
ベクトル量子化調査および選択ガイド
この文書では、実用的な観点から一般的なベクトル量子化手法を紹介し、Apache Doris ANNワークロードでそれらを適用する方法について説明します。
量子化が必要な理由
ANNワークロード、特にHNSWでは、インデックスメモリが急速にボトルネックとなる可能性があります。量子化は高精度ベクトル(通常float32)をより低精度のコードにマッピングし、わずかな再現率を犠牲にしてメモリ使用量を削減します。
Dorisでは、量子化はANNインデックスのquantizerプロパティで制御されます:
flat:量子化なし(最高品質、最高メモリ使用量)sq8:スカラー量子化、8-bitsq4:スカラー量子化、4-bitpq:積量子化
例(HNSW + quantizer):
CREATE TABLE vector_tbl (
id BIGINT,
embedding ARRAY<FLOAT>,
INDEX ann_idx (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "sq8"
)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "3");
Method Overview
| Method | Core Idea | Typical Gain | Main Cost |
|---|---|---|---|
| SQ (Scalar Quantization) | 各次元を独立して量子化 | 大幅なメモリ削減、シンプルな実装 | FLATより構築が遅い;より強い圧縮では再現率が低下 |
| PQ (Product Quantization) | ベクトルをサブベクトルに分割し、各サブベクトルをコードブックで量子化 | 多くのデータセットでより良い圧縮/レイテンシのバランス | 学習/エンコーディングのコストが高い;チューニングが必要 |
Apache Dorisは現在、ANNベクトルインデックスと検索のコアエンジンとして最適化されたFaiss実装を使用しています。以下で説明するSQ/PQの動作は、実際にDorisに直接関連しています。
Scalar Quantization (SQ)
原理
SQはベクトル次元を変更せず、次元ごとの精度のみを下げます。
次元ごとの標準的なmin-maxマッピングは以下の通りです:
max_code = (1 << b) - 1scale = (max_val - min_val) / max_codecode = round((x - min_val) / scale)
Faiss SQには2つのスタイルがあります:
- Uniform:すべての次元が1つのmin/max範囲を共有
- Non-uniform:各次元が独自のmin/maxを使用
次元の値の範囲が大きく異なる場合、non-uniform SQは通常より良い再構築品質を提供します。
主な特徴
- 長所:
- 直接的で安定している
- 予測可能な圧縮(
sq8はfloat32値に対して約4倍、sq4は約8倍)
- 短所:
- 分布が固定ステップでバケット化できることを前提としている
- 次元が非常に不均一な場合(例:強いロングテール)、量子化エラーが増加する可能性がある
Faissソースレベル注記(SQ)
Doris + 最適化Faiss実装パスでは、SQ学習は最初にmin/max統計を計算し、その後追加時の範囲外リスクを軽減するために範囲をわずかに拡張します。簡略化された形は以下の通りです:
void train_Uniform(..., const float* x, std::vector<float>& trained) {
trained.resize(2);
float& vmin = trained[0];
float& vmax = trained[1];
// scan all values to get min/max
// then optionally expand range by rs_arg
}
非一様なSQの場合、Faissは次元ごとに統計を計算します(1つのグローバルな範囲ではなく)。これにより、異なる次元が非常に異なる値スケールを持つ場合に、通常はより良く動作します。
実用的な観察結果
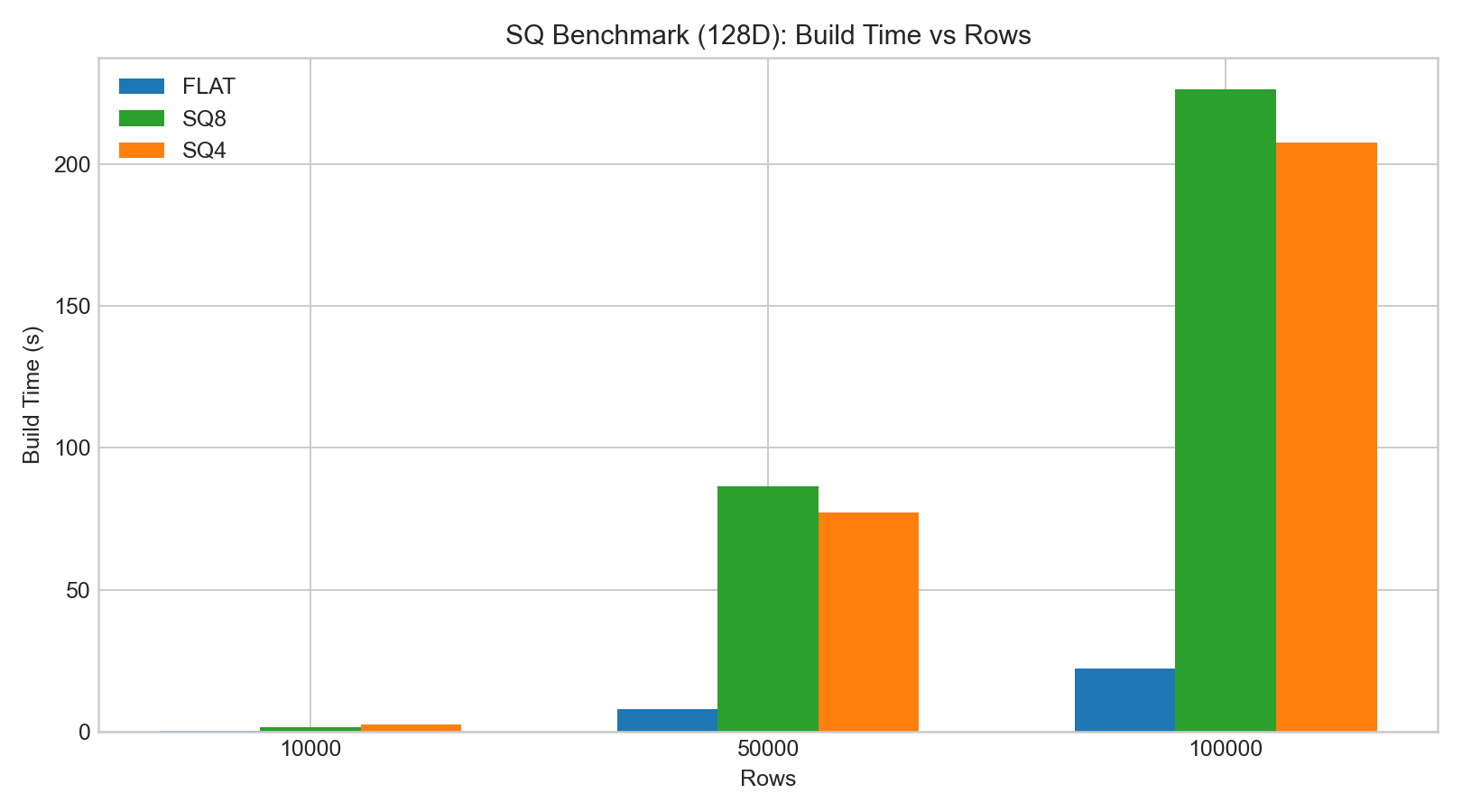
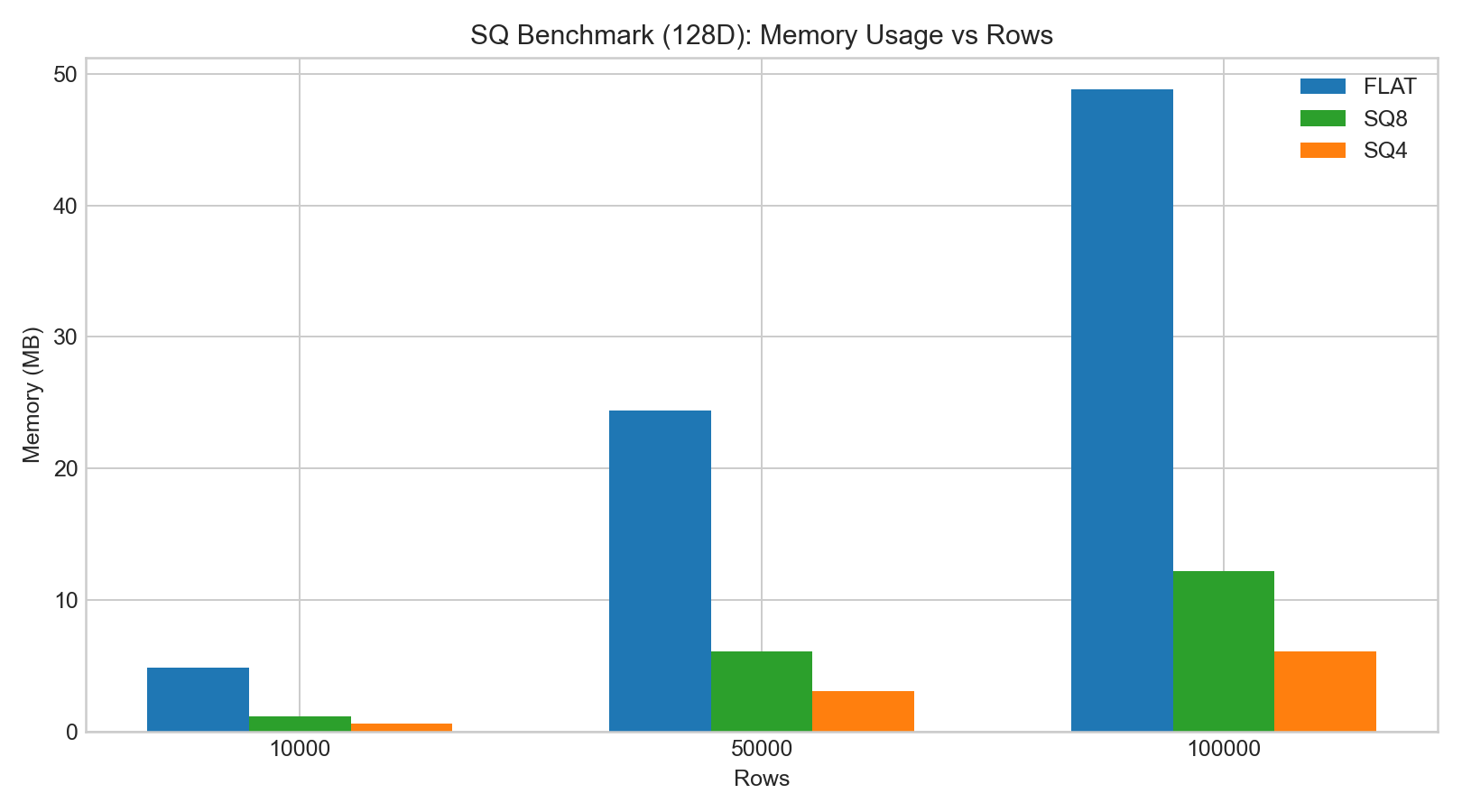
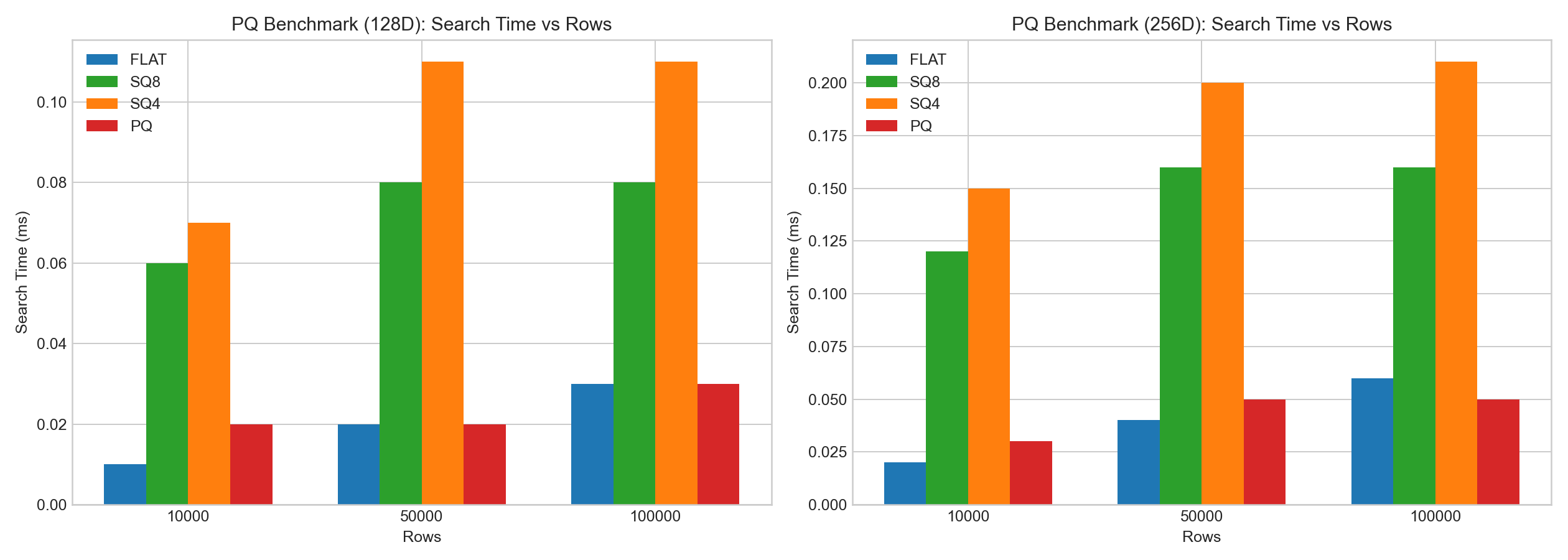
内部の128D/256D HNSWテストにおいて:
sq8は一般的にsq4よりもrecallをよく保持しました。- SQインデックスのbuild/add時間はFLATより大幅に長くなりました。
- 検索レイテンシの変化は
sq8では小さいことが多い一方、sq4はrecallの低下が大きくなりました。
以下の棒グラフはベンチマークデータの例に基づいています:
Product Quantization (PQ)
原理
PQはD次元ベクトルをM個のサブベクトル(それぞれD/M次元)に分割し、各部分空間にk-meansコードブックを適用します。
主要なパラメータ:
pq_m: サブ量子化器(サブベクトル)の数pq_nbits: サブベクトルコードあたりのビット数
pq_mを大きくすると通常は品質が向上しますが、トレーニング/エンコーディングコストが増加します。
PQがクエリ時により高速になる理由
PQはLUT(ルックアップテーブル)距離推定を使用できます:
- クエリサブベクトルとコードブック重心間の距離を事前計算します。
- テーブルルックアップ + 累積により完全ベクトル距離を近似します。
これにより完全な再構築を回避でき、検索CPU コストを削減できます。
Faissソースレベル注意(PQ)
同じ実装パスの下で、Faiss ProductQuantizerは部分空間上でコードブックをトレーニングし、それらを連続した重心テーブルに格納します。簡略化された形状は:
void ProductQuantizer::train(size_t n, const float* x) {
Clustering clus(dsub, ksub, cp);
IndexFlatL2 index(dsub);
clus.train(n * M, x, index);
for (int m = 0; m < M; m++) {
set_params(clus.centroids.data(), m);
}
}
Centroidは (M, ksub, dsub) として配置されます。ここで:
M: サブ量子化器の数ksub: サブ空間あたりのコードブックサイズ (2^pq_nbits)dsub: サブベクトル次元 (D / M)
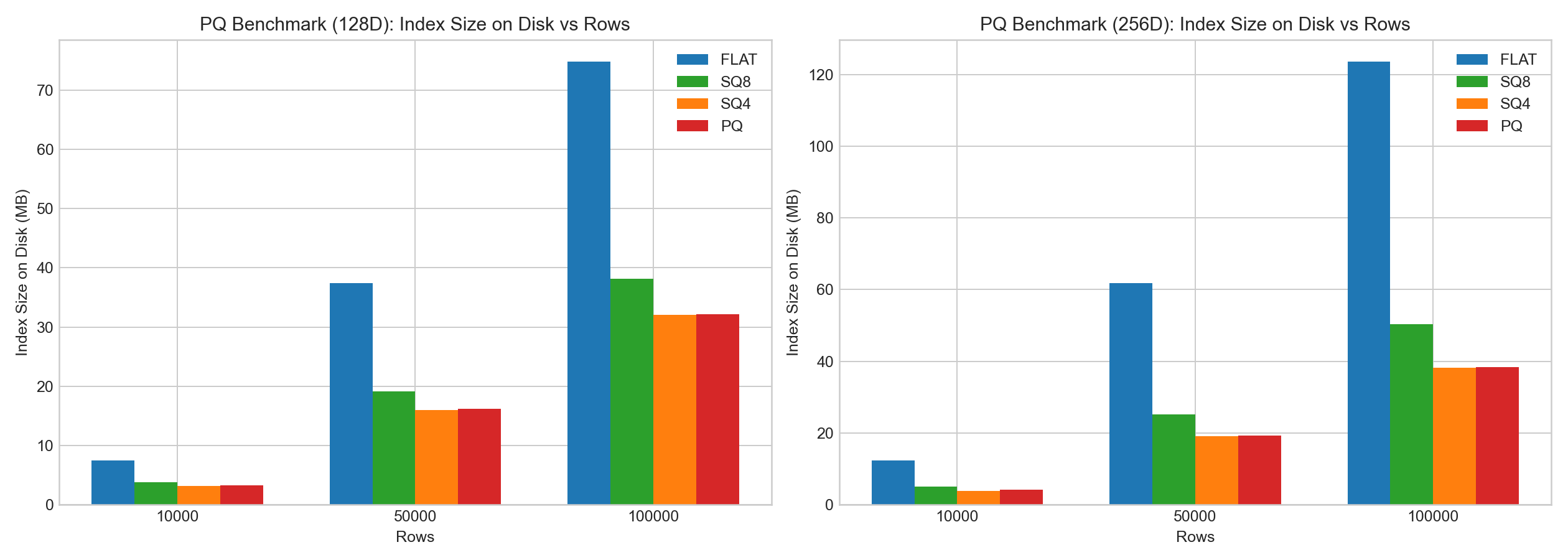
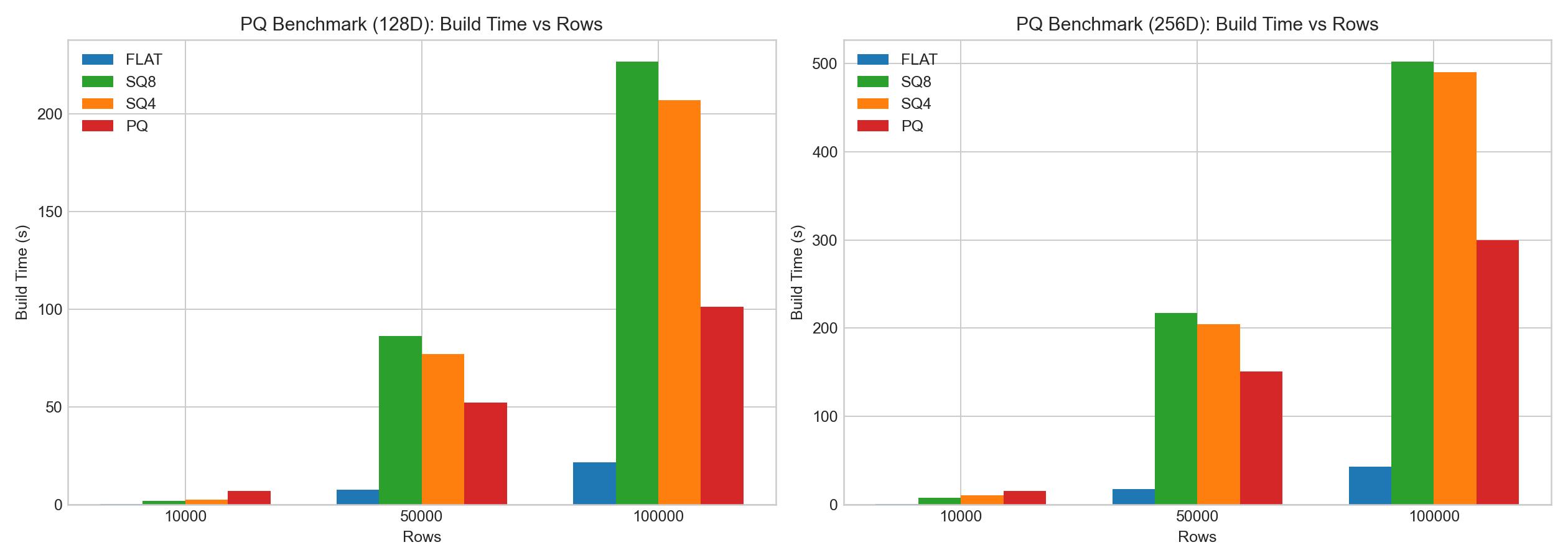
実用的な観測
同じ内部テストにおいて:
- PQは明確な圧縮効果を示しました。
- PQのエンコーディング/トレーニングオーバーヘッドは高いものでした。
- SQと比較して、PQはLUT加速により検索時の動作が良好な場合が多くありましたが、リコール/構築のトレードオフはデータとパラメータに依存しました。
以下の棒グラフはベンチマークデータの例に基づいています:
Dorisの実用的選択ガイド
これを開始点として使用してください:
- メモリが十分でリコールが最優先:
flat - 比較的安定した品質で低リスクの圧縮が必要:
sq8 - 極端なメモリ圧迫があり、より低いリコールを受け入れられる:
sq4 - より強いメモリパフォーマンスバランスが必要で、チューニングに時間をかけられる:
pq
推奨検証プロセス:
- ベースラインとして
flatから開始する - まず
sq8をテストし、リコールとP95/P99レイテンシを比較する - メモリがまだ高すぎる場合、
pqをテストする(最初の試行としてpq_m = D/2) - メモリ削減がリコールより優先度が高い場合のみ
sq4を使用する
ベンチマーキング注意事項
- 絶対時間はハードウェア/スレッド/データセットに依存します。
- 同じ条件下でメソッドを比較してください:
- ベクトル次元
- インデックスパラメータ
- セグメントサイズ
- クエリセットとグラウンドトゥルース
- 品質とコスト両方を評価してください:
- Recall@K
- インデックスサイズ
- 構築時間
- クエリレイテンシ