
リリース 2.0.0
6ヶ月のコーディング、テスト、微調整を経て、Apache Doris 2.0.0が本番環境対応となったことを発表できることを、私たちは非常に嬉しく思います。プロジェクトに4100を超える最適化と修正を貢献した275名のコミッターに特別な感謝を申し上げます。
この新バージョンのハイライト:
- データクエリが10倍高速化
- ログ分析と連合クエリ機能の強化
- より効率的なデータ書き込みと更新
- 改善されたマルチテナントとリソース分離メカニズム
- リソースの弾性スケーリングとストレージ・コンピュート分離の進歩
- より高い使いやすさを実現するエンタープライズ向け機能
ダウンロード: https://doris.apache.org/download
GitHubソースコード: https://github.com/apache/doris/releases/tag/2.0.0-rc04
パフォーマンスの10倍向上
SSB-FlatとTPC-Hベンチマークにおいて、Apache Doris 2.0.0はApache Dorisの初期バージョンと比較して10倍以上高速なクエリパフォーマンスを実現しました。
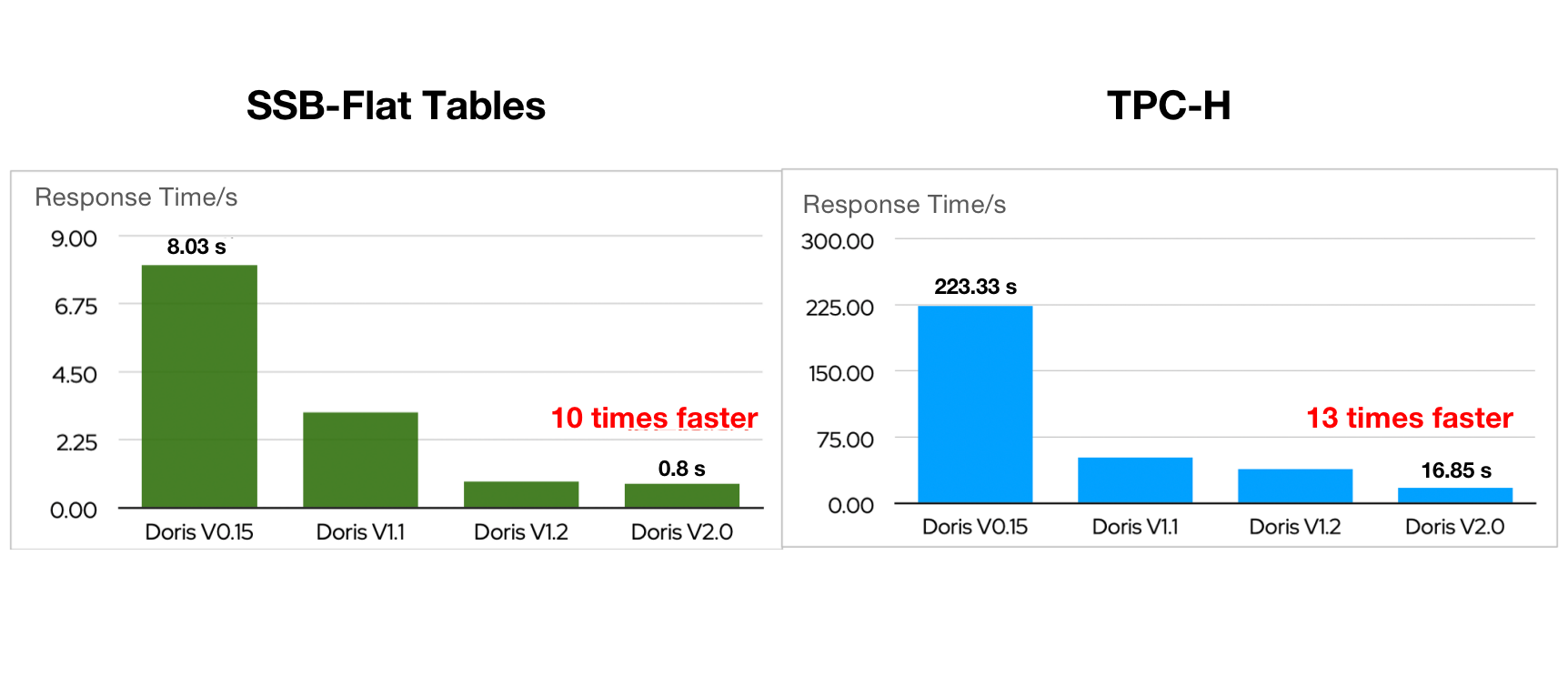
これは、より賢いクエリオプティマイザー、転置インデックス、並列実行モデル、および高同時性ポイントクエリをサポートする一連の新機能の導入により実現されました。
より賢いクエリオプティマイザー
全く新しいクエリオプティマイザーであるNereidsは、より豊富な統計ベースを持ち、Cascadesフレームワークを採用しています。ほとんどのクエリシナリオで自己調整が可能で、TPC-DSの99のSQLすべてをサポートするため、ユーザーは微調整やSQL書き換えなしに高性能を期待できます。
TPC-Hテストでは、人間の介入なしで、Nereidsが古いクエリオプティマイザーを大幅に上回る性能を示しました。100名を超えるユーザーがApache Doris 2.0.0を本番環境で試用し、その大部分がクエリ実行の大幅な高速化を報告しました。
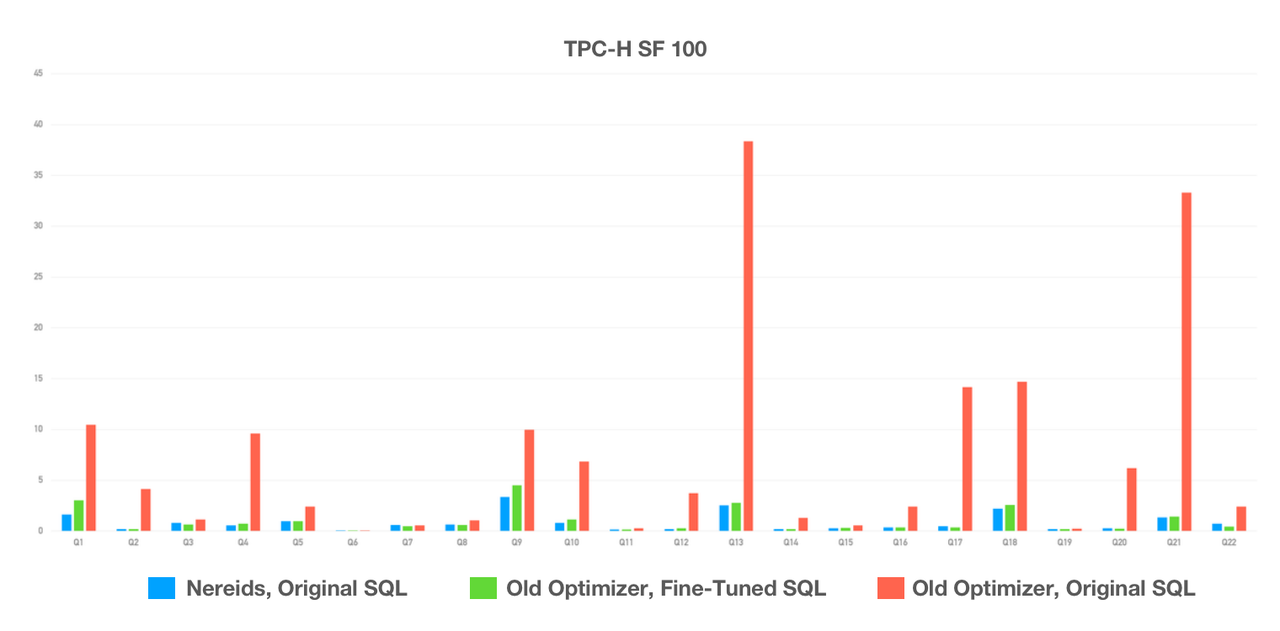
ドキュメント: https://doris.apache.org/docs/dev/query-acceleration/nereids/
NereidsはApache Doris 2.0.0でデフォルトで有効になっています: SET enable_nereids_planner=true。NereidsはAnalyzeコマンドを呼び出すことで統計データを収集します。
転置インデックス
Apache Doris 2.0.0では、あいまいキーワード検索、等価クエリ、範囲クエリをより良くサポートするために転置インデックスを導入しました。
ある携帯電話メーカーがユーザー行動分析シナリオでApache Doris 2.0.0をテストしました。転置インデックスを有効にすることで、v2.0.0はミリ秒以内にクエリを完了し、クエリの同時実行レベルが上がっても安定したパフォーマンスを維持できました。このケースでは、旧バージョンより5倍から90倍高速でした。
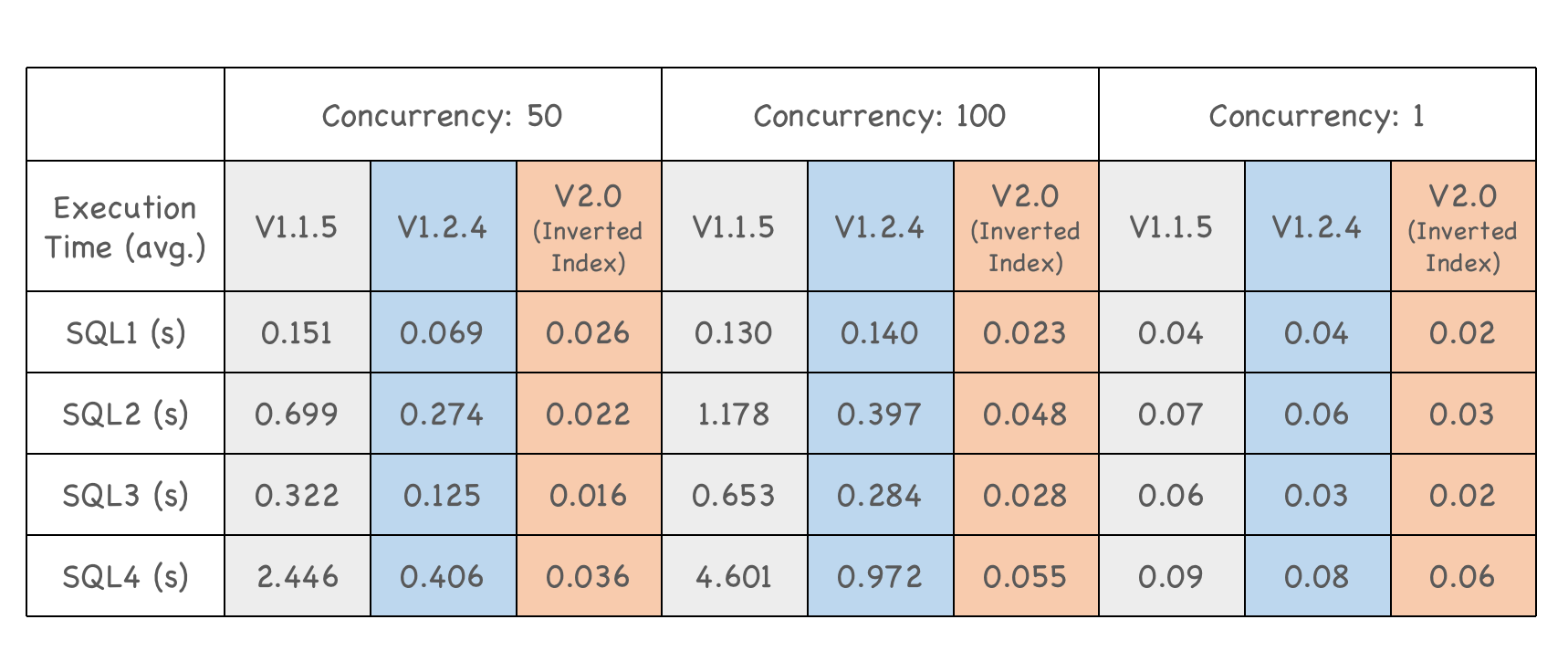
20倍の高い同時実行能力
Eコマースの注文クエリや宅配追跡などのシナリオでは、膨大な数のエンドデータユーザーが特定のデータレコードを同時に検索します。これらは高同時性ポイントクエリと呼ばれ、システムに大きな負荷をかける可能性があります。従来のソリューションは、このようなクエリにApache HBaseなどのKey-Valueストアを導入し、負荷を軽減するためにRedisをキャッシュ層として使用することでしたが、これは冗長なストレージとより高いメンテナンスコストを意味しました。
Apache Dorisのような列指向DBMSでは、ポイントクエリのI/O使用量が倍増します。より効率的な実行が必要です。そこで、列ストレージをベースに、行の読み取り効率を向上させるために行ストレージ形式と行キャッシュを追加し、データ取得を高速化するためのショートサーキットプラン、そしてフロントエンドオーバーヘッドを削減するためのプリペアドステートメントを実装しました。
これらの最適化により、Apache Doris 2.0は4×1TハードドライブとCPU16コア64GBのクラウドサーバー上でYCSBにおいてノード当たり30,000 QPSの同時実行レベルに達し、旧バージョンと比較して20倍の改善を表しました。これにより、Apache Dorisは高同時性シナリオにおけるHBaseの良い代替手段となり、ユーザーは複雑な技術スタックによる追加のメンテナンスコストと冗長なストレージに耐える必要がなくなります。
詳細を読む: https://doris.apache.org/blog/High_concurrency
自己適応型並列実行モデル
Apache 2.0では、ハイブリッド分析ワークロードでより高い効率性と安定性を実現するためにPipeline実行モデルを導入しました。このモデルでは、クエリの実行はデータによって駆動されます。すべてのクエリ実行プロセスのブロッキング演算子がパイプラインに分割されます。パイプラインが実行スレッドを取得するかどうかは、関連するデータが準備できているかどうかに依存します。これにより非同期ブロッキング操作とより柔軟なシステムリソース管理が可能になります。また、システムがスレッドの作成と破棄を頻繁に行う必要がないため、CPU効率が向上します。
ドキュメント: https://doris.apache.org/docs/dev/query-acceleration/pipeline-execution-engine/
Pipeline実行モデルの有効化方法
- Pipeline実行エンジンはApache Doris 2.0でデフォルトで有効になっています:
Set enable_pipeline_engine = true。 parallel_pipeline_task_numは、SQLクエリで並列実行されるパイプラインタスクの数を表します。デフォルト値は0で、これはApache Dorisが各バックエンドノードのCPU数の半分に同時実行レベルを自動設定することを意味します。ユーザーは必要に応じてこの値を変更できます。- 古いバージョンからApache Doris 2.0にアップグレードする場合、
parallel_pipeline_task_numの値を旧バージョンのparallel_fragment_exec_instance_numの値に設定することを推奨します。
複数の分析ワークロードのための統一プラットフォーム
Apache Dorisは境界を押し広げています。レポート用のOLAPエンジンとしてスタートし、現在はETL/ELTなどに対応可能なデータウェアハウスになっています。バージョン2.0では、ログ分析とデータレイクハウス機能に進歩をもたらしています。
10倍コスト効率の高いログ分析ソリューション
Apache Doris 2.0.0は半構造化データをネイティブサポートしています。JSONとArrayに加えて、複雑なデータタイプであるMapをサポートします。Light Schema Changeに基づき、Schema Evolutionもサポートしており、ビジネスの変化に応じてスキーマを調整できます。フィールドとインデックスを追加または削除し、フィールドのデータタイプを変更できます。転置インデックスと高性能テキスト分析アルゴリズムを導入したことで、ログの全文検索と次元分析をより効率的に実行できます。より高速なデータ書き込みとクエリ速度、より低いストレージコストにより、業界内の一般的なログ分析ソリューションより10倍コスト効率が高くなっています。
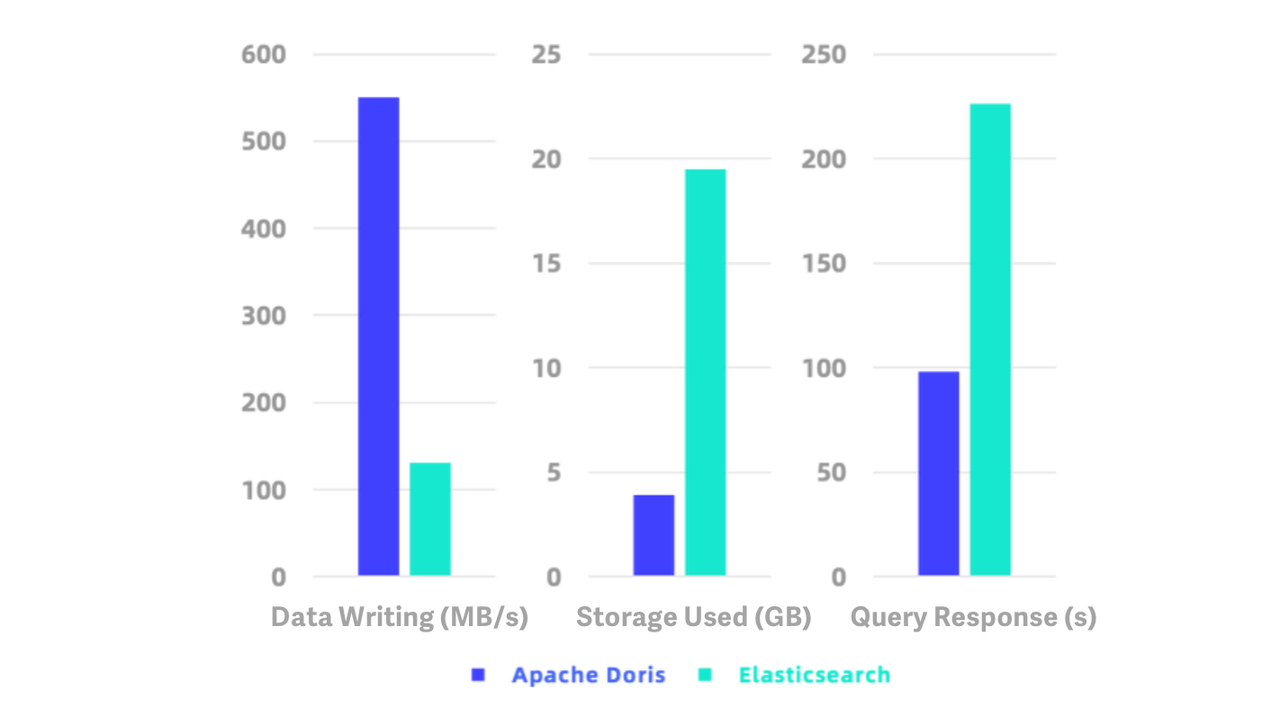
強化されたデータレイクハウス機能
Apache Doris 1.2では、異種データソースからのデータの自動マッピングと自動同期を可能にするMulti-カタログを導入しました。バージョン2.0.0では、サポートされるデータソースのリストを拡張し、本番環境でのユーザーニーズに基づいてDorisを最適化しました。
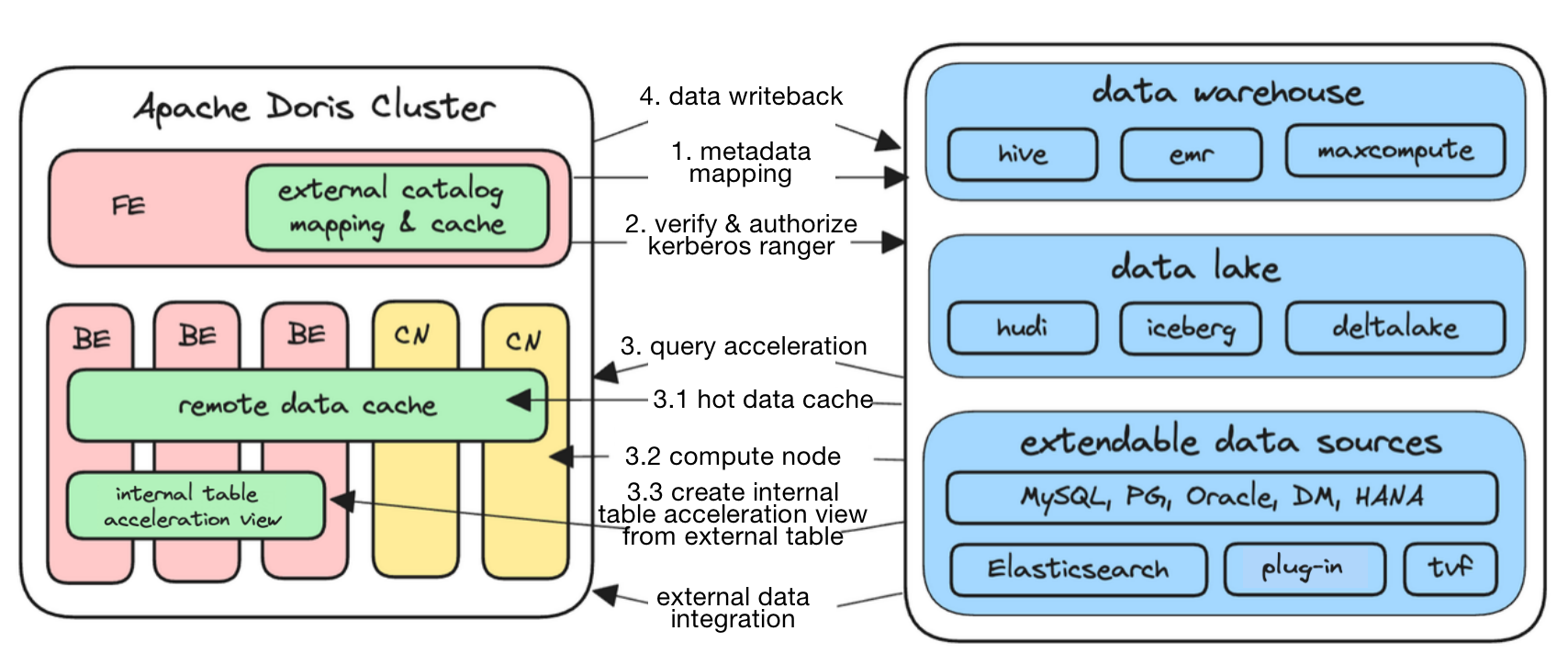
Apache Doris 2.0.0は、Hive、Hudi、Iceberg、Paimon、MaxCompute、Elasticsearch、Trino、ClickHouseなど数十のデータソースと、ほぼすべてのオープンレイクハウス形式をサポートしています。また、Hudi Copy-on-WriteテーブルのスナップショットクエリとHudi Merge-on-Readテーブルの読み取り最適化クエリをサポートしています。Apache Rangerを使用したHive カタログの認証を可能にし、ユーザーは既存の権限制御システムを再利用できます。さらに、任意のカタログに対してユーザー定義の認証方法を可能にする拡張可能な認証プラグインをサポートしています。
TPC-Hベンチマークテストでは、Apache Doris 2.0.0はHiveテーブルでのクエリにおいてPresto/Trinoより3〜5倍高速であることが示されました。これは、この開発サイクルで完了した包括的な最適化(小ファイル読み取り、フラットテーブル読み取り、ローカルファイルキャッシュ、ORC/Parquetファイル読み取り、Compute Nodes、外部テーブルの情報収集)とApache Dorisの分散実行フレームワーク、ベクトル化実行エンジン、クエリオプティマイザーによって実現されました。
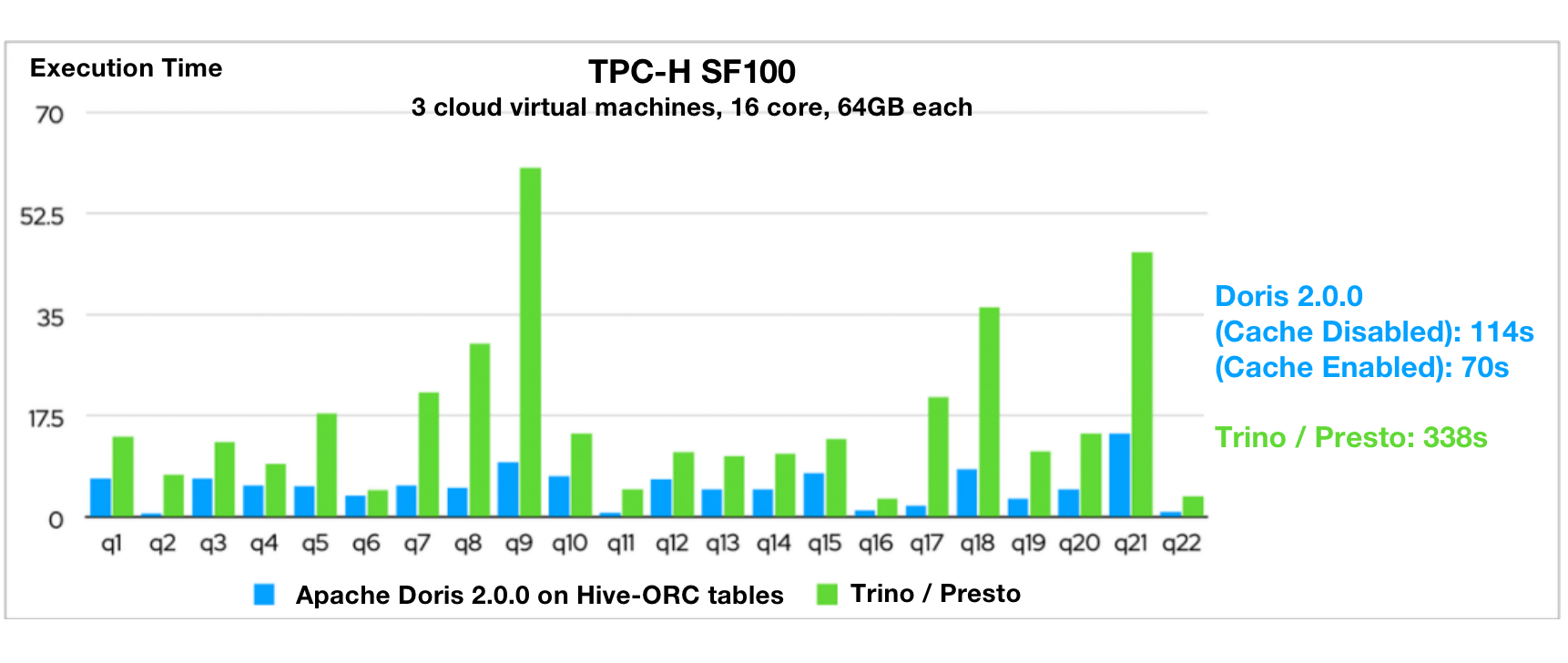
これらすべてにより、Apache Doris 2.0.0はデータレイクハウスシナリオで優位性を持っています。Dorisを使用すると、複数の上流データソースの増分または全体同期を一箇所で実行でき、他のクエリエンジンよりもはるかに高いデータクエリパフォーマンスを期待できます。処理されたデータは、ソースに書き戻すか下流システムに提供できます。このように、Apache Dorisを統一データ分析ゲートウェイにできます。
効率的なデータ更新
データ更新は、ユーザーが常に最新のデータにアクセスしたい、そして行やいくつかの列の更新、指定したデータのバッチ更新や削除、データパーティション全体の上書きなど、柔軟にデータを更新できることを望むため、リアルタイム分析では重要です。
効率的なデータ更新は、データ分析におけるもう一つの難しい課題でした。Apache Hiveはパーティションレベルでの更新のみをサポートし、HudiとIcebergはMerge-on-ReadとCopy-on-Writeの実装により、リアルタイム更新よりも低頻度のバッチ更新により適しています。
データ更新に関して、Apache Doris 2.0.0は以下が可能です:
- より高速なデータ書き込み: オンライン決済プラットフォームでの負荷テストでは、20の同時データ書き込みタスクの下で、Dorisは毎秒300,000レコードの書き込みスループットに達し、10時間を超える継続的な書き込みプロセス全体を通して安定性を維持しました。
- 部分列更新: Dorisの古いバージョンはAggregate Keyモデルで
replace_if_not_nullによる部分列更新を実装していました。2.0.0では、Unique Keyモデルで部分列更新を有効にしています。つまり、書き込み前にFlinkを使用して複数のソーステーブルを1つの出力ストリームに連結する必要なく、複数のソーステーブルからフラットテーブルに直接データを書き込むことができます。この方法は複雑な処理パイプラインと追加のリソース消費を回避します。更新が必要な列を簡単に指定できます。 - 条件付き更新と削除: 単純なアップデートとDelete操作に加えて、Merge-on-Writeに基づいて複雑な条件付き更新と削除操作を実現しています。
より高速、安定、賢いデータ書き込み
データ書き込みの高速化
Apache Dorisのリアルタイム分析能力を強化する継続的な取り組みの一環として、バージョン2.0.0のエンドツーエンドリアルタイムデータ書き込み能力を改善しました。ベンチマークテストでは、様々な書き込み方法でより高いスループットが報告されました:
- Stream Load、TPC-H 144G lineitemテーブル、48バケットDuplicateテーブル、3レプリカ書き込み: スループット100%向上
- Stream Load、TPC-H 144G lineitemテーブル、48バケットUnique Keyテーブル、3レプリカ書き込み: スループット200%向上
- Insert Into Select、TPC-H 144G lineitemテーブル、48バケットDuplicateテーブル: スループット50%向上
- Insert Into Select、TPC-H 144G lineitemテーブル、48バケットUnique Keyテーブル: スループット150%向上
高同時性データ書き込みでのより高い安定性
システム不安定性の原因には、小ファイルのマージ、書き込み増幅、それに伴うディスクI/OとCPUオーバーヘッドがしばしば含まれます。そこで、バージョン2.0.0でVertical CompactionとSegment Compactionを導入し、コンパクションでのOOMエラーを解消し、データ書き込み中の過度なセグメントファイル生成を回避しました。これらの改善により、Apache Dorisは以前に使用していたメモリの10%のみを使用してデータを50%高速に書き込むことができます。
詳細を読む: https://doris.apache.org/blog/Compaction
テーブルスキーマの自動同期
最新のFlink-Doris-Connectorにより、ユーザーは1つの簡単なステップでデータベース全体(MySQLやOracleなど)をApache Dorisに同期できます。テスト結果によると、1つの同期タスクで数千のテーブルのリアルタイム同時書き込みをサポートできます。Apache Dorisがプロセスを自動化したため、ユーザーはもはや複雑な同期手順を経る必要がありません。上流データスキーマの変更は自動的に捉えられ、シームレスにApache Dorisに動的更新されます。
詳細を読む: https://doris.apache.org/blog/FDC
新しいマルチテナントリソース分離ソリューション
マルチテナントリソース分離の目的は、高負荷時のリソース競合を回避することです。そのため、Apache Dorisの古いバージョンではResource Groupを特徴とするハード分離プランを採用していました:同じDorisクラスターのBackendノードにタグが付けられ、同じタグのものがResource Groupを形成します。データがデータベースに取り込まれる際、異なるデータレプリカが異なるResource Groupに書き込まれ、それぞれが異なるワークロードを担当します。例えば、データの読み書きは異なるデータタブレットで行われ、読み書き分離を実現します。同様に、オンラインとオフラインのビジネスを異なるResource Groupに配置することもできます。
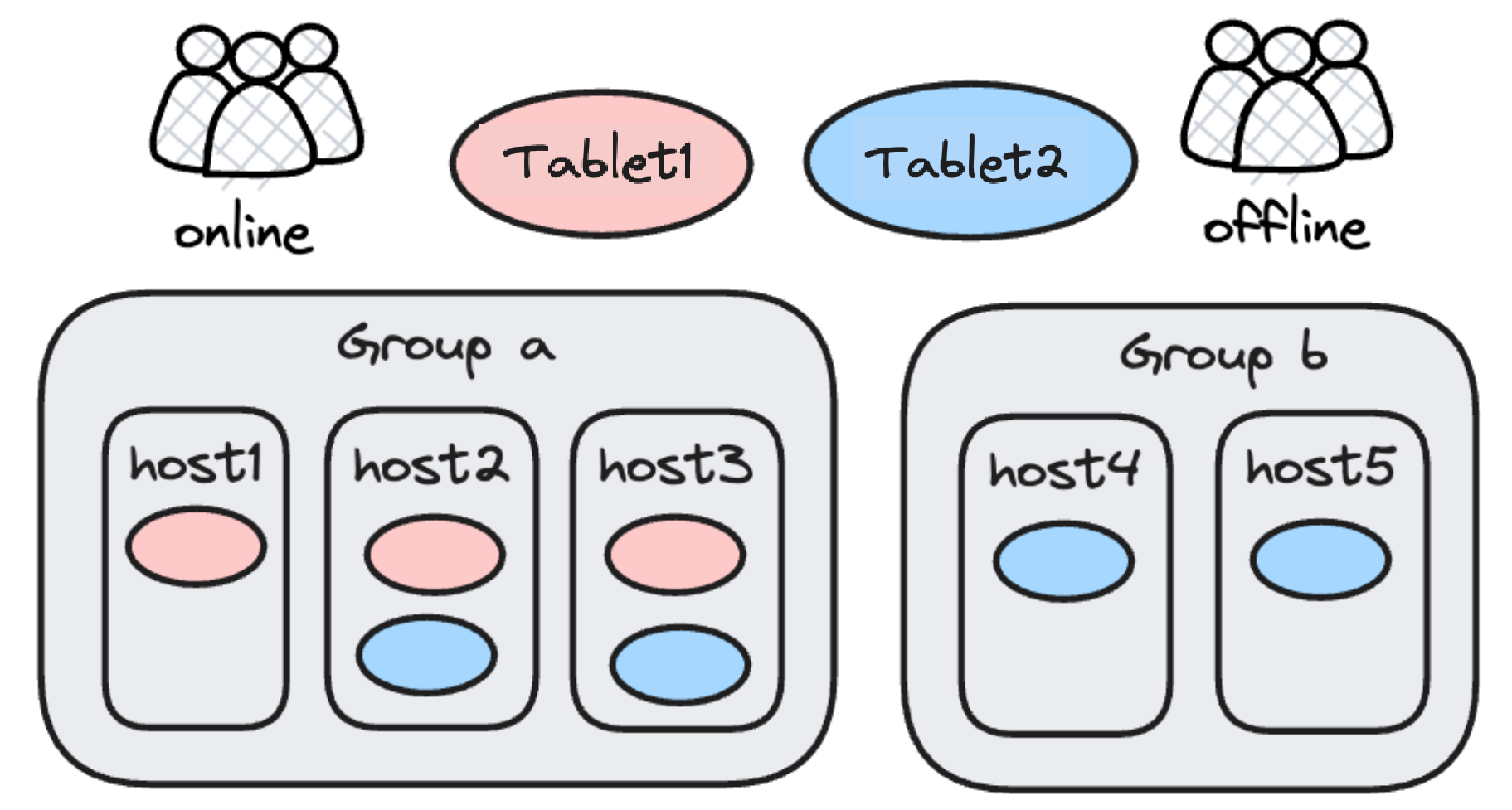
これは効果的なソリューションですが、実際には一部のResource Groupが大きく占有される一方で他がアイドル状態になることがあります。リソースの空き率を下げるより柔軟な方法が欲しいのです。そこで、2.0.0でWorkload Groupリソースソフト制限を導入しました。
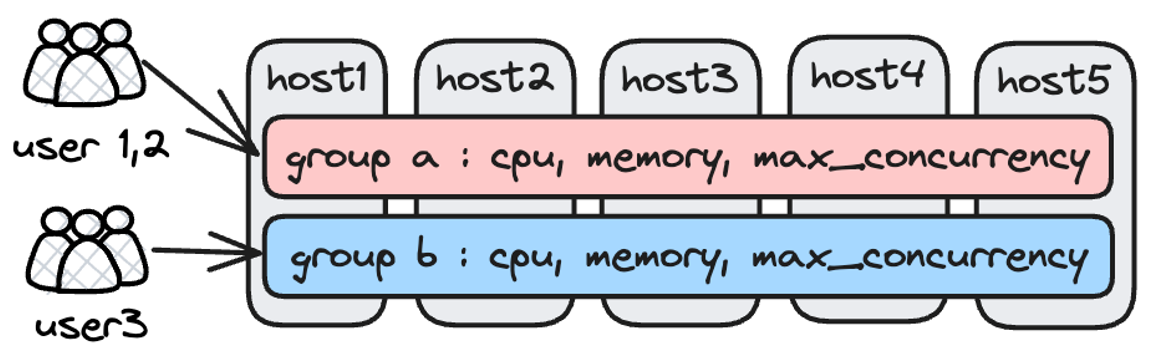
アイデアは、ワークロードをグループに分けてCPUとメモリリソースの柔軟な管理を可能にすることです。Apache DorisはクエリをWorkload Groupに関連付け、バックエンドノードで単一のクエリが使用できるCPUとメモリの割合を制限します。メモリソフト制限はユーザーが設定し有効化できます。
クラスターリソース不足時には、システムは最大メモリ消費クエリタスクを停止します。クラスターリソースが十分な場合、Workload Groupが予想以上にリソースを使用すると、アイドルクラスターリソースがすべてのWorkload Group間で共有され、システムメモリを最大限活用してクエリの安定実行を保証します。また、リソース割り当てに関してWorkload Groupに優先順位を付けることもできます。つまり、どのタスクに十分なリソースを割り当て、どのタスクにそうしないかを決定できます。
同時に、2.0.0でQuery Queueを導入しました。Workload Group作成時に、クエリキューの最大クエリ数を設定できます。その制限を超えるクエリはキューで実行を待ちます。これは高負荷でのシステム負担を軽減するためです。
弾性スケーリングとストレージ・コンピュート分離
計算とストレージリソースに関して、ユーザーは何を求めているでしょうか?
- 計算リソースの弾性スケーリング: ピーク時にリソースを迅速にスケールアップして効率を向上させ、オフピーク時にスケールダウンしてコストを削減する。
- より低いストレージコスト: 低コストストレージメディアを使用し、ストレージと計算を分離する。
- ワークロードの分離: 異なるワークロードの計算リソースを分離して競合を回避する。
- データの統一管理: カタログとデータを一箇所で簡単に管理する。
ストレージと計算を分離することはリソースの弾性スケーリングを実現する方法ですが、ストレージの安定性を維持するためにより多くの努力が必要で、これがOLAPサービスの安定性と継続性を決定します。ストレージの安定性を確保するため、キャッシュ管理、計算リソース管理、ガベージコレクションなどのメカニズムを導入しました。
この点で、調査後にユーザーを3つのグループに分けます:
- リソーススケーリングが不要なユーザー
- リソーススケーリング、低ストレージコスト、Apache Dorisからのワークロード分離を必要とするユーザー
- すでに安定した大規模ストレージシステムを持っており、効率的なリソーススケーリングのための高度な計算・ストレージ分離アーキテクチャを必要とするユーザー
Apache Doris 2.0は最初の2つのタイプのユーザーのニーズに対処する2つのソリューションを提供します。
- Computeノード。バージョン2.0でステートレスcomputeノードを導入しました。mixノードとは異なり、computeノードはデータを保存せず、クラスタースケーリング時のデータタブレットのワークロードバランシングに関与しません。そのため、ピーク時にクラスターに迅速に参加し、計算負荷を共有できます。さらに、データレイクハウス分析では、これらのノードがリモートストレージ(HDFS/S3)でのクエリを最初に実行するため、内部テーブルと外部テーブル間のリソース競争がありません。
- ホット・コールドデータ分離。ホット/コールドデータとは、それぞれ頻繁に/めったにアクセスされないデータを指します。一般的に、コールドデータを低コストストレージに保存する方が理にかなっています。Apache Dorisの古いバージョンは、テーブルパーティションのライフサイクル管理をサポートしています:ホットデータがコールドになると、SSDからHDDに移動されます。しかし、データはHDD上で複数のレプリカで保存され、これはまだ無駄でした。現在、Apache Doris 2.0では、コールドデータをオブジェクトストレージに保存でき、これはさらに安価で単一コピーストレージを可能にします。これによりストレージコストが70%削減され、ストレージに伴う計算とネットワークオーバーヘッドが削減されます。
より明確な計算とストレージの分離のため、VeloDBチームはCloud Compute-Storage-SeparationソリューションをApache Dorisプロジェクトに貢献する予定です。その性能と安定性は、本番環境での数百の企業でのテストに耐えています。コードのマージは今年10月までに完了し、すべてのApache Dorisユーザーが9月に早期テストできるようになります。
使いやすさの向上
Apache Doris 2.0.0はエンタープライズ向け機能もハイライトしています。
Kubernetesデプロイメントのサポート
Apache Dorisの古いバージョンはIPベースで通信するため、POD IPドリフトを引き起こすKubernetesデプロイメントでのホスト障害は、クラスター利用不可能を招きます。現在、バージョン2.0はFQDNをサポートしています。つまり、障害したDorisノードは人間の介入なしに自動回復でき、これがKubernetesデプロイメントと弾性スケーリングの基盤を築きます。
クロスクラスターレプリケーション(CCR)のサポート
Apache Doris 2.0.0はクロスクラスターレプリケーション(CCR)をサポートしています。ソースクラスターでのデータベース/テーブルレベルでのデータ変更がターゲットクラスターに同期されます。増分データまたは全体データの複製を選択できます。
また、DDLの同期もサポートしており、ソースクラスターで実行されたDDLステートメントも自動的にターゲットクラスターに複製されます。
DorisでのCCRの設定と使用は簡単です。この機能を活用して、読み書き分離とマルチデータセンターレプリケーションを実装できます。
この機能により、データの可用性向上、読み書きワークロード分離、クロスデータセンターレプリケーションをより効率的に実現できます。
動作変更
- 1.2-ITSから2.0.0へはローリングアップグレードを使用し、2.0のプレビューバージョンから2.0.0へは再起動アップグレードを使用
- 新しいクエリオプティマイザー(Nereids)がデフォルトで有効:
enable_nereids_planner=true - すべての非ベクトル化コードがシステムから削除されたため、
enable_vectorized_engineパラメータは機能しません - 新しいパラメータ
enable_single_replica_compactionが追加されました - datev2、datetimev2、decimalv3がテーブル作成のデフォルトデータタイプ;datav1、datetimev1、decimalv2はテーブル作成でサポートされません
- decimalv3はJDBCとIceberg カタログのデフォルトデータタイプ
- 新しいデータタイプ
AGG_STATEが追加されました - backendテーブルからcluster列が削除されました
- BIツールとの互換性向上のため、
show create table時にdatev2とdatetimev2はdateとdatetimeとして表示されます - max_openfilesとswapsチェックがbackend起動スクリプトに追加されたため、不適切なシステム設定はbackend障害を引き起こす可能性があります
- localhostでfrontendにアクセスする際、パスワードなしログインは許可されません
- システムにMulti-カタログがある場合、デフォルトで情報スキーマをクエリする際は内部カタログのデータのみが表示されます
- 式ツリーの深さに制限が課されました。デフォルト値は200です
- 配列文字列の戻り値の単一引用符が二重引用符に変更されました
- DorisプロセスがDorisFEとDorisBEに名前変更されました
- 2つの引数を持つAESとSM4関数の動作が変更されました。詳細は関連する関数ドキュメントを参照してください
2.0.0への旅の始まり
Apache Doris 2.0.0を本番環境対応にするため、数百のエンタープライズユーザーをテストに招待し、より良いパフォーマンス、安定性、使いやすさのために最適化しました。次の段階では、アジャイルリリース計画でユーザーニーズに応え続けます。8月下旬に2.0.1、9月に2.0.2のリリースを計画し、バグ修正と新機能追加を続けます。また、9月に2.1の早期バージョンをリリースして、長い間リクエストされていたいくつかの機能をお届けする予定です。例えば、Doris 2.1では、Variantデータタイプが半構造化データのスキーマフリー分析ニーズにより良くサービスし、マルチテーブル実体化ビューがデータスケジューリングと処理リンクを簡素化しながらクエリを高速化し、より多くの効率的なデータ取り込み方法が追加され、