
大規模Performance Benchmark
このページでは、単一ノードと分散デプロイメントの両方での大規模ベンチマーク結果をまとめています。これらのテストの目的は、異なるデータスケールでのクエリ動作を示し、Dorisがベクトルクエリ容量を単一ノードワークロードから大規模な分散デプロイメントへとどのように拡張するかを説明することです。
テストマトリックス
- 単一ノード: FE/BE分離、BEは16C64GBマシン1台
- 分散: 3つのBEノード、各16C64GB
- ワークロード:
- Performance768D10M
- Performance1536D5M
- Performance768D100M
単一ノードベンチマーク (16C64GB)
単一ノードの結果は、中規模から大規模データセットでのANNクエリパフォーマンスのベースラインを提供します。
インポートパフォーマンス
| 項目 | Performance768D10M | Performance1536D5M |
|---|---|---|
| 次元数 | 768 | 1536 |
| metric_type | inner_product | inner_product |
| 行数 | 10M | 5M |
| バッチ設定 | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 | NUM_PER_BATCH=250000--stream-load-rows-per-batch 250000 |
| インポート時間 | 76m41s | 41m |
show data all | 56.498 GB (25.354 GB + 31.145 GB) | 55.223 GB (25.346 GB + 29.878 GB) |
Performance768D10Mのインポート時のCPU使用率を以下に示します。チャートは、取り込み全体を通してCPU使用量が比較的安定していることを示しています。
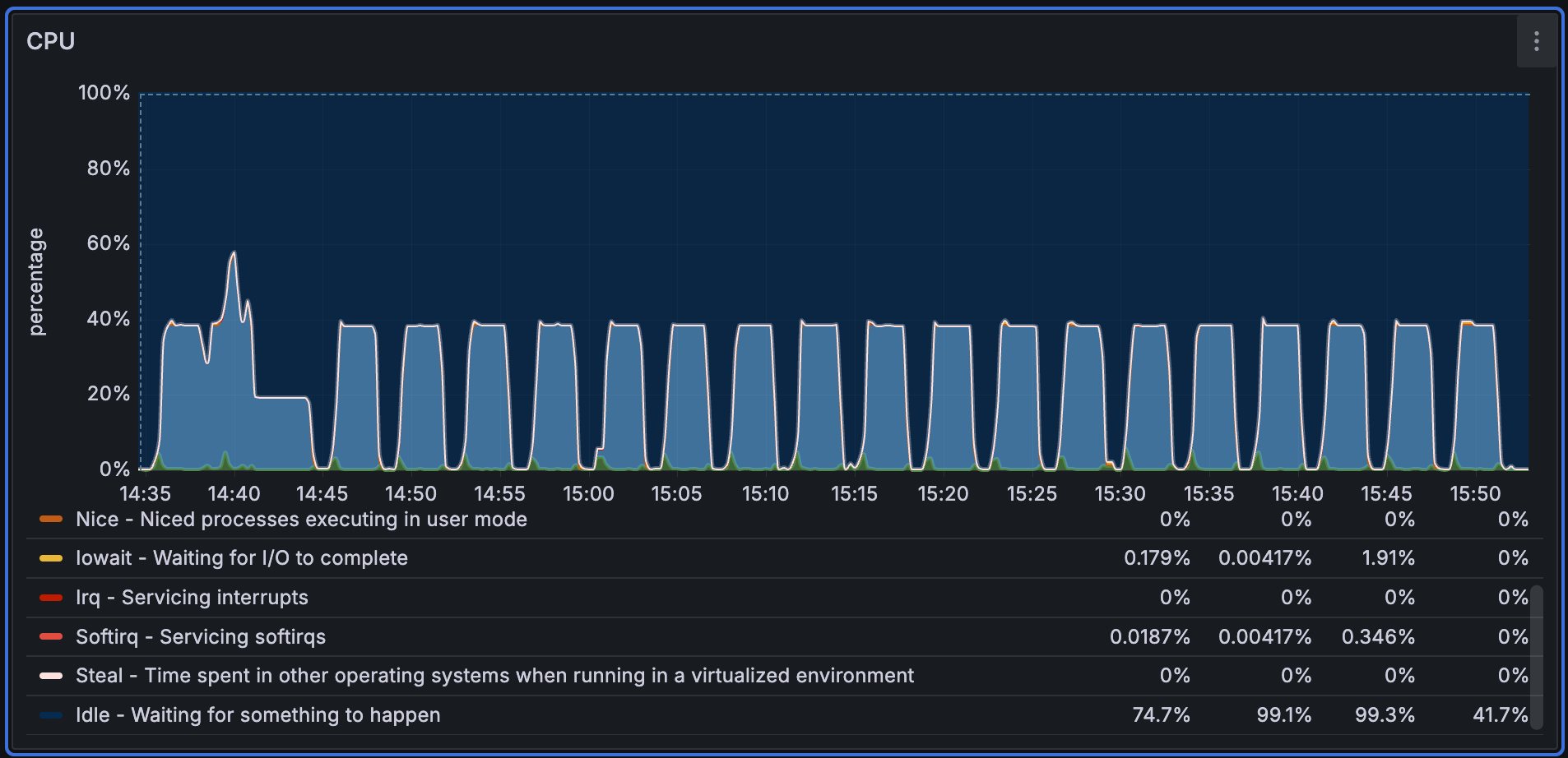
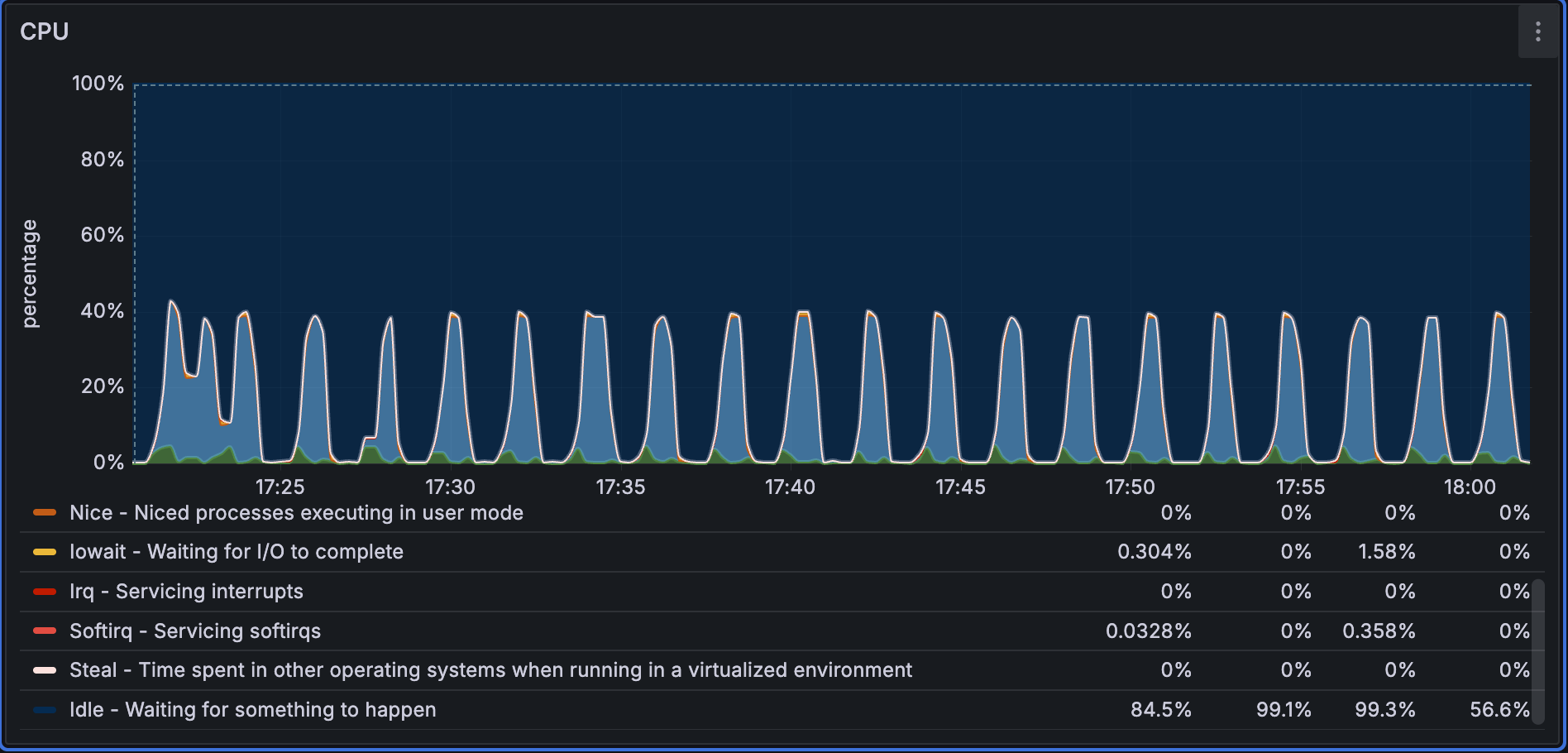
Performance1536D5Mの場合、データセットが小さく、バッチサイズも小さいため、取り込み中にCPU使用率がより頻繁に変動します。
クエリパフォーマンス
2つの単一ノードワークロードでは、Dorisは高いrecallと低いレイテンシを維持しながら、数百QPSに達しています。
サマリー
| データセット | BestQPS | Recall@100 |
|---|---|---|
| Performance768D10M | 481.9356 | 0.9207 |
| Performance1536D5M | 414.7342 | 0.9677 |
Performance768D10M (inner_product, 10M行)
| 同時実行数 | QPS | P95レイテンシ | P99レイテンシ | 平均レイテンシ |
|---|---|---|---|---|
| 10 | 116.2000 | 0.0932 | 0.0933 | 0.0861 |
| 40 | 455.9485 | 0.1102 | 0.1225 | 0.0877 |
| 80 | 481.9356 | 0.2331 | 0.2674 | 0.1658 |
Performance1536D5M (inner_product, 5M行)
| 同時実行数 | QPS | P95レイテンシ | P99レイテンシ | 平均レイテンシ |
|---|---|---|---|---|
| 10 | 144.3221 | 0.0764 | 0.0800 | 0.0693 |
| 40 | 401.9732 | 0.1271 | 0.1404 | 0.0994 |
| 80 | 414.7342 | 0.2772 | 0.3222 | 0.1925 |
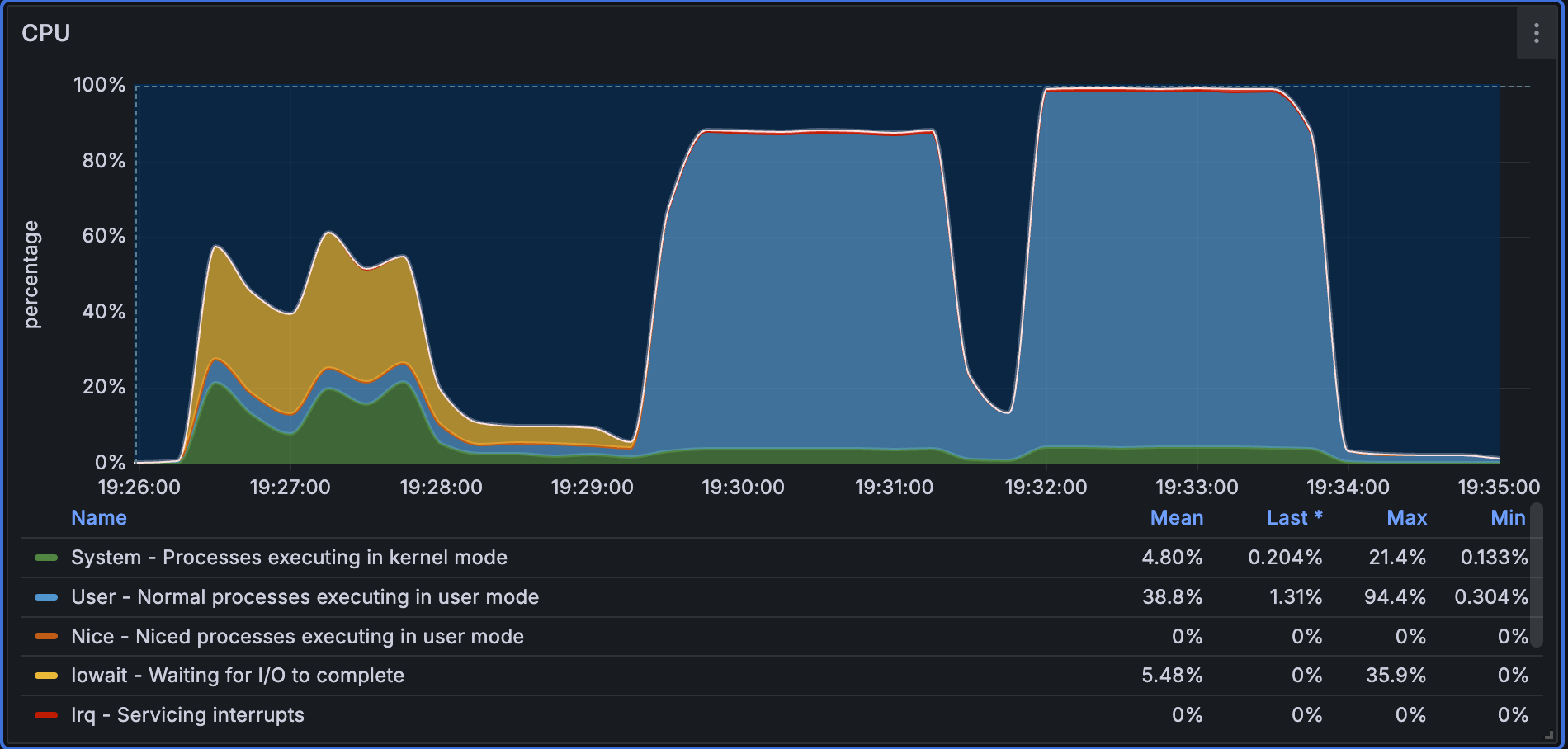
単一ノードクエリテストでは、コールドクエリフェーズで完全なインデックスをメモリに読み込む必要があるため、システムがIOを待っている間のCPU使用率は比較的低くなります。ウォームクエリフェーズでは、CPU使用率が大幅に増加し、100%に近づきます。
分散ベンチマーク (3 x 16C64GB)
分散テストでは、単一の16C64GBノードの実用的なメモリ容量を超える大規模データセットに焦点を当てています。
3BEテストでは、Performance768D100Mが選択されました。単一ノードのメモリが64GBに制限されているため、メモリ使用量を削減するためにベクトル量子化が有効になっています。このテストは、より小さい単一ノードケースとの直接的な1対1比較を提供するためではなく、マルチBEデプロイメントを通じてDorisが100Mスケールでベクトルクエリ機能をどのように維持するかを示すことを目的としています。
インポートパフォーマンス
| 項目 | 値 |
|---|---|
| データセット | Performance768D100M |
| 行数 | 100M |
| 次元数 | 768 |
| バッチ設定 | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 |
| インデックスプロパティ | "dim"="768", "index_type"="hnsw", "metric_type"="l2_distance", "pq_m"="384", "pq_nbits"="8", "quantizer"="pq" |
| インデックス構築時間 | 4h5min |
show data all | 198.809 GB (137.259 GB + 61.550 GB) |
構築後の分散状況:
- 3つのbucket
- bucket当たり34個のrowset、各rowsetは約1.99 GB
- rowset当たり6個のsegment
クエリパフォーマンス
サマリー
| メトリック | 値 |
|---|---|
| BestQPS | 77.6247 |
| Recall@100 | 0.9294 |
詳細結果 (l2_distance, 100M行)
| 同時実行数 | QPS | P95レイテンシ | P99レイテンシ | 平均レイテンシ |
|---|---|---|---|---|
| 10 | 46.5836 | 0.2628 | 0.2791 | 0.2145 |
| 20 | 75.3579 | 0.3251 | 0.3541 | 0.2651 |
| 30 | 77.6247 | 0.5222 | 0.5766 | 0.3860 |
| 40 | 76.6313 | 0.7089 | 0.7854 | 0.5212 |
インデックス構築中、CPU使用率は約50%を維持しており、構築プロセスが長期間CPUリソースを飽和させないことを示しています。
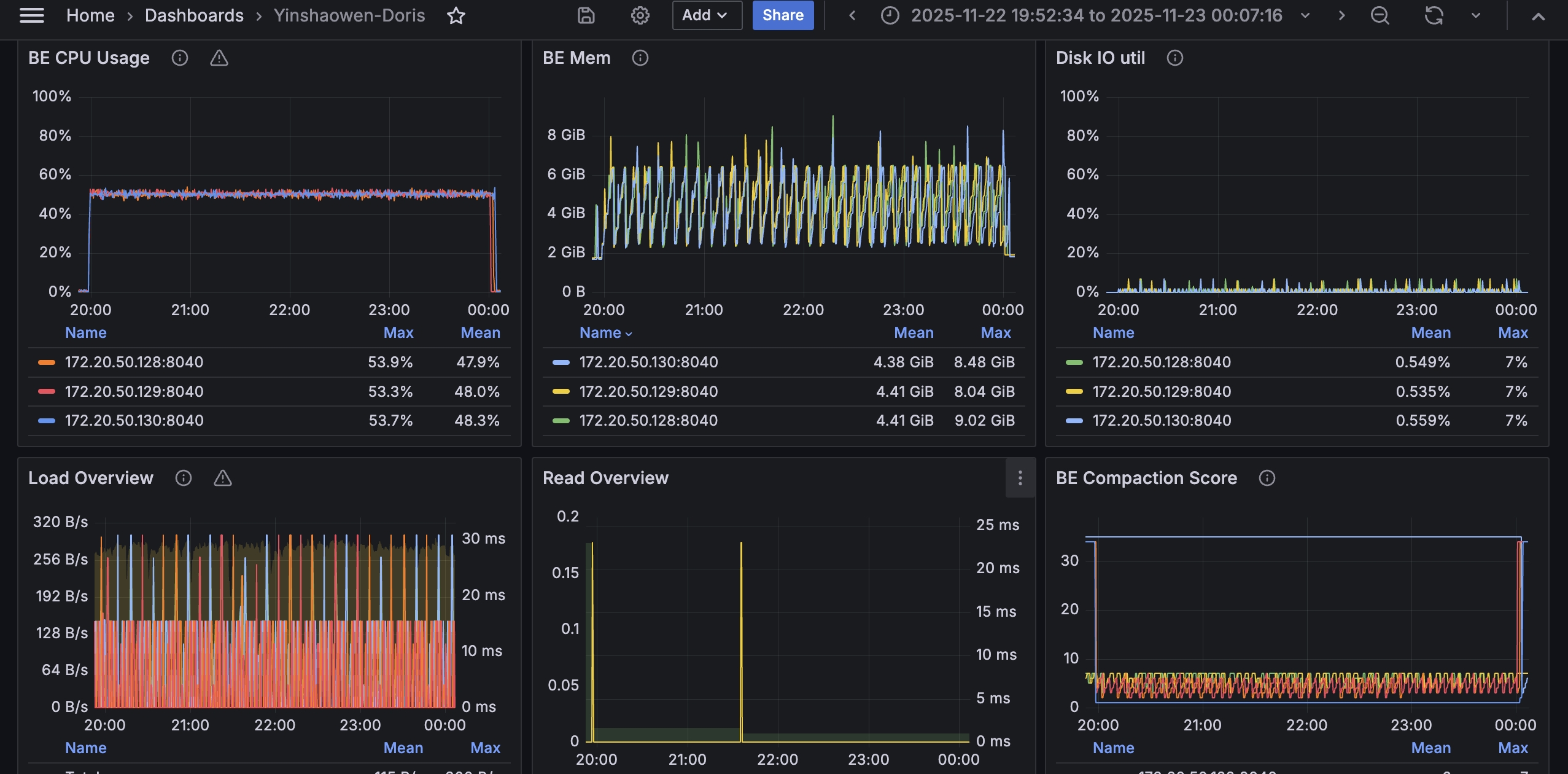
以下のチャートは、クエリフェーズ中のCPU使用率を示しています。CPU使用率はノード全体で比較的高いレベルを維持しており、分散クエリワークロードが利用可能な計算リソースを有効活用していることを示しています。
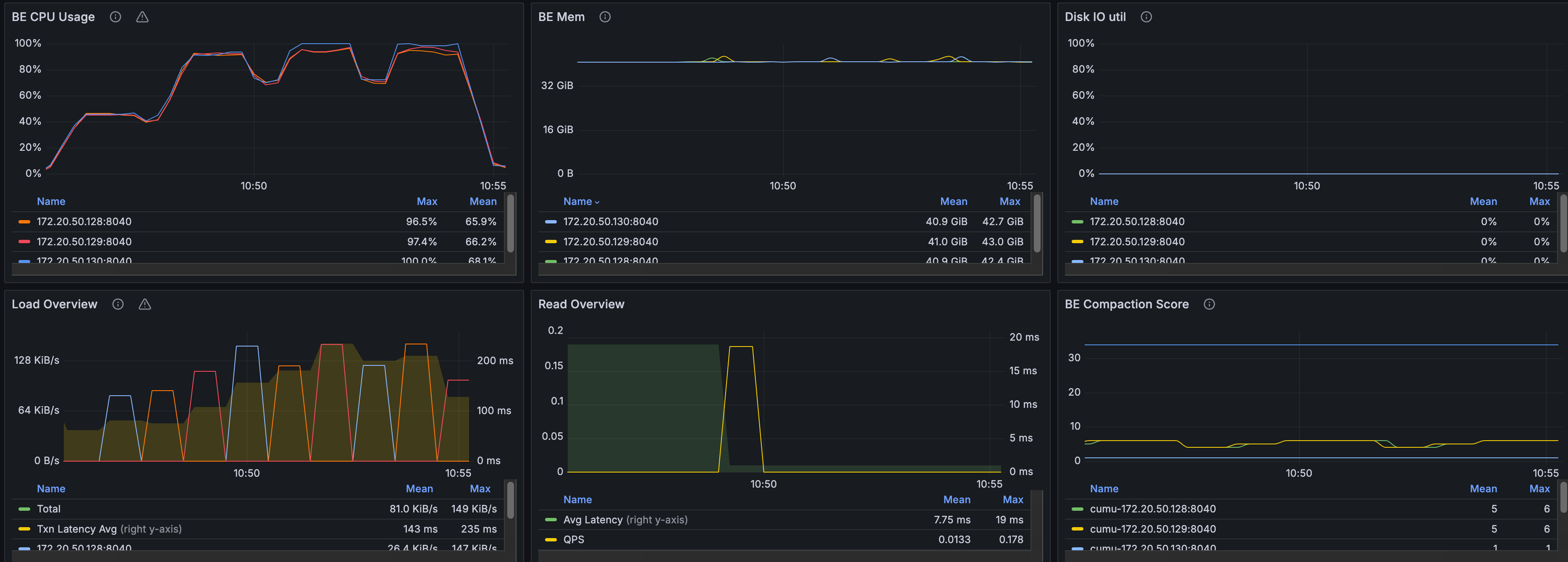
まとめ
- 数千万のベクトルに対して、Dorisは単一ノードで強力なANNクエリパフォーマンスを提供し、数百QPSと高いrecallを実現しています。
- 100Mベクトルデータセットでは、DorisはマルチBEデプロイメントを通じてオンラインベクトルクエリ機能を継続して提供しています。
- テストグループでは異なるデータセットサイズ、距離メトリック、インデックス設定を使用しているため、結果は直接的な1対1パフォーマンス比較ではなく、スケールベンチマークとして読むべきです。
注記
- 2つのテストグループ間でメトリックタイプが異なるため(
inner_productvsl2_distance)、絶対値を直接比較すべきではありません。 - 単一ノード
Performance768D10Mの同時実行数=10での結果は、コールドクエリの影響を除外するように調整されています。
再現
単一ノード:
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D10M --stream-load-rows-per-batch 500000
export NUM_PER_BATCH=250000
vectordbbench doris ... --case-type Performance1536D5M --stream-load-rows-per-batch 250000
分散 3BE:
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D100M --stream-load-rows-per-batch 500000