
監視とアラーム
この文書では主にDorisの監視項目と、それらを収集・表示する方法を紹介します。そしてアラームの設定方法について説明します(TODO)
Dashboardテンプレートをダウンロードするにはクリックしてください
| Doris Version | Dashboard Version |
|---|---|
| 1.2.x | revision 5 |
Dashboardテンプレートは随時更新されます。テンプレートの更新方法は最後のセクションに示されています。
より良いdashboardの提供を歓迎します。
コンポーネント
DorisはPrometheusとGrafanaを使用して入力監視項目を収集・表示します。
-
Prometheus
Prometheusはオープンソースのシステム監視・アラームスイートです。PullまたはPushによって監視項目を収集し、独自の時系列データベースに保存できます。そして豊富な多次元データクエリ言語を通じて、ユーザーの異なるデータ表示ニーズを満たします。
-
Grafana
Grafanaはオープンソースのデータ分析・表示プラットフォームです。Prometheusを含む複数の主流な時系列データベースソースをサポートします。対応するデータベースクエリステートメントを通じて、データソースから表示データを取得します。柔軟で設定可能なdashboardにより、これらのデータをグラフの形でユーザーに素早く提示できます。
注意:この文書は、PrometheusとGrafanaを使用してDoris監視データを収集・表示する方法のみを提供します。原則として、これらのコンポーネントは開発・保守されていません。これらのコンポーネントの詳細については、対応する公式文書をご参照ください。
監視データ
Dorisの監視データは、FrontendとBackendのHTTPインターフェースを通じて公開されます。監視データはキー・バリューテキストの形式で提示されます。各Keyは異なるLabelsによっても区別される場合があります。ユーザーがDorisを構築した際、以下のインターフェースを通じてブラウザでノードの監視データにアクセスできます:
- Frontend:
fe_host:fe_http_port/metrics - Backend:
be_host:be_web_server_port/metrics - Broker: 現在利用不可
ユーザーは以下の監視項目結果を確認できます(例:FE部分監視項目):
# HELP jvm_heap_size_bytes jvm heap stat
# TYPE jvm_heap_size_bytes gauge
jvm_heap_size_bytes{type="max"} 8476557312
jvm_heap_size_bytes{type="committed"} 1007550464
jvm_heap_size_bytes{type="used"} 156375280
# HELP jvm_non_heap_size_bytes jvm non heap stat
# TYPE jvm_non_heap_size_bytes gauge
jvm_non_heap_size_bytes{type="committed"} 194379776
jvm_non_heap_size_bytes{type="used"} 188201864
# HELP jvm_young_size_bytes jvm young mem pool stat
# TYPE jvm_young_size_bytes gauge
jvm_young_size_bytes{type="used"} 40652376
jvm_young_size_bytes{type="peak_used"} 277938176
jvm_young_size_bytes{type="max"} 907345920
# HELP jvm_old_size_bytes jvm old mem pool stat
# TYPE jvm_old_size_bytes gauge
jvm_old_size_bytes{type="used"} 114633448
jvm_old_size_bytes{type="peak_used"} 114633448
jvm_old_size_bytes{type="max"} 7455834112
# HELP jvm_gc jvm gc stat
# TYPE jvm_gc gauge
<GarbageCollector>{type="count"} 247
<GarbageCollector>{type="time"} 860
# HELP jvm_thread jvm thread stat
# TYPE jvm_thread gauge
jvm_thread{type="count"} 162
jvm_thread{type="peak_count"} 205
jvm_thread{type="new_count"} 0
jvm_thread{type="runnable_count"} 48
jvm_thread{type="blocked_count"} 1
jvm_thread{type="waiting_count"} 41
jvm_thread{type="timed_waiting_count"} 72
jvm_thread{type="terminated_count"} 0
...
これはPrometheus Formatで提供される監視データです。これらの監視項目の1つを例として説明します:
# HELP jvm_heap_size_bytes jvm heap stat
# TYPE jvm_heap_size_bytes gauge
jvm_heap_size_bytes{type="max"} 8476557312
jvm_heap_size_bytes{type="committed"} 1007550464
jvm_heap_size_bytes{type="used"} 156375280
- "#"から始まる行動コメント行。HELPは監視項目の説明です。TYPEは監視項目のデータタイプを表し、Gaugeは例のスカラーデータです。Counter、Histogramなどの他のデータタイプもあります。詳細については、Prometheus Official Documentを参照してください。
jvm_heap_size_bytesは監視項目の名前(Key)です。type= "max"はtypeという名前のラベルで、値はmaxです。監視項目は複数のLabelsを持つことができます。8476557312などの最終的な数値が監視値です。
監視アーキテクチャ
監視アーキテクチャ全体を以下の図に示します:
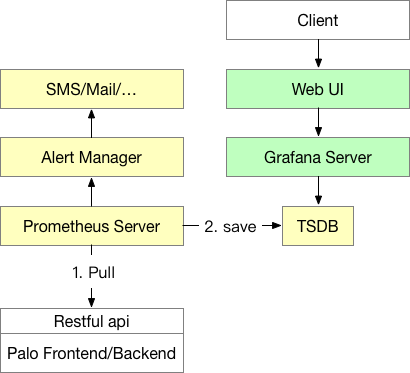
- 黄色の部分はPrometheus関連コンポーネントです。Prometheus ServerはPrometheusのメインプロセスです。現在、PrometheusはPullによってDorisノードの監視インターフェースにアクセスし、時系列データを時系列データベースTSDBに格納します(TSDBはPrometheusプロセスに含まれており、別途デプロイする必要はありません)。PrometheusはPush Gatewayの構築もサポートしており、監視システムによって監視データをPushでPush Gatewayにプッシュし、その後Prometheus ServerがPullを通じてPush Gatewayからデータを取得することができます。
- Alert ManagerはPrometheusのアラームコンポーネントで、別途デプロイする必要があります(まだソリューションは提供されていませんが、公式ドキュメントを参照して構築できます)。Alert Managerを通じて、ユーザーはアラーム戦略を設定し、メール、ショートメッセージなどのアラームを受信できます。
- 緑の部分はGrafana関連コンポーネントです。Grafana ServerはGrafanaのメインプロセスです。起動後、ユーザーはWebページを通じてGrafanaを設定できます。これには、データソース設定、ユーザー設定、Dashboard描画などが含まれます。これは、エンドユーザーが監視データを表示する場所でもあります。
構築を開始
Dorisのデプロイが完了した後、監視システムの構築を開始してください。
Prometheus
-
Prometheus WebsiteでPrometheusの最新バージョンをダウンロードします。ここではバージョン2.43.0-linux-amd64を例に取ります。
-
監視サービスを実行する予定のマシンで、ダウンロードしたtarファイルを展開します。
-
設定ファイルprometheus.ymlを開きます。ここでは設定例を提供し、説明します(設定ファイルはYML形式で、統一されたインデントとスペースに注意してください):
ここでは、監視設定に静的ファイルの最もシンプルな方法を使用します。Prometheusは様々なservice discoveryをサポートしており、ノードの追加と削除を動的に検出できます。
# my global config
global:
scrape_interval: 15s # Global acquisition interval, default 1 m, set to 15s
evaluation_interval: 15s # Global rule trigger interval, default 1 m, set 15s here
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'DORIS_CLUSTER' # Each Doris cluster, we call it a job. Job can be given a name here as the name of Doris cluster in the monitoring system.
metrics_path: '/metrics' # Here you specify the restful API to get the monitors. With host: port in the following targets, Prometheus will eventually collect monitoring items through host: port/metrics_path.
static_configs: # Here we begin to configure the target addresses of FE and BE, respectively. All FE and BE are written into their respective groups.
- targets: ['fe_host1:8030', 'fe_host2:8030', 'fe_host3:8030']
labels:
group: fe # Here configure the group of fe, which contains three Frontends
- targets: ['be_host1:8040', 'be_host2:8040', 'be_host3:8040']
labels:
group: be # Here configure the group of be, which contains three Backends
- job_name: 'DORIS_CLUSTER_2' # We can monitor multiple Doris clusters in a Prometheus, where we begin the configuration of another Doris cluster. Configuration is the same as above, the following is outlined.
metrics_path: '/metrics'
static_configs:
- targets: ['fe_host1:8030', 'fe_host2:8030', 'fe_host3:8030']
labels:
group: fe
- targets: ['be_host1:8040', 'be_host2:8040', 'be_host3:8040']
labels:
group: be
-
Prometheusの開始
以下のコマンドでPrometheusを開始します:
nohup ./prometheus --web.listen-address="0.0.0.0:8181" &このコマンドはPrometheusをバックグラウンドで実行し、Webポートを8181として指定します。起動後、データが収集されdataディレクトリに保存されます。
-
Prometheusの停止
現在、プロセスを停止する正式な方法はなく、kill -9で直接停止します。もちろん、Prometheusをサービスとして設定し、サービス方式で開始・停止することも可能です。
-
Prometheusへのアクセス
PrometheusはWebページを通じて簡単にアクセスできます。ブラウザでポート8181を開くことでPrometheusのページにアクセスできます。ナビゲーションバーの
Status->Targetsをクリックすると、グループ化されたJobsのすべての監視ホストノードを確認できます。通常、すべてのノードはUP状態であるべきで、これはデータ取得が正常であることを示します。Endpointをクリックすると、現在の監視値を確認できます。ノードの状態がUPでない場合は、まずDorisのmetricsインターフェース(前の記事を参照)にアクセスして接続可能かどうかを確認するか、Prometheus関連ドキュメントを参照して解決を試みてください。 -
これまでで、シンプルなPrometheusが構築・設定されました。より高度な使用方法については、公式ドキュメントを参照してください。
Grafana
-
Grafanaの公式サイトでGrafanaの最新版をダウンロードします。ここではversion 8.5.22.linux-amd64を例とします。
-
監視サービスの実行準備ができたマシンで、ダウンロードしたtarファイルを解凍します。
-
設定ファイルconf/defaults.iniを開きます。ここでは変更が必要な設定項目のみをリストし、その他の設定はデフォルトで使用できます。
# Path to where grafana can store temp files, sessions, and the sqlite3 db (if that is used)
data = data
# Directory where grafana can store logs
logs = data/log
# Protocol (http, https, socket)
protocal = http
# The ip address to bind to, empty will bind to all interfaces
http_addr =
# The http port to use
http_port = 8182 -
Grafanaの開始
以下のコマンドでGrafanaを開始します
nohup ./bin/grafana-server &このコマンドはGrafanaをバックグラウンドで実行し、アクセスポートは上記で設定した8182です。
-
Grafanaの停止
現在、プロセスを停止する正式な方法はありません。kill -9で直接停止してください。もちろん、Grafanaをサービスとして設定して、サービスとして開始・停止することもできます。
-
Grafanaへのアクセス
ブラウザから8182ポートを開くと、Grafanaページにアクセスできます。デフォルトのユーザー名とパスワードはadminです。
-
Grafanaの設定
初回ログイン時は、プロンプトに従ってデータソースを設定する必要があります。ここでのデータソースは、前のステップで設定したPrometheusです。
データソース設定のSettingページの説明は以下の通りです:
- Name:データソースの名前。カスタマイズ可能。例:doris_monitor_data_source
- Type:Prometheusを選択
- URL:PrometheusのWebアドレスを入力。例:http://host:8181
- Access:ここではServerモードを選択します。これは、Grafanaプロセスが配置されているサーバーを通じてPrometheusにアクセスすることを意味します。
- その他のオプションはデフォルトで利用可能です。
- 下部の
Save & Testをクリックします。Data source is workingが表示されれば、データソースが利用可能であることを意味します。 - データソースが利用可能であることを確認したら、左側のナビゲーションバーの+番号をクリックして、Dashboardの追加を開始します。ここではDorisのダッシュボードテンプレート(このドキュメントの冒頭にあります)を用意しています。ダウンロードが完了したら、
New dashboard->Import dashboard->Upload.json Fileをクリックして、ダウンロードしたJSONファイルをインポートします。 - インポート後、Dashboardにはデフォルトで
Doris Overviewという名前を付けることができます。同時に、データソースを選択する必要があります。ここで、先ほど作成したdoris_monitor_data_sourceを選択します。 Importをクリックしてインポートを完了します。その後、Dorisのダッシュボードディスプレイが表示されます。
-
これまでで、シンプルなGrafanaの構築と設定が完了しました。より高度な使用方法については、公式ドキュメントを参照してください。
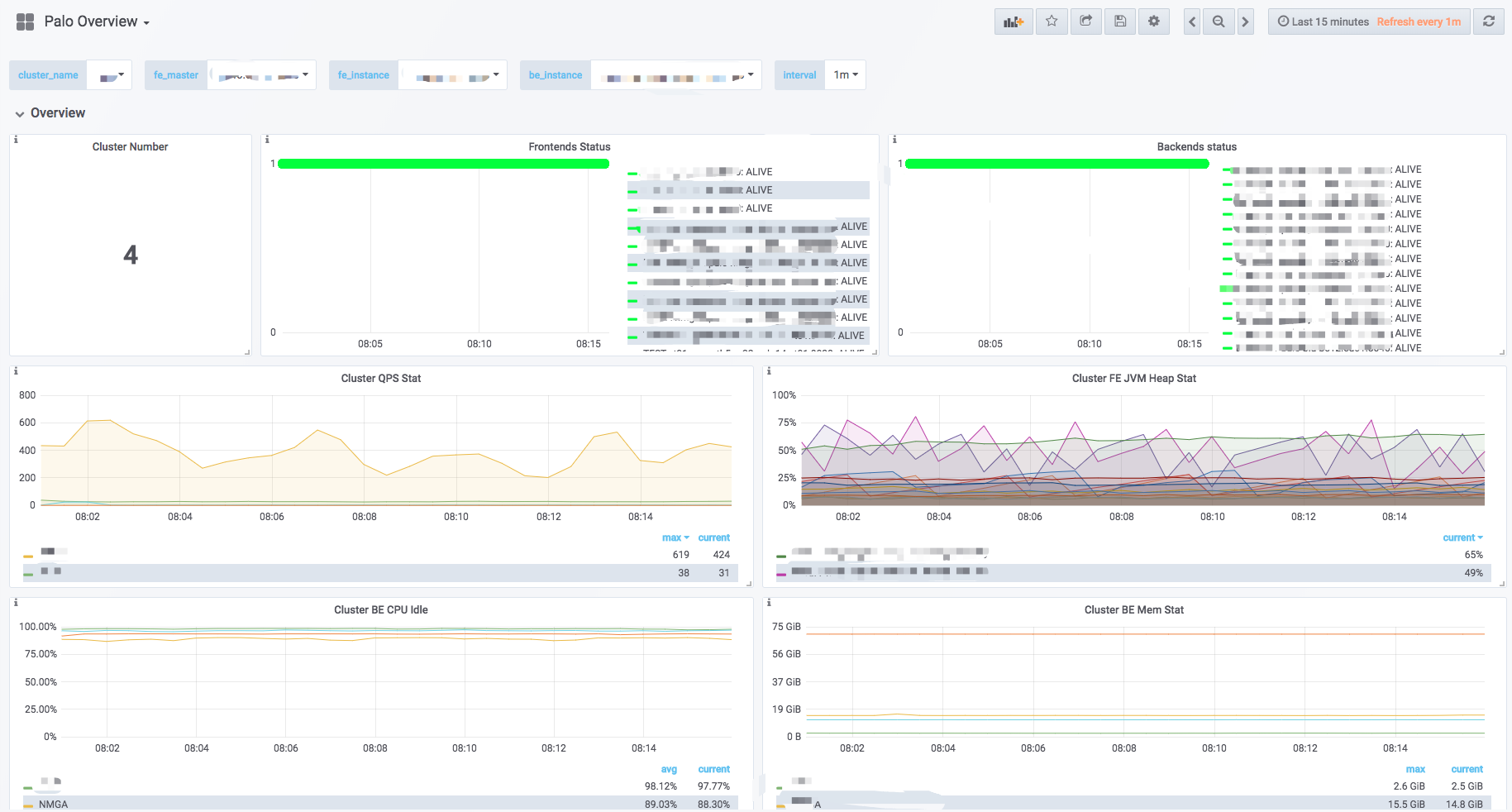
Dashboard
ここでDoris Dashboardについて簡単に紹介します。Dashboardの内容は、バージョンのアップグレードに伴って変更される可能性があります。このドキュメントが最新のDashboard説明であることは保証されません。
-
トップバー

- 左上はDashboardの名前です。
- 右上は現在の監視時間範囲を示しています。ドロップダウンで異なる時間範囲を選択できます。定期的なページ更新間隔も指定できます。
- クラスター名:Prometheus設定ファイルの各job名はDorisクラスターを表します。異なるクラスターを選択すると、下のチャートは対応するクラスターの監視情報を表示します。
- fe_master:クラスターに対応するMaster Frontendノード。
- fe_instance:クラスターに対応するすべてのFrontendノード。異なるFrontendを選択すると、下のチャートはそのFrontendの監視情報を表示します。
- be_instance:クラスターに対応するすべてのBackendノード。異なるBackendを選択すると、下のチャートはそのBackendの監視情報を表示します。
- Interval:一部のチャートはレート関連の監視項目を表示します。ここでは、レートをサンプリングして計算する間隔を選択できます(注:15s間隔では一部のチャートが表示できない場合があります)。
-
Row
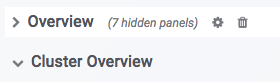
Grafanaでは、Rowの概念は一連のグラフです。上図に示すように、OverviewとCluster Overviewは2つの異なるRowです。RowはRowをクリックして折りたたむことができます。現在のDashboardには以下のRowがあります(継続的に更新中):
- Overview:すべてのDorisクラスターのサマリー表示。
- Cluster Overview:選択されたクラスターのサマリー表示。
- Query Statistic:選択されたクラスターのクエリ関連監視。
- FE JVM:選択されたFrontendのJVM監視。
- BE:選択されたクラスターのバックエンドのサマリー表示。
- BE Task:選択されたクラスターのBackends Task情報の表示。
-
チャート
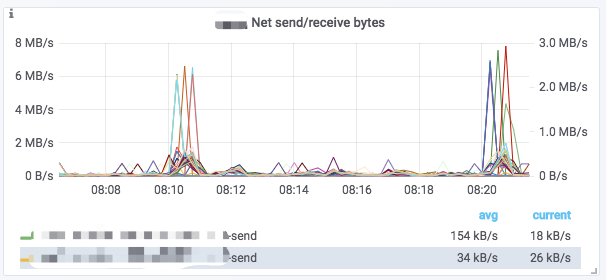
典型的なアイコンは以下の部分に分かれています:
- マウスを左上のIアイコンにホバーすると、チャートの説明が表示されます。
- 下の図をクリックすると、監視項目を個別に表示できます。再度クリックするとすべてが表示されます。
- チャート内でドラッグすると時間範囲を選択できます。
- 選択されたクラスター名がタイトルの[]内に表示されます。
- 一部の値は左のY軸に対応し、一部は右に対応します。これは凡例の末尾の
-rightで区別できます。 - チャート名をクリックし、
Editをクリックしてチャートを編集できます。
Dashboardの更新
- Grafanaの左列の
+をクリックし、Dashboardをクリックします。 - 左上の
New dashboardをクリックすると、右側にImport dashboardが表示されます。 Upload .json Fileをクリックして最新のテンプレートファイルを選択します。- データソースの選択
Import (Overwrite)をクリックしてテンプレート更新を完了します。