
コンピュートグループ
Compute Groupは、ストレージ・コンピュート分離アーキテクチャにおいて、異なるワークロード間の物理的な分離を実現するメカニズムです。Compute Groupの基本原理は以下の図に示されています:
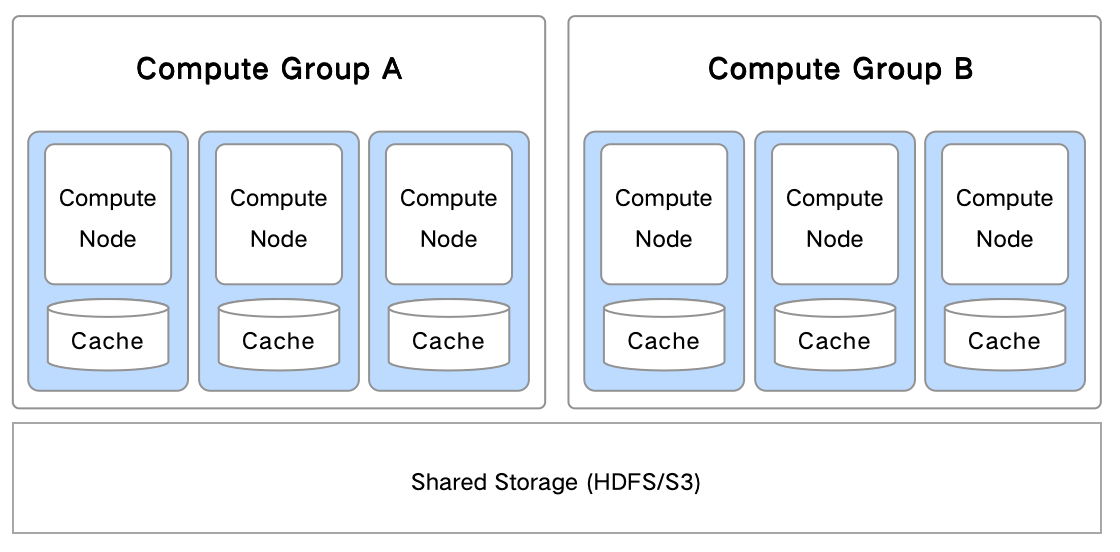
-
1つまたは複数のBEノードでCompute Groupを構成できます。
-
BEノードはローカルではステートレスで、データは共有ストレージに保存されます。
-
複数のCompute Groupが共有ストレージを通じてデータにアクセスします。
Resource Groupのような強力な分離の利点を維持しながら、Compute Groupは以下の利点を提供します:
-
低コスト:ストレージ・コンピュート分離アーキテクチャにより、データは共有ストレージに存在するため、Compute Groupの数はレプリカ数に制限されません。ユーザーはストレージコストを増加させることなく、必要な数のCompute Groupを作成できます。
-
より高い柔軟性:ストレージ・コンピュート分離アーキテクチャでは、BEノード上のデータはキャッシュされるため、Compute Groupの追加に煩雑なデータ移行プロセスは不要です。新しいCompute Groupは、クエリ実行中にキャッシュをウォームアップするだけで済みます。
-
より良い分離:データの可用性は共有ストレージレイヤーで処理されるため、任意のCompute Group内のBEノードの障害が、Resource Groupで発生するようなデータロードの失敗を引き起こすことはありません。
3.0.2以前では、Compute クラスターと呼ばれていました。
すべてのCompute Groupの表示
SHOW COMPUTE GROUPSコマンドを使用して、現在のリポジトリ内のすべてのcompute groupを表示します。返される結果は、ユーザーの権限レベルに基づいて異なる内容が表示されます:
ADMIN権限を持つユーザーはすべてのcompute groupを表示できます- 一般ユーザーは使用権限(USAGE_PRIV)を持つcompute groupのみを表示できます
- ユーザーがいずれのcompute groupに対しても使用権限を持たない場合、空の結果が返されます
SHOW COMPUTE GROUPS;
Compute Groupの追加
compute groupの管理にはOPERATOR権限が必要です。この権限はノード管理の許可を制御します。詳細については、Privilege Managementを参照してください。デフォルトでは、rootアカウントのみがOPERATOR権限を持ちますが、GRANTコマンドを使用して他のアカウントに付与することができます。
BEを追加してcompute groupに割り当てるには、Add BEコマンドを使用します。例:
ALTER SYSTEM ADD BACKEND 'host:9050' PROPERTIES ("tag.compute_group_name" = "new_group");
上記のsqlはhost:9050をcompute group new_groupに追加します。PROPERTIES文を省略した場合、BEはcompute group default_compute_groupに追加されます。例えば:
ALTER SYSTEM ADD BACKEND 'host:9050';
Compute Group アクセスの許可
前提条件: 現在の操作ユーザーが 'ADMIN' 権限を持っているか、現在のユーザーが admin ロールに属している。
GRANT USAGE_PRIV ON COMPUTE GROUP {compute_group_name} TO {user}
Compute Group アクセスの取り消し
前提条件:現在の操作ユーザーが 'ADMIN' 権限を持つか、現在のユーザーが admin ロールに属している。
REVOKE USAGE_PRIV ON COMPUTE GROUP {compute_group_name} FROM {user}
デフォルトCompute Groupの設定
現在のユーザーのデフォルトcompute groupを設定するには(この操作には、現在のユーザーがすでにcomputing groupを使用する権限を持っている必要があります):
SET PROPERTY 'default_compute_group' = '{clusterName}';
他のユーザーのデフォルトcompute groupを設定するには(この操作にはAdmin権限が必要です):
SET PROPERTY FOR {user} 'default_compute_group' = '{clusterName}';
現在のユーザーのデフォルトコンピュートグループを表示するには、返される結果のdefault_compute_groupの値がデフォルトコンピュートグループです:
SHOW PROPERTY;
他のユーザーのデフォルトcompute groupを表示するには、この操作では現在のユーザーが管理者権限を持っている必要があり、返される結果のdefault_compute_groupの値がデフォルトcompute groupです:
SHOW PROPERTY FOR {user};
現在のリポジトリ内の利用可能なすべてのcompute groupを表示するには:
SHOW COMPUTE GROUPS;
- 現在のユーザーがAdmin役割を持つ場合、例:
CREATE USER jack IDENTIFIED BY '123456' DEFAULT ROLE "admin"の場合:- 自分と他のユーザーのデフォルトコンピュートグループを設定できます;
- 自分と他のユーザーの
PROPERTYを閲覧できます。
- 現在のユーザーがAdmin役割を持たない場合、例:
CREATE USER jack1 IDENTIFIED BY '123456'の場合:- 自分のデフォルトコンピュートグループを設定できます;
- 自分の
PROPERTYを閲覧できます; - すべてのコンピュートグループを閲覧することはできません。この操作には
GRANT ADMIN権限が必要です。
- 現在のユーザーがデフォルトコンピュートグループを設定していない場合、既存システムはデータの読み取り/書き込み操作を実行する際にエラーを発生させます。この問題を解決するため、ユーザーは
use @clusterコマンドを実行して現在のコンテキストで使用するコンピュートグループを指定するか、SET PROPERTYステートメントを使用してデフォルトコンピュートグループを設定することができます。 - 現在のユーザーがデフォルトコンピュートグループを設定しているが、そのクラスターが後に削除された場合、データの読み取り/書き込み操作中にもエラーが発生します。ユーザーは
use @clusterコマンドを実行して現在のコンテキストで使用するコンピュートグループを再指定するか、SET PROPERTYステートメントを使用してデフォルトクラスター設定を更新することができます。
コンピュートグループの切り替え
ユーザーはコンピュート・ストレージ分離アーキテクチャで使用するデータベースとコンピュートグループを指定できます。
構文
USE { [catalog_name.]database_name[@compute_group_name] | @compute_group_name }
データベースやcompute group名に予約キーワードが含まれている場合、対応する名前はバッククォート```で囲む必要があります。
Compute Groupのスケーリング
ALTER SYSTEM ADD BACKENDとALTER SYSTEM DECOMMISION BACKENDを使用してBEを追加または削除することで、compute groupをスケーリングできます。