
ログストレージと分析 | 実践ガイド
ログはシステムの重要なイベントを記録し、イベントの主体、時刻、場所、内容などの重要な情報を含んでいます。運用における可観測性、ネットワークセキュリティ監視、ビジネス分析の多様なニーズに応えるため、企業は散在するログを収集して集中保存、クエリ、分析を行い、ログデータからさらなる価値のあるコンテンツを抽出する必要がある場合があります。
このシナリオにおいて、Apache Dorisは対応するソリューションを提供します。ログシナリオの特性を念頭に置き、Apache Dorisは転置インデックスと超高速全文検索機能を追加し、書き込みパフォーマンスとストレージ容量を極限まで最適化しました。これにより、ユーザーはApache Dorisをベースとしたオープンで高性能、コスト効果が高く、統一されたログ保存・分析プラットフォームを構築できます。
このソリューションに焦点を当て、本章では以下の3つのセクションを含みます:
-
全体アーキテクチャ: このセクションでは、Apache Doris上に構築されたログ保存・分析プラットフォームのコアコンポーネントとアーキテクチャについて説明します。
-
機能と利点: このセクションでは、Apache Doris上に構築されたログ保存・分析プラットフォームの機能と利点について説明します。
-
運用ガイド: このセクションでは、Apache Dorisをベースとしたログ保存・分析プラットフォームの構築方法について説明します。
全体アーキテクチャ
以下の図は、Apache Doris上に構築されたログ保存・分析プラットフォームのアーキテクチャを示しています:

このアーキテクチャには以下の3つの部分が含まれます:
-
ログ収集と前処理: 様々なログ収集ツールがHTTP APIを通じてログデータをApache Dorisに書き込むことができます。
-
ログ保存・分析エンジン: Apache Dorisは高性能で低コストの統一されたログ保存を提供し、SQLインターフェースを通じて豊富な検索・分析機能を提供します。
-
ログ分析・アラートインターフェース: 様々なログ検索・分析ツールが標準SQLインターフェースを通じてApache Dorisにクエリを実行でき、ユーザーにシンプルで使いやすいインターフェースを提供します。
機能と利点
以下の図は、Apache Doris上に構築されたログ保存・分析プラットフォームのアーキテクチャを示しています:
-
高スループット、低レイテンシログ書き込み: 1日あたり数百TBおよびGB/sレベルでのログデータの安定した書き込みをサポートし、同時に1秒以内のレイテンシを維持します。
-
大量ログデータのコスト効果的な保存: ペタバイトスケールのストレージをサポートし、Elasticsearchと比較してストレージコストを60%から80%節約し、コールドデータをS3/HDFSに保存することでストレージコストをさらに50%削減します。
-
高性能ログ全文検索・分析: 転置インデックスと全文検索をサポートし、一般的なログクエリ(キーワード検索、トレンド分析など)に対して秒レベルの応答時間を提供します。
-
オープンでユーザーフレンドリーな上流・下流エコシステム: Stream LoadのユニバーサルHTTP APIを通じてLogstash、Filebeat、Fluentbit、Kafkaなどの一般的なログ収集システムやデータソースとの上流統合、および標準MySQLプロトコルと構文を使用して可観測性プラットフォームGrafana、BIアナリティクスSuperset、KibanaのようなDoris WebUIログ検索などの様々なビジュアル分析UIとの下流統合。
コスト効果的なパフォーマンス
Benchmarkテストと本番環境での検証後、Apache Doris上に構築されたログ保存・分析プラットフォームは、Elasticsearchと比較して5から10倍のコストパフォーマンス優位性を持っています。Apache Dorisのパフォーマンス上の利点は主に、世界をリードする高性能ストレージ・クエリエンジンと、ログシナリオに特化した最適化によるものです:
-
書き込みスループットの向上: Elasticsearchの書き込みパフォーマンスボトルネックは、データ解析と転置インデックス構築のためのCPU消費にあります。これと比較して、Apache Dorisは2つの側面で書き込みを最適化しています:SIMDおよびその他のCPUベクター命令を使用してJSONデータ解析速度とインデックス構築パフォーマンスを向上させ、前方インデックスなどの不要なデータ構造を除去することでログシナリオ向けの転置インデックス構造を簡素化し、インデックス構築の複雑さを効果的に削減しています。同じリソースで、Apache Dorisの書き込みパフォーマンスはElasticsearchより3から5倍高くなっています。
-
ストレージコストの削減: Elasticsearchでのストレージボトルネックは、前方インデックス、転置インデックス、Docvalue列の複数のストレージ形式と、汎用圧縮アルゴリズムの相対的に低い圧縮率にあります。これに対し、Apache Dorisはストレージにおいて以下の最適化を行っています:前方インデックスを除去することでインデックスデータサイズを30%削減;列指向ストレージとZstandard圧縮アルゴリズムを使用して5から10倍の圧縮率を達成し、これはElasticsearchの1.5倍を大幅に上回る;ログデータにおいてコールドデータへのアクセス頻度は非常に低く、Apache Dorisのホット・コールドデータ階層化機能により、定義された期間を超えたログを自動的により低コストのオブジェクトストレージに保存し、コールドデータのストレージコストを70%以上削減できます。同じ生データに対して、DorisのストレージコストはElasticsearchの約20%にすぎません。
強力な分析機能
Apache Dorisは標準SQLをサポートし、MySQLプロトコルと構文と互換性があります。したがって、Apache Doris上に構築されたログシステムは、ログ分析にSQLを使用でき、ログシステムに以下の利点をもたらします:
-
使いやすさ: エンジニアやデータアナリストはSQLに非常に精通しており、彼らの専門知識を再利用でき、新しい技術スタックを学ぶ必要なく迅速に開始できます。
-
豊富なエコシステム: MySQLエコシステムはデータベース分野で最も広く使用されている言語であり、MySQLエコシステムとシームレスに統合・適用されます。DorisはMySQLコマンドラインや様々なGUIツール、BIツール、その他のビッグデータエコシステムツールを活用して、より複雑で多様なデータ処理・分析ニーズに対応できます。
-
強力な分析機能: SQLはデータベースとビッグデータ分析のデファクトスタンダードとなっており、検索、集計、マルチテーブルJOIN、サブクエリ、UDF、論理ビュー、マテリアライズドビュー、および様々なデータ分析機能をサポートする強力な表現力と機能を持っています。
柔軟なSchema
これはJSON形式の半構造化ログの典型的な例です。トップレベルのフィールドは、timestamp、source、node、component、level、clientRequestID、message、propertiesなどの固定フィールドで、すべてのログエントリに存在します。properties.sizeやproperties.formatなどのpropertiesのネストされたフィールドはより動的であり、各ログのフィールドは異なる場合があります。
{
"timestamp": "2014-03-08T00:50:03.8432810Z",
"source": "ADOPTIONCUSTOMERS81",
"node": "Engine000000000405",
"level": "Information",
"component": "DOWNLOADER",
"clientRequestId": "671db15d-abad-94f6-dd93-b3a2e6000672",
"message": "Downloading file path: benchmark/2014/ADOPTIONCUSTOMERS81_94_0.parquet.gz",
"properties": {
"size": 1495636750,
"format": "parquet",
"rowCount": 855138,
"downloadDuration": "00:01:58.3520561"
}
}
Apache Dorisは、Flexible Schemaログデータに対して以下の複数の側面でサポートを提供します:
-
トップレベルフィールドの変更に対して、Light Schema Changeを使用してカラムの追加や削除、およびインデックスの追加や削除を行うことができ、スキーマ変更を秒単位で完了できます。ログプラットフォームを計画する際、ユーザーはどのフィールドにインデックスが必要かを考慮するだけで済みます。
-
propertiesに類似した拡張フィールドに対して、ネイティブの半構造化データ型
VARIANTが提供されており、任意のJSONデータを書き込み、JSON内のフィールド名と型を自動認識し、頻繁に出現するフィールドを自動的に分割して列指向ストレージにして後続の分析に使用できます。さらに、VARIANTは転置インデックスを作成して内部フィールドのクエリと検索を高速化できます。
ElasticsearchのDynamic Mappingと比較して、Apache DorisのFlexible Schemaには以下の利点があります:
-
フィールドが複数の型を持つことを許可し、
VARIANTがフィールドの競合と型昇格を自動的に処理し、ログデータの反復的な変更により適応します。 -
VARIANTは出現頻度の低いフィールドを自動的にカラムストアにマージし、過度のフィールド、メタデータ、またはカラムによるパフォーマンス問題を回避します。 -
カラムの動的追加だけでなく、動的削除も可能で、インデックスも動的に追加または削除できるため、Elasticsearchのように最初にすべてのフィールドにインデックスを作成する必要がなく、不要なコストを削減します。
運用ガイド
ステップ1: リソース見積もり
クラスター展開前に、サーバーに必要なハードウェアリソースを見積もる必要があります。以下の手順に従ってください:
- 以下の計算式でデータ書き込みのリソースを見積もります:
-
平均書き込みスループット = 1日のデータ増分 / 86400 s -
ピーク書き込みスループット = 平均書き込みスループット \* ピーク書き込みスループットと平均書き込みスループットの比率 -
ピーク書き込みスループットに必要なCPUコア数 = ピーク書き込みスループット / シングルコアCPUの書き込みスループット
-
計算式でデータストレージのリソースを見積もります:
ストレージ容量 = 1日のデータ増分 / データ圧縮率 * データコピー数 * データ保存期間 -
データクエリのリソースを見積もります。データクエリのリソースはクエリ量と複雑さに依存します。初期段階ではデータクエリ用にCPUリソースの50%を予約し、実際のテスト結果に応じて調整することを推奨します。
-
計算結果を以下のように統合します:
-
ステップ1とステップ3で計算したCPUコア数をBEサーバーのCPUコア数で割ることで、必要なBEサーバー数を得ることができます。
-
BEサーバー数とステップ2の計算結果に基づいて、各BEサーバーに必要なストレージ容量を見積もります。
-
各BEサーバーに必要なストレージ容量を4~12個のデータディスクに配分することで、単一データディスクに必要なストレージ容量を得ることができます。
-
例えば、1日のデータ増分が100 TB、データ圧縮率が5、データコピー数が1、ホットデータの保存期間が3日、コールドデータの保存期間が30日、ピーク書き込みスループットと平均書き込みスループットの比率が200%、シングルコアCUPの書き込みスループットが10 MB/s、データクエリ用にCPUリソースの50%を予約する場合、以下のように見積もることができます:
-
FEサーバー3台が必要で、それぞれ16コアCPU、64 GBメモリ、1 100 GB SSDディスクで構成されます。
-
BEサーバー15台が必要で、それぞれ32コアCPU、256 GBメモリ、10 600 GB SSDディスクで構成されます。
-
S3オブジェクトストレージ容量600 TB
上記の例における指標の値とその計算方法については、以下の表を参照してください。
| 指標(単位) | 値 | 説明 |
|---|---|---|
| 1日のデータ増分(TB) | 100 | 実際のニーズに応じて値を指定してください。 |
| データ圧縮率 | 5 | 実際のニーズに応じて値を指定してください。通常3~10の範囲です。データにはインデックスデータが含まれることに注意してください。 |
| データコピー数 | 1 | 実際のニーズに応じて値を指定してください。1、2、または3にできます。デフォルト値は1です。 |
| ホットデータの保存期間(日) | 3 | 実際のニーズに応じて値を指定してください。 |
| コールドデータの保存期間(日) | 30 | 実際のニーズに応じて値を指定してください。 |
| データ保存期間 | 33 | 計算式:ホットデータの保存期間 + コールドデータの保存期間 |
| ホットデータの見積もりストレージ容量(TB) | 60 | 計算式:1日のデータ増分 / データ圧縮率 * データコピー数 * ホットデータの保存期間 |
| コールドデータの見積もりストレージ容量(TB) | 600 | 計算式:1日のデータ増分 / データ圧縮率 * データコピー数 * コールドデータの保存期間 |
| ピーク書き込みスループットと平均書き込みスループットの比率 | 200% | 実際のニーズに応じて値を指定してください。デフォルト値は200%です。 |
| BEサーバーのCPUコア数 | 32 | 実際のニーズに応じて値を指定してください。デフォルト値は32です。 |
| 平均書き込みスループット(MB/s) | 1214 | 計算式:1日のデータ増分 / 86400 s |
| ピーク書き込みスループット(MB/s) | 2427 | 計算式:平均書き込みスループット * ピーク書き込みスループットと平均書き込みスループットの比率 |
| ピーク書き込みスループットに必要なCPUコア数 | 242.7 | 計算式:ピーク書き込みスループット / シングルコアCPUの書き込みスループット |
| データクエリ用に予約するCPUリソースの割合 | 50% | 実際のニーズに応じて値を指定してください。デフォルト値は50%です。 |
| 見積もりBEサーバー数 | 15.2 | 計算式:ピーク書き込みスループットに必要なCPUコア数 / BEサーバーのCPUコア数 /(1 - データクエリ用に予約するCPUリソースの割合) |
| 四捨五入したBEサーバー数 | 15 | 計算式:MAX (データコピー数、見積もりBEサーバー数) |
| 各BEサーバーの見積もりデータストレージ容量(TB) | 5.7 | 計算式:ホットデータの見積もりストレージ容量 / 見積もりBEサーバー数 /(1 - 30%)、ここで30%は予約ストレージ容量の割合を表します。I/O能力を向上させるため、各BEサーバーに4~12個のデータディスクをマウントすることを推奨します。 |
ステップ2: クラスターの展開
リソース見積もり後、クラスターを展開する必要があります。物理環境と仮想環境の両方で手動展開することを推奨します。手動展開については、Manual Deploymentを参照してください。
ステップ3: FEおよびBE設定の最適化
クラスター展開完了後、ログストレージと分析のシナリオにより適合するよう、フロントエンドとバックエンドの設定パラメータをそれぞれ最適化する必要があります。
FE設定の最適化
FE設定フィールドはfe/conf/fe.confにあります。FE設定を最適化するには、以下の表を参照してください。
| 最適化する設定フィールド | 説明 |
|---|---|
max_running_txn_num_per_db = 10000 | 高同時インポートトランザクションに適応するためパラメータ値を増加します。 |
streaming_label_keep_max_second = 3600 label_keep_max_second = 7200 | 高メモリ使用量を伴う高頻度インポートトランザクションを処理するため保持時間を増加します。 |
enable_round_robin_create_tablet = true | Tablets作成時に、均等に分散するRound Robin戦略を使用します。 |
tablet_rebalancer_type = partition | Tabletsのバランシング時に、各パーティション内で均等に分散する戦略を使用します。 |
autobucket_min_buckets = 10 | 自動バケット化の最小バケット数を1から10に増加し、ログ量増加時の不十分なバケット数を回避します。 |
max_backend_heartbeat_failure_tolerance_count = 10 | ログシナリオでは、BEサーバーが高負荷によりタイムアウトが発生する可能性があるため、許容回数を1から10に増加します。 |
詳細については、FE Configurationを参照してください。
BE設定の最適化
BE設定フィールドはbe/conf/be.confにあります。BE設定を最適化するには、以下の表を参照してください。
| モジュール | 最適化する設定フィールド | 説明 |
|---|---|---|
| Storage | storage_root_path = /path/to/dir1;/path/to/dir2;...;/path/to/dir12 | ディスクディレクトリ上のホットデータのストレージパスを設定します。 |
| - | enable_file_cache = true | ファイルキャッシュを有効化します。 |
| - | file_cache_path = [{"path": "/mnt/datadisk0/file_cache", "total_size":53687091200, "query_limit": "10737418240"},{"path": "/mnt/datadisk1/file_cache", "total_size":53687091200,"query_limit": "10737418240"}] | コールドデータのキャッシュパスと関連設定を以下の具体的な設定で構成します:path: キャッシュパスtotal_size: キャッシュパスの総サイズ(バイト単位)。53687091200バイトは50 GBに相当query_limit: 1回のクエリでキャッシュパスから照会できるデータの最大量(バイト単位)。10737418240バイトは10 GBに相当 |
| Write | write_buffer_size = 1073741824 | 書き込みバッファのファイルサイズを増加し、小さなファイルとランダムI/O操作を削減してパフォーマンスを向上させます。 |
| - | max_tablet_version_num = 20000 | テーブル作成のtime_series compaction戦略と連携し、より多くのバージョンが一時的にマージされずに残ることを許可します |
| Compaction | max_cumu_compaction_threads = 8 | CPUコア数 / 4に設定し、CPUリソースの1/4を書き込み、1/4をバックグラウンドcompaction、2/1をクエリとその他の操作に使用することを示します。 |
| - | inverted_index_compaction_enable = true | 転置インデックスcompactionを有効化し、compaction中のCPU消費を削減します。 |
| - | enable_segcompaction = false enable_ordered_data_compaction = false | ログシナリオでは不要な2つのcompaction機能を無効化します。 |
| - | enable_compaction_priority_scheduling = false | 低優先度compactionは単一ディスクで2タスクに制限され、compactionの速度に影響する可能性があります。 |
| - | total_permits_for_compaction_score = 200000 | このパラメータはメモリ制御に使用され、メモリ時系列戦略下では、パラメータ自体がメモリを制御できます。 |
| Cache | disable_storage_page_cache = true inverted_index_searcher_cache_limit = 30% | ログデータの大容量と限定的なキャッシュ効果により、データキャッシュからインデックスキャッシュに切り替えます。 |
| - | inverted_index_cache_stale_sweep_time_sec = 3600 index_cache_entry_stay_time_after_lookup_s = 3600 | インデックスキャッシュをメモリ内に最大1時間維持します。 |
| - | enable_inverted_index_cache_on_cooldown = trueenable_write_index_searcher_cache = false | インデックスアップロード中のコールドデータストレージの自動キャッシュを有効化します。 |
| - | tablet_schema_cache_recycle_interval = 3600 segment_cache_capacity = 20000 | 他のキャッシュによるメモリ使用量を削減します。 |
| - | inverted_index_ram_dir_enable = true | 一時的なインデックスファイル書き込みによるIOオーバーヘッドを削減します。 |
| Thread | pipeline_executor_size = 24 doris_scanner_thread_pool_thread_num = 48 | 32コアCPUの計算スレッドとI/Oスレッドをコア数に比例して設定します。 |
| - | scan_thread_nice_value = 5 | クエリI/Oスレッドの優先度を下げ、書き込みパフォーマンスと適時性を確保します。 |
| Other | string_type_length_soft_limit_bytes = 10485760 | 文字列型データの長さ制限を10 MBに増加します。 |
| - | trash_file_expire_time_sec = 300 path_gc_check_interval_second = 900 path_scan_interval_second = 900 | ゴミファイルのリサイクルを高速化します。 |
詳細については、BE Configurationを参照してください。
ステップ4: テーブルの作成
ログデータの書き込みとクエリの両方の特徴により、パフォーマンスを向上させるため、テーブルに対象を絞った設定を行うことを推奨します。
データパーティショニングとバケット化の設定
-
データパーティショニングの場合:
-
レンジパーティショニング (
PARTITION BY RANGE(ts)) と 動的パーティション ("dynamic_partition.enable" = "true") を有効化し、日単位で自動管理します。 -
最新のNログエントリの検索高速化のため、DATETIME型のフィールドをキー (
DUPLICATE KEY(ts)) として使用します。
-
-
データバケット化の場合:
-
バケット数をクラスター内の総ディスク数のおよそ3倍に設定し、各バケットが圧縮後約5GBのデータを含むようにします。
-
単一tabletインポートと組み合わせてバッチ書き込み効率を最適化するため、Random戦略 (
DISTRIBUTED BY RANDOM BUCKETS 60) を使用します。
-
詳細については、Data Partitioningを参照してください。
圧縮パラメータの設定
データ圧縮効率を向上させるため、zstd圧縮アルゴリズム ("compression" = "zstd") を使用します。
compactionパラメータの設定
compactionフィールドを以下のように設定します:
- 高スループットログ書き込みに重要な書き込み増幅を削減するため、time_series戦略 (
"compaction_policy" = "time_series") を使用します。
インデックスパラメータの設定
インデックスフィールドを以下のように設定します:
-
頻繁にクエリされるフィールドにインデックスを作成します (
USING INVERTED)。 -
全文検索が必要なフィールドについては、ほとんどの要件を満たすparserフィールドをunicodeとして指定します。フレーズクエリのサポートが必要な場合はsupport_phraseフィールドをtrueに設定し、不要な場合はfalseに設定してストレージ容量を削減します。
ストレージパラメータの設定
ストレージポリシーを以下のように設定します:
-
ホットデータのストレージについて、クラウドストレージを使用する場合はデータコピー数を1に設定し、物理ディスクを使用する場合はデータコピー数を少なくとも2に設定します (
"replication_num" = "2")。 -
log_s3のストレージ場所を設定し (
CREATE RESOURCE "log_s3")、log_policy_3dayポリシーを設定します (CREATE STORAGE POLICY log_policy_3day)。データは3日後に冷却されlog_s3の指定されたストレージ場所に移動されます。以下のコードを参照してください。
CREATE DATABASE log_db;
USE log_db;
CREATE RESOURCE "log_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "your_endpoint_url",
"s3.region" = "your_region",
"s3.bucket" = "your_bucket",
"s3.root.path" = "your_path",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk"
);
CREATE STORAGE POLICY log_policy_3day
PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "259200"
);
CREATE TABLE log_table
(
`ts` DATETIME,
`host` TEXT,
`path` TEXT,
`message` TEXT,
INDEX idx_host (`host`) USING INVERTED,
INDEX idx_path (`path`) USING INVERTED,
INDEX idx_message (`message`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true")
)
ENGINE = OLAP
DUPLICATE KEY(`ts`)
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY RANDOM BUCKETS 60
PROPERTIES (
"compression" = "zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "60",
"dynamic_partition.replication_num" = "2", -- unneccessary for the compute-storage coupled mode
"replication_num" = "2", -- unneccessary for the compute-storage coupled mode
"storage_policy" = "log_policy_3day" -- unneccessary for the compute-storage coupled mode
);
Step 5: ログの収集
テーブル作成の完了後、ログ収集を進めることができます。
Apache Dorisは、オープンで汎用性の高いStream HTTP APIを提供しており、これを通じてLogstash、Filebeat、Kafkaなどの人気のあるログコレクターと接続し、ログ収集作業を実行できます。このセクションでは、これらのログコレクターをStream HTTP APIを使用して統合する方法について説明します。
Logstashの統合
以下の手順に従ってください:
-
Logstash Doris Output pluginをダウンロードしてインストールします。以下の2つの方法のいずれかを選択できます:
-
ここをクリックしてダウンロードしてインストールします。
-
ソースコードからコンパイルし、以下のコマンドを実行してインストールします:
-
./bin/logstash-plugin install logstash-output-doris-1.2.0.gem
- Logstashを設定します。以下のフィールドを指定してください:
logstash.yml:データ書き込みパフォーマンスを向上させるために、Logstashバッチ処理ログのサイズとタイミングを設定するために使用されます。
pipeline.batch.size: 1000000
pipeline.batch.delay: 10000
logstash_demo.conf: 収集するログの具体的な入力パスとApache Dorisへの出力設定を構成するために使用されます。
input {
file {
path => "/path/to/your/log"
}
}
output {
doris {
http_hosts => [ "<http://fehost1:http_port>", "<http://fehost2:http_port>", "<http://fehost3:http_port">]
user => "your_username"
password => "your_password"
db => "your_db"
table => "your_table"
# doris stream load http headers
headers => {
"format" => "json"
"read_json_by_line" => "true"
"load_to_single_tablet" => "true"
}
# field mapping: doris fileld name => logstash field name
# %{} to get a logstash field, [] for nested field such as [host][name] for host.name
mapping => {
"ts" => "%{@timestamp}"
"host" => "%{[host][name]}"
"path" => "%{[log][file][path]}"
"message" => "%{message}"
}
log_request => true
log_speed_interval => 10
}
}
```
3. 以下のコマンドに従ってLogstashを実行し、ログを収集してApache Dorisに出力します。
```shell
./bin/logstash -f logstash_demo.conf
Logstash Doris Output pluginの詳細については、Logstash Doris Output Pluginを参照してください。
Filebeatの統合
以下の手順に従ってください:
-
Apache Dorisへの出力をサポートするFilebeatバイナリファイルを取得します。クリックしてダウンロードするか、Apache Dorisソースコードからコンパイルできます。
-
Filebeatを設定します。収集されるログの具体的な入力パスとApache Dorisへの出力設定を構成するために使用されるfilebeat_demo.ymlフィールドを指定します。
# input
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/to/your/log
multiline:
type: pattern
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}'
negate: true
match: after
skip_newline: true
processors:
- script:
lang: javascript
source: >
function process(event) {
var msg = event.Get("message");
msg = msg.replace(/\t/g, " ");
event.Put("message", msg);
}
- dissect:
# 2024-06-08 18:26:25,481 INFO (report-thread|199) [ReportHandler.cpuReport():617] begin to handle
tokenizer: "%{day} %{time} %{log_level} (%{thread}) [%{position}] %{content}"
target_prefix: ""
ignore_failure: true
overwrite_keys: true
# queue and batch
queue.mem:
events: 1000000
flush.min_events: 100000
flush.timeout: 10s
# output
output.doris:
fenodes: [ "http://fehost1:http_port", "http://fehost2:http_port", "http://fehost3:http_port" ]
user: "your_username"
password: "your_password"
database: "your_db"
table: "your_table"
# output string format
codec_format_string: '{"ts": "%{[day]} %{[time]}", "host": "%{[agent][hostname]}", "path": "%{[log][file][path]}", "message": "%{[message]}"}'
headers:
format: "json"
read_json_by_line: "true"
load_to_single_tablet: "true"
-
以下のコマンドに従ってFilebeatを実行し、ログを収集してApache Dorisに出力します。
chmod +x filebeat-doris-2.1.1
./filebeat-doris-2.1.1 -c filebeat_demo.yml
Filebeatの詳細については、Beats Doris Output Pluginを参照してください。
Kafkaの統合
JSON形式のログをKafkaのメッセージキューに書き込み、Kafka Routine Loadを作成し、Apache DorisがKafkaからデータを能動的に取得できるようにします。
以下の例を参照してください。property.*はLibrdkafkaクライアント関連の設定を表し、実際のKafkaクラスターの状況に応じて調整する必要があります。
CREATE ROUTINE LOAD load_log_kafka ON log_db.log_table
COLUMNS(ts, clientip, request, status, size)
PROPERTIES (
"max_batch_interval" = "60",
"max_batch_rows" = "20000000",
"max_batch_size" = "1073741824",
"load_to_single_tablet" = "true",
"format" = "json"
)
FROM KAFKA (
"kafka_broker_list" = "host:port",
"kafka_topic" = "log__topic_",
"property.group.id" = "your_group_id",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="GSSAPI",
"property.sasl.kerberos.service.name"="kafka",
"property.sasl.kerberos.keytab"="/path/to/xxx.keytab",
"property.sasl.kerberos.principal"="<xxx@yyy.com>"
);
<br />SHOW ROUTINE LOAD;
Kafkaについての詳細は、Routine Loadを参照してください。
カスタマイズされたプログラムを使用してログを収集する
一般的なログコレクターとの統合に加えて、Stream Load HTTP APIを使用してApache Dorisにログデータをインポートするプログラムをカスタマイズすることもできます。以下のコードを参照してください:
curl
--location-trusted
-u username:password
-H "format:json"
-H "read_json_by_line:true"
-H "load_to_single_tablet:true"
-H "timeout:600"
-T logfile.json
http://fe_host:fe_http_port/api/log_db/log_table/_stream_load
カスタムプログラムを使用する際は、以下の重要なポイントに注意してください:
-
HTTP認証にはBasic Authを使用し、echo -n 'username:password' | base64コマンドを使用して計算してください。
-
HTTPヘッダー「format:json」を設定して、データ形式をJSONとして指定してください。
-
HTTPヘッダー「read_json_by_line:true」を設定して、1行につき1つのJSONを指定してください。
-
HTTPヘッダー「load_to_single_tablet:true」を設定して、小さなファイルのインポートを減らすため、一度に1つのバケットにデータをインポートしてください。
-
クライアント側では100MBから1GBのサイズのバッチを書き込むことを推奨します。Apache Dorisバージョン2.1以降では、Group Commit機能を通じてクライアント側でバッチサイズを減らす必要があります。
ステップ6:ログのクエリと分析
ログのクエリ
Apache Dorisは標準SQLをサポートしているため、MySQLクライアントやJDBCを通じてクラスターに接続し、ログクエリ用のSQLを実行できます。
mysql -h fe_host -P fe_mysql_port -u your_username -Dyour_db_name
参考用の5つの一般的なSQLクエリコマンドを以下に示します:
- 最新の10件のログエントリを表示
SELECT * FROM your_table_name ORDER BY ts DESC LIMIT 10;
- ホストが8.8.8.8の最新10件のログエントリを取得する
SELECT * FROM your_table_name WHERE host = '8.8.8.8' ORDER BY ts DESC LIMIT 10;
- request フィールドにerrorまたは404を含む最新の10件のログエントリを取得します。以下のコマンドでは、MATCH_ANYはApache Dorisがフィールド内の任意のキーワードをマッチングするために使用する全文検索SQL構文です。
SELECT * FROM your_table_name WHERE message **MATCH_ANY** 'error 404'
ORDER BY ts DESC LIMIT 10;
- request フィールドに image と faq を含む最新の10件のログエントリを取得します。以下のコマンドでは、MATCH_ALL は Apache Doris で使用される全文検索 SQL 構文で、フィールド内のすべてのキーワードをマッチングするために使用されます。
SELECT * FROM your_table_name WHERE message **MATCH_ALL** 'image faq'
ORDER BY ts DESC LIMIT 10;
- リクエストフィールドにimageとfaqを含む最新の10件のエントリを取得します。以下のコマンドでは、MATCH_PHRASEはApache Dorisで使用される全文検索SQL構文で、フィールド内のすべてのキーワードをマッチングし、一貫した順序を要求します。以下の例では、a image faq bはマッチしますが、a faq image bはimageとfaqの順序が構文とマッチしないためマッチしません。
SELECT * FROM your_table_name WHERE message **MATCH_PHRASE** 'image faq'
ORDER BY ts DESC LIMIT 10;
ログを視覚的に分析する
一部のサードパーティベンダーは、Apache Dorisをベースとした視覚的ログ分析開発プラットフォームを提供しており、これらにはKibana Discoverに類似したログ検索・分析インターフェースが含まれています。これらのプラットフォームは、直感的でユーザーフレンドリーな探索的ログ分析インタラクションを提供します。
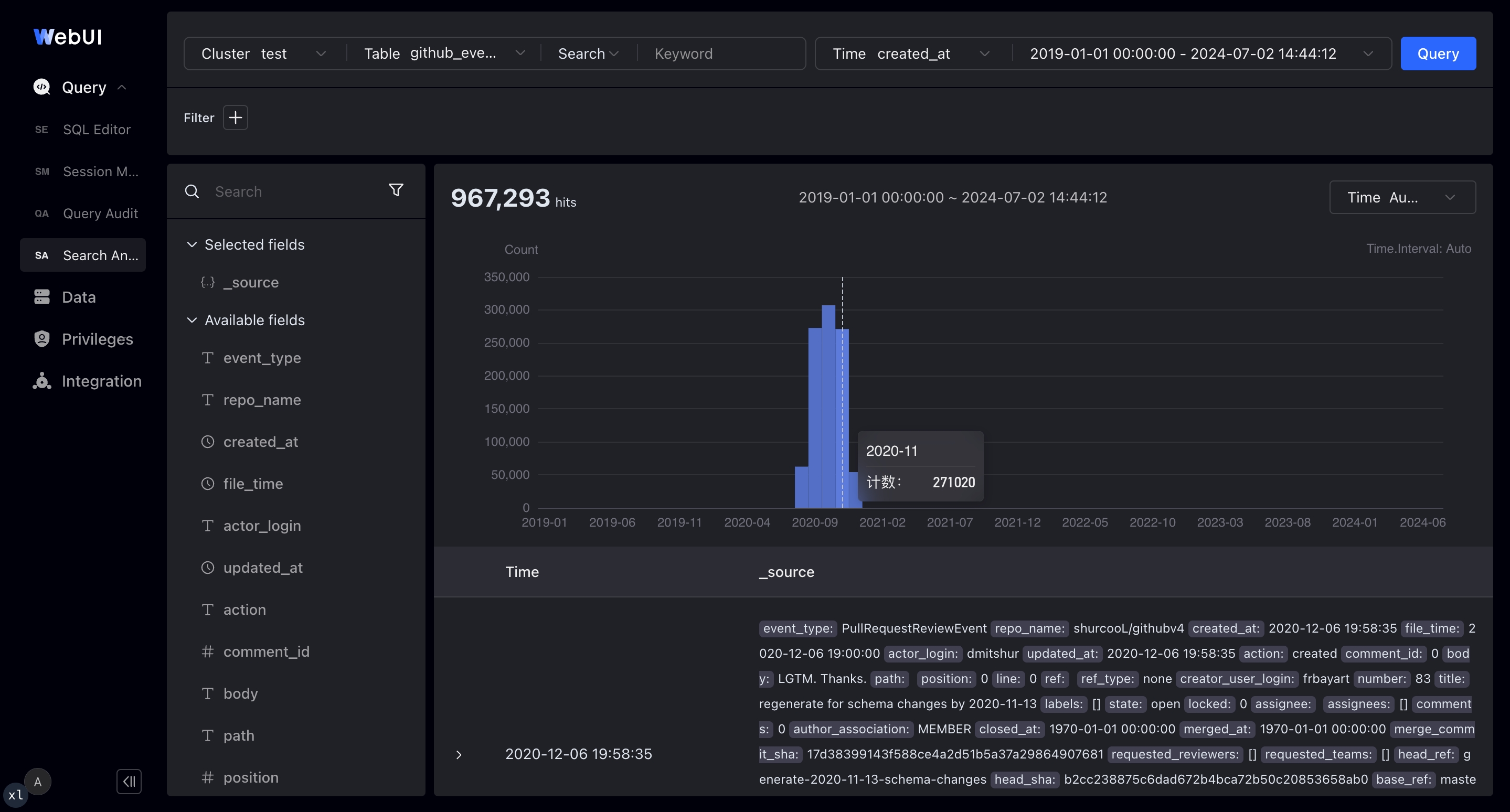
-
全文検索とSQLモードのサポート
-
タイムボックスとヒストグラムによるクエリログ時間枠の選択サポート
-
詳細なログ情報の表示、JSONやテーブルに展開可能
-
ログデータコンテキストでフィルタ条件を追加・削除するインタラクティブなクリック操作
-
異常を発見し、さらに詳細な分析を行うための検索結果における上位フィールド値の表示
詳細については、dev@doris.apache.orgまでお問い合わせください。