が必要なシナリオに適しています。
データがインポートまたは更新される際に、事前定義された式に基づいて結果が自動的に計算され、永続的に保存されます。これにより、後続のクエリ時にシステムは複雑な計算を実行することなく、これらの計算結果に直接アクセスできるため、クエリパフォーマンスが向上します。
Generated columnはV3.0からサポートされています。テーブル作成時に列をgenerated columnとして指定できます。Generated columnは、データが書き込まれる際に定義された式に基づいて値を自動的に計算します。Generated columnではより複雑な式を定義できますが、値を明示的に書き込みまたは設定することはできません。
8. 機能改善
8-1. Materialized view
Materialized viewの選択ロジックをリファクタリングし、ルールベースオプティマイザー(RBO)からコストベースオプティマイザー(CBO)に移行しました。これにより選択ロジックが非同期materialized viewのものと一致します。この機能はデフォルトで有効です。問題が発生した場合は、set global enable_sync_mv_cost_based_rewrite = falseを使用してRBOモードに戻すことができます。
8-2. Routine Load
以前のバージョンでは、Routine Load機能にはBEノード間でのタスクスケジューリングの不均衡、タスクスケジューリングの遅延、複雑な設定要件(最適化のために複数のFEおよびBE設定を変更する必要)、全体的な安定性不足(再起動やアップグレードによりRoutine Loadジョブが頻繁に一時停止し、再開するために手動でのユーザー介入が必要)など、いくつかの使いやすさの課題がありました。
これらの問題に対処するため、Routine Load機能に対して広範囲な最適化を行いました:
-
リソーススケジューリング: スケジューリングバランスを改善し、タスクがBEノード間により均等に分散されるようにしました。修復不可能なエラーに遭遇したジョブは、無駄なスケジューリング試行でリソースを浪費することを避けるため、速やかに一時停止されます。さらに、スケジューリングプロセスの適時性を改善し、Routine Loadのインポートパフォーマンスが向上しました。
-
パラメーター設定: ほとんどの環境でユーザーは最適化のためにFEおよびBE設定を変更する必要がなくなりました。クラスターの負荷が増大した際にタスクが継続的に再試行することを防ぐため、タイムアウトパラメーターを含む自動調整メカニズムを導入しました。
-
安定性: FEフェイルオーバー、BEローリングアップグレード、Kafkaクラスター異常など、様々な例外的シナリオでのDorisの堅牢性を強化し、継続的で安定した動作を確保しました。また、Auto Resumeメカニズムを最適化し、障害が修復された後にRoutine Loadが自動的に動作を再開できるようになり、手動でのユーザー介入の必要性を減らしました。
9. 動作変更
-
cpu_resource_limitはサポートされなくなり、すべてのタイプのリソース分離はWorkload Groupsを通じて実装されます。 -
Apache Doris 3.0以降のバージョンではJDK 17を使用してください。推奨バージョンは
jdk-17.0.10_linux-x64_bin.tar.gzです。
Apache Doris 3.0を今すぐお試しください!
バージョン3.0の正式リリースまでに、Apache Dorisのcompute-storage decoupledモードは数百の企業の本番環境で約2年間にわたる広範囲なテストと最適化が行われました。多くの大手テック企業の貢献者がコミュニティと協力し、実際のビジネスニーズに基づく大量のテストケースを提供しました。これによりバージョン3.0の使いやすさと安定性が厳格に検証されました。
compute-storage decouplingニーズを持つユーザーには、バージョン3.0をダウンロードして直接体験することを強くお勧めします。
今後は、すべてのユーザーにより安定したバージョン体験を提供するため、リリース反復サイクルを加速していきます。ぜひApache Dorisコミュニティにご参加いただき、コア開発者と直接交流してください。
Credits
このバージョンの開発、テスト、フィードバック提供に参加いただいた以下の貢献者の皆様に特別な感謝を申し上げます:
@133tosakarin、@390008457、@924060929、@AcKing-Sam、@AshinGau、@BePPPower、@BiteTheDDDDt、@ByteYue、@CSTGluigi、@CalvinKirs、@Ceng23333、@DarvenDuan、@DongLiang-0、@Doris-Extras、@Dragonliu2018、@Emor-nj、@FreeOnePlus、@Gabriel39、@GoGoWen、@HappenLee、@HowardQin、@Hyman-zhao、@INNOCENT-BOY、@JNSimba、@JackDrogon、@Jibing-Li、@KassieZ、@Lchangliang、@LemonLiTree、@LiBinfeng-01、@LompleZ、@M1saka2003、@Mryange、@Nitin-Kashyap、@On-Work-Song、@SWJTU-ZhangLei、@StarryVerse、@TangSiyang2001、@Tech-Circle-48、@Thearas、@Vallishp、@WinkerDu、@XieJiann、@XuJianxu、@XuPengfei-1020、@Yukang-Lian、@Yulei-Yang、@Z-SWEI、@ZhongJinHacker、@adonis0147、@airborne12、@allenhooo、@amorynan、@bingquanzhao、@biohazard4321、@bobhan1、@caiconghui、@cambyzju、@caoliang-web、@catpineapple、@cjj2010、@csun5285、@dataroaring、@deardeng、@dongsilun、@dutyu、@echo-hhj、@eldenmoon、@elvestar、@englefly、@feelshana、@feifeifeimoon、@feiniaofeiafei、@felixwluo、@freemandealer、@gavinchou、@ghkang98、@gnehil、@hechao-ustc、@hello-stephen、@httpshirley、@hubgeter、@hust-hhb、@iszhangpch、@iwanttobepowerful、@ixzc、@jacktengg、@jackwener、@jeffreys-cat、@kaijchen、@kaka11chen、@kindred77、@koarz、@kobe6th、@kylinmac、@larshelge、@liaoxin01、@lide-reed、@liugddx、@liujiwen-up、@liutang123、@lsy3993、@luwei16、@luzhijing、@lxliyou001、@mongo360、@morningman、@morrySnow、@mrhhsg、@my-vegetable-has-exploded、@mymeiyi、@nanfeng1999、@nextdreamblue、@pingchunzhang、@platoneko、@py023、@qidaye、@qzsee、@raboof、@rohitrs1983、@rotkang、@ryanzryu、@seawinde、@shoothzj、@shuke987、@sjyango、@smallhibiscus、@sollhui、@sollhui、@spaces-X、@stalary、@starocean999、@superdiaodiao、@suxiaogang223、@taptao、@vhwzx、@vinlee19、@w41ter、@wangbo、@wangshuo128、@whutpencil、@wsjz、@wuwenchi、@wyxxxcat、@xiaokang、@xiedeyantu、@xiedeyantu、@xingyingone、@xinyiZzz、@xy720、@xzj7019、@yagagagaga、@yiguolei、@yongjinhou、@ytwp、@yuanyuan8983、@yujun777、@yuxuan-luo、@zclllyybb、@zddr、@zfr9527、@zgxme、@zhangbutao、@zhangstar333、@zhannngchen、@zhiqiang-hhhh、@ziyanTOP、@zxealous、@zy-kkk、@zzzxl1993、@zzzzzzzs