
ワークロードグループ
Workload Groupは、ワークロードを分離するためのプロセス内メカニズムです。 BEプロセス内でリソース(CPU、IO、Memory)を細かく分割または制限することで、リソース分離を実現します。 その原理を以下の図で示します:
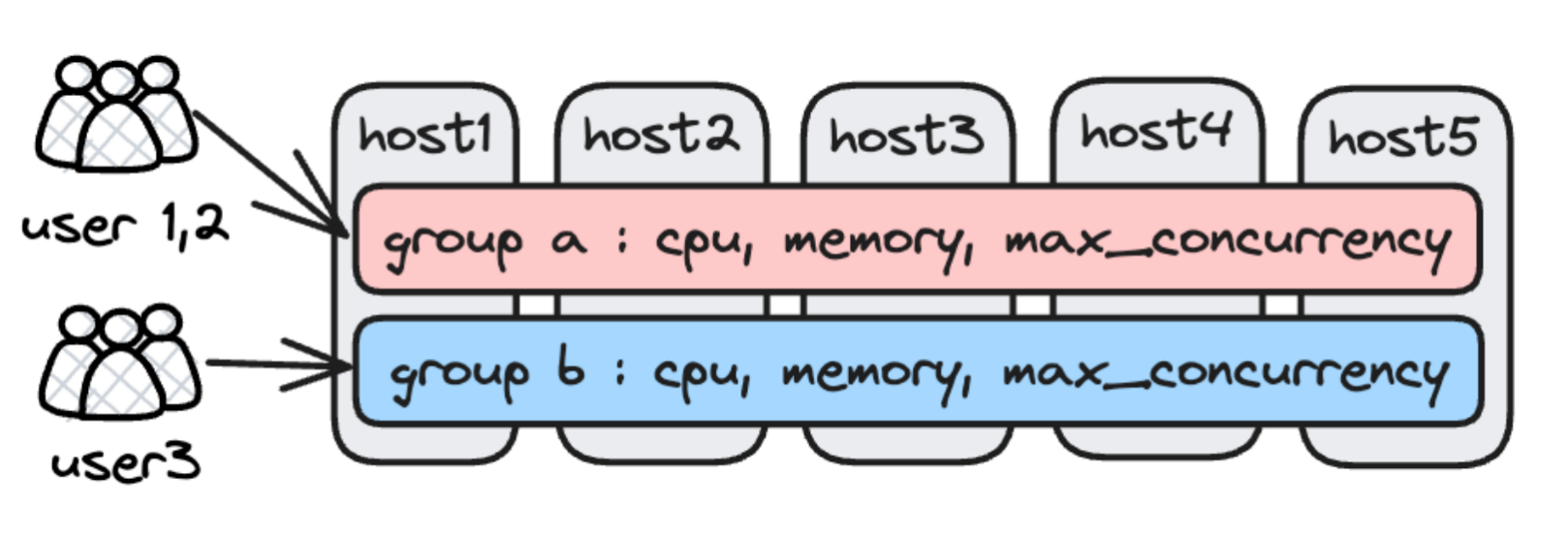
現在サポートされている分離機能には以下が含まれます:
- CPUリソースの管理、cpu hard limitとcpu soft limitの両方をサポート
- メモリリソースの管理、memory hard limitとmemory soft limitの両方をサポート
- IOリソースの管理、ローカルファイルとリモートファイルの読み取りで生成されるIOを含む
Workload Groupはプロセス内リソース分離機能を提供しており、プロセス間リソース分離手法(Resource GroupやCompute Groupなど)とは以下の点で異なります:
- プロセス内リソース分離では完全な分離を実現することはできません。例えば、高負荷クエリと低負荷クエリが同一プロセス内で実行される場合、Workload Groupを使用して高負荷グループのCPU使用量を制限し、全体のCPU使用量を妥当な範囲内に保ったとしても、低負荷グループのレイテンシは依然として影響を受ける可能性があります。ただし、CPU制御が全くない場合と比較すれば、より良いパフォーマンスを発揮します。この制限は、共通キャッシュや共有RPCスレッドプールなど、プロセス内の特定の共有コンポーネントを完全に分離することが困難であることに起因します。
- リソース分離戦略の選択は、分離とコストのトレードオフに依存します。ある程度のレイテンシを許容でき、低コストを優先する場合は、Workload Group分離アプローチが適している可能性があります。一方、完全な分離が必要で高コストが許容できる場合は、プロセス間リソース分離アプローチ(つまり、分離されたワークロードを別々のプロセスに配置する)を検討すべきです。例えば、Resource GroupやCompute Groupを使用して高優先度ワークロードを独立したBEノードに割り当てることで、より徹底的な分離を実現できます。
バージョンノート
-
Workload Group機能はDoris 2.0から利用可能になりました。Doris 2.0では、Workload Group機能はCGroupに依存しませんが、Doris 2.1以降ではCGroupが必要です。
-
Doris 1.2から2.0へのアップグレード:クラスタ全体のアップグレードが完了した後にWorkload Group機能を有効にすることを推奨します。一部のfollower FEノードのみがアップグレードされた場合、アップグレードされていないFEノードにWorkload Groupメタデータが存在しないため、アップグレードされたfollower FEノードでのクエリが失敗する可能性があります。
-
Doris 2.0から2.1へのアップグレード:Doris 2.1のWorkload Group機能はCGroupに依存するため、Doris 2.1にアップグレードする前にCGroup環境を設定する必要があります。
Workload Groupの設定
CGroup環境のセットアップ
Workload GroupはCPU、メモリ、IOの管理をサポートします。CPU管理はCGroupコンポーネントに依存します。 Workload GroupをCPUリソース管理に使用するには、まずCGroup環境を設定する必要があります。
以下はCGroup環境を設定する手順です:
- まず、BEが配置されているノードにCGroupがインストールされているかを確認します。 出力にcgroupが含まれている場合、現在の環境にCGroup V1がインストールされていることを示します。 cgroup2が含まれている場合、CGroup V2がインストールされていることを示します。次のステップでどのバージョンがアクティブかを判断できます。
cat /proc/filesystems | grep cgroup
nodev cgroup
nodev cgroup2
nodev cgroupfs
- アクティブなCGroupのバージョンはパス名に基づいて確認できます。
If this path exists, it indicates that CGroup V1 is currently active.
/sys/fs/cgroup/cpu/
If this path exists, it indicates that CGroup V2 is currently active.
/sys/fs/cgroup/cgroup.controllers
- CGroupパスの下にdorisという名前のディレクトリを作成します。ディレクトリ名はユーザーがカスタマイズできます。
If using CGroup V1, create the directory under the cpu directory.
mkdir /sys/fs/cgroup/cpu/doris
If using CGroup V2, create the directory directly under the cgroup directory.
mkdir /sys/fs/cgroup/doris
- Doris BEプロセスがこのディレクトリに対して読み取り、書き込み、実行の権限を持っていることを確認してください。
// If using CGroup V1, the command is as follows:
// 1. Modify the directory's permissions to be readable, writable, and executable.
chmod 770 /sys/fs/cgroup/cpu/doris
// 2. Change the ownership of this directory to the doris account.
chown -R doris:doris /sys/fs/cgroup/cpu/doris
// If using CGroup V2, the command is as follows:
// 1.Modify the directory's permissions to be readable, writable, and executable.
chmod 770 /sys/fs/cgroup/doris
// 2. Change the ownership of this directory to the doris account.
chown -R doris:doris /sys/fs/cgroup/doris
- 現在の環境がCGroup v2を使用している場合、以下の手順が必要です。CGroup v1の場合、この手順はスキップできます。
- ルートディレクトリのcgroup.procsファイルの権限を変更します。これは、CGroup v2がより厳格な権限制御を持っており、CGroupディレクトリ間でプロセスを移動するためにルートディレクトリのcgroup.procsファイルへの書き込み権限が必要なためです。
chmod a+w /sys/fs/cgroup/cgroup.procs
- CGroup v2では、cgroup.controllersファイルが現在のディレクトリで利用可能なコントローラーをリストし、cgroup.subtree_controlファイルがサブディレクトリで利用可能なコントローラーをリストします。 そのため、dorisディレクトリでcpuコントローラーが有効になっているかを確認する必要があります。dorisディレクトリのcgroup.controllersファイルにcpuが含まれていない場合、cpuコントローラーが有効になっていないことを意味します。dorisディレクトリで以下のコマンドを実行することで有効にできます。 このコマンドは、親ディレクトリのcgroup.subtree_controlファイルを変更してdorisディレクトリがcpuコントローラーを使用できるようにすることで動作します。
// After running this command, you should be able to see the cpu.max file in the doris directory,
// and the output of cgroup.controllers should include cpu.
// If the command fails, it means that the parent directory of doris also does not have the cpu controller enabled,
// and you will need to enable the cpu controller for the parent directory.
echo +cpu > ../cgroup.subtree_control
- cgroupのパスを指定するためにBE設定を変更します。
If using CGroup V1, the configuration path is as follows:
doris_cgroup_cpu_path = /sys/fs/cgroup/cpu/doris
If using CGroup V2, the configuration path is as follows:
doris_cgroup_cpu_path = /sys/fs/cgroup/doris
- BEを再起動し、ログ(be.INFO)で「add thread xxx to group」というフレーズが表示されることで、設定が成功したことを示します。
- 現在のWorkload Group機能は単一マシンでの複数BE instance のデプロイをサポートしていないため、マシンごとに1つのBEのみデプロイすることを推奨します。
- マシンが再起動された後、CGroupパス下のすべての設定はクリアされます。 CGroup設定を永続化するには、systemdを使用して操作をカスタムシステムサービスとして設定することで、 マシンが再起動するたびに作成と認証操作を自動実行できます。
- コンテナ内でCGroupを使用する場合、コンテナはホストマシンを操作する権限を持つ必要があります。
コンテナでのWorkload Group使用に関する考慮事項
WorkloadのCPU管理はCGroupに基づいています。コンテナ内でWorkload Groupを使用したい場合、 コンテナ内のBEプロセスがホストマシン上のCGroupファイルの読み書き権限を持てるよう、コンテナを特権モードで起動する必要があります。
BEがコンテナ内で実行される場合、Workload GroupのCPUリソース使用量はコンテナの利用可能なリソースに基づいて分割されます。 例えば、ホストマシンが64コアでコンテナに8コアが割り当てられ、 Workload Groupが50%のCPUハード制限で設定されている場合、Workload Groupの実際の利用可能CPUコア数は4(8コア * 50%)となります。
Workload Groupのメモリとio管理機能はDorisによって内部的に実装されており、外部コンポーネントに依存しないため、 コンテナと物理マシン間のデプロイに違いはありません。
K8S上でDorisを使用したい場合は、Doris Operatorを使用してデプロイすることを推奨します。これにより基盤の権限問題を回避できます。
Workload Groupの作成
mysql [information_schema]>create workload group if not exists g1
-> properties (
-> "cpu_share"="1024"
-> );
Query OK, 0 rows affected (0.03 sec)
CREATE-WORKLOAD-GROUPを参照してください。
この時点で設定されるCPU制限はソフトリミットです。バージョン2.1以降、Dorisは自動的にnormalという名前のグループを作成し、このグループは削除できません。
Workload Groupプロパティ
| Property | データ型 | デフォルト値 | 値の範囲 | 説明 |
|---|---|---|---|---|
| cpu_share | Integer | -1 | [1, 10000] | オプション。CPUソフトリミットモードで有効です。有効な値の範囲は使用されているCGroupのバージョンに依存し、詳細は後述します。cpu_shareはWorkload Groupが取得できるCPU時間の重みを表します。値が大きいほど、より多くのCPU時間を取得できます。例えば、ユーザーがg-a、g-b、g-cという3つのWorkload Groupを作成し、cpu_share値をそれぞれ10、30、40に設定した場合、ある時点でg-aとg-bがタスクを実行しg-cがタスクを実行していない場合、g-aはCPUリソースの25%(10 / (10 + 30))を受け取り、g-bはCPUリソースの75%を受け取ります。システムで1つのWorkload Groupのみが実行されている場合、cpu_shareの値に関係なく、すべてのCPUリソースを取得できます。 |
| memory_limit | Float | -1 | (0%, 100%] | オプション。メモリハードリミットの有効化は、現在のWorkload Groupの最大利用可能メモリパーセンテージを表します。デフォルト値はメモリ制限が適用されないことを意味します。すべてのWorkload Groupのmemory_limitの累積値は100%を超えることはできず、通常はenable_memory_overcommit属性と組み合わせて使用されます。例えば、マシンが64GBのメモリを持ち、Workload Groupのmemory_limitが50%に設定されている場合、そのグループで利用可能な実際の物理メモリは64GB * 90% * 50% = 28.8GBとなります。ここで90%はBEプロセスの利用可能メモリ設定のデフォルト値です。 |
| enable_memory_overcommit | Boolean | true | true, false | オプション。現在のWorkload Groupのメモリ制限がハードリミットかソフトリミットかを制御するために使用され、デフォルトはtrueに設定されています。falseに設定すると、Workload Groupはハードメモリリミットを持ち、システムがメモリ使用量が制限を超えていることを検出すると、グループ内で最もメモリ使用量の多いタスクを即座にキャンセルして、超過メモリを解放します。trueに設定すると、Workload Groupはソフトメモリリミットを持ちます。利用可能な空きメモリがある場合、Workload Groupはmemory_limitを超えた後でもシステムメモリを使用し続けることができます。システムの総メモリが圧迫されている場合、システムはグループ内で最もメモリ使用量の多いタスクをキャンセルし、システムメモリ圧迫を緩和するために超過メモリの一部を解放します。すべてのWorkload Groupの総memory_limitを100%未満に保ち、BEプロセスの他のコンポーネント用にメモリを確保することが推奨されます。 |
| cpu_hard_limit | Integer | -1 | [1%, 100%] | オプション。CPUハードリミットモードで有効で、Workload Groupが使用できる最大CPU パーセンテージを表します。マシンのCPUリソースが完全に利用されているかどうかに関係なく、Workload GroupのCPU使用率はcpu_hard_limitを超えることはできません。すべてのWorkload Groupのcpu_hard_limitの累積値は100%を超えることはできません。この属性はバージョン2.1で導入され、バージョン2.0ではサポートされていません。 |
| max_concurrency | Integer | 2147483647 | [0, 2147483647] | オプション。最大クエリ並行性を指定します。デフォルト値は整数の最大値で、並行性制限がないことを意味します。実行中のクエリ数が最大並行性に達すると、新しいクエリはキューに入ります。 |
| max_queue_size | Integer | 0 | [0, 2147483647] | オプション。クエリ待機キューの長さを指定します。キューが満杯になると、新しいクエリは拒否されます。デフォルト値は0で、キューイングなしを意味します。キューが満杯の場合、新しいクエリは直接失敗します。 |
| queue_timeout | Integer | 0 | [0, 2147483647] | オプション。待機キューでのクエリの最大待機時間をミリ秒で指定します。キューでのクエリの待機時間がこの値を超えると、例外が直接クライアントにスローされます。デフォルト値は0で、キューイングなしを意味し、クエリはキューに入ると即座に失敗します。 |
| scan_thread_num | Integer | -1 | [1, 2147483647] | オプション。現在のWorkload Groupでスキャンに使用されるスレッド数を指定します。このプロパティが-1に設定されている場合、アクティブでないことを意味し、BEでの実際のスキャンスレッド数はBEのdoris_scanner_thread_pool_thread_num設定にデフォルト設定されます。 |
| max_remote_scan_thread_num | Integer | -1 | [1, 2147483647] | オプション。外部データソースを読み取るためのスキャンスレッドプール内の最大スレッド数を指定します。このプロパティが-1に設定されている場合、実際のスレッド数はBEによって決定され、通常はCPUコア数に基づきます。 |
| min_remote_scan_thread_num | Integer | -1 | [1, 2147483647] | オプション。外部データソースを読み取るためのスキャンスレッドプール内の最小スレッド数を指定します。このプロパティが-1に設定されている場合、実際のスレッド数はBEによって決定され、通常はCPUコア数に基づきます。 |
| read_bytes_per_second | Integer | -1 | [1, 9223372036854775807] | オプション。Dorisで内部テーブルを読み取る際の最大I/Oスループットを指定します。デフォルト値は-1で、I/O帯域幅制限が適用されないことを意味します。この値は個々のディスクに関連付けられるのではなく、ディレクトリに関連付けられることに注意することが重要です。例えば、Dorisが内部テーブルデータを格納するために2つのディレクトリで設定されている場合、各ディレクトリの最大読み取りI/Oはこの値を超えません。両方のディレクトリが同じディスクに配置されている場合、最大スループットは2倍になります(つまり、read_bytes_per_secondの2倍)。スピルディスクのファイルディレクトリもこの制限の対象となります。 |
| remote_read_bytes_per_second | Integer | -1 | [1, 9223372036854775807] | オプション。Dorisで外部テーブルを読み取る際の最大I/Oスループットを指定します。デフォルト値は-1で、I/O帯域幅制限が適用されないことを意味します。 |
-
現在、cpuハードリミットとcpuソフトリミットの同時使用はサポートされていません。 任意の時点で、クラスターはソフトリミットまたはハードリミットのいずれかのみを持つことができます。それらの切り替え方法については後述します。
-
すべてのプロパティはオプションですが、Workload Groupを作成する際には少なくとも1つのプロパティを指定する必要があります。
-
CPUソフトリミットのデフォルト値はCGroup v1とCGroup v2で異なることに注意することが重要です。CGroup v1のデフォルトCPUソフトリミットは1024で、有効範囲は2から262144です。一方、CGroup v2のデフォルトは100で、有効範囲は1から10000です。 ソフトリミットに範囲外の値が設定されると、BEでCPUソフトリミットの変更に失敗する可能性があります。CGroup v2のデフォルト値である100がCGroup v1環境で適用されると、このWorkload Groupがマシン上で最低の優先度を持つ結果となる可能性があります。
-
CPUソフトリミットは相対的な重み配分です。タスクが消費する絶対CPU時間を制限するものではありません。代わりに、CPUリソースが競合している場合(全体的な使用率≥100%)、割り当てられた重みに比例してCPU時間スライスを配分します。CPUがアイドル状態の場合、タスクは制限なしに利用可能なすべてのCPUリソースを消費できます。そのため、実際の効果を評価することは極めて困難であり、本番環境ではCPUハードリミットの使用が推奨されます。
ユーザーへのWorkload Group設定
ユーザーを特定のWorkload Groupにバインドする前に、ユーザーがWorkload Groupに対する必要な権限を持っていることを確認する必要があります。 ユーザーでinformation_schema.workload_groupsシステムテーブルを照会でき、結果には現在のユーザーがアクセス権限を持つWorkload Groupが表示されます。 以下のクエリ結果は、現在のユーザーがg1とnormalのWorkload Groupにアクセスできることを示しています:
SELECT name FROM information_schema.workload_groups;
+--------+
| name |
+--------+
| normal |
| g1 |
+--------+
g1 Workload Groupが表示されない場合は、ADMINアカウントを使用してGRANT文を実行し、ユーザーを認可することができます。例えば:
GRANT USAGE_PRIV ON WORKLOAD GROUP 'g1' TO 'user_1'@'%';
このステートメントは、user_1にg1という名前のWorkload Groupを使用する権限を付与することを意味します。 詳細はgrantで確認できます。
Workload Groupをユーザーにバインドする2つの方法
- ユーザープロパティを設定することで、ユーザーをデフォルトのWorkload Groupにバインドできます。デフォルトはnormalです。ここでの値は空にできないことに注意してください。そうしないと、ステートメントが失敗します。
set property 'default_workload_group' = 'g1';
このステートメントを実行した後、現在のユーザーのクエリはデフォルトで 'g1' Workload Group を使用するようになります。
- セッション変数を通じて Workload Group を指定する場合、デフォルトは空です:
set workload_group = 'g1';
両方の方法でユーザーのWorkload Groupを指定する場合、セッション変数がユーザープロパティよりも優先されます。
Workload Groupの表示
- SHOW文を使用してWorkload Groupを表示できます:
show workload groups;
詳細は SHOW-WORKLOAD-GROUPS を参照してください
- システムテーブルを通じて Workload Group を表示できます:
mysql [information_schema]>select * from information_schema.workload_groups where name='g1';
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
| ID | NAME | CPU_SHARE | MEMORY_LIMIT | ENABLE_MEMORY_OVERCOMMIT | MAX_CONCURRENCY | MAX_QUEUE_SIZE | QUEUE_TIMEOUT | CPU_HARD_LIMIT | SCAN_THREAD_NUM | MAX_REMOTE_SCAN_THREAD_NUM | MIN_REMOTE_SCAN_THREAD_NUM | MEMORY_LOW_WATERMARK | MEMORY_HIGH_WATERMARK | TAG | READ_BYTES_PER_SECOND | REMOTE_READ_BYTES_PER_SECOND |
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
| 14009 | g1 | 1024 | -1 | true | 2147483647 | 0 | 0 | -1 | -1 | -1 | -1 | 50% | 80% | | -1 | -1 |
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
1 row in set (0.05 sec)
Workload Group の変更
mysql [information_schema]>alter workload group g1 properties('cpu_share'='2048');
Query OK, 0 rows affected (0.00 sec
mysql [information_schema]>select cpu_share from information_schema.workload_groups where name='g1';
+-----------+
| cpu_share |
+-----------+
| 2048 |
+-----------+
1 row in set (0.02 sec)
より詳細な情報はALTER-WORKLOAD-GROUPをご参照ください
Workload Groupの削除
mysql [information_schema]>drop workload group g1;
Query OK, 0 rows affected (0.01 sec)
詳細についてはDROP-WORKLOAD-GROUPを参照してください。
CPUソフト制限とハード制限モード間の切り替えについて
現在、DorisはCPUソフト制限とハード制限の両方を同時に実行することはサポートしていません。任意の時点で、DorisクラスターはCPUソフト制限モードまたはCPUハード制限モードのいずれかでのみ動作できます。 ユーザーはこれら2つのモード間で切り替えることができ、切り替え方法は以下の通りです:
1 現在のクラスター構成がデフォルトのCPUソフト制限に設定されており、これをCPUハード制限に変更したい場合は、Workload Groupのcpu_hard_limitパラメーターを有効な値に変更する必要があります。
alter workload group test_group properties ( 'cpu_hard_limit'='20%' );
クラスター内のすべてのWorkload Groupを変更する必要があり、すべてのWorkload Groupのcpu_hard_limitの累積値は100%を超えることはできません。
CPUハード制限は自動的に有効な値を持つことができないため、プロパティを変更せずに単純にスイッチを有効にするだけでは、CPUハード制限が有効になりません。
2 すべてのFEノードでCPUハード制限を有効にする
1 Modify the configuration in the fe.conf file on the disk.
experimental_enable_cpu_hard_limit = true
2 Modify the configuration in memory.
ADMIN SET FRONTEND CONFIG ("enable_cpu_hard_limit" = "true");
ユーザーがCPUハードリミットからCPUソフトリミットに戻したい場合は、すべてのFEノードでenable_cpu_hard_limitの値をfalseに設定する必要があります。 CPUソフトリミットプロパティcpu_shareは、(以前に指定されていなかった場合)有効な値である1024がデフォルトになります。ユーザーは、グループの優先度に基づいてcpu_share値を調整できます。
テスト
メモリハードリミット
アドホック型クエリは通常、予測不可能なSQL入力と不確実なメモリ使用量を持つため、少数のクエリが大量のメモリを消費するリスクがあります。 このようなワークロードは別のグループに割り当てることができ、Workload Groupのメモリハードリミット機能を使用することで、突発的な大規模クエリがすべてのメモリを消費することを防ぎ、他のクエリが利用可能なメモリを使い果たしたり、OOM(Out of Memory)エラーが発生したりする可能性を防ぎます。 このWorkload Groupのメモリ使用量が設定されたハードリミットを超えると、システムはクエリを強制終了してメモリを解放し、プロセスのメモリ不足を防ぎます。
テスト環境
1 FE、1 BE、BEは96コアと375GBのメモリで構成。
テストデータセットはclickbenchで、テスト方法はJMeterを使用してクエリQ29を3つの同時実行で実行します。
Workload Groupでメモリハードリミットを有効にしないテスト
-
プロセスのメモリ使用量を確認します。psコマンド出力の4番目の列は、プロセスの物理メモリ使用量をキロバイト(KB)で表しています。現在のテスト負荷下で、プロセスは約7.7GBのメモリを使用していることが示されています。
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 7896792
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 7929692
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 8101232 -
Dorisのシステムテーブルを使用して、Workload Groupの現在のメモリ使用量を確認します。Workload Groupのメモリ使用量は約5.8GBです。
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5797.524360656738 |
+-------------------+
1 row in set (0.01 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5840.246627807617 |
+-------------------+
1 row in set (0.02 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5878.394917488098 |
+-------------------+
1 row in set (0.02 sec)
ここでは、1つのWorkload Groupのみが実行されている場合でも、プロセスのメモリ使用量は通常、Workload Groupのメモリ使用量よりもはるかに大きいことがわかります。これは、Workload Groupがクエリと読み込みで使用されるメモリのみを追跡するためです。メタデータや各種キャッシュなど、プロセス内の他のコンポーネントで使用されるメモリは、Workload Groupのメモリ使用量の一部としてカウントされず、Workload Groupによって管理されることもありません。
Workload Groupのメモリハード制限を有効にしたテスト
-
SQLコマンドを実行してメモリ設定を変更します。
alter workload group g2 properties('memory_limit'='0.5%');
alter workload group g2 properties('enable_memory_overcommit'='false'); -
同じテストを実行し、システムテーブルでメモリ使用量を確認します。メモリ使用量は約1.5Gです。
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+--------------------+
| wg_mem_used_mb |
+--------------------+
| 1575.3877239227295 |
+--------------------+
1 row in set (0.02 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+------------------+
| wg_mem_used_mb |
+------------------+
| 1668.77405834198 |
+------------------+
1 row in set (0.01 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+--------------------+
| wg_mem_used_mb |
+--------------------+
| 499.96760272979736 |
+--------------------+
1 row in set (0.01 sec) -
psコマンドを使用してプロセスのメモリ使用量を確認します。メモリ使用量は約3.8Gです。
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4071364
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4059012
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4057068 -
同時に、クライアントはメモリ不足によって引き起こされる大量のクエリ失敗を観測することになります。
1724074250162,14126,1c_sql,HY000 1105,"java.sql.SQLException: errCode = 2, detailMessage = (127.0.0.1)[MEM_LIMIT_EXCEEDED]GC wg for hard limit, wg id:11201, name:g2, used:1.71 GB, limit:1.69 GB, backend:10.16.10.8. cancel top memory used tracker <Query#Id=4a0689936c444ac8-a0d01a50b944f6e7> consumption 1.71 GB. details:process memory used 3.01 GB exceed soft limit 304.41 GB or sys available memory 101.16 GB less than warning water mark 12.80 GB., Execute again after enough memory, details see be.INFO.",并发 1-3,text,false,,444,0,3,3,null,0,0,0
エラーメッセージから、Workload Groupが1.7Gのメモリを使用したが、Workload Groupの制限が1.69Gであることが確認できます。計算は以下の通りです:1.69G = 物理マシンメモリ(375G) * mem_limit (be.confからの値、デフォルトは0.9) * 0.5% (Workload Groupの設定)。 これは、Workload Groupで設定されたメモリの割合が、BEプロセスで利用可能なメモリに基づいて計算されることを意味します。
推奨事項
上記のテストで実証されたように、メモリハード制限はWorkload Groupのメモリ使用量を制御できますが、メモリを解放するためにクエリを終了することで制御します。このアプローチはユーザーエクスペリエンスの悪化につながり、極端な場合には全てのクエリが失敗する可能性があります。
したがって、本番環境では、メモリハード制限をクエリキューイング機能と併用することを推奨します。これにより、クエリの成功率を維持しながら制御されたメモリ使用量を確保できます。
CPUハード制限
Dorisのワークロードは一般的に3つのタイプに分類できます:
- コアレポートクエリ:これらは通常、会社の経営陣がレポートを確認するために使用されます。負荷はそれほど高くないかもしれませんが、可用性要件は厳格です。これらのクエリは、より高い優先度のソフト制限を持つグループに割り当てることができ、リソースが不足している時により多くのCPUリソースを受け取ることを保証します。
- Adhocクエリは通常、探索的で分析的な性質を持ち、ランダムなSQLと予測不可能なリソース消費を伴います。その優先度は通常低いです。したがって、CPUハード制限を使用してこれらのクエリを管理し、クラスター可用性を低下させる可能性のある過度のCPUリソース使用を防ぐためにより低い値を設定できます。
- ETLクエリは通常、固定されたSQLと安定したリソース消費を持ちますが、上流データの増加によりリソース使用量が急増することが時折あります。したがって、これらのクエリを管理するためにCPUハード制限を設定できます。
異なるワークロードはCPU消費が異なり、ユーザーは異なるレイテンシ要件を持ちます。BE CPUが完全に利用されると、可用性が低下し、応答時間が増加します。例えば、Adhoc分析クエリがクラスター全体のCPUを完全に利用すると、コアレポートクエリがより高いレイテンシを経験し、SLAに影響を与える可能性があります。したがって、異なるワークロードを分離し、クラスターの可用性とSLAを確保するためにCPU分離メカニズムが必要です。
Workload GroupはCPUソフト制限とハード制限の両方をサポートします。現在、本番環境ではWorkload Groupをハード制限で設定することが推奨されています。これは、CPUソフト制限が通常CPUが完全に利用されている時にのみ優先度効果を示すためです。しかし、CPUが完全に使用されると、内部Dorisコンポーネント(RPCコンポーネントなど)とオペレーティングシステムの利用可能CPUが減少し、クラスター全体の可用性が大幅に低下します。したがって、本番環境では、CPUリソースの枯渇を避けることが不可欠であり、同じロジックがメモリなどの他のリソースにも適用されます。
テスト環境
1 FE、1 BE、96コアマシン。 データセットはclickbenchで、テストSQLはq29です。
テスト
-
JMeterを使用して3つの並行クエリを開始し、BEプロセスのCPU使用率を比較的高い使用率まで押し上げます。テストマシンは96コアを持ち、topコマンドを使用すると、BEプロセスのCPU使用率が7600%であることが確認でき、これはプロセスが現在76コアを使用していることを意味します。

-
現在使用されているWorkload GroupのCPUハード制限を10%に変更します。
alter workload group g2 properties('cpu_hard_limit'='10%'); -
CPU ハード制限モードに切り替えます。
ADMIN SET FRONTEND CONFIG ("enable_cpu_hard_limit" = "true"); -
クエリの負荷テストを再実行すると、現在のプロセスが9〜10コアしか使用できないことがわかります。これは全コアの約10%です。

このテストはクエリワークロードを使用して実施することが重要であることに注意してください。クエリワークロードの方が効果をより反映しやすいためです。負荷をテストする場合、Compactionがトリガーされ、実際の観測値がWorkload Groupで設定された値よりも高くなる可能性があります。現在、CompactionワークロードはWorkload Groupの管理下にありません。
-
Linuxシステムコマンドの使用に加えて、DorisのシステムテーブルからグループのCPU使用率を確認することも可能で、CPU使用率は約10%になっています。
mysql [information_schema]>select CPU_USAGE_PERCENT from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+-------------------+
| CPU_USAGE_PERCENT |
+-------------------+
| 9.57 |
+-------------------+
1 row in set (0.02 sec)
注意
- 設定時は、すべてのグループの合計CPU割り当てを正確に100%に設定しないことを推奨します。これは主に低レイテンシシナリオの可用性を確保するためで、他のコンポーネント用にリソースを予約する必要があるためです。ただし、レイテンシにそれほど敏感でなく、最大限のリソース利用を目的とするシナリオでは、すべてのグループの合計CPU割り当てを100%に設定することを検討できます。
- 現在、FEからBEへのWorkload Groupメタデータの同期間隔は30秒です。そのため、Workload Groupの設定変更が有効になるまで最大30秒かかる場合があります。
ローカルIOの制限
OLAPシステムでは、ETL操作や大規模なAdhocクエリの際に、大量のデータを読み取る必要があります。データ解析プロセスを高速化するため、Dorisは複数のディスクファイルにわたってマルチスレッド並列スキャンを使用しており、これにより大量のディスクIOが発生し、他のクエリ(レポート解析など)に影響を与える可能性があります。 Workload Groupを使用することで、DorisはオフラインのETLデータ処理とオンラインのレポートクエリを別々にグループ化し、オフラインデータ処理のIOバンドワイズを制限できます。これにより、オフラインデータ処理がオンラインレポート解析に与える影響を軽減できます。
テスト環境
1 FE、1 BE、96コアマシン。データセット:clickbench。テストクエリ:q29。
IOハード制限を有効にしないテスト
-
Cacheをクリアする。
// clear OS cache
sync; echo 3 > /proc/sys/vm/drop_caches
// disable BE page cache
disable_storage_page_cache = true -
clickbenchテーブルでフルテーブルスキャンを実行し、単一の並行クエリを実行する。
set dry_run_query = true;
select * from hits.hits; -
DorisのシステムテーブルでCurrent Groupの最大スループットが3GB毎秒であることを確認します。
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 1146.6208400726318 |
+--------------------+
1 row in set (0.03 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 3496.2762966156006 |
+--------------------+
1 row in set (0.04 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 2192.7690029144287 |
+--------------------+
1 row in set (0.02 sec) -
pidstat コマンドを使用してプロセス IO を確認します。最初の列はプロセス ID で、2 番目の列は読み取り IO スループット(kb/s 単位)です。IO が制限されていない場合、最大スループットは毎秒 2GB であることがわかります。
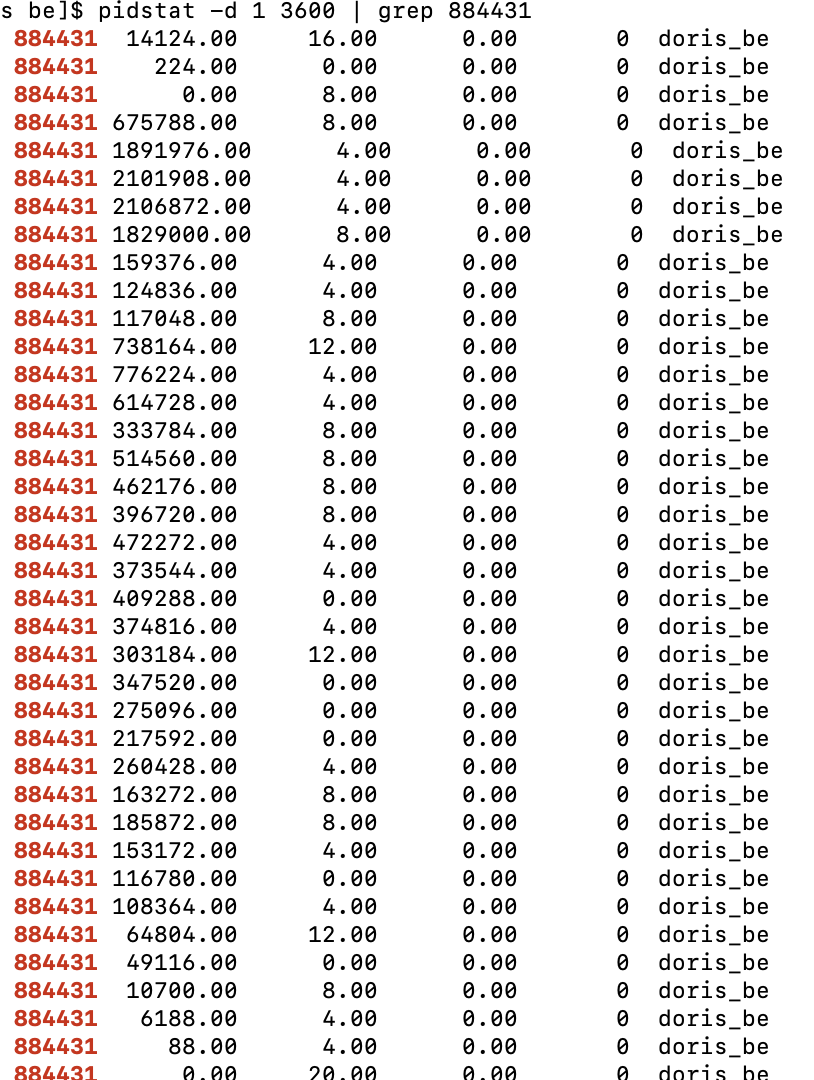
IO ハード制限を有効にした後のテスト
-
キャッシュをクリアします。
// Clear OS cache.
sync; echo 3 > /proc/sys/vm/drop_caches
// disable BE page cache
disable_storage_page_cache = true -
Workload Group設定を変更して、最大スループットを毎秒100Mに制限します。
alter workload group g2 properties('read_bytes_per_second'='104857600'); -
Doris システムテーブルを使用して、Workload Group の最大 IO スループットが毎秒 98M であることを確認します。
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 97.94296646118164 |
+--------------------+
1 row in set (0.03 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 98.37584781646729 |
+--------------------+
1 row in set (0.04 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 98.06641292572021 |
+--------------------+
1 row in set (0.02 sec) -
pidツールを使用して、プロセスの最大IOスループットが毎秒131Mであることを確認します。
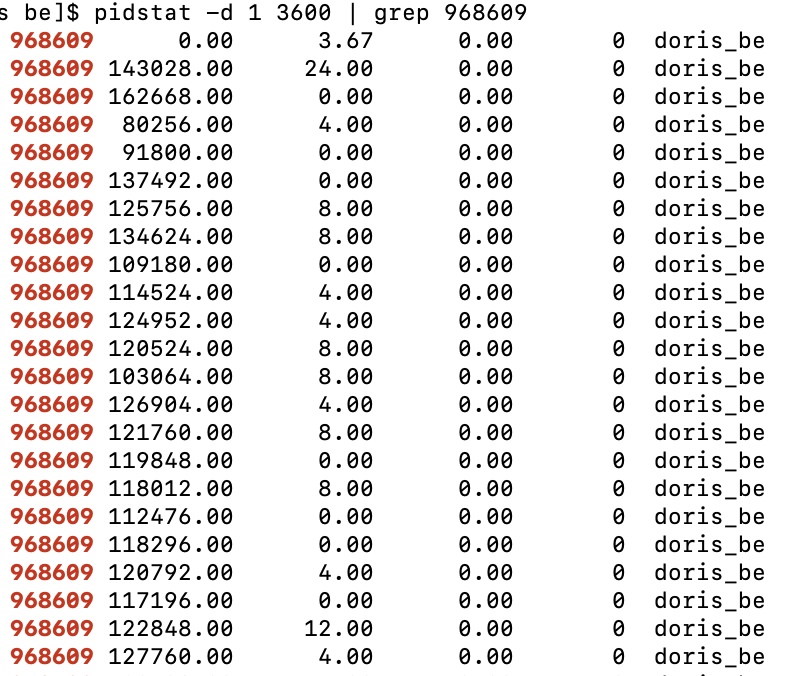
注記
-
システムテーブルのLOCAL_SCAN_BYTES_PER_SECONDフィールドは、プロセスレベルでの現在のWorkload Groupの統計の要約値を表します。例えば、12個のファイルパスが設定されている場合、LOCAL_SCAN_BYTES_PER_SECONDはこれら12個のファイルパスの最大IO値です。各ファイルパスのIOスループットを個別に確認したい場合は、Grafanaで詳細値を確認できます。
-
オペレーティングシステムとDorisのPage Cacheの存在により、LinuxのIO監視スクリプトを通じて観測されるIOは、通常システムテーブルで確認されるIOより小さくなります。
リモートIOの制限
BrokerLoadとS3Loadは大規模データロードでよく使用される手法です。ユーザーはまずデータをHDFSまたはS3にアップロードし、その後BrokerLoadとS3Loadを使用してデータを並列でロードできます。ロードプロセスを高速化するため、DorisはマルチスレッドでHDFS/S3からデータを取得しますが、これによりHDFS/S3に大きな負荷がかかり、HDFS/S3で実行されている他のジョブが不安定になる可能性があります。
他のワークロードへの影響を軽減するため、Workload Groupのリモート IO制限機能を使用して、HDFS/S3からのロードプロセス中に使用される帯域幅を制限できます。これにより、他のビジネス操作への影響を軽減できます。
テスト環境
1台のFEと1台のBEが同一マシンにデプロイされ、16コア64GBのメモリで構成されています。テストデータはclickbenchデータセットで、テスト前にデータセットをS3にアップロードする必要があります。アップロード時間を考慮して、1000万行のデータのみをアップロードし、TVF機能を使用してS3からデータをクエリします。
アップロードが成功した後、コマンドを使用してスキーマ情報を確認できます。
```sql
DESC FUNCTION s3 (
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
);
```
リモート読み取りIOを制限せずにテスト
-
clickbenchテーブルでフルテーブルスキャンを実行するシングルスレッドテストを開始します。
// Set the operation to only scan the data without returning results.
set dry_run_query = true;
SELECT * FROM s3(
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
); -
システムテーブルを使用して現在のリモートIO スループットを確認します。このクエリのリモートIOスループットは1秒あたり837MBであることが示されています。ここでの実際のIOスループットは環境に大きく依存することに注意してください。BEをホストするマシンが外部ストレージへの帯域幅が制限されている場合、実際のスループットはより低くなる可能性があります。
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 837 |
+---------+
1 row in set (0.104 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 867 |
+---------+
1 row in set (0.070 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 867 |
+---------+
1 row in set (0.186 sec) -
sar コマンド(sar -n DEV 1 3600)を使用してマシンのネットワーク帯域幅を監視します。マシンレベルでの最大ネットワーク帯域幅が1秒あたり1033 MBであることを示しています。 出力の最初の列は、マシン上の特定のネットワークインターフェースが1秒あたりに受信するバイト数を、1秒あたりKB単位で表しています。
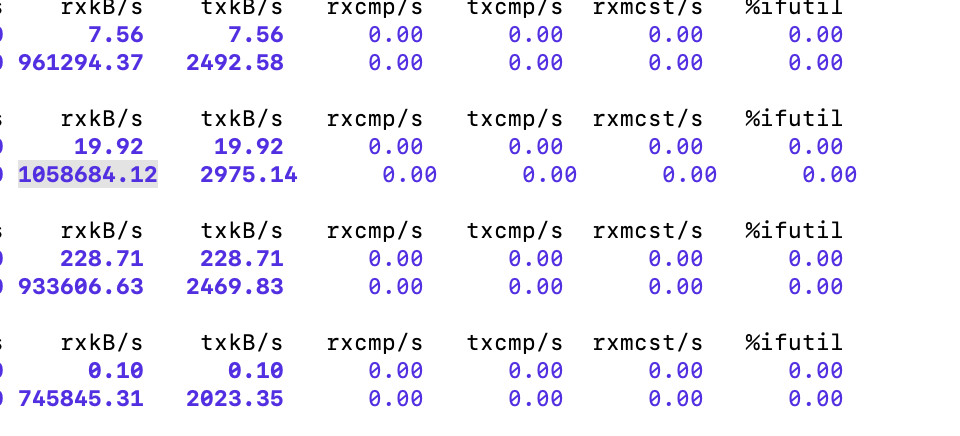
リモートread IOの制限をテストする
-
Workload Group設定を変更して、リモートread IOスループットを1秒あたり100Mに制限します。
alter workload group normal properties('remote_read_bytes_per_second'='104857600'); -
単一の同時実行フルテーブルスキャンクエリを開始します。
set dry_run_query = true;
SELECT * FROM s3(
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
); -
システムテーブルを使用して、現在のリモート読み取りIOスループットを確認します。この時点で、IOスループットは約100M程度で、いくらかの変動があります。これらの変動は現在のアルゴリズム設計の影響を受けており、通常は短時間でピークに達し、長期間持続することはなく、これは正常と考えられます。
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 56 |
+---------+
1 row in set (0.010 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 131 |
+---------+
1 row in set (0.009 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 111 |
+---------+
1 row in set (0.009 sec) -
sarコマンド(sar -n DEV 1 3600)を使用して、現在のネットワークカードの受信トラフィックを監視します。最初の列は1秒あたりに受信されるデータ量を表します。観測された最大値は現在207M/秒であり、read IO制限が有効であることを示しています。ただし、sarコマンドはマシンレベルのトラフィックを反映するため、観測された値はDorisが報告する値よりもわずかに高くなっています。
よくある質問
- CPU hard limit設定が有効にならないのはなぜですか?
- これは通常、以下の理由によって引き起こされます:
- 環境の初期化に失敗しました。Doris CGoupパス下の2つの設定ファイルを確認する必要があります。
ここでは、CGroup V1バージョンを例に取ります。ユーザーがDoris CGoupパスを
/sys/fs/cgroup/cpu/doris/として指定している場合、 まず/sys/fs/cgroup/cpu/doris/query/1/tasksの内容にWorkload Groupに対応するスレッドIDが含まれているかを確認する必要があります。 パス内の「1」はWorkload Group IDを表し、top -H -b -n 1 -p pidコマンドを実行してWorkload GroupのスレッドIDを見つけることで取得できます。 確認後、Workload GroupのスレッドIDがtasksファイルに書き込まれていることを確認してください。 次に、/sys/fs/cgroup/cpu/doris/query/1/cpu.cfs_quota_usの値が-1かどうかを確認します。-1の場合、CPU hard limit設定が有効になっていないことを意味します。 - Doris BEプロセスのCPU使用量が、Workload Groupに設定されたCPU hard limitよりも高い。
これは予期される動作です。Workload Groupによって管理されるCPUは主にクエリスレッドとLoadのmemtable flushスレッド用だからです。
ただし、BEプロセスには通常、Compactionなど、CPUを消費する他のコンポーネントもあります。
そのため、プロセスのCPU使用量は一般的にWorkload Groupに設定された制限よりも高くなります。
クエリ負荷のみにストレスをかけるテスト用Workload Groupを作成し、
システムテーブル
information_schema.workload_group_resource_usageを通じてWorkload GroupのCPU使用量を確認できます。 このテーブルはWorkload GroupのCPU使用量のみを記録し、バージョン2.1.6以降でサポートされています。 - 一部のユーザーが
cpu_resource_limitを設定している場合。まず、show property for jack like 'cpu_resource_limit'を実行して、 ユーザーjackのプロパティでこのパラメータが設定されているかを確認します。 次に、show variables like 'cpu_resource_limit'を実行して、セッション変数でこのパラメータが設定されているかを確認します。 このパラメータのデフォルト値は-1で、設定されていないことを示します。 このパラメータを設定すると、クエリはWorkload Groupによって管理されない独立したスレッドプールによって処理されます。このパラメータを直接変更すると、本番環境の安定性に影響を与える可能性があります。 このパラメータで設定されたクエリ負荷をWorkload Groupの管理下に段階的に移行することをお勧めします。 このパラメータの現在の代替手段はセッション変数num_scanner_threadsです。主なプロセスは以下の通りです: まず、cpu_resource_limitを設定したユーザーをいくつかのバッチに分割します。最初のバッチのユーザーを移行する際、 これらのユーザーのセッション変数num_scanner_threadsを1に変更します。次に、これらのユーザーにWorkload Groupを割り当てます。その後、cpu_resource_limitを-1に変更し、一定期間クラスターの安定性を観察します。クラスターが安定している場合、次のバッチのユーザーの移行を続行します。
- 環境の初期化に失敗しました。Doris CGoupパス下の2つの設定ファイルを確認する必要があります。
ここでは、CGroup V1バージョンを例に取ります。ユーザーがDoris CGoupパスを
- デフォルトのWorkload Groups数が15に制限されているのはなぜですか?
- Workload Groupは主に単一マシン上でのリソース分割に使用されます。
1台のマシン上で多数のWorkload Groupが作成されると、各Workload Groupが受け取るリソースは非常に少なくなります。
ユーザーが実際にこれほど多くのWorkload Groupを作成する必要がある場合、
クラスターを複数のBEグループに分割し、各BEグループに異なるWorkload Groupを作成することを検討できます。
また、FE設定
workload_group_max_numを変更することで、この制限を一時的に回避することもできます。
- 多数のWorkload Groupを設定後に「Resource temporarily unavailable」エラーが発生するのはなぜですか?
- 各Workload Groupは独立したスレッドプールに対応します。 Workload Groupを多数作成すると、BEプロセスが過度に多くのスレッドを開始しようとし、 オペレーティングシステムがプロセスに許可する最大スレッド数を超える可能性があります。 この問題を解決するには、システム環境設定を変更してBEプロセスがより多くのスレッドを作成できるようにすることができます。